
多传感器机器人定位信息挖掘方法设计
2022-06-28 17:46刘云萍韩艳丽
制造业自动化 2022年6期
刘云萍,韩艳丽
(太原工业学院 计算机工程系,太原 030008)
0 引言
机器人SLAM技术中有一个可以自动定位的技术叫做机器人定位技术,机器人定位技术的运行原理就是凭借着自身的各个传感器为介质,用此来吸引附近的物质获得一些精准消息,并将获得精准消息通过详细的计算方式得到精准的地理位置。通过单个传感器在复杂环境下很难准确定位,不能保证机器人能够长期稳定的运行[1]。通常在不同的场景需要不同的传感器,以保证定位的稳定性,因此多传感器融合定位已成为一种必要的发展趋势。实现多传感器融合定位过程中还存在众多问题,比如怎样选取多传感器组合,怎样融合多传感器相关信息,克服这些阻碍对将来机器人的推广和应用有着重大意义。利用机器人自身的传感器来收集附近的精准信息,并且应用这些信息,计算出机器人的精准位置和实时动态的方法就叫做机器人定位算法[2]。可为机器人实时提供有效的避障、路径规划、作业决策等相关信息。进一步对机器人的精准位置和实时动态等信息进行挖掘,是可以提升多传感器机器人整体工作实效的一种方式。为此,提出了一种基于SLFN的多传感器机器人定位信息挖掘方法。
1 多传感器机器人定位
把匀速状态设立在实施定位的机器人中,速度值为v。当T1时刻到达点A时,收集传感器状态强度数据,因为机器人是一直在运行的状态,所以必须当信号抵达点B并且是在T2时间抵达时,才能达到可以开始定位计算的要求[3]。从下面的图1可以看到,L是A、B之间的长度,Δt是T1、T2中间的时间段,AB两者之间的中间点是C。经过对这些数据的推理可以得到,需要计算出的是T1时间时A(x1,y1)的具体坐标点,但是现实计算出来的是T2时间时B(x2,y2)的具体坐标点。因此,把机器人在Δt时走的长度L当成计算得出的偏差。
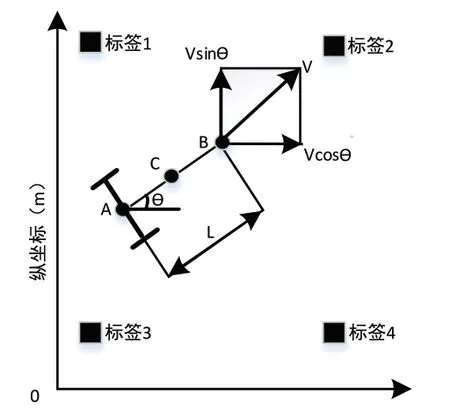
图1 机器人实时定位模型
在图1中,机器人运动以XOY为全局坐标系,在全局坐标系下,机器人的姿态角为θ,多传感器机器人x轴和y轴的位置坐标为Lx和Ly,多传感器机器人的位姿向量设置为(Lx,Ly,θ)。从多传感器机器人实时更新的定位反馈回应中运用其中最大的四个定位点,并且以A(L1,L1,θ)为基点开展之后的计算,点1为,点2坐标为,点3坐标为,点4坐标为。多传感器机器人在Δt时间内以v为前进速度的运动学方程如式(1)所示:

由于在定位过程中,机器人处于平面运动状态,须满足纯滚动和不滑动两个约束条,其约束条件可如式(2)所示:

则机器人的姿态角θ计算公式如式(3)所示:

式(3)中,θ,不是完全独立的。当机器人在实践启动情况里,因为使用了平均值的计算手段,所以要求多传感器机器人从P(t1)到P(t2)需要在固定的Δt时间内完成,进行精准定位之后的具体地点大致是(t2-t1)/2时ΔRSSI对应的点,机器人实时定位的偏差会受到无线信号状态的作用,得到机器人运动到t2的实际坐标如式(4)所示:

多传感器机器人在空间的姿态变换设定为是分别绕三个轴旋转所获得的。选择的旋转顺序不同时,会有不同的分解方式[4]。目前常用的分解方式为欧拉角。即机器人的位姿变换可用ZYX轴顺序旋转获得,即:

式(5)中:R表示多传感器机器人旋转矩阵,γ表示多传感器机器人翻滚角,ψ表示多传感器机器人航向角。
为判断原始数据点un是否属于目标特征直线,对原共线判定准则修订如式(6)所示:
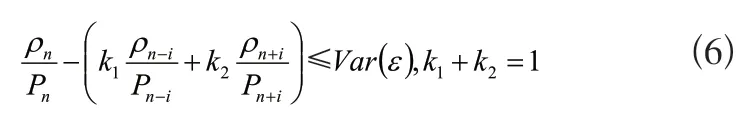
式(6)中:ρn、ρn-i、ρn+i表示数据点,un、加权系数是k1、k2,标准差是un-i、un+i,设定阈值是Var(ε)。当un和它临近的存在2i个点共线,那么un一定是遵循着共线准则的。
线段特征的收集成效会被ε、k1、k2与i这写共线判断依据的精准参数而作用。从整体来看,如果把共线准则的要求执行得过于严苛,会导致具有同样特征的直线分割成几段不同的线条,也就是会使特征在传感器测量噪声的强大干扰下变得片段化。过于随意便会导致特征的夸大化,造成一定的错误判断和差距,得到不符合本体的数值。因为这个计算准则的收集一你那个因素很多,运行附近的环境也是多种多样,所以这个容易就受到个别参数的干扰,因此,需要选择合适的程度,把可能出现的种种情况都考虑进去。
1)选取参数i
i的选择的影响因素很多,其中最影响最大的就是数据点的密集程度,如果数据点十分密集的时候,i取值过于小会导致共线的判断依据宽松,且ρn、ρn+i、ρn-i之间的差距过于小;反之i取值过大容易导致错误判断。因此,i的选择要根据实际状态来看i,如果数据已经提前进行了整理,i的选择可以适当偏小,因为如果导致了特征的线段变短,那么之后可以的操作中还可以将线段进行整合或者是重新分配便于改动。
2)选取参数参数k1、k2
共线数据un-i与特征判断数据un+i对un是否属于该特征线段判断影响的对应点是k1与k2。k1大轻易造成判断依旧过于严苛,而k2大轻易造成错误判断。因此k1选择的依据可以参照参数i来进行,则为k1的选择可以大于k2。
3)阈值ε的选择
阈值ε的取值有着非常重要的意义,并且距离dn作用于阈值ε的取值。一般情况下,阈值ε会随着dn的的增大而增大,所以,要想使阈值ε达到上面的详细要求,阈值函数可以依据实践状态来调整改进分段函数ε=W(dn),
其具体形式如式(7)所示:

式(7)中,d1=0.6,d2=2.4,ε1=0.01,ε2=0.012。
2 多传感器机器人定位信息挖掘
定位信息与处理即对多传感器机器人行为信息和IMU信息进行处理,为机器人线程规划及定位信息挖掘提供依据。假设预测值为Z,估计量为X,则在X下Z的概率密度函数表示为f(Z/X),若函数∏f(Z/X)为最大取值时,将参数值当做是X的估计值,如式(8)、式(9)所示:
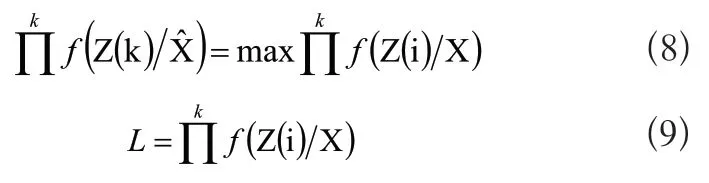
式(9)中,L为最大似然函数。当式中X为最大值时,其L值也达到最大,则表明为X的极大似然估计。所以,求取X的极大似然估计值的问题可转变成求取似然函数最大值的问题,方便多传感器机器人定位。在进行预处理的过程中,将实时采集到的多传感器机器人定位信息与离线状态构建的信息库中的信息相对比[5],找到相匹配的值,取μ=e_rssi_i,σ=d_rssi_i,利用正态分布的概率公式,计算pi(x.y)即为rssi_AP_i与信息库中的概率如式(10)所示:
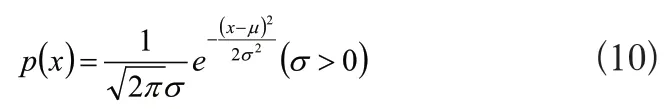
计算各个多传感器机器人定位点在信息库中出现的概率分布,将每个点的所有概率相乘,得到该多传感器机器人定位的总分布概率。
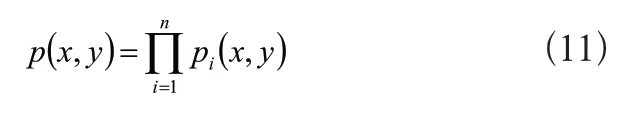
式(11)中,n为信息库中所有多传感器机器人定位信息量。在之前收集到的p(x.y)参考信息概率经过计算得到结果之后,基于此,在机器人定位坐标信息中选择里面最大的p(x.y)值所相对应的具体信息。
基于总分布概率,确定状态转移概率p(xt|ut,xt-1)f为具有随机高斯噪声的线性函数,如式(12)所示:

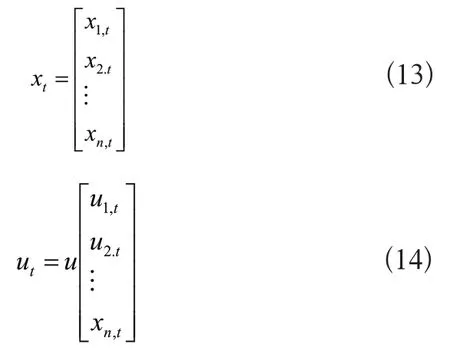
式(12)中:矩阵是At、Bt,接下来用状态乘At,控制向量乘Bt,然后用这些参数和状态转移形成线性关系;xt和xt-1为状态向量,t时刻的控制向量表示为ut,xt和ut的形式如式(13)、式(14)所示:
首先通过上述处理得到多传感器机器人定位信息,这些定位信息是一组在x轴和y轴坐标位置点组合[6]。其结合多传感器信息及预处理结果,得到机器人当前的定位信息值,将机器人当前定位的信息与输入值进行对照,可以获得对照之后的比较差值[7],得到比较差值之后,矫正值就容易得出了,可以利用对照后的差值继而使用深度估计法进行信息计算就可以得出,然后可以对多传感器机器人的定位信息数据调整改进,如式(15)、式(16)所示:

式(16)中,r(k)为标准设定值,c(k)为当前机器人的定位信息,e(k)为比较差值。比例系数是Kp,积分系数是ki,第k个采集时刻的输出量是u(k),微分系数是Kd,则k-1个采集时刻的输出量如式(17)所示:
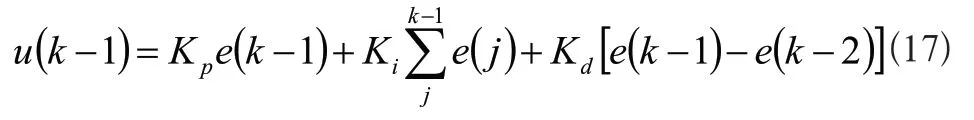
基于输出量对多传感器机器人定位信息进行融合,实现对机器人输出量控制,而不对输入量控制[8],进而适应输入信号的频繁变化规律,避免出现剧烈振荡,影响对机器人定位信息准确度,基于此设计的微分器为:

在微分器控制过程中,假设视觉机器人定位信息存在一定约束条件:

式(19)中,ϑd表示视觉机器人位置向量;表示视觉机器人速度向量;ϑ′表示视觉机器人加速度向量;ϑ表示标准数值。
基于此,计算控制器输入与微分器输入之和,如式(21)所示:

式(20)中,αPI表示线性控制器的输入值;αD表示微控制器的输入值。在控制目标的一阶微分环节上,通过转换控制目标的转移函数,添加抵抗空气流产生扰动的性能,可得到表达式如式(21)所示:


式(22)中,μ、κ分别表示变换分母、分子系数;y表示输出信号。
通过参数整定后,可以离散处理视觉机器人变量,使经过微分线性控制的数值变化较小,变化幅度在-1和1之间,避免输入过程出现剧烈波动,影响控制效果。设定随机变量为Sh,确定多传感器机器人定位信息的先验概率p(Sh),计算后验概率的分布结果为p(Sh|D),计算公式如式(23)所示:

式(23)中,p(D)表示得到的正规化常数;p(D|Sh)表示挖掘的边界似然值。
在确定激活函数之后,实现参数独立,保证不同参数完整性后,得到多传感器机器人定位数据集,分析机器人定位信息集中各个不同变量之间的独立性关系,从而得到机器人定位信息特征。分析机器人激活函数,将所有的多传感器机器人关键定位特征进行挖掘,其计算公式如式(24)所示:

从上面的数据可以看出,可以达成多传感器机器人在定位信息的挖掘,其中的重要原因就是使用定位,获取多传感器机器人定位信息,并进行实时挖掘。
3 仿真实验与结果分析
3.1 实验设置
为验证本文提出的多传感器机器人定位信息挖掘方法的有效性,搭建机器人平台和实验所需环境。仿真环境使用URDF文件实现,URDF作为机器人的一种描述文件,在Gazebo中大量使用。利用仿真环境调试方法稳定性高,修改调试方便,节约成本,还能够加深对方法的理解。但实际运行环境更复杂,在加上真实传感器不可能避免的存在随机误差,对定位信息挖掘方法提出了更大的挑战,因此需要搭建实体机器人实验凭条,进一步验证所设计方法的有效性。实验采用的机器人如图2所示,机器人参数如表1所示。

图2 机器人
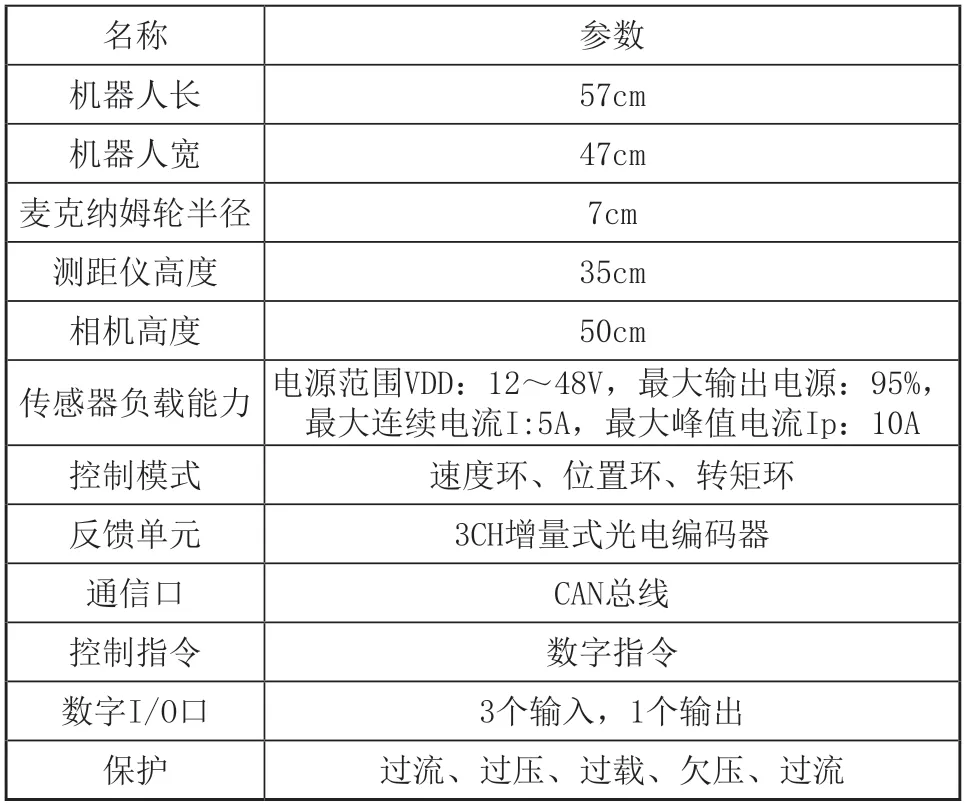
表1 机器人参数
服务器使用的配置为Windows10操作系统,8.00GB内存,64为操作系统,数据库软件为微软开发的SQL service2020。
3.2 实验指标
实验中以多传感器机器人定位信息挖掘精度和挖掘时间开销为实验指标。
1)定位信息挖掘精度:该指标是衡量多传感器机器人定位信息挖掘的重要性能指标,其计算公式如式(25)所示:
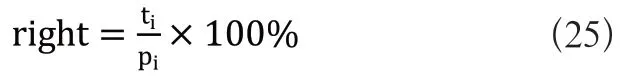
式(25)中,代表挖掘的实际数据量,代表挖掘数据的总量。
2)定位信息挖掘时间耗时:该性能指标反映多传感器机器人定位信息挖掘的速度,其计算公式如式(26)所示:

式(26)中,代表实际挖掘数据的用时,代表理想的挖掘所用时间。
3.3 实验结果分析
3.3.1 挖掘精度分析
多传感器机器人定位信息的挖掘精度可衡量方法的优势,本文实验中对比了本文方法、文献[3]方法以及文献[4]方法对样本多传感器机器人定位信息进行挖掘,为了保证实验的精度,对样本信息进行挖掘时均进行了多次迭代速度,且得到的实验结果均为迭代后的均值,三种方法对样本信息挖掘的精度结果如图3所示。

图3 挖掘精度对比结果
分析图3中数据可以看出,随着挖掘时间的不断改变,采用本文方法、文献[3]方法以及文献[4]方法对样本信息进行挖掘的精度存在一定差异。当挖掘时间为40min时,本文方法的挖掘精度约为96%,文献[3]方法的挖掘精度约为70%,文献[4]方法的挖掘精度约为56%;当挖掘时间为60min时,本文方法的挖掘精度约为98%,文献[3]方法的挖掘精度约为78%,文献[4]方法的挖掘精度约为80%;对比三种方法可以看出,本文方法的挖掘精度最高,这是由于本文方法进行定位信息挖掘之前对多传感器机器人定位信息进行预处理,并对其冗余进行删除,降低了干扰项的存在,提高了本文方法的挖掘精度。
3.3.2 挖掘时间开销分析
在保证定位信息挖掘精度的基础上,进一步分析了本文方法、文献[3]方法和文献[4]方法在进行信息挖掘时的时间开销,得到的结果如图4所示。

图4 挖掘时间开销对比结果
分析图4 中数据可以看出,在相同实验条件下采用三种方法对样本信息进行挖掘的耗时存在一定差异。当信息量为750bit时,本文方法的挖掘时间开销约为46.5s,文献[3]方法的挖掘时间开销约为68.3s,文献[4]方法的挖掘时间开销约为48.7s;当信息量为100bit时,本文方法的挖掘时间开销约为24.5s,达到最小值;文献[3]方法的挖掘时间开销约为63.2s,文献[4]方法的挖掘时间开销约为48.9s;相比之下所提方法的挖掘时间开销较短均要小于文献[3]方法、文献[4]方法,实现了快速的挖掘,进而提升了方法的有效性。
3.3.3 内存占用率对比
以内存占用率为指标检验不同方法的资源利用情况,以此来反映不同方法的实用效果。实验中,不同方法的内存占用率变化情况如图5所示。
通过分析图5所示结果可知,对于三种不同方法,内存占用率均随着实验迭代次数的增加而增加。其中,文献[3]的内存占用率最大值为57.38%,文献[4]方法的内存占用率最大值为45.32%,而本文所提方法的内存占用率最大值仅为28.4%。相比之下,所提方法的内存占用率更少,说明在实际应用过程中,该方法的可行性更高。
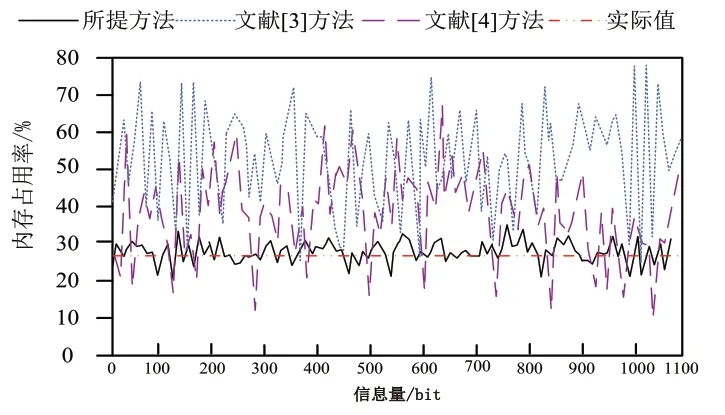
图5 内存占用率对比结果
4 结语
针对多传感器机器人定位信息由于存在定位信息量大、干扰因素多等原因,导致挖掘精度差、耗时长、内存占用率高的问题,提出了新的挖掘方法。经实验验证,采用本文提出的基于SLFN的多传感器机器人定位信息挖掘方法,具有以下优势:
1)采用所提方法挖掘精度,相比文献[3]方法、文献[4]方法提高了23%、29%。
2)采用所提方法挖掘耗时,相比文献[3]方法、文献[4]方法降低了30.25、13.3s。
3)采用所提方法内存占用率相比文献[3]方法、文献[4]方法降低了28.98%、16.92%。
猜你喜欢
一重技术(2021年5期)2022-01-18
企业文化(2020年8期)2020-06-03
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
电子制作(2018年11期)2018-08-04
华人时刊(2016年16期)2016-04-05
安阳工学院学报(2015年2期)2015-09-26
电脑爱好者(2015年21期)2015-09-10
移动通信(2014年14期)2014-09-10
电脑爱好者(2009年13期)2009-07-07
