
燃烧动力学平台设计①
2022-06-27 03:55张宝花任海生王静波李象远
计算机系统应用 2022年5期
张宝花, 任海生, 王静波, 徐 江, 李象远, 金 钟
1(中国科学院 计算机网络信息中心, 北京 100190)
2(四川大学, 成都 610065)
3(北京石油化工学院, 北京 102627)
4(中国科学院大学, 北京 100049)
航空燃料通过燃烧为飞行器提供动力, 燃料燃烧是发动机共性问题, 反应机理是燃烧数值模拟的关键.NASA 规划在2030 年实现百亿亿次带复杂燃烧模型的整机CFD 模拟[1], 其中合理的简化燃烧模型耦合是计算得以实现的基本保证, 燃烧数据是燃烧模型耦合的基础.
专业的燃烧数据库是燃烧室数值仿真、燃烧组织优化和热端部件冷却设计的基础. 国际上NIST[2]等数据库系统已经收集了众多的热力学、动力学数据, 但多为气相小分子参数, 而高碳烃等大分子燃料的热力学和动力学参数仍然缺乏. 目前大量裂解、夺氢等基元反应的动力学参数还采用按反应类赋值等方式近似处理, 而热力学参数多采用基团贡献法等近似. 由于我国在数据库建设方面的短板, 使得大量基础研究和工程设计对国外数据库网站产生了高度依赖. 对国外数据的使用仅限于可公开的部分数据和网上检索, 网络开关掌控在别人手里. 对西方核心技术的高度依赖导致了高科技领域的被动. 因此, 建立自主的燃烧数据库平台非常迫切.
对燃料燃烧反应机理的研究, 国际上有MAMOX[3]、EXGAS[4]以及RMG[5]等主流机理构建程序. 但这些软件都有其局限性, 且多为非开源软件, 无法满足需求.因此, 发展并完善我国自有的机理生成方法和程序, 根据化学反应动力学研究的最新进展对燃烧参数和燃烧机理构建方法不断更新是十分必要的. 另外, 由于燃烧机理构建对燃料、工况和简化方法选择的依赖性, 使得燃烧动力学模型具有个性化特点[6]. 因此, 如何将不同燃料的个性化动力学建模在发动机燃烧数值模拟过程同步实现, 根据湍流分辨率和计算资源确定动力学建模策略, 是连接燃烧反应机理研究和燃烧数值模拟应用的一条全新途径. 一种可行的技术路线是基于燃烧机理自动生成、自动简化方法和可靠的燃烧反应参数计算, 构建用户自定义燃烧动力学模型的在线建模环境. 用户能以数据库为基础, 通过对话式引导获得燃烧动力学模型, 解决当前燃烧数值模拟软件不能为用户提供个性化燃烧反应机理的问题, 服务于我国独立自主的航空发动机预研体系建立.
针对以上对燃烧数据库和软件易用性服务的迫切需求, 本文以形成我国自主的燃烧数据库系统和动力学建模系统为目标, 实现基于Web 的页面数据检索和软件计算, 秉承开放共享的理念建立建成燃烧动力学平台.
本文采取前后端分离的开发模式[7], 将前端业务和后端业务逻辑分离开来, 考虑到燃烧动力学平台包括多个数据库检索和软件在线计算, 页面交互式强, 需要多终端访问和可持续扩展等特点, 本文采用模块化设计与实现, 建成了开放使用的燃烧反应数据库系统和人机交互的燃料动力学建模系统.
另一方面, 燃烧数据包含5 大类8 个类型的数据,类型多且来源分散, 数据产生周期长, 而整理耗时耗力且容易出错. 因此, 为促进数据的长期管理和维护, 本文开发了灵活易用的数据汇交系统, 实现汇交数据和已有数据的融合, 通过用户和平台的共建共享, 提升数据流动性, 让数据产生真正的价值. 燃烧动力学平台的建立, 将显著拓宽数据获取渠道, 减少国内用户对国外数据平台的依赖, 显著降低燃料反应机理软件使用门槛, 节约用户科研时间和经费, 推动国内基础燃烧反应数据的交流与共享, 支撑航空煤油高精度燃烧反应机理的构建.
以下围绕燃烧动力学平台展开叙述, 将从平台的整体结构、关键技术设计与实现以及实现效果等方面进行介绍.
1 整体结构
燃烧动力学平台包括燃烧数据库检索、数据汇交和在线动力学建模模块及一些辅助模块. 为保证平台的易用友好、稳定运行和良好的可维护性, 平台采取了图1 所示的框架设计方案.
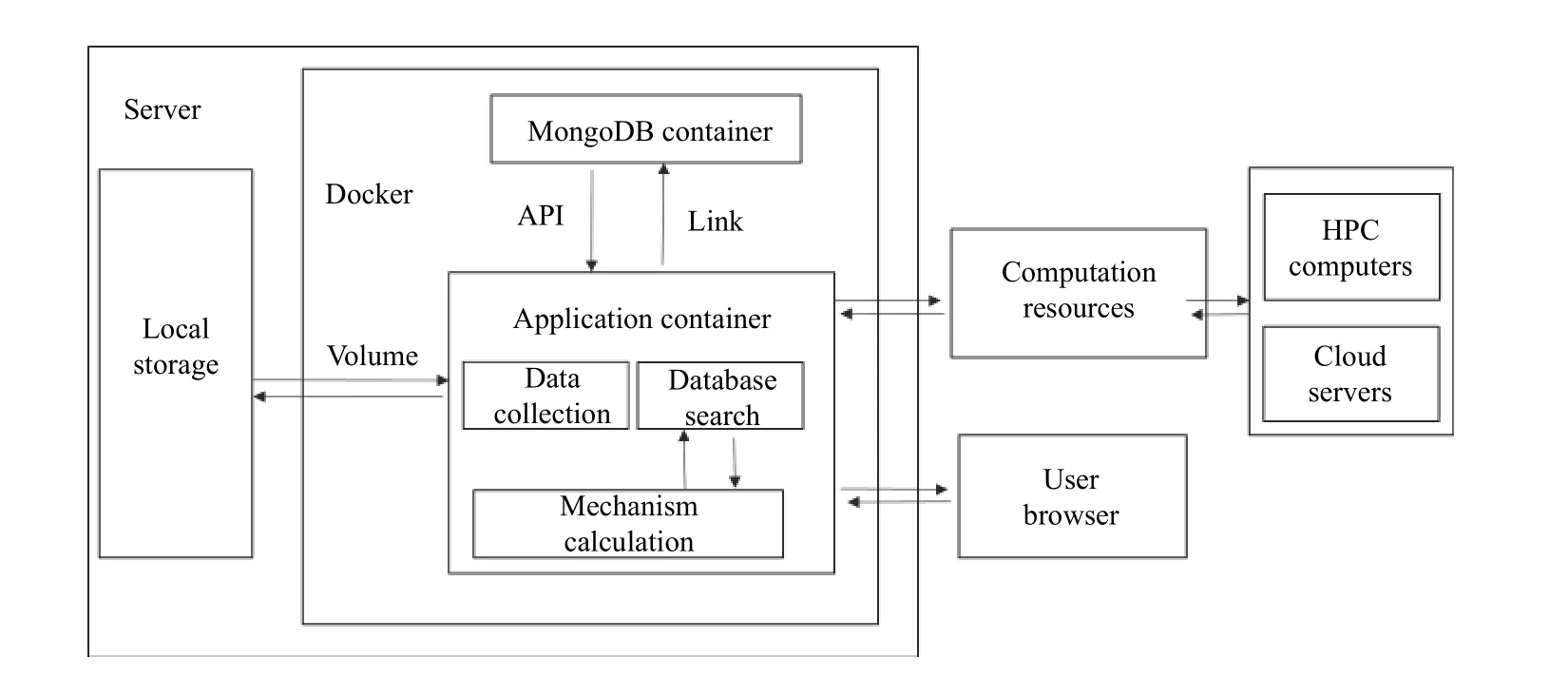
图1 燃烧平台设计架构
平台整体架构以容器化方案为基础, 采取Browser/Server 的前后端分离开发模式, 分为前端用户浏览器、前端服务器及后端服务器和数据库等部分. 代码开发遵循“高内聚, 低耦合”策略, 各功能独立的模块分离, 通过API 等进行调用, 实现易于插拔和良好的可扩展性.前端页面采用目前流行的Vue.js[8]渐进式框架开发, 并结合Bootstrap、Chart.js 等开源工具包进行各种页面的渲染和结果展示. Vue.js 是MVVM (model, view,view-model)[9]框架, 支持响应式数据双向绑定, 低耦合且重用性强. 在开发中, 遵循组件化设计模式, 通过组件引用等形式层层组装形成各个页面, 以达到最大化复用(图2).

图2 前端代码组织结构
平台后端开发使用Python 语言的Flask 框架[10],它是一个基于Werkzeug 工具箱开发的Web 开发框架,具有轻量灵活的特点. 本文利用Flask 框架构建RESTful API 接口进行前后端交互, 通过pymongo 链接MongoDB数据库进行数据增删改查等操作. 对于计算任务, 采用Celery 进行调度计算, Redis 进行消息传递, 保证了计算过程与平台操作的多线程处理, 提高响应速度, 计算结果通过MongoDB 进行存储(图3).
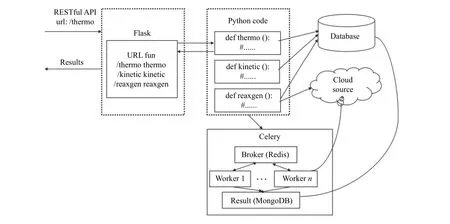
图3 后端代码组织结构
2 设计实现
2.1 数据存储与检索系统
数据库系统包括热力学数据库、动力学数据库、输运数据库、实验数据库(含点火延迟数据库、 高温热物性数据库、 火焰传播数据库、燃料物种浓度数据库)和燃烧机理数据库5 大类8 个数据库. 由于数据种类多且来源分散, 数据存在格式不一致, 数据质量参差不齐等问题, 对数据的处理和检索提出了较大的挑战.为此, 平台采取了图4 所示的处理流程策略.

图4 数据入库处理流程
原始数据来源包括公开网站的爬虫数据、公开发表文献、理论计算结果、实验测试结果等, 通常格式各异, 数据规范化差. 根据业务数据特点, 本文分别制定了各数据入库标准规范, 对每一类来源数据进行规范化与标准化, 例如对数据字段和单位进行统一. 数据处理包括对原始数据的再加工, 例如对热力学摩尔文件进行分析, 由OpenBabel[11]软件统一转换为 Canonical SMILES, 对于含自由基的结构进行特殊标记处理, 保证在转换时候保留自由基特性. 对动力学数据进行双参数拟合, 并计算拟合优度等. 针对数据质量和重复问题采取了数据清洗策略, 例如对热力学数据焓变取值的一致性检查, 对错误的动力学反应结果或缺少关键信息数据进行筛减, 对重复数据进行去重等操作. 经过处理的数据, 采用MongoDB 以BSON (binary JSON)格式来存储和管理各种数据. 如图5, 根据数据特点建立数据逻辑模型, 前端检索通过API 对应到后端相应的检索方法, 根据每类数据的特点链接到对应数据库执行语法分析和查询计划.

图5 数据查询流程图
平台对每类数据提供了多种检索方式, 例如热力学数据库包括上传文件检索、SMILES 检索、分子式检索、CAS 号以及在线建模检索等多种方式, 并支持精确检索和模糊匹配检索. 由于同一物种对应的SMILES 会出现不一致, 简单字段匹配检索会出现检索不准确问题, 为此, 后端采用了SMILES 转换处理策略,转换为可唯一性标识的Canonical SMILES, 保证了查询结果的一致性.
2.2 数据汇交系统
数据汇交与审核是数据库实现良性可持续发展的关键. 增加数据汇交系统, 可以随时随地收集零散数据到平台. 为确保高效、规范化的将高质量科研数据汇交到燃烧动力学平台, 促进汇交数据与已有数据的有效融合, 本文制定了如图6 所示的数据汇交与审核方案.
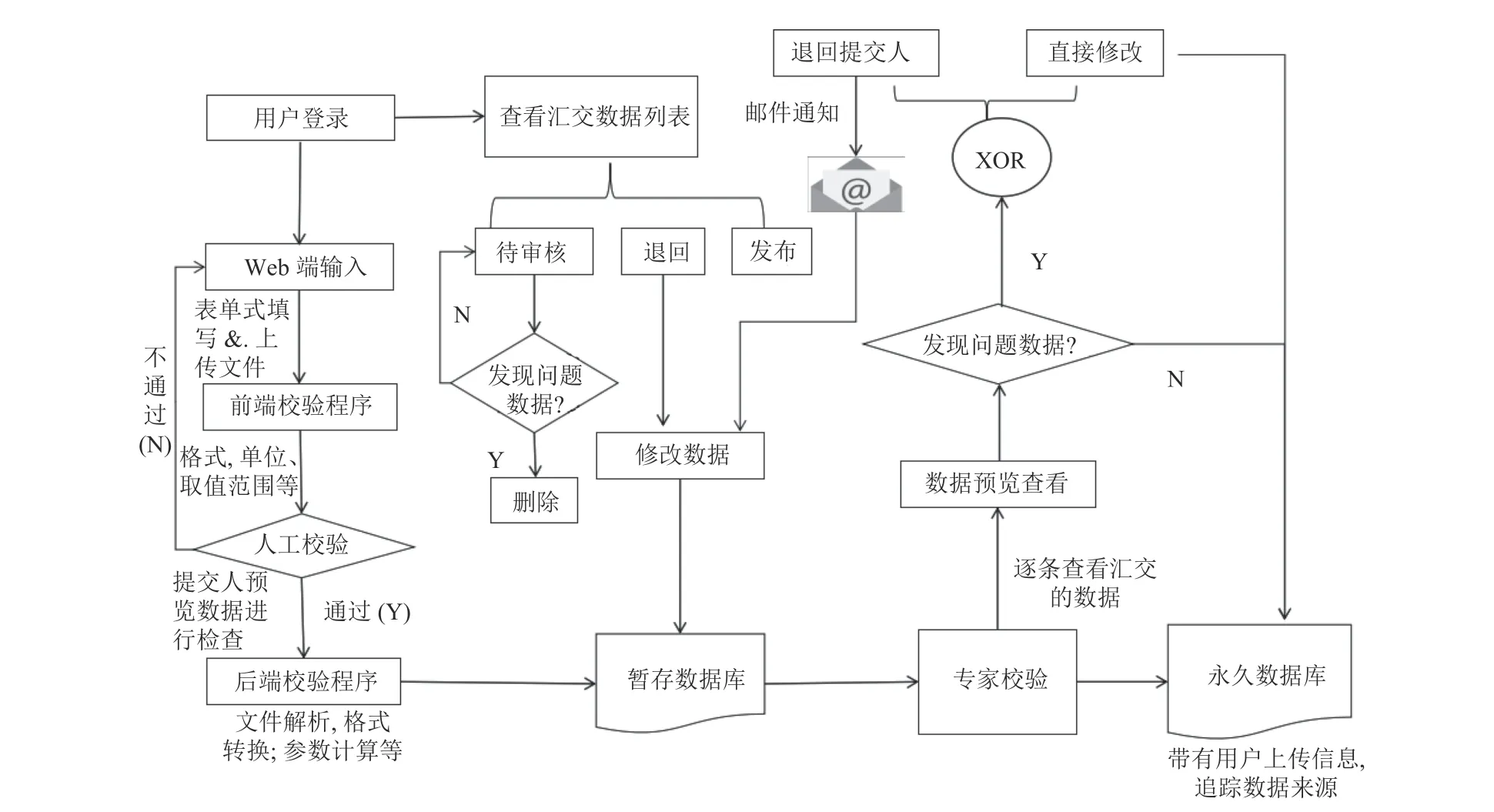
图6 数据汇交与审核方案
本文从用户角度出发, 设计了数据提交、数据预览和提交审核3 个步骤. 在数据提交阶段, 用户通过在线表单方式填写数据和上传文件, 平台对数据完整性、规范性以及数据重复性进行校验. 在数据预览阶段, 对通过校验的数据进行处理和结构化展示, 例如对上传数据的可视化展示功能, 辅助用户审查汇交的数据. 通过数据预览正确的数据, 可以提交汇交审核到平台.
为避免低质量或错误数据污染正式数据库, 经过上述步骤汇交的数据会保存到暂存数据库中, 由专家审核通过后方能汇入到正式数据库中. 专家审核是实现数据汇交系统功能价值的关键, 此部分代码逻辑如图7 所示.

图7 专家审核代码逻辑
由于燃烧数据复杂, 难以从数据表中各类字段直观看出数据错误, 本文设计了与数据汇交预览阶段相似的处理方式辅助专家进行数据审核. 通过审核的数据会转入正式数据库中共享给其他用户. 数据审核中,专家可对低质量数据进行退回, 对于少量错误亦可直接修正. 对于未通过审核的数据, 专家本人或其他专家可以再次审核, 审核意见经由后端Flask-Mail 邮件服务通知汇交者进行数据的修改或补充. 暂存数据库和正式数据库中均带有汇交用户和审核专家信息, 为数据的溯源和回滚等操作提供依据.
2.3 在线动力学建模系统
本文建设了人机交互的燃烧反应动力学建模环境,前端由用户输入机理计算所需要的物种和参数等信息,并提供“所见即所得”形式的文件展示, 后端计算采用Python 并行分步式框架Celery 进行任务计算, 采用Redis进行消息传递, 任务结果存储于MongoDB 数据库中(图8).
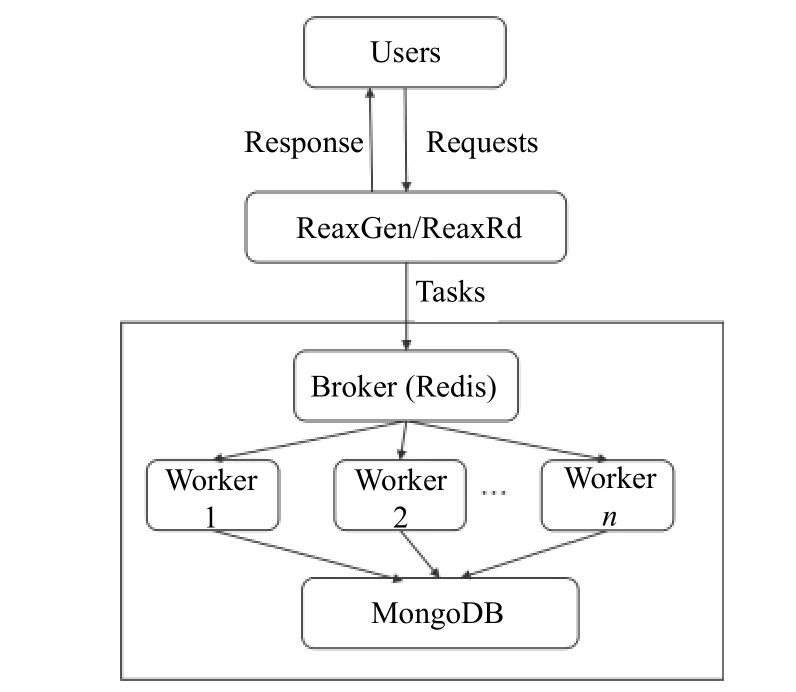
图8 在线动力学建模技术流程
2.4 用户授权与安全认证
用户认证和管理是平台提供个性化服务的基础.平台采取了RBAC (role-based access control)模型[12],通过用户-角色-权限3 个维度完成对用户权限的控制.根据平台数据管理、搜索和汇交审核等不同功能特点,设计了普通用户、专家用户和管理员用户3 种角色,其中专家角色根据其对不同数据的专业度, 赋予不同数据库的审核权限. 平台通过邀请码机制来赋予专家角色. 为了保障数据的安全, 采用JWT (JSON Web token)[13]跨域身份认证方案作为平台 “通行证”, 采用HMAC-SHA256 算法进行密码加密, 校验成功后返回token, 在后面的操作中只需要携带此token 即可访问相关的页面和数据(图9).
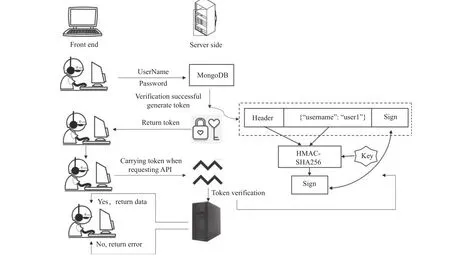
图9 用户认证授权过程
2.5 平台部署
在线服务的快速部署和一致性运行环境是数据平台实现快速迭代及稳定化运行的关键. 平台采取了Docker 容器化技术[14]建立一致的运行环境, 采用Docker-Compose 技术自动化部署和管理多个容器.平台涉及的容器包括数据库容器、软件容器、计算容器等, 通过Docker networks 将涉及的容器进行互连并与其他软硬件隔离, 通过端口映射到公开端口的方式实现外网访问, 提高平台的安全性. 对于前端代码, 通过webpack 打包工具将代码翻译压缩, 形成浏览器可以访问的静态文件. 以Flask-Nginx 作为基础镜像(包括一个精简的Ubuntu 系统、 Python+Flask环境和Nginx 服务器)结合特定源码文件Dockerfile来创建平台应用镜像. 在容器运行中, 前端请求通过容器内Nginx 服务器接收并代理到WSGI 服务(Python Web server gateway interface), 进而调用后端相关模块完成操作并返回结果. 代码的开发, 迁移及发布阶段, 编写了相应的脚本辅助进行, 以实现自动化部署流程.
2.6 数据灾备
平台的稳定运行是可持续发展的基本保证. 燃烧数据平台涉及用户信息、正式数据、用户上传数据,计算程序结果等多种类型数据. 随着数据量的增大, 服务和数据的容灾备份就显得非常重要. 在本工作中, 采取了每天备份策略, 将数据通过NFS 网络文件系统及时备份到其他服务器. 另外, 为保证在线服务的稳定运行, 在备份服务器中部署了服务容器, 一旦生产环境出现问题, 立即可以切换到备用服务器提供服务(图10).
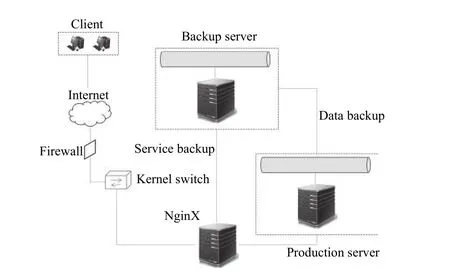
图10 服务灾备策略
3 实现效果
燃烧动力学平台分为发布版和测试版, 其中发布版本功能稳定, 网址为http://combus.vlcc.cn/, 测试版本注重功能的增加与完善, 网址为http://test.vlcc.cn. 网站平台采用自适应网页设计理念, 支持多种浏览设备, 如桌面电脑显示器、智能手机或其他移动产品设备, 及多种操作系统的访问, 如Linux、Windows、 Mac 等,下面以测试版本功能进行介绍.
平台主页上提供了各个数据库/计算软件的入口,点击相应的卡片可进入各功能版块. 例如, 点击热力学数据库卡片, 可进入到热力学数据检索页面, 用户可根据需求选择上传文件或输入分子式、SMILES 式、CAS号进行检索, 此外, 通过集成JSME 软件[15]提供了在线建模形式的检索, 并支持模糊匹配. 例如, 以SMILES为“CC”输入进行精确匹配查询, 检索结果如图11 所示, 图11(a)简单展示了检索结果, 在详细信息下点击“查看”后进入到详细信息展示页面, 图11(b)详细展示了乙烷分子所包含的基本信息, 常温下热力学信息表及参考文献等信息. 在热力学信息表中, 点击相应的热力学数据项, 可显示图11(c)的CHEMKIN 格式热力学数据拟合曲线, 点击Cp_T 数据项, 可显示图11(d)所示的等压热容随温度变化曲线及拟合曲线和公式.

图11 热力学数据搜索结果页面
对于动力学数据库, 提供按照分子组成和分子唯一性检索方式, 并支持模糊匹配. 例如, 输入反应物分子式C3H4, 产物分子式C6H6, 模糊匹配查询得到如图12 结果. 图12(a)展示了所有符合条件的反应, 在每条结果的详细信息处点击“查看”, 显示出对应方程式的详细信息(图12(b)), 包括反应方程式, 鼠标悬浮到每个反应物/产物会显示其结构式, 点击物种名称可展示其对应热力学信息, 实现了热力学数据和动力学数据的联动. 列表展示了反应方程式所对应的参考文献、温度范围、方法模型、对应的三参数数值、计算出的双参数数值等. 点击“plot”可展示图12(c)所示的速率常数曲线.
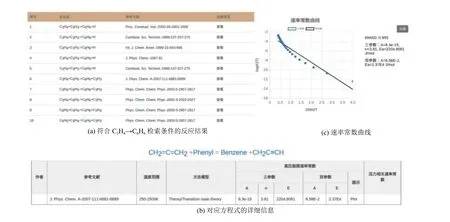
图12 动力学数据搜索结果页面
对于实验数据库, 所有数据(包含燃料点火延迟时间、火焰传播速度、物种浓度、高温热物性等数据类型)通过同一入口页面进行检索. 对一些常见物种提供了按照分子名称选择的查询模式, 在列出的实验数据类型中选择相应的数据类型, 点击后进行具体工况的选择和查询. 例如以“RP-3”为例, 检索得到的实验数据类型包括点火延迟时间和高温热物性(图13(a))[16]. 点击“点火延迟时间”标签, 进入到点火延迟数据页面, 按照参考文献、当量比和压力, 确定检索的温度范围. 检索结果包括点火延迟时间曲线等(图13(b)). 点击“高温热物性”标签, 进入到高温热物性数据页面, 包括密度、热容和热沉数据. 选择数据类型后, 根据压力确定温度范围. 检索结果包括温度-密度曲线、温度-热容曲线、温度-热沉曲线, 并提供参考文献及原始数据的查询.

图13 实验数据搜索页面
数据汇交功能包括数据填写、数据预览、数据审核3 个步骤, 通过引导式进行访问. 如图14, 以热力学数据汇交为例, 数据填写步骤中带“*”的为必填字段.一条数据可以包含多条热力学信息, 并通过SMILES与已有数据库数据进行比对, 避免数据重复提交. 用户可上传摩尔文件, 热力学文件和热容-温度数据(图14(a)).在数据预览阶段, 数据结构化呈现, 通过 “Chem-Doodle”分子模型绘图工具解析摩尔文件并提供分子模型展示, 不同热力学信息通过参考文献进行划分. 对热力学文件进行解析, 并通过参数拟合公式, 得到热力学信息曲线(图14(b)). 在专家审核页面, 加入了专家审核-有关信息和专家审核-请审核数据模块(图14(c)和图14(d)), 审核意见可供汇交用户和其他审核专家参考.

图14 数据汇交与审核页面
在平台首页提供了反应动力学软件入口卡片, 点击后可进入到相应的软件计算页面. 例如, 点击ReaxGen程序进行在线计算, 计算输入文件可通过表单式创建,包括勾选参数、填写物质SMILES 或在线创建分子等多种方式创建输入文件, 平台提供实时的输入文件展示功能. 点击“提交计算”可上传作业到后端运行(图15(a)).计算任务提交后, 会返回作业计算进度条, 用户可收藏页面稍候查看计算结果, 或等待计算任务完成自动刷新显示结果. 计算结果提供了文件列表, 包括文件名、大小、文件查看和下载功能(图15(b)).

图15 机理生成计算与结果页面
4 结论
本文基于燃烧反应相关的各类数据和计算软件,建立了可持续发展的燃烧动力学平台. 文中从平台整体框架、数据检索系统、在线动力学建模系统、数据汇交系统、用户认证系统、平台部署及数据灾备策略等方面介绍了关键的技术与实现策略. 建成的平台包括数据库检索和汇交系统及在线动力学建模系统, 为国内首个公开免费且可持续发展的多类型燃烧数据平台. 其中数据库检索系统可实现包括热力学数据库、动力学数据库、输运数据库、实验数据库、燃烧机理数据库在内的5 大类8 个数据库的检索, 检索界面简洁友好, 交互式强. 通过制定统一的数据准入标准和规范, 将理论计算、文献及实验等多方来源数据进行分类管理和检索, 并保证了数据的前后一致性. 平台通过汇交系统进行数据的收集与审核, 实现高质量汇交数据与已有数据的融合, 促进了数据的流动. 在线动力学建模系统采用交互引导方式实现了创建计算输入文件、提交计算和获取结果的一站式功能, 实现了用户自定义燃烧机理生成的在线动力学建模计算.
燃烧动力学平台在性能和稳定性方面的发展还在持续进行中, 未来功能发展的重点包括: (1)进一步完善数据汇交流程, 开发更多数据库的汇交功能. (2)实现数据库与机理计算软件的联用, 通过数据库为计算软件提供基础和参考, 通过计算来扩充数据库. (3)为计算软件计算提供与多种计算资源的融合与调度及丰富的结果分析功能.
猜你喜欢
保健医苑(2022年1期)2022-08-30
空气动力学学报(2022年4期)2022-08-23
北京航空航天大学学报(2022年7期)2022-08-06
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
黑龙江大学自然科学学报(2022年1期)2022-03-29
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
动漫界·幼教365(中班)(2021年4期)2021-05-23
电脑爱好者(2020年17期)2020-09-14
中学物理·高中(2016年8期)2016-08-08
中学生数理化·高二版(2008年10期)2008-06-17
