
基于单标签射频识别的唇语识别算法
2022-07-05 08:34张瑛琪彭大卫李森孙莹牛强
计算机应用 2022年6期
张瑛琪,彭大卫,李森,孙莹,牛强
基于单标签射频识别的唇语识别算法
张瑛琪,彭大卫,李森,孙莹,牛强*
(中国矿业大学 计算机科学与技术学院,江苏 徐州 221116)(*通信作者电子邮箱niuq@cumt.edu.cn)
近年来,有研究提出了使用多个定制且可拉伸的射频识别(RFID)标签进行语音识别的无线平台,但该标签难以精准捕捉拉伸引起的大频率偏移,而且需要探测多个标签,标签脱落或自然磨损时还须重新校准。针对以上问题,提出基于单标签RFID的唇语识别算法,将灵活、易于隐藏且没有侵入性的单个通用RFID标签贴在脸上,即使用户不发出声音,仅依靠面部的微动作也可进行唇语识别。首先建立模型处理RFID阅读器接收的单个标签随时间和频率响应的接收信号强度(RSS)和相位变化,然后采用高斯函数对原始数据的噪点进行平滑去噪预处理,再采用动态时间规整(DTW)算法对收集到的信号特征进行评估分析,以解决发音长短不匹配的问题;最后创建无线语音识别系统来识别区分与声音相对应的面部表情,从而达到识别唇语的目的。实验结果表明,对于识别不同用户的200组数字信号特征,该方法的RSS准确率可以达到86.5%以上。
射频识别;唇语识别;单标签;接收信号强度;动态时间规整
0 引言
唇读主要研究说话者发音过程中口腔的变化。每个人的语言都有自己的特点,言语过程中嘴巴的运动也有自己独特的规律。这种规律包括一般特征和个体特征:一般特征指语音中常见的口腔运动规律,主要与语音内容有关,可以应用于语音识别;个体特征与说话者的生理特征和习惯有关,主要用于说话者的身份识别。早在1984年,Petajan等[1]就介绍了自动唇读系统进行语音识别;1988年,在原有工作的基础上,Petajan等[2]引入了矢量量化、动态时间规整(Dynamic Time Warping, DTW)和一种新的启发式距离测度,使语音识别系统的性能显著提高。随着对唇读技术的研究,人们对嘴唇运动规律和生理特性的认识也越来越深入。唇部作为人类面部最大的区域,包含着丰富的内容和信息,包括唇形、肤色、肌肤纹理和语速等。唇部的运动可以充分反映说话人的个性信息。其次,它可以充分结合人脸和语音特征,充分展示其在说话人识别中的优势[3]。随着计算机视觉、模式识别和信号处理等领域的技术进步,基于射频识别(Radio Frequency IDentification, RFID)的唇语识别成为可能。利用RFID进行唇语识别时,无需使用具有侵入性的面部传感器,仅采用小巧且价格低廉的标签。基于RFID的唇语识别针对无法发声的用户也具有很好的鲁棒性,且环境周围的噪声对实验影响较小。传统的无线运动检测更侧重于手势[4]或者身体的运动[5],本文提出的单标签RFID唇语识别算法可以识别到面部的微动作,细粒度较高。
在RFID应用中,贴上RFID标签的物品被密集地大规模放置。RFID标签是一个小型芯片,封装在天线上。在扫描过程中,RFID阅读器通电并发射连续波给标签通电;然后,标签通过调制反向散射信号,以携带标签的信息响应阅读器,阅读器则进一步解码信号并获得相应的信息[6]。由于拥有读取速度较快、信息存储量较大、应用寿命较长以及使用安全、可靠性较高等特点,RFID被广泛应用于射频门禁、电子溯源、产品防伪、医疗管理、交通运输、车牌识别以及商品销售等领域。RFID系统包括硬件组件与软件组件两大部分:硬件组件包括阅读器、射频标签和网络基础设施等;软件组件包括驱动程序、RFID中间件和企业应用软件等。
文献[7]中设计了多个定制标签利用RFID的方法进行唇语特征识别,但该方法存在以下不足:1)所定制的标签天线长度的变化较为敏感,即使只有1 mm的微小变化,也会使谐振频率降低8 MHz,难以精准捕捉拉伸引起的大频率偏移;2)需要探测多个经过特殊调整的标签;3)如果标签脱落或自然磨损,必须重新校准。为了解决上述问题,本文提出了一种采用通用单标签的语音识别方法。在系统正常运行之前,需要解决几个关键挑战:1)采用通用的RFID标签,该标签不具备可拉伸性;2)处理使用单个RFID标签收集到的信号,并将其进行分割,提取出信号的特征值进行后续计算;3)标签的轻微移动不应影响实验的准确性及鲁棒性。
针对挑战1),本文使用无电池供电且轻巧灵活的RFID标签粘贴在皮肤上,采用无需佩戴手动输入设备的RFID无线语音识别系统,利用尽量少的标签识别用户所能够做出的与语音相关的嘴部动作,并随着时间的推移来学习这些动作,以便识别用户发出的不同声音,进而指导。虽然标签不可拉伸,但可以通过跟踪单个标签随时间的应变来进行识别,因为它们会根据不同的声音以及嘴部微小的动作产生不同的阻抗,这些阻抗会引起不同的相位和接收信号强度(Received Signal Strength, RSS),通过对这些变化的相位和RSS的处理与分析,来识别不同的语音。针对挑战2),考虑到采集原始数据的环境具有各种噪声,且原始数据很多时候不稳定或有明显波动,采用高斯函数对原始数据的噪点进行平滑去噪预处理。由于每个人的发音方式、发音长短各不相同,采用DTW算法对收集到的信号特征进行“规整”对齐,解决了发音的音节长短线性不一致、频谱偏移和音强大小的问题,并创建无线语音识别系统来识别区分与声音相对应的面部微表情。针对挑战3),本文采用RSS替代相位进行唇部特征值的提取。RSS对接收到的无线电信号中呈现的功率进行测量,测量相对简单,而且相比相位,RSS对唇部动作的变化较不敏感,故而标签的脱落之后再粘贴或面部表情导致的标签轻微移动对实验结果影响不大。本文设计将薄薄的标签贴在用户脸上,并使用化妆品进行遮盖隐藏。使用基于RFID的方法进行评估分析,它所应用的RFID标签较为灵活,且RFID相关部署较为简单,没有受过专业训练的人也可以胜任。综上,本文设计了可以通过一个小巧灵活的RFID标签来识别用户(包括语音障碍患者)的预期语音系统,主要工作包括:
1)通过处理阅读器收集的来自不可拉伸的通用RFID标签的反向散射信号来进行唇语识别算法研究;
2)仅检测一个标签随面部表情的信号变化并提取相关的相位和RSS特征值,利用高斯滤波和DTW等方法进行数据的分析与处理;
3)进行唇语识别实验,对比不同标签角度、人脸朝向及用户是否发声对实验的影响。
1 相关工作
1.1 基于人体感应的射频识别
文献[8]将RFID标签进行物理修改使其转换为传感器并用来监测温度、湿度;文献[9]则利用配备传感器的RFID标签监测神经信号;文献[10]的研究依赖标签的相位和RSS来精确跟踪它们的位置,包括感知身体骨架、形状和目标成像;文献[11]利用RFID标签通过感知标签芯片和天线之间的阻抗不匹配进行手指触摸跟踪;文献[12]利用近场天线的耦合效应来区分位于RFID标签下的不同材料。与这些研究不同的是,本文试图根据用户脸上已知位置的标签的相位和RSS变化来识别用户的唇语,因此需要新的解决方案。
1.2 自动语音识别
文献[13]探索了一种视听融合策略,超越简单的特征拼接,提高了识别精度;基于摄像头的唇读解决方案,如文献[14-15],需要提取独立且有区分度的几何特征,基于图像、模型和运动的特征,较为复杂且对照明条件很敏感,而且在用户移动时可能无法实现;基于音频的辅助解决方案仅适用于用户可以发出声音的情况,对于不能发声的语音障碍患者效果甚微;基于手语的辅助解决方案需要用户熟练使用手语,对语音障碍患者练习发声用处不大;此外,多种用于言语感应的面部传感器被提出,比如在临床环境中附在舌头上的磁铁[16]、脑电图(ElectroEncephaloGram, EEG)[17]和面部肌电电极等,但这些设备具有侵入性并且需要经过训练的专业医护人员操作,对日常生活中的语音练习来说较为昂贵。
1.3 神经网络语音识别
文献[18]中提出了基于超分辨率测试序列(Visual Geometry Group, VGG)的时空卷积神经网络用于将单词分类。该体系结构在一个字级数据集BBC-TV(333和500个类)上进行了评估,结果显示时空模型与空间体系结构的差距约为14%;然而,该文献中的唇读模型不能处理可变的序列长度,也不尝试句子级的序列预测。文献[19]中训练了一个用于学习预训练嘴特征的视听最大边缘匹配模型,将其输入到长短期记忆(Long Short-Term Memory, LSTM)网络中,用于在OuluVS2数据集上进行10个短语分类,以及非唇读任务。文献[20]中介绍了用于唇读的LSTM递归神经网络,但既没有解决句子级序列预测问题,也没有解决说话人独立性问题,与说话人相关的准确率为79.6%。
1.4 针对唇语识别的研究方法
随着机器学习的发展,广泛应用于唇语识别的方法有隐马尔可夫模型(Hidden Markow Model, HMM)、DTW算法、卷积神经网络(Convolutional Neural Network, CNN)、深度学习(Deep Learning, DL)以及LSTM等。但目前利用深度学习进行唇语识别的工作并不多,因为这类工作需要对帧进行大量预处理以提取图像特征,或进行时间预处理以提取视频特征(例如光流或运动检测)或其他类型的手工制作视觉管道。本文选择采用DTW算法来进行唇语识别。
2 预实验
2.1 标签的选择及放置
标签的大小和FCC(Federal Communications Commission)读距有很大的关系。标签越小,FCC读距就越小,因此如果想要精准地读取数据,标签和天线的距离需要减小;反之,标签越大,FCC读距相对来说就较大,但是过大的标签贴在用户脸上不美观,且更易脱落。因此,需要平衡好标签的大小与FCC读距之间的关系。
当标签连接到目标时,标签天线的阻抗会发生变化;而不同材料的目标也会引起不同数量的阻抗变化,这种阻抗变化将导致从该标签反向散射信号的相位变化,并且还导致从该标签辐射的功率发生变化[21]。不过由于本文实验始终将标签贴在同一目标——人脸上,因此,标签连接到目标上产生的影响相互抵消,可忽略不计。
本文将轻量型、对皮肤友好且无电池的RFID标签贴在人的左(或右)脸颊上,每个标签都是柔韧、薄片状的,并且由低过敏性材料制成,跟踪单个标签随时间的应变,因为它们会因为不同的声音而变形。标签在人脸的位置如图1所示。

图1 标签在人脸的位置示意图
2.2 采用单标签消除标签之间的相互干扰
原则上来说,标签的数量越多识别的精度就越高,但在多通道网络中,给定的时隙中只有一个标签通过共享信道进行传输,则传输成功;如果两个或多个标签在同一信道上同时传输,就会发生冲突[22]。在RFID实际应用中,多个标签共享一个公共通信信道,因此当多个标签同时进入读写器的有效识别区域范围内传输时,会产生信道征用的问题,不同标签之间的信息相互影响,导致阅读器不能正确识别,数据包将发生冲突并丢失。
本文进行了多标签和单标签的对比实验,相位和RSS结果对比如图2、图3,其中,图2从上至下的四个标签依次位于左脸颊、嘴唇上方、嘴唇下方和右脸颊。

图2 多标签的相位和RSS
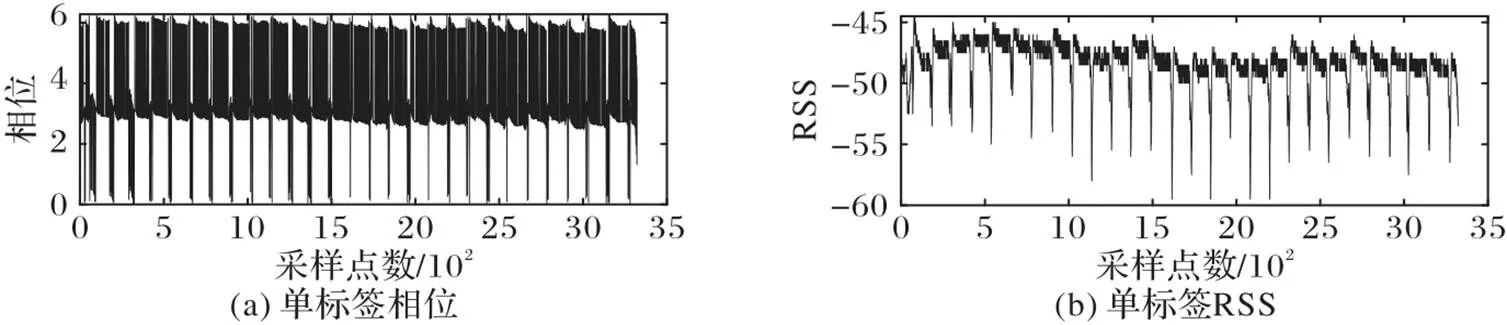
图3 单标签的相位和RSS
由图2、3可以看出,单标签的相位和RSS的规律比多标签更加明显,且多标签之间互相干扰会造成部分标签存在失读或者是误读的问题,从而导致数据准确性下降。在本文的实验中,由于粘贴在脸上的标签较小,该标签的FCC读取距离也较小,如果同时在脸上贴多个标签的话,标签之间的相互影响会干扰读取面部表情的微小变化,因此仅采用1个RFID标签附着在面部皮肤表面的已知位置。
2.3 消除多径等干扰因素对识别的影响
在室内环境中,除了硬件电路施加的相位噪声之外,多径效应是另外一个影响实验结果精确性的破坏性因素,且标签的方向以及用户的移动对实验也会有影响。因此可以通过控制实验环境等因素来抵消多径效应对识别的影响,并保证用户在采集时粘贴标签的位置尽量一致,且在用户发声时标签被拉伸。
设置空白对照组来判断多径干扰对识别的影响,该对照组可以将拉伸的影响与无线电环境相关的其他方面隔离开来。具体来说,放置固定位置的RFID标签,先在用户尽量静止的时候采集数据,然后在用户进行唇读时继续采集,接着将标签在用户唇读时接收到的信号减掉用户静止不动时所采集的信号,以隔离标签位置、方向和无线电环境的影响。实验表明,由于唇读时天线和标签的距离比较近,因此,多径等干扰因素对识别的影响很小,可忽略不计。
3 算法设计
本章首先介绍数据的采集方法,然后介绍高斯滤波预处理,最后着重研究了DTW算法的原理与使用。系统流程如图4所示。

图4 系统流程
3.1 单标签数据采集方法
监控标签拉伸的关键方法是测量标签伸长引起的阻抗变化。具体而言,当用户想要说话时,标签会随着用户的嘴部动作不断地被拉伸,其宽度和长度都会相应地发生变化,标签的电阻和电抗增加,这也会导致标签的共振频率发生变化。将单个RFID标签贴在人脸上,当一个人发出不同的音素声音时,该标签会被拉伸不同的量,从而产生不同的阻抗变化。采集该标签的所有响应,以获得标签拉伸所导致的变化。
用户面向天线重复数字0~9若干次,并提取每个数据的相位和RSS信息,如图5所示。从图5可以看出,这若干个重复的数字的相位和RSS都是有规律的,将其分割后每个数字随机选取20组数据集,10个数字共200个数据集。

图5 原始数据相位和RSS信息
3.2 基于高斯滤波预处理
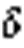


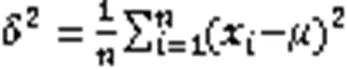
3.3 基于单标签的唇语识别算法
本文对HMM、互相关和DTW算法进行深入研究后发现:由于语音序列具有时序性,互相关并不能将不同速度且不同长度的语音序列很好地对齐,实验结果仅呈现微相关的状态;而使用HMM进行建模需要符合隐性状态的转移必须满足马尔可夫性(即一个状态只与前一个状态有关)这一条件,因此更适用于连续语音识别系统,所以本文采用DTW算法对唇语识别进行研究。
DTW是孤立词语音识别中最简单有效的方法,在自动语音识别中,DTW最初用于比较不同的语音模式。它可以在一定的约束条件下,在两个给定的时间相关序列之间找到最佳的对齐方式,是一种用于测量两个可能在时间或速度上变化的序列之间的相似性的弹性测量方法,解决了模板中发音长短不一的匹配问题。

图6 高斯预处理前后相位和RSS的对比
DTW的计算公式如下:
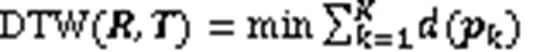


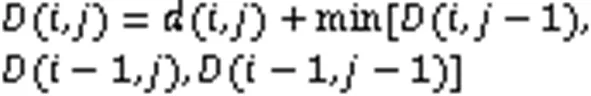
规整前和规整后的累积距离矩阵如图7所示,图8为DTW前后最优路径对比。

图7 DTW累积距离矩阵

图8 DTW前后最优路径对比
4 实验与分析
4.1 评估标准


4.2 实验设置
前端硬件:使用商品RFID Impinj R420读卡器实现本文识别系统的原型,可以在920.625~924.375 MHz的16个频道上跳跃。硬件组件如图9,包括一个阅读器、一个增益为8 dBi的定向圆极化天线和无源标签(阅读器Impinj AZ-ET的尺寸是13.2 cm ×13.2 cm ×18 cm,标签B42的芯片为M4,天线尺寸是8 mm × 22 mm,Wet Inlay尺寸为12 mm ×26 mm)。阅读器通过以太网线与上位机相连,并连续报告时间、相位和RSS读数。实验中该阅读器的工作范围约为3 m。

图9 硬件组件
后端实施:使用C#和Matlab语言进行数据收集和处理[23]。该处理过程在配备Intel Core i7-6500U CPU和8.0 GB RAM的DELL笔记本电脑上进行。该系统可以实现直接从RFID阅读器中检索相位和RSS读数。
测试环境:测试参与者在安静的办公室环境下进行测试,该环境具有丰富的多路径:墙壁、沙发、书架和家具。实验场景部署如图10。

图10 实验场景部署
4.3 实验与讨论
采用上述方法收集了5位用户(2女3男)的1 000组数据,每位用户各200组数据,各用户的相位和RSS的准确率如表1所示。可以看出,根据相位测量的准确率远低于根据RSS测量的准确率,这是因为与RSS相比,相位读数具有更好的分辨率[24],因此相位变化对面部微表情的感知更为敏感,进而引入了更多关于面部微表情的信息,导致数据包含的内容更繁杂。本文的目的仅在于识别用户说出的不同数字,所以本文主要采用RSS进行数据的处理与唇语的识别,在日后更为精细的工作中,可能会在RSS读数效果较差或区分度不大时采用相位进行辅助识别。同时,对于不同性别用户的不同语速,本实验的准确性也十分可观,在未来会采集更多不同年龄段及特殊人群(如聋哑人、语音障碍患者等)用户进行数据收集并实验,进一步提高系统的准确率和鲁棒性。

表1 各用户的相位和RSS准确率
图11、12显示了用户A和用户B的相位和RSS混淆矩阵,可以很清晰地看到RSS的准确率普遍比相位的准确率高。同时经分析得到:一个数字会被认为是另一个数字的原因是发音时的嘴部动作较为相近,从而使标签产生了相似的形变,导致信号的变化较为相似。不同的数字,根据相位和RSS的DTW距离判断出来的结果也略有不同,不同用户同一数字的准确率也未必相同,一个可能的原因是:每个人的发音习惯不同,进而在发声时嘴巴张开的角度及面部肌肉拉伸的情况也略有区别。
由图13观察到,当词汇量变大时,系统的精确度会下降。一个可能的解决方案是使用对拉伸更为敏感的RFID芯片,这些芯片在更细粒度的离散频率上共振,来模拟拉伸,从而更为精准地识别用户的唇语;或者使用相位读数更为精准的感知用户唇读时面部的微小变化。
此外,本文继续研究其他相关因素对实验的影响,包括标签角度、人脸相对天线朝向以及用户是否发出声音。具体分析如下:
1)标签角度的影响:本文通过重复一个单词若干次来验证标签位于不同角度的鲁棒性。标签角度部署如图14,根据图15标签不同角度的RSS对比分析得到,在45°时,数据收集的稳定性最差,0°其次,90°的时候效果相对较好。这是由于在45°时,标签的方向与唇部周围肌肉的运动方向大致相同,受到的拉伸最小,导致的形变也较小,因此本实验的标签方向选择90°。
2)人脸相对天线朝向的影响:将标签贴在左脸颊,分别对脸正对天线、贴标签一侧的脸正对天线和未贴标签一侧的脸正对天线进行实验,以判断人脸朝向对实验的影响,准确率分别为88%、90%和0%。可见虽然平衡好了标签FCC读距与标签大小的关系,但是在标签隔着人脸对着天线时,由于中间遮挡物太多,收集数据较为困难,因此准确率几乎为0;当人脸正对天线或者贴标签一侧正对天线时,效果较好。因此在实验及日后应用中,应尽量保证标签与天线之间没有遮挡。
3)用户是否发出声音对实验的影响:针对同一用户发声和不发声的100个样本,测试得出的相位准确率分别为90%和91%,因此可知用户是否发声对实验结果几乎无影响,所以本文的系统也可以用于不能发声的语音障碍患者。

图11 用户A的相位和RSS的混淆矩阵

图12 用户B的相位和RSS的混淆矩阵

图13 不同样本量的准确率

图14 标签角度部署示意图

图15 标签不同角度的RSS对比
5 结语
针对现有RFID唇语识别需要探测多个经过特殊调整的标签来捕捉拉伸引起的偏移以及标签脱落需重新校准等问题,本文提出了基于单标签RFID的唇语识别算法,使用价格低廉的单个RFID标签来识别用户发声时面部的微表情,并采用高斯的方法进行预处理,在此基础上,利用DTW算法处理收集到的相位和RSS信息,计算训练集和测试集之间模板匹配时最小的累计距离,保证了唇语识别的有效性。
本文充分利用已进行广泛应用的RFID设备,根据所收集到的信号参数的变化进行研究分析,实现了成本较低且准确率较高的唇语识别。本文方法与其他唇语识别方法相比,不具有侵入性,利用通用RFID标签,降低了应用成本,易于在实际环境中广泛部署应用。同时,由于采用了说话时面部表情的微动作识别,本文方法可以很好地适用各种用户(包括语音障碍患者)唇语识别。提高DTW算法的计算效率、进一步完善本方法的实际部署方案和应用模式使识别模型可以在不同的环境中快速部署应用是下一步工作的重点。此外,关于利用该方法识别更多种类的词句、进行细粒度更高的识别、延长唇语识别的读取距离也值得进一步研究。
)
[1] PETAJAN E D. Automatic lipreading to enhance speech recognition (speech reading)[D]. Champaign, IL: University of Illinois at Urbana-Champaign, 1984: 4-23.
[2] PETAJAN E, BISCHOFF B, BODOFF D, et al. An improved automatic lipreading system to enhance speech recognition[C]// Proceedings of the 1988 SIGCHI Conference on Human Factors in Computing Systems. New York: ACM, 1988: 19-25.
[3] BAI Z X, ZHANG X L. Speaker recognition based on deep learning: an overview[J]. Neural Networks, 2021, 140: 65-99.
[4] HONMA N, TODA K, TSUNEKAWA Y. DoA estimation technique of back-scattering signal from RFID for gesture recognition[C]// Proceedings of the 2015 9th European Conference on Antennas and Propagation. Piscataway:IEEE, 2015: 1-2.
[5] LIU J, CHEN X Y, CHEN S G, et al. TagSheet: sleeping posture recognition with an unobtrusive passive tag matrix[C]// Proceedings of the 2019 IEEE Conference on Computer Communications. Piscataway: IEEE, 2019: 874-882.
[6] XIE L, YIN Y F, VASILAKOS A V, et al. Managing RFID data: challenges, opportunities and solutions[J]. IEEE Communications Surveys and Tutorials, 2014, 16(3): 1294-1311.
[7] WANG J X, PAN C F, JIN H J, et al. RFID tattoo: a wireless platform for speech recognition[J]. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 2019, 3(4): No.155.
[8] WANG J, ABARI O, KESHAV S. Challenge: RFID hacking for fun and profit[C]// Proceedings of the 24th Annual International Conference on Mobile Computing and Networking. New York: ACM, 2018: 461-470.
[9] YEAGER D J, HOLLEMAN J, PRASAD R, et al. NeuralWISP: a wirelessly powered neural interface with 1-m range[J]. IEEE Transactions on Biomedical Circuits and Systems, 2009, 3(6): 379-387.
[10] YANG L, CHEN Y K, LI X Y, et al. Tagoram: real-time tracking of mobile RFID tags to high precision using COTS devices[C]// Proceedings of the 20th Annual International Conference on Mobile Computing and Networking. New York: ACM, 2014: 237-248.
[11] PRADHAN S, CHAI E, SUNDARESAB K, et al. RIO: a pervasive RFID-based touch gesture interface[C]// Proceedings of the 23rd Annual International Conference on Mobile Computing and Networking. New York: ACM, 2017: 261-274.
[12] HA U, MA Y F, ZHONG Z X, et al. Learning food quality and safety from wireless stickers[C]// Proceedings of the 17th ACM Workshop on Hot Topics in Networks. New York: ACM, 2018: 106-112.
[13] STERPU G, SAAM C, HARTE N. Attention-based audio-visual fusion for robust automatic speech recognition[C]// Proceedings of the 20th ACM International Conference on Multimodal Interaction. New York: ACM, 2018: 111-115.
[14] AGRAWAL S, OMPRAKASH V R, RANVIJAY. Lip reading techniques: a survey[C]// Proceedings of the 2nd International Conference on Applied and Theoretical Computing and Communication Technology. Piscataway: IEEE, 2016: 753-757.
[15] ASSAEL Y M, SHILLINGFORD B, WHITESON S, et al. LipNet: sentence-level lipreading[EB/OL]. (2016-11-05)[2021-05-19]. https://arxiv.org/pdf/1611.01599v1.pdf.
[16] BEDRI A, SAHNI H, THUKRAL P, et al. Toward silent-speech control of consumer wearables[J]. Computer, 2015, 48(10):54-62.
[17] BRIGHAM K, KUMAR B V K V. Imagined speech classification with EEG signals for silent communication: a preliminary investigation into synthetic telepathy[C]// Proceedings of the 4th International Conference on Bioinformatics and Biomedical Engineering. Piscataway: IEEE, 2010: 1-4.
[18] CHUNG J S, ZISSERMAN A. Lip reading in the wild[C]// Proceedings of the 2016 Asian Conference on Computer Vision, LNIP 10112. Cham: Springer, 2017: 87-103.
[19] CHUNG J S, ZISSERMAN A. Out of time: automated lip sync in the wild[C]// Proceedings of the 2016 Asian Conference on Computer Vision, LNIP 10117. Cham: Springer, 2017: 251-263.
[20] WAND M, KOUTNÍK J, SCHMIDHUBER J. Lipreading with long short-term memory[C]// Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2016: 6115-6119.
[21] DOBKIN D M. The RF in RFID: UHF RFID in Practice[M]. 2nd ed. Waltham, MA: Newnes, 2013: 306-314.
[22] COHEN K, LESHEM A. Distributed game-theoretic optimization and management of multichannel ALOHA networks[J]. IEEE/ACM Transactions on Networking, 2016, 24(3): 1718-1731.
[23] XIE B B, XIONG J, CHEN X J, et al. Tagtag: material sensing with commodity RFID[C]// Proceedings of the 17th Conference on Embedded Networked Sensor Systems. New York: ACM, 2019: 338-350.
[24] YANG L, LI Y, LIN Q Z, et al. Making sense of mechanical vibration period with sub-millisecond accuracy using backscatter signals[C]// Proceedings of the 22nd Annual International Conference on Mobile Computing and Networking. New York: ACM, 2016: 16-28.
Lip language recognition algorithm based on single-tag radio frequency identification
ZHANG Yingqi, PENG Dawei, LI Sen, SUN Ying, NIU Qiang*
(,,221116,)
In recent years, a wireless platform for speech recognition using multiple customized and stretchable Radio Frequency Identification (RFID) tags has been proposed, however, it is difficult for the tags to accurately capture large frequency shifts caused by stretching, and multiple tags need to be detected and recalibrated when the tags fall off or wear out naturally. In response to the above problems, a lip language recognition algorithm based on single-tag RFID was proposed, in which a flexible, easily concealable and non-invasive single universal RFID tag was attached to the face, allowing lip language recognition even if the user does not make a sound and relies only on facial micro-actions. Firstly, a model was established to process the
Signal Strength (RSS) and phase changes of individual tags received by an RFID reader responding over time and frequency. Then the Gaussian function was used to preprocess the noise of the original data by smoothing and denoising, and the Dynamic Time Warping (DTW) algorithm was used to evaluate and analyze the collected signal characteristics to solve the problem of pronunciation length mismatch. Finally, a wireless speech recognition system was created to recognize and distinguish the facial expressions corresponding to the voice, thus achieving the purpose of lip language recognition. Experimental results show that the accuracy of RSS can reach more than 86.5% by the proposed algorithm for identifying 200 groups of digital signal characteristics of different users.
Radio Frequency IDentification (RFID); lip language recognition; single tag; Received Signal Strength (RSS); Dynamic Time Warping (DTW)
This work is partially supported by National Natural Science Foundation of China (51674255).
ZHANG Yingqi, born in 1996, M. S. candidate. Her research interests include Internet of Things, wireless sensing.
PENG Dawei, born in 2001. His research interests include wireless sensing.
LI Sen, born in 1998. His research interests include wireless sensing.
SUN Ying, born in 2000. Her research interests include wireless sensing.
NIU Qiang, born in 1974, Ph. D., professor. His research interests include intelligent information processing, artificial intelligence, pattern recognition, machine learning, data mining.
TP391
A
1001-9081(2022)06-1762-08
10.11772/j.issn.1001-9081.2021061390
2021⁃08⁃03;
2021⁃08⁃31;
2021⁃10⁃15。
国家自然科学基金资助项目(51674255)。
张瑛琪(1996—),女,辽宁营口人,硕士研究生,CCF会员,主要研究方向:物联网、无线感知;彭大卫(2001—),男,江苏邳州人,主要研究方向:无线感知;李森(1998—),男,河南郑州人,主要研究方向:无线感知;孙莹(2000—),女,江苏泰兴人,主要研究方向:无线感知;牛强(1974—),男,辽宁沈阳人,教授,博士,主要研究方向:智能信息处理、人工智能、模式识别、机器学习、数据挖掘。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
作文通讯·高中版(2019年11期)2019-09-10
文学港(2019年5期)2019-05-24
移动通信(2019年2期)2019-03-27
动漫界·幼教365(大班)(2018年9期)2018-05-14
发明与创新·大科技(2018年2期)2018-03-17
