
基于文本分析的标书综合评估模型①
2022-06-29 07:49任杰
计算机系统应用 2022年6期
任 杰
(中国水利电力物资集团有限公司, 北京 100043)
近年来, 我国的社会发展与经济建设取得了举世瞩目的成绩. 社会的发展过程离不开工程建设, 工程建设招标和投标是在市场经济条件下进行工程建设的一种经济活动, 其实质是一种市场竞争行为. 在甲方市场的条件下, 招标人可以通过招标活动在众多投标人中选定报价合理、工期较短、信誉良好的承包商、供应商来承担工程建设任务[1]. 工程建设的招投标不仅具有高报价、高复杂性和高竞争性等问题, 还存在人工评标效率低和识别围标、串标行为难的问题[2,3]. 这些问题都在不同程度上阻碍了工程的建设和企业的发展,同时也给招标投标的工作带来了不小的挑战. 因此招标投标的各个环节是否能够遵守高效、客观、科学、公平、公正、公开的原则至关重要[4].
目前招投标领域正在由纸质化招标向电子化招标的方向发展, 这也为利用计算机分析电子化招投标文件提供了可能. 首先, 利用计算机对标书进行评估, 可以实现对标书的预选, 为人工评分提供了参考和客观依据; 其次, 计算机的应用与分析为构建电子化招投标系统和标书文本分析工作提供了条件; 最后, 利用计算机分析招投标过程信息和背景信息, 可以为识别围标、串标行为提供参考. 但是目前招投标实践中, 标书评估主要还是依靠人工评标, 缺少全面、科学的技术辅助手段. 招投标研究领域中, 利用大数据分析标书并识别围标、串标的技术仍然不完善, 缺乏通用性. 这主要是因为投标过程具有高复杂性, 现有的方法仅仅针对一个或两个指标进行定量分析, 这显然是不够的. 标书文本的分析不仅要考虑内部、外部等多个指标, 还需将定量分析与定性分析相结合, 从而实现更加全面、完整、科学的标书评估.
随着深度学习在NLP 领域的发展, 利用NLP 进行自然语言理解(natural language understanding, NLU)和自然语言生成(natural language generation, NLG)已经越来越普遍[5]. 文本是语言信息的主要载体, 利用文本信息进行挖掘并提取关键信息, 对于人们快速准确地获取文本内容具有重要的作用. 语义相似度计算(semantic textual similarity)是联系文本信息表示和潜在上层应用之间的纽带[6], 重复率常用于大型网页和巨量文本的量化计算[7,8]. 在相似度和重复率的实践上, 目前Simahash 算法和Shingling 算法[9]被认为是当前最好的算法之一[10,11]. 采用这两种算法计算投标文件间的相似度与重复率, 可以为标书文本的评估和识别围标、串标行为提供量化指标.
本文提出了基于文本分析的标书评估模型, 从定量分析和定性分析两个方面分别处理标书文本, 实现对标书的综合评估. 本文第1 节介绍评估模型的框架和基本思路, 第2 节介绍涉及到的关键算法与改进, 第3 节介绍模型的评估指标及计算方法, 第4 节进行实际案例分析, 第5 节总结评估模型, 提出不足与展望.
1 评估模型框架
当前招投标研究领域主要存在两个主要问题:(1) 识别围标、串标行为主要依赖评标现场进行人工识别和判断, 但是评标现场时间有限, 并且围标和串标行为往往不易发现, 缺少有效的机器辅助手段; (2) 当前评标工作中, 利用计算机分析标书时缺少有效合理的评价指标和评价方法, 现有评价指标往往侧重于对少数几个方面进行定量分析, 缺少结合定量分析与定性分析的全面评价体系.
本文提出了基于文本分析的标书综合评估模型,模型通过基于定量分析的文本评估和基于定性分析的文本评级实现对标书的综合评估. 文本评估模型是通过定量分析计算5 项指标及权重得到标书评分, 通过评分对标书进行排序, 为实际评标工作中的标书评分提供参考. 文本评级模型是通过定性分析利用7 项指标分别对标书文本进行评级得到评级结果, 通过评级结果识别投标企业是否疑似出现围标、串标行为, 模型识别再结合人工核查确认最终的识别结果, 模型为评标工作中识别围标、串标行为提供参考. 文本评估和文本评级的结果分别实现了对标书的定量计算和定性分析, 两者结果综合集成后即可实现对标书的综合评估, 标书评估模型框架图见图1.
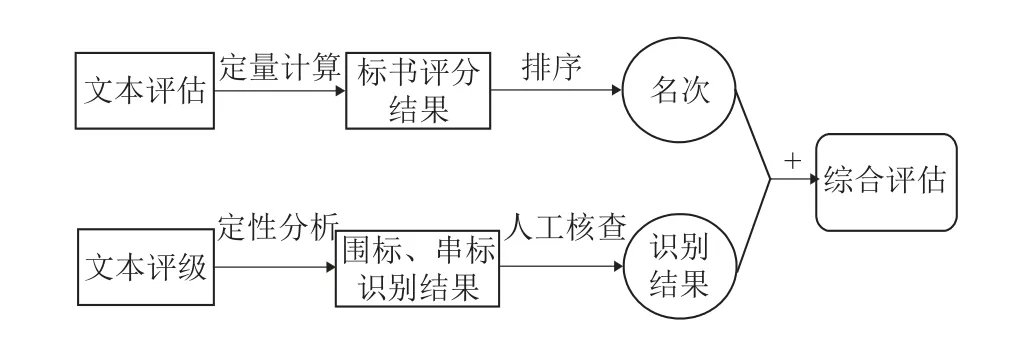
图1 标书评估模型框架图
本文的研究语料来源于中国水利电力物资集团有限公司工程建设中的招投标文件, 投标文件通常包含投标函部分、商务标部分和技术标部分. 由于投标文件是非结构化文本数据, 而且文件中不仅含有大量的文字信息, 还有表格和图片信息. 这些非结构化信息给开标现场的评标带来了不少困难, 尤其是投标企业出现围标、串标行为时, 评标专家难以在评标现场短时间内进行定量或定性识别. 《中华人民共和国招投标法》《招投标实施条例》《招投标实施细则》等法律法规规定了对出现围标、串标行为的处罚条例, 但是缺少于围标、串标行为的界定标准.
在文本分析方面, 构建招投标过程文件查重对比模型, 通过基于NLP 的权重改进的Simhash 算法和Shingling 算法对投标文件进行分析, 得到投标文件之间的相似度和重复率. 再通过匹配和对比得到招标文件目录的匹配度、资质与报价的一致性和投标价格的上(下)浮率指标. 这些指标通过定量分析为评标专家的评标工作提供更加客观、准确、科学的依据, 同时也为识别围标、串标的行为提供了参考.
在行为分析方面, 构建异常检测模型, 针对投标企业在投标过程中出现的异常行为进行分析, 从而识别企业是否存在围标、串标的嫌疑. 其中异常行为包括:故意废标、开标前几家企业同时撤回标书、不同企业的保证金出自同一账户、投标文件签名字迹一致、标书出现明显的错误等.
在背景分析方面, 构建企业资质审查模型, 首先建立基于知识图谱的文本知识库, 实现知识的智能存储、智能关联、智能推理, 通过企业与项目之间的关系, 形成网状的知识结构, 利用知识问答、实体查询、关系查询、逻辑推理等功能, 实现对企业关联度的分析计算. 然后利用基于OCR 技术的企业资质审查模型, 对投标企业资质进行审查, 通过OCR 识别自动抽取投标文件中的企业资质等证书图片信息, 获取证书的名称、编号和印章信息, 将证书名称和编号上传至查验网站进行真伪查验, 再对印章信息进行真实性查验, 确定证书的真实性和有效性. 然后利用政府的公开信息查询企业是否出现违规、失信等情况, 得到企业的信用度.
基于文本分析的标书综合评估模型在传统的评估指标上加入文本方面、行为方面和背景方面的综合分析, 构成了更加全面、客观的标书综合评估模型, 模型的评估指标框架图见图2.

图2 评估指标框架图
2 算法介绍与改进
标书文本分析的核心技术为文本相似度和重复率计算, 文本相似度是定性分析两个文本是否具有相似性, 文本重复率是定量计算两个文本的重复程度.
2.1 改进的Simhash 算法
传统的文本相似度是通过计算文本特征词所构成的特征向量的夹角余弦值实现的, 面对长文本, 传统的方法由于整个特征向量的维度高, 导致计算的时间和空间复杂度都很高. 面对几万字的标书, 传统的相似度计算方法效率过低.
Simhash 算法解决了无法处理长文本的问题, 并常常被用于实践, Simhash 是一种局部敏感哈希, 局部敏感是指假如两个字符串具有一定的相似性, 这种相似性在哈希之后仍然会被保持, 这种特性常用于海量文本之间的相似度计算, 最早被Google 应用于对海量文本进行去重处理[12]. Simhash 是一种降维的思想, 它将高维的向量映射成低维的向量并得到一个Simhash 值,即一个n位的指纹, 而相似文档的指纹之间只存在少量的不同, 因此通过计算n位指纹的海明距离即可判断文本之间的相似度[13,14].
Simhash 算法是由Manku、Jain、Sarma 3 位Google 工程师提出并通过实验验证了采用64 位的指纹时, 文本间的海明距离取k=3作为阈值来判断文本的相似是合理的. 由于参数k的取值直接影响算法的准确率和召回率, 这两个指标大致呈现反比关系, 实验发现当k=3时, 算法的准确率和召回率均在75% 左右,并且达到了较好的均衡[15], 适用于标书文本的相似度计算. 除此之外, Simhash 算法通过降维的思想将高维特征向量映射成唯一的二值Simhash 值, 降低了计算复杂度, 提升了算法效率.
传统的Simhash 算法在权重计算时通常直接设置为1 或者特征词的词频, 这就无法体现出词汇的分布特征, 导致信息的丢失和准确率降低. 为了解决传统Simhash 算法中权重计算不充分的问题, 受文献[16]的启发, 本文在权重计算中使用词频-逆向文件频率(TF-IDF)和信息熵的基础上, 加入了特征词偏向性权重, 并人为判断特征项是否能够作为算法特征项进行计算, 最终形成了基于熵-特征词偏向性加权的Simhash算法, 具体计算方法如下.
(1)词频-逆向文件频率定义为:
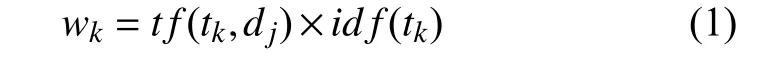
其中,t f(tk,dj)代表词频, 是指特征项tk在文本dj中的词频,id f(tk)代表逆向文件频率, 是指语料库中文件总数与出现特征词tk的文件数量的比值的对数.
(2)左右信息熵和熵量分别定义为:

其中,w为单词,Hl(w)为单词的左熵,P(aw|w)为单词左侧出现不同词的频率,a表示与w结合的词.Hr(w)为单词的右熵.Hk(w)为熵量.
(3)特征词偏向性权重定义为:

其中,ai是特征项所属的标书部分(标书通常分为: 投标函部分、商务标部分、技术标部分)的权重, 该权重是通过对评标专家对各部分重要性排序通过层次分析法计算获得.
(4)基于熵-特征词偏向性加权公式:

上述公式的物理意义是: 特征项tk在文档dj中出现次数越多, 在所有文档中出现次数越少, 信息量越大,所属标书部分重要性程度越高, 则其对应的权重越大.
(5)特征项的二次选择
经过上述步骤计算出来的特征项及对应的权重在带入Simhash 算法进行计算之前, 需要结合标书文本的特殊性和本次投标所属行业关键信息的专业性利用预定的阈值进行人工二次选择, 通过二次选择提高特征项的准确性和代表性, 从而提高Simhash 算法的计算效果.
(6) Simhash 值和海明距离的计算
Simhash 算法主要有2 个主要步骤: 计算simhash值和计算文本间的海明距离.
1) 计算Simhash 值.
首先, 对于给定的标书文本, 利用停用词表过滤掉符号、助词、语气词等无效字符, 然后通过分词库进行分词, 将文本转换为一些特征词的集合(a1,a2,···,an),集合中各元素的权重(w1,w2,···,wn)为该特征词在文本中的词频. 然后, 通过hash 计算将集合中每个特征词映射为长度为n的二进制数hash 值[17], 再将二进制数中的0 变为−1, 并乘以权重. 最后把乘以权重后的特征集合按位累加, 得到一个n位的文本特征值(即文本的指纹). 遍历文本特征值的每一位, 当该位值大于0 时赋值为1, 小于等于0 时赋值为0, 即可得到降维后的文本的Simhash 值, 算法流程图见图3.
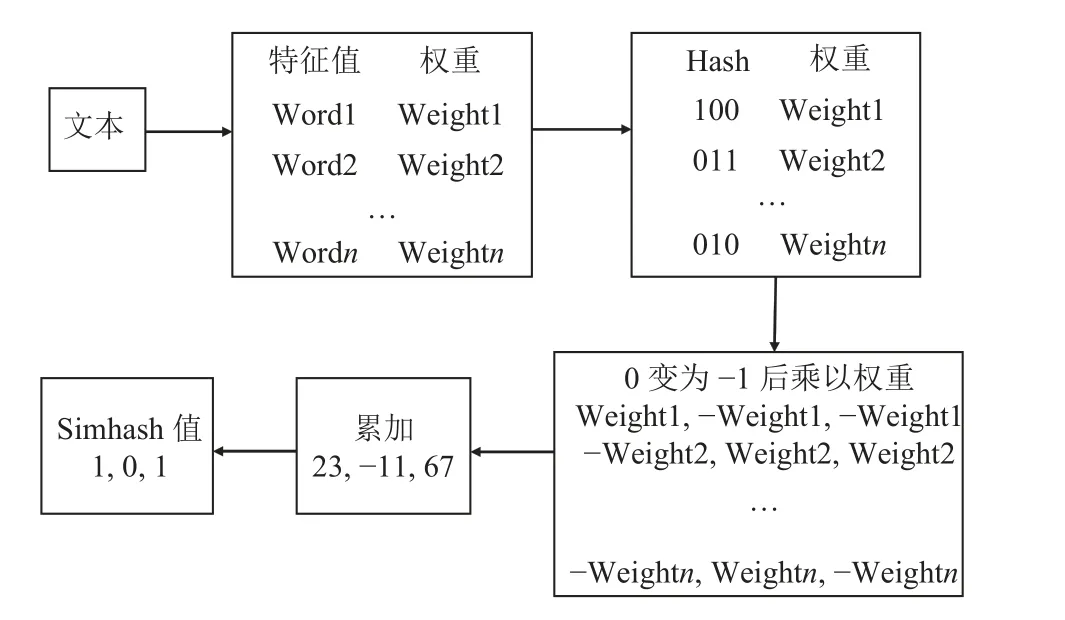
图3 Simhash 算法流程图
2) 计算海明距离(Hamming distance).
由于相似文本的指纹信息只有少量的不同, 因此可以通过计算文本的指纹信息即Simhash 值的相似程度来判断文本的相似程度. 海明距离表示两个文本Simhash 值每一个索引位置值不同的数量, 假设两个文本(a1,a2,···,an)与(b1,b2,···,bn)的Simhash 值长度为n,i表示第i位, 则文本a和b之间的海明距离计算公式为:
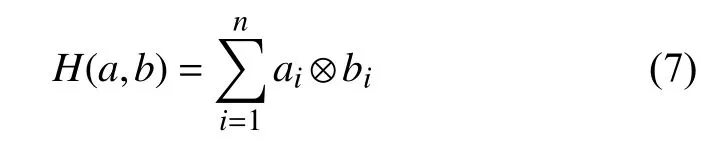
其中, ⊗表示异或运算.
Simhash 算法中, 首先将文本信息映射得到指纹信息, 再通过计算海明距离H(a,b)来判断相似度. 在实践中, 通常认为两个文本的海明距离H(a,b)≤3时文本是相似的, 本文采用H(a,b)=3作为判断相似性的阈值.海明距离H(a,b)是文本评级模型的指标之一.
2.2 Shingling 算法
Shingling 算法是一种降低特征维度去检测文本相似性的方法[18]. Shingling 算法是将文本的相似性转化为词语集合的相似性, 首先将文本M划分成一些大小为w的连续子序列的集合(w1,w2,···,wn)称为S(M,w),再通过两个集合的交集除以并集的计算方式表示文本的相似性[19,20], 则文本A和B的相似性定义为:
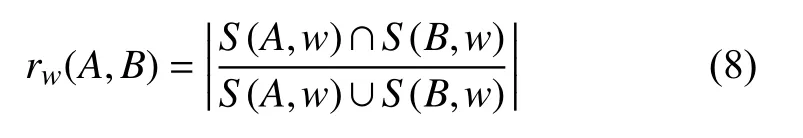
式(8) 得到的rw(A,B)是文本的相似系数即文本A和B的重复率, 重复率是标书文本评估的指标之一.
3 评估指标
基于文本分析的标书综合评估模型由文本评估模型和文本评级模型组成, 两者的计算结果共同实现了对标书的综合评估.
3.1 文本评估模型
在传统的评标中, 通常是评标专家对投标文件的3 个主要部分: 商务标部分、技术标部分和报价部分进行打分, 每部分得分与权重相乘后累加即可得到专家评分结果. 在这个过程中, 围标、串标行为的识别往往依靠评分专家的主观判断, 缺少客观的评定指标.
基于文本分析的标书综合评估模型分为标书文本评估和文本评级. 文本评估模型是在传统的评分指标“商务标部分X1”“技术标部分X2”“价格得分X3”的基础上加入了基于Shingling 算法计算得到的标书文本的“重复率X4”和投标文件要求的招标文件目录与真实目录的“匹配度X5”. 其中X1、X2得分是参考专家经验计算得到的,X3、X4、X5是模型评分.
本实验中标书的评标基准价采用平均值法, 评标基准价的计算方法[21]为:
C(评标基准价)=A(所有有效标书的平均价格) (9)
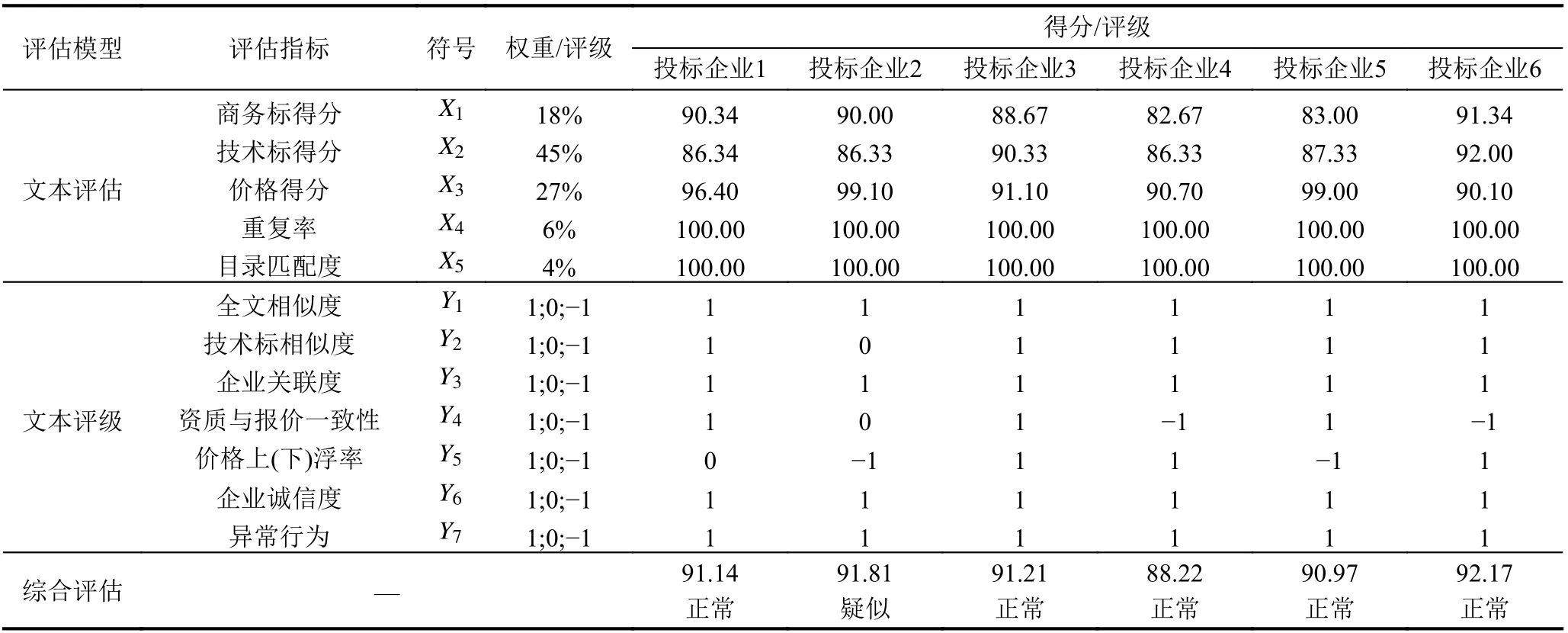
价格得分X3的计算方法是: 当投标报价=C时, 该标书的价格分为100 分; 投标报价>C时, 每高于评标基准价1%, 扣1 分; 投标报价 重复率指标X4的计算方法是: 当重复率F≤n%时,得100 分; 当重复率F>n%时, 每高于重复率1%, 扣2 分, 本文取n=5. 当重复率得分<0 时, 记0 分. 目录匹配度指标X5是把招标文件对于投标文件的要求目录中的各级标题提取关键词, 利用关键词与真实目录进行字符串匹配, 匹配度的计算公式为: 匹配度X5的计算方法是: 当P=100% 时, 得100 分;当P<100%, 每少1%, 扣5 分. 当匹配度得分<0 时, 记0 分. 为了获取到指标Xi在评标过程中所占的权重, 本实验通过调查问卷的方法收集了5 位评标专家对5 个指标中两两相比时的相对重要性排序, 然后通过层次分析法(analytic hierarchy process, AHP)获取了指标Xi对应的权重ai. 文本评估得分的计算公式为: 文本评估模型通过对5 项指标进行定量计算, 得到了指标权重, 并进一步得到各标书的得分. 文本评估模型的指标权重是基于评标专家的经验, 采用半定量的层次分析法确定. 文本评估模型的各项指标综合了传统评估指标、重复率和目录匹配度, 是一种更加全面的评价方法, 具有一定的通用性. 文本评估模型的指标列表见表1. 表1 文本评估模型的指标列表 在传统的评标中, 招投标行为是否出现围标、串标行为往往是通过评标专家现场进行人工识别, 一方面效率较低且难以发现围标、串标行为的有效证据,另一方面, 人工难以有效的挖掘标书的深层次信息. 文本评级模型识别围标串标行为的方法是通过7 个指标对标书分别进行评级, 进行风险等级划分, 最终综合7 个评级结果, 通过综合评级式(18)得到最终的标书评级, 7 个指标分别是: 利用基于权重改进的Simhash 算法得到的两个标书文本全文之间的相似度指标Y1和标书文本的技术标部分(技术标是投标的关键性内容) 的相似度指标Y2. 定义H(A,B)(即海明距离)为标书文本A和B之间的相似度, 则Y1和Y2评级公式为: 基于知识图谱的投标企业关联度指标Y3, 通过外部系统中的知识图谱获取两个企业间工程建设项目、资金等信息往来情况. 定义C(A,B)为企业A和企业B的项目往来次数, 则Y3的评级公式为: 投标企业的企业资质与投标价格的一致性指标Y4,通过投标企业的标书获取报价、总资产、已完成同类项目数量, 定义投标企业的报价排序为a、企业总资产排序为b和已完成同类项目数量排序为c, 则Y4评级公式为: 投标价的价格上(下)浮率指标Y5, 文献[22]验证了围标、串标的企业通常由一定数量的相同或相似报价的企业和一定数量的远低于正常报价的企业共同组成, 这些企业从价格方面使得评标基准价向组织围标、串标的企业靠近. 本实验的投标价A相对于基准价C价格上(下)浮率为F(A,C), 则Y5的评级公式为: 基于政府信息公开的投标企业诚信度指标Y6, 通过政府公开信息查询网站获取投标企业的社会信用情况、资金状况和违法违规情况的负面记录数量J(A),并进行评级,Y6的评级公式为: 基于异常行为的指标Y7, 异常行为是指: 文件混装、未按照要求撰写投标文件等故意废标的情况; 不同标书的签名字迹一致; 截标前多家企业同时撤回标书; 不同企业的投标保证金出自同一账户等. 企业A异常行为的数量记为M(A), 其Y7评级公式为: 其中,R(·)表示所有可能的情况中使得括号内条件成立的情况的个数. 文本评估模型的创新之处在于该模型考虑了文本层面的分析、企业关联分析、背景分析与行为分析等因素, 通过7 个指标的评级结果综合分析得到识别围标串标的结果, 为围标、串标行为的检测提供了支撑,文本评级指标列表见表2. 表2 文本评级模型的指标列表 标书评估实践中, 最重要的两个步骤是对标书进行评分得到排序和识别围标、串标行为, 从而确定最终入围的标书. 但在技术研究中, 往往只少数文献对某些方面进行了分析, 并未考虑到标书分析的全面性和客观性问题. 本文提出的标书评估模型分别从文本评估(指标X1–X5)和文本评级(指标Y1–Y7)两个方面进行标书的定量计算和定性分析. 文本评估(X项)是在传统的评分指标中加入了“重复率X4”和“目录匹配度X5”, 并利用层次分析法获得指标对应的权重, 从定量计算方面实现对文本的评分, 确认投标企业的标书得分排序. 文本评级(Y项)是利用7 项指标的定性评级结果判断投标企业是否出现疑似围标、串标的行为, 结合人工进行核查, 为文本评估(X项)提供围标、串标的参考, 两者共同实现对标书的综合评估.综合评估本质是将两个不同方面的计算结果进行结合, 但是这种结合又加入了人工的核查, 增大了模型的准确性和可靠性. 本节将中国水利电力物资集团有限公司工程建设中两个招投标项目的文本和数据作为实际案例数据进行实验, 通过基于文本分析的标书综合评估模型的计算结果与真实结果进行对比, 展示本文模型的有效性. 在文本评估中的指标X4(重复率), 文本评级中的指标Y1(全文相似度)、Y2(技术标部分相似度)、Y3(企业关联度) 是描述两文本之间的关系, 当某项目有A1,A2,···,An共n个企业进行投标, 在计算Ai的这4 个指标时, 要将Ai与其他n−1个企业进行比较, 共有n−1个结果, 结果应当选择数值属性最不利于该企业的实验数据作为Ai在该指标的数据值. 此外, 实验数据中的招标项目的投标企业个数通常为4–8 个, 所以计算的复杂度是合理的. 实际案例数据分别采用“某电厂入厂次干道”项目和“某电站公用及辅机控制设备”项目的案例数据. “某电厂入厂次干道”招标项目共有4 家企业进行投标, 即共有4 份标书文本. 经过标书文本的数据处理得到“某电厂入厂次干道”项目的指标数据与综合评估结果, 见表3. 其中有3 家企业的标书被识别为“正常”, 1 家企业的标书被识别为“疑似围标、串标”. 投标企业4 被识别为“疑似围标、串标”, 这是由于投标企业4 的文本评级结果中有两项评级为“–1”, 根据文本评级式(18), 故被识别为“疑似围标、串标”. 表3 “某电厂入厂次干道”项目的指标数据与综合评估结果 “某电厂入厂次干道”项目的招标文件规定了根据评标分数选择评分最高的3 家企业作为“晋级”企业.实验数据也采用评分排序前3 的企业为“晋级”企业,进入候选标书名单. 经过综合评估结果与专家评标结果和评标报告进行对比, 发现实验评分结果与专家评标的真实评分结果吻合, 识别围标、串标结果为评分结果提供参考, 为人为识别围标、串标行为提供依据,实验结果见表4. 表4 “某电厂入厂次干道”项目模型数据和真实数据表 对“某电站公用及辅机控制设备”项目标书文本进行处理, 项目共有6 家企业进行投标, 经过标书文本的处理, 最终得到“某电站公用及辅机控制设备”项目的指标数据与综合评估结果分析, 见表5. 经过综合评估结果与专家评标结果和评标报告进行对比, 发现实验结果与专家的真实结果吻合, 实验结果见表6. 表5 “某电站公用及辅机控制设备”项目的指标数据与综合评估结果 表6 “某电站公用及辅机控制设备”项目模型数据和真实数据表 通过2 个项目共10 个标书的案例分析, 并将实验结果与真实结果进行对比, 发现通过标书综合评估模型的计算结果与真实结果吻合, 表明了基于文本分析的标书综合评估模型的在本节2 个项目案例分析上的有效性. 该模型的评估从定量计算和定性分析两个方面分别实现了文本评估和文本评级, 两者的结果共同构成了综合评估的结果. 在实践中, 文本评估模型为专家打分提供数据支持, 提高了人工评标的效率;文本评级模型能够为招投标过程中围标、串标行为的识别提供依据, 大大提升识别围标、串标行为的效率和效果, 识别为疑似或高度疑似存在围标、串标行为的企业标书需进行人工核查, 得到围标、串标行为的识别结果. 招投标是工程建设中的重要环节, 高效地识别围标、串标行为是招投标过程的一大难题, 在实践领域人工识别围标、串标行为效率较低、成本高, 在研究领域缺少全面、完善的评估方法. 本文的创新点在于提出了融合文本评估和文本评级的综合评估模型, 模型基于定量计算和定性分析两个方面进行标书处理,同时将Shingling 算法和改进的Simhash 算法用于标书文本分析之中. 通过建立基于文本分析的标书综合评估模型, 提取文本的数据信息, 对标书建立文本评估模型和文本评级模型, 实现了对标书的定量和定性的分析, 进而实现对标书的综合评估. 该模型不仅能够为标书评估提供更加客观、合理的得分依据, 为识别投标企业围标串标行为提供有效的参考, 还能提高标书评分的效率. 除此之外, 也能为构建电子化招投标系统和建立标书分析模型提供条件与准备. 基于文本分析的标书综合评估模型对工程建设项目中的标书评标工作具有重要的意义, 基于标书数据形成的知识图谱也为电子化招投标中属性关系的建立和未来的深度探索提供有力的支撑. 基于文本分析的标书综合评估模型仍可在以下几个方面进行改进: 首先, 随时招投标领域向电子化方向发展, 标书评估中用到的评估指标还需要根据国家政策法规、招投标实际情况、招投标工程领域等方面进行补充和完善; 其次, 针对较多数量的标书, 需要采取更加高效、快速的方法识别文本之间的相似度和重复率; 最后, 需要采取不同的方法论证本文模型的有效性和可解释性.


3.2 文本评级模型


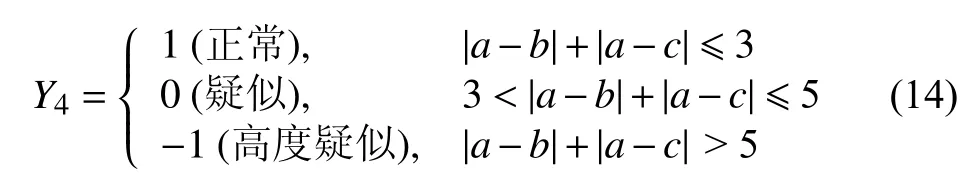



3.3 综合评估
4 实际案例分析



5 结论与展望
猜你喜欢
运输经理世界(2022年15期)2022-08-18
计算机与网络(2021年12期)2021-08-16
现代商贸工业(2020年21期)2020-06-29
校园英语·上旬(2018年9期)2018-10-16
今日财富(2018年9期)2018-05-14
环球市场信息导报(2017年1期)2017-04-08
航运交易公报(2015年2期)2015-01-19
城市建设理论研究(2012年35期)2012-04-23
