
云计算下多源异构大数据算法研究
2022-07-02 14:31张志强
电脑知识与技术 2022年15期
张志强
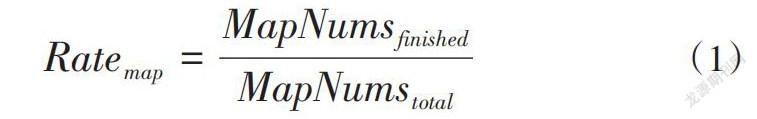


摘要:在互联网技术迅速普及的大潮下,信息数据呈指数增长趋势,如何对这些异构数据进行高效处理和调度,成为当今大数据处理的一个研究热点,针对这一热点,该文提出云计算下多源异构大数据的优化算法,首先通过阈值对比预取大数据源,接着进行数据调度优先级计算,最后按优先权值确定调度顺序,选择合理处理器执行。通过本算法与传统大数据调度方法对比实验,证明本算法具有更高的加速比和吞吐量的优点。
关键词:云计算;异构数据;数据源
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2022)15-0025-03
1 引言
在互联网技术迅速普及的大潮下,信息数据呈指数增长趋势,庞大的数据由于来源不一、分布不一,其数据结构具有多样性、多源性、异构性、复制性的特点[1]。如何对这些异构数据进行高效处理和调度,成为当今大数据处理的一个研究热点,其中对大数据跨源调度算法的研究更是广大相关学者广泛关注的一个课题。
现今,大数据多源异构体结构一般包括三种形式:DBMS异构形式、SELECT异构形式以及FROM 异构形式[2]。目前国内相关研究重点是围绕这三种形式关于如何解决大数据多源异构合理调度和有效对接方面 [3]。如夏明等虽然提出对全部变量进行更新处理,将所有待调度多源异构子流的质量以权重的方式重新组合排列,然后从排列出来的多源异构子流群里优先选择高质量的子流来作为传输的数据,通过反复操作后,最终把所有的调度的多源异构子全部处理完毕[4],但对各类多源异构数据差异性研究不足,不能解决大量复杂多源异构数据的有效调度问题;刘运提出结合采集和融合手段,先构建统一的数据模型标准,然后再按照数据分类构造各个分类体系,包括数据结构、运营机制、约束方法等,最后把纵向多源异构数据和横向多源异构数据相互融合在一起,以解决其一致性的问题[5],但此算法开销太大,对系统的负荷过重,算法运行速度过慢;岳婧文等将渲染应用特点以及作业调度算法相结合,将任务划分为不同的子任务,引入Min-min 以及Max-min 思想构建时间负载均衡模型[6],该方法虽然解决了开销问题,但适用范围十分有限,对于并行度高的大数据调度很难达到理想的效果。本文针对云计算下的复杂多源异构大数据,提出首先通过冲突检测预取异构数据,然后利用标准方差值计算数据调度优先级,最后依据优先权值确定调度顺序,选择合理处理器执行。实验证明本文算法与传统调度算法在相同的硬件环境下,具有更高的平均加速比,调度时间更短的优点。当丢包率不断增高时,本算法还能保持十分理想的吞吐量,从而证明本文算法相比其他算法具备更高的调度能力。
2 云计算下多源异构大数据的跨源调度算法
2.1 云计算下的多源异构大数据预取
由于多源异构大数据源的数据体烦琐、凌乱,所以需要先进行前期的归一整理,即预取操作,通过预取算法,缩短数据源开始的计算时间,减少系统运行成本[7]。由于多源异构大数据具备数据源差异的特征,可以认为每个数据源来自不同的任务。使用[Map]来表示数据源的任务,通过完成的[Map]任务数与[Map]任务总数的比率来计算[Map]比率,然后设置一个预定的阈值。当比率达到预定阈值时,实现多源异构大数据源的预取操作,如式(1)所示。
[Ratemap=MapNumsfinishedMapNumstotal] (1)
在式(1)中,[MapNumsfinished]表示完成的映射任务数;[MapNumstotal]表示所有映射总任务数。在整个预取算法运行过程中,很容易会出现多个节点同一时间从相同的输出结果中预取数据,形成竞争状态,从而降低预取的效率。为解决上述问题,可以通过加入冲突判断算法来提供数据预取的效率。当另一个任务在该任务预取数据的节点中预取数据时,将丢弃该数据,并预取其他节点上所需的数据。如果在某个时间段内,系统占用了所有的节点,那么,算法就会错开一个时间,再进行读取,算法如下:
[WaitingTime=rateTIME] (2)
[rate=DatafinishedDatatotal] (3)
在式(2)和式(3)中,數据[Datafinished]用于描述已预取的数据,[Datatotal]用于描述全部需要预取的数据;[TIME]为时间常量,主要作用是代表在多源异构的环境里传输所有数据所需的时间;[WaitingTime]代表的是等待的时间,该时间与预取异构数据的速度成正比关系。如果预取数据的速度不断增加,那么[WaitingTime]的值也就越大。
2.2 多源异构大数据跨源调度算法
2.2.1 数据调度优先级计算
上述算法在计算异构数据调度优先级的过程时,会把出口节点作为出发点向上迭代来得到每个节点的优先权值[rankj],然后实现异构数据调度的排序方式,因此,节点[rankj]的计算公式如式(4)。
[rankjQi=maxωi×δi+Z(Qi)O(QI)+rankj(QJ)rankjQexit=ωexit×δexit] (4)
式(4)中,[δi]代表对变量[Qi]进行计算所需要系统开销的标准方差;[O(Qi)]代表变量[Qi]所有后继节点的数目;[Z(Qi)]代表算法的总系统开销。从式(4)可以看出,[δi]能比较有效地反映同一数据在不同处理器中的差异值,当差异值增大时,[δi]的值也会提高,这时系统的调度效果越好。如果把[δi]与节点的平均值相乘,并将所得结果作为计算权重,可以确保算法在一定系统开销上的公平性。如果把总系统开销[Z(Qi)]除以传出量,那么,得到的商可以作为系统的通信开销权重。上述算法与传统通信权重算法相比,更能确保数据计算差异和通信开销之间的平衡关系,从而提高在多源异构环境中跨源数据调度的稳定性。C1FF0C1A-5727-4603-A204-CC5DB6166ACC
2.2.2 分配处理器算法
为节省系统开销,需要在处理器的分配方法上进行优化,本文算法是以优先级权重来作为处理器分配和执行顺序的原则[8]。第一步,选择入口数据,入口数据指的是在异构数据调度过程中首先要处理的第一个数据,即当所有处理器为空时,通过入口数据选择处理器,以进一步提高调度效率,而不会造成处理器过载。具体步骤如下:
(1) 选择输入数据[γj]数据处理开销最小的处理器;
(2) 对于其余处理器[γi],如果录入数据有直接后继节点分配处理器,则根据以下公式判断。如果满足以下公式所示的条件,则完成[γi]复制处理器输入数据;否则,直接在[γi]处理器中处理。
[WQentry,i 其中,[W]用于描述总计算开销,[H]用于描述总权重。 当满足以下的某一个条件时,系统就会结束上面的循环,否则继续循环执行: (1)每个处理器分配数据处理,即所有处理器[γi]的条目副本选择已完成。 (2)所有数据都经过处理。选择条目副本后,后继节点用于调度仍然没有分配处理器的数据。上述方法与传统的处理器分配方法相比,由于兼顾到直接后继节点完成的速度对调度结果数据的影响,从而提高了通信速度和缩短了数据传输的时间。其中,后继节点完成时间的计算公式为: [τQi,γk=maxminω(Qi,γk)+Hi,j] (6) 在数据中,[Qi]和直接后继节点在同一处理器上处理,[Hi,j]值为0,对于出口节点,[τ(Qi,γk)]为0。在调度过程中,[τ(Qi,γk)]在处理器上的值最小。 3 实验结果分析 3.1 实验环境 为了验证基于云计算的多源异构大数据跨源调度方法的实用价值,设计了以下对比实验。以两台配备VMwareace核心处理器的计算机为实验对象,其中一台配备传统大数据调度方法作为控制组,另一台配备新的大数据调度方法作为实验组。在保持其他影响因素不变的前提下,采用控制变量法记录实验组和控制组应用调度方法后底层网络流量整合时间和数据完整性的变化。 3.2 测试加速比 加速比作为数据调度性能的关键指标,主要是用来判断调度算法的运行效率,加速比的计算公式如下: [Sp=TpT1] (7) 在等式(7)中,[Tp]用于描述P测试程序在处理器系统里并行处理的时间;[T1]表示单个CUP上,测试程序的平均运行时间。 参与本次实驗的有传统的遗传算法、当今流行的社会力量群算法和本文算法,为了让分析结果更科学,系统采用了CPU8核+1个GPU核、CPU8核+2个GPU核、CPU8核+GPU4核这三种硬件环境下,测试三种算法的加速比,测试结果如图1所示。 根据图1的分析,当系统的硬件环境为CPU8核+GPU1核时,加速比结果显示,本文算法比遗传算法高出35%,比社会力量群算法高出18%;当系统的硬件环境为CPU8核+GPU2核时,加速比结果显示,本文算法比遗传算法高出33%,比社会力量群算法高出25%;当系统的硬件环境为CPU8核+ GPU4核时,加速比结果显示,本文算法比遗传算法高出16%,比社会力量群算法高出40%。 从比较结果可以看出,在三种硬件环境下,传统蚁群算法和社会力群算法的加速比都不高,其原因主要是由于这两种算法在运行时难以对处理器性能做有效的预测[9]。遗传算法的执行率无法与GPU的真实执行率同步,因此降低了处理器的实际利用率;而社会力量群算法由于没有优化调度性能,使得在大多数时间下,CPU是在等待状态,因此也降低了处理器的实际利用率。在实验过程中,加大GPU的数量时,本文算法、遗传算法和社会力群算法的平均加速度如表1所示。 从表1结果可知,当加大GPU的核数时,平均加速比结果显示,本文算法从原来的39%提高为97%,提高了1.3倍;遗传算法从原来的23.8%提高为62.3%,提高了1.6倍;社会力量群算法从原来的30%提高为88%,提高了1.9倍。通过比较分析,本文的算法由于能很好地提高CPU的利用率,因此平均加速比的提高值最高。 下面在比较三种算法在不断加大GPU的环境下平均执行时间的对比,用[T]表示应用程序执行的总时间,用[Ta]表示应用程序的调度时间,那么,[Ta÷T]就表示了调度时间占时比,称为“时间比例”。硬件环境跟测试平均加速比的硬件环境一样,分别为CPU8核+GPU1核、CPU8核+GPU2核、CPU8核+GPU4核。采用BFS等级调度来测试,测试结果如表2所示。 从表2的测试结果分析,在同一个硬件环境中,本文算法的时间比例都比另外两个算法低。当加大GPU核数时,时间比例分析结果表明,本文算法从原来的22.3%降低为13.8%,遗传算法从原来的57%降低为41.5%,社会力量群算法从原来的40.9%降低为21.5%。通过比较分析,本文的算法由于能充分利用GPU的资源,所以执行调度的时间比另外两种算法都短。C1FF0C1A-5727-4603-A204-CC5DB6166ACC 3.3 吞吐量测试 本节通过吞吐量测试该算法的调度性能。对于Lud应用,随着测试时间的增长,当丢包率上升时,本文算法和另外两种算法的吞吐量测试结果如图2所示。 从图2测试结果分析,随着测试时间的增长,当丢包率上升时,三种算法的吞吐量都有所降低,但总体来说,本文算法的吞吐量一直保持在1500以上的吞吐量,明显高于另外两种算法,说明本文算法相比另外两种算法具备更高的调度性能。 4 结论 随着现代制造业往工业4.0的演进,企业在运营和生产的过程中所产生的海量多源异构数据急需进行调度处理,以保证企业正常运营。对多源异构数据进行有效处理和深度挖掘,可以為制造商提供更有效的生产调度、设备管理等策略,从而提高生产质量和效率[6]。本文针对云计算环境下的多源异构大数据,提出了一种新的跨源调度算法。实验测试分析结果说明本文算法较传统的遗传算法和社会力量群算法具备更高的加速比和吞吐量,具有更好的数据调度性能。 参考文献: [1] 李汉鹏,王阳,郑君旋,等.多源异构检测大数据采集与存储方法研究[J].电子质量,2021(9):53-55. [2] 屈春一.非均质性海量复杂异构数据的混合云存储技术[J].单片机与嵌入式系统应用,2021,21(8):26-30. [3] 李帅,郭妍彤,周文迪.基于Neo4j的数据空间多源异构数据集成管理研究[J].现代计算机,2021(12):36-42. [4] 夏明,刘川杰,王奇.面向公共安全的多源异构数据结构化提取关键技术研究[J].数字通信世界,2021(5):3-4,30. [5] 刘运.基于循环神经网络的多源异构大数据融合模型构建[J].内蒙古民族大学学报(自然科学版),2021,36(3):204-210. [6] 岳婧文,李晓霞,秦少林.互联网信息监督管理大数据平台多源异构数据融合及应用技术分析[J].长江信息通信,2021,34(9):119-122. [7] 万磊,陈洪胜,王晓婷,等.面向电力大数据的多源异构数据融合技术研究[J].电子技术与软件工程,2021(2):172-173. [8] 肖楠.基于DTS的多模态异构大数据检测方法研究[J].电子设计工程,2021,29(20):143-146,151. [9] 李跃鹏,温亮明,黎建辉.基于查询语言转换的多源数据统一访问框架[J].计算机系统应用,2021,30(9):53-61. 【通联编辑:代影】C1FF0C1A-5727-4603-A204-CC5DB6166ACC
猜你喜欢
计算机与生活(2018年3期)2018-03-12
中国科技期刊研究(2017年2期)2017-05-14
电脑知识与技术(2016年21期)2016-10-18
电脑知识与技术(2016年21期)2016-10-18
电脑知识与技术(2016年21期)2016-10-18
大学教育(2016年9期)2016-10-09
科技视界(2016年20期)2016-09-29
河北遥感(2015年1期)2015-07-18
浙江大学学报(工学版)(2015年2期)2015-05-30
土木建筑工程信息技术(2013年4期)2013-10-17
