
多主体机器人路径规划方法研究
2022-06-28 17:46祝晨旭仲志丹张浩博乔栋豪
制造业自动化 2022年6期
祝晨旭,仲志丹,张浩博,乔栋豪
(河南科技大学 机电工程学院,洛阳 471003)
0 引言
机器人路径规划是指在机器人工作环境中,为指定目标的移动机器人规划出无碰撞、高效率的最佳路径。随着移动机器人的广泛应用,导航场景由最简单的预设轨道的导航[1,2],扩展到躲避静态障碍、动态障碍和动态静态障碍混合的复杂场景。得益于传感器技术的提升,移动机器人获取环境信息的能力增强,移动机器人的路径规划方法也演变成了更加强大的基于学习的算法[3~5]。
常见的移动机器人有各个品牌的扫地机器人,它们的路径规划分为两个部分,全局路径规划和局部路径规划。扫地机器人的全局路径规划属于遍历式的路径规划,这取决于它们的工作性质。全局路径规划通过雷达扫描环境完成地图创建,基于地图信息完成清扫路径的规划;局部路径规划适用于处理突发情况,躲避地图信息上未显示的特殊障碍,例如人。一旦出现突发情况,要结合全局规划重置全局路线绕过特殊障碍。在扫地机器人的工作环境中,对出现特殊障碍的问题处理的时效性要求不高。
相对于扫地机器人,在多主体环境中运动的移动机器人需要的不仅是将其他主体视为动态障碍,还要对其他主体的移动趋势进行判断,以此来做为决定自身下一步运动规划的重要条件。在较为简单的情况下,其他主体的移动趋势为静止或者匀速运动,易于观测与判断,Chen Y F[6]提出短时间内将其他主体看作明确的匀速运动模型来简化方法设计。但是在多数情况下,即便了解其他主体的目的地,在转向角度等内部因素未知,尤其是其他主体为人的情况下,其他主体的移动趋势就变得难以捉摸,这是常规的运动规划处理不好的。为了应对这样的工作环境,Long P[7]等不再试图明确其他主体的动作,而是使用深度强化学习直接对移动机器人与环境的交互建模完成路径规划。
多主体机器人运动规划还需要解决另一个关键问题:环境中其他主体的数量是变化着的,深度强化学习网络需要固定维度的输入,Cho K[8,9]等定义网络所能观测到的主体的最大数量,使用LSTM(long-short term memory)神经元,接收不同长度的输入信息,输出固定维度的向量,输入信息在输出中所占比重与时序相关,距离主体机器人越近,信息所占比重越大。这使得规划方法能够基于任意数量的其他主体做出决策。
1 基于深度强化学习的避障
延续之前方法[10]的常规设定,使用st表示主体机器人的状态,ut表示它的动作,用表示其他主体的状态。状态由可观测和不可观测两部分组成,可观测部分s0包含主体的位置p,速度v,和半径r,s0=[px,py,vx,vy,r],不可观测部分sh包含目标位置,优先速度vp和方向角ψ:sh=[pgx,pgy,vpx,vpy,ψ],动作ut由速度和方向角组成,ut=[vt,ψt]。深度强化学习的策略π:该策略在避免与其他主体发生碰撞的同时,最小化到达目标的时间Etg。
其中,式(2)代表碰撞约束,在所有时间内主体与任意其他主体距离不得超过其半径和;式(3)为目标约束,式(4)为主体的运动方程。对于式(1)中的期望值,不需要去考虑明确的数学模型,通过强化学习方法,发生碰撞时给予主体惩罚,顺利到达目标点给予主体奖励,由奖励方程Rcol(Sjn,u)决定:


在式(7)中γ表示奖励因子,V*(Sjnt+1,u)表示通过选择动作u达到最大化的价值。
2 学习策略
2.1 演员-评论家(Actor-Critic)
深度强化学习方法对于动作的选择有两种方式,基于概率(Policy-based)和基于值(Value-based),其中基于概率的方式中,动作集中的每个动作都可能作为下一个动作,只是选择概率不同;基于值的方式中,算法为每个动作评分,选择评分最高的动作作为下一个动作。演员-评论家算法是这两种方法的结合:Actor基于概率选择下一步的动作,环境将对动作的奖励反馈给Critic,Critic根据环境反馈的奖励指导Actor修改选择动作的概率。图1的框架显示了Actor网络、Critic网络之间的关系。

图1 AC网络结构图
2.2 NoisyNet-GA3C避障方法
A3C方法是基于AC方法的一种优化训练方法,对学习主体多线程训练以加快主体的训练速度。A3C结构如图2所示。在A3C方法中,主体与环境交互的许多线程是并行模拟的,学习方法的训练结果基于全部经历的融合。这个算法在许多电子游戏的表现中优于人类。Babaeizadeh M[12]对其实现进行了修改,以有效地使用GPU来最大化每秒处理的训练经验的数量,在许多情况下,GA3C方法的学习速度比A3C方法快一个数量级。
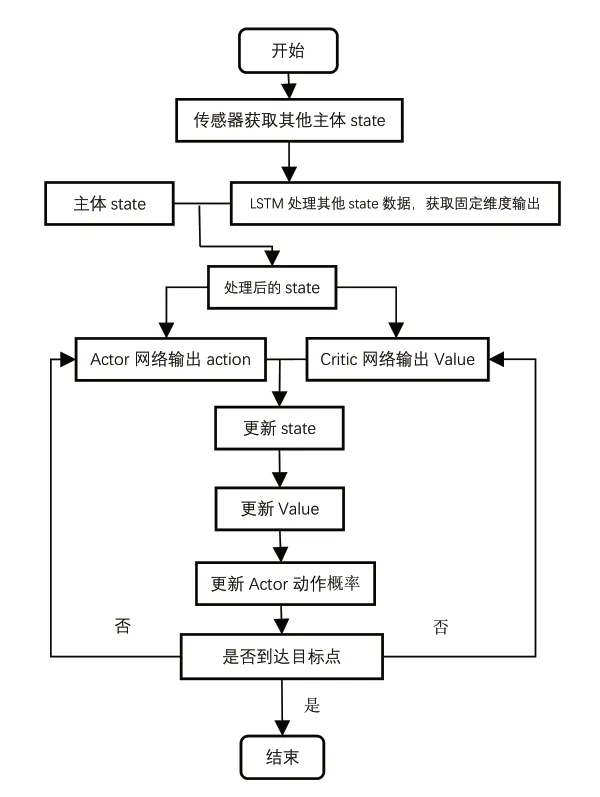
图2 Noisy Net-A3C方法流程图
一般地,将NoisyNet以y=fθ(x)表示,x表示输入,y表示输出,θ表示噪声参数,其中θ定义为:


NoisyNet-GA3C方法在Critic网络的全连接层中添加了一层噪声网络以增加模型的探索能力。NoisyNet-GA3C方法总体流程图如图2所示。
3 实验验证
3.1 网络训练
针对现存方法在数据维度较低时寻路时间长,碰撞率高的问题,设置训练场景时,场景中的最多共存机器人数量n<5。Actor网络为基于概率的学习网络。设置主体转向角度的间隔为30°,每一步的动作有十一个方向可以选择,每次训练中的动作选择概率由Critic网络的Value更新。Critic网络为基于值的学习网络,通过环境反馈的奖励更新Value。在训练网络时,Critic网络选择的学习率为,Actor网络选择的学习率为,这是因为Critic网络对Actor网络起指导作用,Critic网络要更加快速的学习。网络训练的tensorflow版本为tensorflow1.4.0-GPU,使用Adam优化器。
将主体每回合接收的最大奖励设置为1,最终获得的平均奖励为0.96,意味着最终收敛之后还是会发生碰撞,这在预料之内,在大量的训练中,选择出非最优动作是难以避免的。如表1中所示,相对于之前的方法平均奖励为0.92,改进后的方法平均奖励取得了可观的进步。

表1 三种规划方法平均奖励对比
3.2 实验仿真

图3 训练中主体得到的奖励
ROS(Robot Operating System)是一款机器人仿真开源平台,使用ROS平台仿真主要应用到了它独特的通讯机制——话题的发布和订阅,可以通过修改话题内容和订阅者对机器人模型进行修改和。Gazebo是ROS平台中的机器人仿真工具,在Gazebo中设置一个turtlebot3_waffle机器人作为实验主体,三个turtlebot3_burger机器人作为其他主体。获取Gazebo发布的机器人state作为NoisyNet-GA3C的输入,算法输出的action发布到action话题,实验主体订阅action话题,即可在仿真环境中做出相应的动作。
在gazebo中,场景里设置一定数目的移动机器人后,算法所需state值,即移动机器人的在仿真世界的坐标、速度,可以由软件自行生成(图4(a)),获取到数据后按照算法所需state格式打包发送至对应的pose话题,NoisyNetA3C算法获取主体state和LSTM算法处理过的其他主体state之后,输出action至cmd_vel话题,主体订阅该话题接收action信息完成响应。使用gazebo仿真的话题节点图如图5所示。在仿真环境中,主体能够快速响应,避开其他主体到达给定目标。
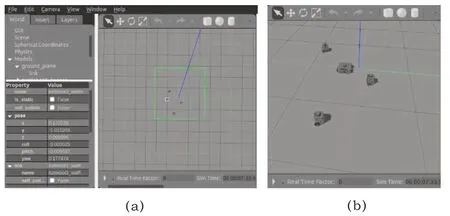
图4 gazebo中仿真

图5 gazebo仿真节点图
4 结语
本文对现存的基于强化学习的多主体路径规划方法进行了改进,引入NoisyNet方法,使用LSTM网络处理不同维度的数据,在输入网络前得到相同维度的输入。通过在网络的全连接层添加噪声网络,增强模型的探索能力,提升了现存深度强化学习算法在输入数据维度较低时规避障碍的能力。随着强化学习方法的不断发展,将有更加优秀的强化学习方法提出和改进,多主体机器人规划会在避障速度和时效性上获得更进一步的发展。
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02
财会月刊·上半月(2022年5期)2022-05-17
南大法学(2021年3期)2021-08-13
房地产导刊(2021年6期)2021-07-22
现代仪器与医疗(2021年1期)2021-06-09
领导文萃(2020年15期)2020-08-19
电子技术与软件工程(2019年20期)2019-11-30
领导决策信息(2018年16期)2018-09-27
计算机测量与控制(2018年9期)2018-09-19
中华诗词(2018年1期)2018-06-26
