
基于Gazebo和PX4的强化学习训练仿真环境接口设计与实现
2022-07-07 12:42孙翔龙梁彦刚
电子技术与软件工程 2022年5期
孙翔龙 梁彦刚
(国防科技大学空天科学学院 湖南省长沙市 410073)
PX4是一款致力于为学术界、业余爱好者和产业社区提供低成本高性能飞控的独立开源项目,Gazebo是内置物理引擎的动力学仿真软件,直接集成在ROS(Robot Operating System)开发环境中,二者都是智能无人机开发者常用的工具,国内外有不少相关的研究和工程开发。基于PX4飞控的四旋翼无人机在Gazebo仿真环境中进行强化学习训练的相关研究过程中,需要一个接口程序使得强化学习训练过程中能够与仿真环境进行交互。本文就该程序的设计与实现方法进行探讨,以期为其他研究者提供参考。
1 PX4飞控、外部程序、Gazebo仿真环境之间的交互方式
1.1 PX4飞控与外部程序及仿真环境之间的交互方式
软件在环仿真(SITL)中,PX4可以通过MAVLink消息与外部程序进行交互。同时,PX4也通过MAVLink消息与仿真环境(如Gazebo)进行交互。与Gazebo进行交互时,通常情况下,PX4向Gazebo发布驱动无人机螺旋桨电机的控制指令,Gazebo向PX4发布无人机模型(simulator)上的各种传感器在仿真环境中感知到的信息。
在利用ROS开发环境进行编程时,由于各ROS节点(外部控制程序)之间通过ROS话题、服务进行交互,还需要利用MavROS功能包进行MAVLink消息与ROS话题、服务之间的转换。消息流如图1所示。

图1:外部程序到simulator的消息流图
1.2 外部程序与Gazebo仿真环境之间的交互方式
Gazebo提供了一组ROS API,允许用户修改并获取有关模拟世界各个方面的信息。在ROS编程环境中,外部程序可以通过话题或服务直接与Gazebo仿真环境进行交互,如在仿真环境中增加、删除模型、获得模型状态、设置模型状态、暂停仿真等。例如:Gazebo订阅的话题有“/gazebo/set_model_state”话题等,该话题可用于快速设置模型的姿势,而无需等待姿势设置动作完成;发布的话题有“gazebo_msgs/ModelStates”等,该话题发布仿真中所有模型的状态;服务有“gazebo_msgs/DeleteModel”等,此服务允许用户从仿真环境中删除模型。
2 强化学习中训练智能体的一般方法
2.1 强化学习的基本模型
强化学习主要解决的问题是智能体,即运行强化学习算法的实体,在环境中执行动作以获得最大的累计奖励。强化学习应用广泛,所有需要做决策和控制的地方,都有它的身影。典型的包括游戏与博弈,如打星际争霸、Atari游戏:算法需要根据当前的游戏画面和状态决定其要执行的动作,如按游戏的键盘、手柄,鼠标;围棋、象棋等棋类游戏:算法需要根据当前的棋局决定当前该怎么走子;自动驾驶系统、无人车:算法需要根据当前的路况,无人车自身的状态(如速度、加速度)决定其行驶的行为,如控制方向盘,油门,刹车等;机器人控制:机器人要根据当前所处的环境,自身的状态,决定其要执行的动作。
其基本模型如图2所示。
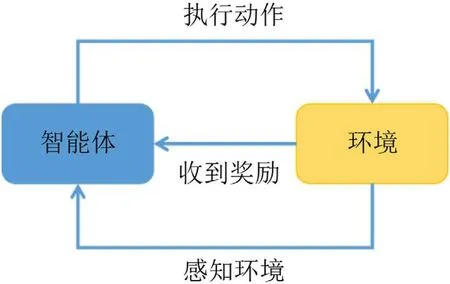
图2:强化学习模型
本文基于强化学习研究无人机在着陆地标上自主着陆问题。在该问题中,无人机为智能体,无人机与着陆地标之间的相对位置和相对速度信息为状态信息。无人机智能体感知环境,得到状态信息,并根据该信息通过智能体内部的神经网络得出无人机的控制指令。无人机执行该控制指令后,经过设定时间步后在环境中到达新的位置,并获得新的速度,从而可以计算出新的相对位置和相对速度,得到新的状态信息。环境根据无人机智能体的状态信息给出奖励或者惩罚,并根据新的状态信息得出新的控制指令。通过程序的不断循环实现无人机智能体逐步接近着陆地标并到达适合上锁的位置,程序判断出无人机到达该位置后,通过上锁指令使无人机着陆。
2.2 强化学习训练的一般方法
智能体能够正确地执行动作,关键在于得到一个映射函数π,称为策略函数:a = π(s),其输入s是当前时刻环境状态信息,输出a是智能体要执行的动作。策略函数由神经网络来进行实现,为了得到策略函数,需要运用大量的样本通过特定的算法来训练该神经网络。一般情况下,强化学习训练用到的样本可用一个类似元组或数组的数据结构[observation,action,reward,observation_next,done]来表示,其中observation表示从环境中感知到的与问题相关的信息,action表示智能体执行的动作信息,reward表示智能体从环境中获得的奖励信息,observation_next表示智能体执行动作后在环境中感知到的新的信息,done标记该状态是否为终结状态。
大量的样本通常由智能体在环境中通过海量的试错来获得,由于试错的次数比较庞大,且一些控制类试错容易造成智能体的损坏,因此,通过仿真环境开展强化学习训练是一种非常有效的手段。
3 仿真环境接口程序的设计与实现
3.1 设计思路
OpenAI Gym是一款非常著名的强化学习训练的仿真环境,包含一个测试问题集;每个问题成为一个环境,可以用于用户自己的强化学习算法开发;这些环境有共享的接口,允许用户设计通用的算法。其环境接口是Env,典型调用方法如表1所示。

表1:Gym的Env接口调用示例

if done:observation = env.reset()env.close()
作为统一的环境接口,Env包含以下核心方法:env.reset(self):仿真环境复位,重置环境的状态,返回observation;env.step(self,action):逐步推进仿真,推进一个时间步长,返回observation,reward,done等结果。
在强化学习训练时,这两个方法作为仿真环境的接口具有很强的通用性。由于强化学习的训练往往需要进行非常多的轮次(episode),每个轮次的初始状态要有某种相似性,这就需要解决仿真环境复位的问题。其方法通常是设计一个reset函数,每个轮次开始时调用该函数使仿真环境恢复到设定的初始状态。由于强化学习训练用到的样本是一组一组的离散数据,而在连续运行的控制类强化学习训练情形中,该离散数据的获得方式通常是按照预先设定的时间步长使仿真过程逐步向前推进,这就需要逐步推进仿真的方法。逐步推进仿真习惯上用step函数来实现,step函数通常以控制指令作为参数。
但是,Gym提供的仿真环境的场景是有限的,研究者可能还需要结合研究任务,构建适合自己需求的仿真环境。由于完善的、仿真程度高的仿真环境是一个复杂的软件系统,研究者自己编写的仿真环境往往存在仿真程度差等问题。如果需要在仿真研究的基础上进行真机验证,最好使用其它机构开发的较为成熟的仿真环境。但是,类似Gazebo的相对成熟的仿真环境往往并非专门为强化学习训练而设计,需要另外设计接口程序以使其适于进行强化学习的训练。设计仿真环境的接口可以借鉴Gym的核心方法,特别是强化学习训练中两个最重要的方法:仿真环境复位方法和逐步推进仿真方法。
3.2 实现方法
3.2.1 仿真环境复位
对基于Gazebo仿真环境和PX4飞控无人机(下文所述无人机均为基于PX4飞控的无人机,所述飞控为PX4开源飞控)在ROS开发环境中开展的基于强化学习的无人机自主着陆仿真研究中仿真环境复位用到的reset函数实现方法如下:
(1)通过发布控制指令的方式使无人机进入OFFBOARD模式。OFFBOARD模式是利用外部程序控制无人机时,无人机应处于的工作模式。方法是先订阅MavROS功能包发布的“/mavros/state”的话题来获得无人机的工作模式,如果工作模式不是OFFBOARD模式,则通过MavROS功能包提供的“/mavros/set_mode”服务将无人机的工作模式设置为OFFBOARD模式。
(2)通过发布控制指令的方式使无人机解锁(arm)。调用MavROS模块提供的“/mavros/set_mode”服务向无人机的飞控发布解锁指令。为确保飞控接收到该指令,可采取重复发布数次指令的方式。考虑到每次复位都会调用reset函数,解锁时应先判断无人机是否处于锁定(disarm)状态,如果不处于锁定状态则不发布解锁指令。
(3)设置无人机及其它模型的初始位置。在恢复仿真环境时,本文的研究只需要考虑无人机的位置信息,故采用了控制无人机飞行到预定位置的方式。方法是发布“/mavros/setpoint_raw/local”话题至MavROS功能包,转换成MAVLink消息后发送给飞控来控制无人机飞行到预定位置。判断无人机是否飞行到预定位置的方法是先通过MavROS功能包,利用Gazebo仿真环境提供的“/gazebo/get_model_state”服务,获取无人机的位置信息,然有将该位置信息与预定位置进行比较,偏差在一定范围内即认为无人机到达预定位置。选择其它的MavROS话题也可以实现无人机的速度、加速度或姿态控制。关键代码如表2所示。

表2:控制无人机飞行到预先设定的随机位置
也可以采用外部程序直接与Gazebo仿真环境进行交互的方式控制无人机的初始位置,方法是先向MavROS功能申请“/gazebo/set_model_state”服务,转换成MAVLink消息后发送给Gazebo仿真环境直接控制无人机瞬移到预定位置。但是,经验证,瞬移的方法会导致无人机不能稳定飞行,非常容易坠机,原因可能是瞬移会导致飞控感知到的位置信息紊乱,无法控制无人机稳定飞行。
本文的仿真环境中还有一个着陆地标,该地标不包含飞控,故采用了直接与Gazebo仿真环境进行交互的方式,利用“/gazebo/set_model_state”服务设置其初始位置为一定范围内的随机位置。
(4)计算reset函数返回值。在进行强化学习训练时通常需要从reset函数获得状态信息。该状态信息由reset函数的返回值来提供。本文研究的状态信息是无人机和着陆地标之间的相对位置和相对速度信息。利用Gazebo仿真环境提供的“/gazebo/get_model_state”服务可获得无人机和着陆地标的位置、速度信息,简单计算后可获得相对位置和相对速度信息。
3.2.2 逐步推进仿真
仿真环境中的step函数实现方法如下:
(1)发布无人机控制指令。在step函数中将作为函数参数的控制指令传递到“/mavros/setpoint_raw/local”话题中,并将该话题发送给MavROS功能包,转换成MAVLink消息后发送给飞控实现对无人机的控制。本文的研究以xyz方向的速度作为控制指令来控制无人机逐步飞向目标。也可以根据不同的问题以无人机的位置、姿态、加速度作为控制指令选用其它的MavROS话题发送给飞控。关键代码如表3所示。
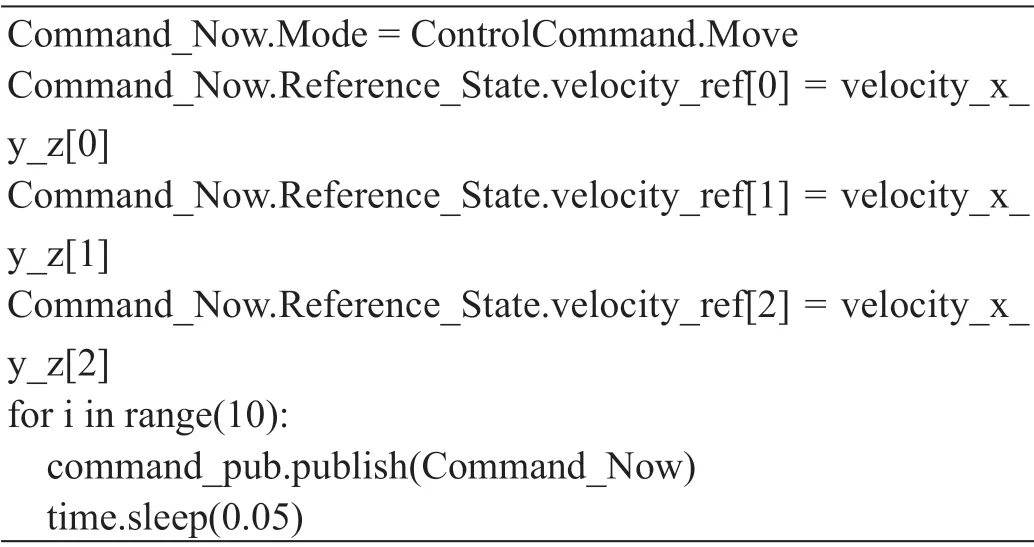
表3:发布无人机控制指令
(2)设定一段休眠时间。因其它指令的执行时间非常短,休眠时间基本上就是仿真的时间步长。在休眠的过程中,由于Gazebo仿真环境是并行运行的,无人机在收到的控制指令的控制下向前运动一个时间步。
(3)获取状态信息。无人机运动一个时间步后,系统进入一个新的状态,利用Gazebo仿真环境提供的“/gazebo/get_model_state”服务分别获得无人机和着陆地标的位置和速度信息,经简单计算后得到相对位置和相对速度信息。根据状态信息进一步判断无人机所处的状态,如果在该步仿真中无人机达到预定目标,则进入终结状态,如果没有达到目标则仍处于中间状态。通常用标记变量done来标记无人机所处的状态,done的值为1则进入终结状态,为0则为中间状态。
(4)给出奖励。需要在step函数中给出该步仿真后无人机智能体从环境中获得的奖励。如果在该步仿真中无人机达到目标,如到达着陆地标上方的设定点,则给予较大奖励;如果无人机触发惩罚条件,如飞行高度低于安全高度,则给予一定的负奖励。由于在绝大多数仿真步是未到达终结状态的中间步,无人机既没有达到目标又没有触发惩罚,如果没有适当奖励则会出现强化学习训练中的奖励稀疏(Sparse Reward)问题,容易导致训练不收敛。因此,应加入奖励函数塑形(reward shaping)以引导智能体学习到最终目标。经验证,以无人机和着陆地标之间的相对距离以及相对位置矢量和相对速度矢量之间的夹角为函数变量,经过适当运算给中间步一个较小的或正或负的奖励,进行奖励函数塑形,引导无人机朝向目标点飞行和接近目标点,效果较好。关键代码如表4所示。

表4:奖励函数
(5)计算reset函数返回值。将状态信息和获得奖励进行整合,给出reset函数的返回值。返回值可用一个形如[observation,reward,done]的数组或元组来表示,其中observation表示状态信息,reward表示智能体从环境中获得的奖励,done标记该状态是否为终结状态。
(6)暂停和恢复仿真。Gazebo仿真环境具有暂停和恢复仿真的功能,可以在发布完控制指令后恢复仿真,在程序休眠和获得状态信息后暂停仿真,以使强化学习的训练程序下一次调用step函数时智能体和仿真环境能够紧接着上一次的状态向前推进,排除了执行其它代码的时间对仿真连贯性的影响。可利用“gazebo/unpause_physics”服务恢复仿真环境,利用“gazebo/pause_physics”服务暂停仿真环境。
4 可能遇到问题的处理方法
4.1 意外坠机
在仿真环境中如果无人机意外坠机则程序就不再继续往下运行了,这显然不利于强化学习的训练。针对此问题,本文采用了一个简化问题的方法,在reset函数和step函数中将目标点设置到着陆地标上方10 m处,当无人机飞行高度低于9.5 m时本轮次训练结束,通过控制指令使无人机飞到初始位置。抬高飞行高度后,无人机基本上没有坠机的可能,并且对强化学习训练来说,将目标点设定在较高位置和设定在着陆地标上没有本质不同。当飞行高度低于安全高度时,理论上也可采用调用“/gazebo/reset_world”服务与Gazebo仿真环境进行交互,使仿真环境复位的方法解决此问题。但是,实验发现该方法同样会导致无人机飞行不稳定。
4.2 程序与飞控交互时不能实现预期功能
外部程序与飞控进行交互时有一些技术细节,开发者如果想更多地关注功能实现而不想陷入到技术细节中,可借用中间程序。笔者利用了国内阿木实验室开源的Prometheus项目中px4_sender.cpp等程序文件中提供的功能函数与飞控进行交互,避免了自行设计交互函数的繁琐细节。
5 结束语
本文借鉴OpenAI Gym的统一环境接口,针对基于Gazebo和PX4强化学习训练这个具体的应用场景,介绍了仿真环境复位和逐步推进仿真两个程序接口的实现方法,以及可能遇到的问题的处理方法。实际强化学习训练验证了本文接口程序设计与实现方法的有效性,可以为相关研究提供一定的借鉴和参考。
猜你喜欢
装备维修技术(2021年37期)2021-11-03
现代电子技术(2019年15期)2019-08-12
民用飞机设计与研究(2019年2期)2019-08-05
人大建设(2019年12期)2019-05-21
电子测试(2018年23期)2018-12-29
瞭望东方周刊(2017年42期)2017-12-05
中国公共安全(2017年7期)2017-10-13
计算机测量与控制(2017年6期)2017-07-01
环球时报(2017-03-30)2017-03-30
科技视界(2016年13期)2016-06-13
