
基于Python的图书信息搜集与展示研究
2022-07-10 13:45孙俊李秋月赵晨悦
现代信息科技 2022年5期
关键词:图书
孙俊 李秋月 赵晨悦



摘 要:文章以Python语言为基础编写了一个爬虫程序,用于获取网络上关于图书的信息,经过数据清洗和筛选后存入到数据库中实现数据的长久保存。在经过广泛查阅相关主题著作、论文、使用手册等资料后,在借鉴前人的研究成果的基础上,参考了图书评价人员给出的图书得分,尝试去除网络水军对图书得分的影响,最后通过给定的新的图书分值计算公式,重新计算图书得分,并以新的分数推荐给用户。
关键词:Python;图书;推荐;查询
中图分类号:TP311 文献标识码:A文章编号:2096-4706(2022)05-0030-04
Collection and Display Research of Book Information Based on Python
SUN Jun1, LI Qiuyue1, ZHAO Chenyue2
(1.Zhengzhou Technical College, Zhengzhou 450121, China; 2.Zhengzhou Information Engineering Vocational College, Zhengzhou 450121, China)
Abstract: This paper writes a crawler program based on the Python language to obtain information about books on the Internet. After data cleaning and filtering, it is stored in the database to achieve long-term data storage. After extensive review of relevant subject works, papers, user manuals and other materials, on the basis of using for reference from previous research results, and referring to the book scores given by book reviewers, it tries to remove the influence of the Internet army on the book scores. Finally, through the given new book score calculation formula, the book score is recalculated, and the new score is recommended to the user.
Keywords: Python; book; recommendation; query
0 引 言
在移动互联网快速发展的今天,各种各样的图书以及图书评论和图书排名的网站层出不穷。面对如此浩瀚的信息,人们在选择图书的时候总会感到茫然和困惑,不知应该听从哪一家的图书排行信息。而且在互联网上在图书数据肯图书评论数据存在大量灌水现象,让人难以分辨。除此之外,各种阅读门户网站主要推荐的是网络小说,但是对经典著作等排序甚少,而且杂乱无章,可信度低[1]。本项目通过爬虫程序在互联网搜集图书信息,然后使用新的計算方法计算图书分值。凭借新在图书分值能够为用户推荐图书。图书评分经过重新计算,减少了网络水军对图书分值的影响,增加了图书分值的合理性。
1 开发平台与开发工具
本项目使用了目前流行的网络爬虫语言Python。该语言具有高性能,语言简洁方便,较为实用的特点。Python语言因其自身简单和丰富资源库的特性,在网络爬虫和数据分析方面有着巨大的优势[2,3]。本项目使用的开发环境是Python2.7版本。开发工具是PyCharm。在数据库方面使用的是MySQL5.7版本。
1.1 Python
Python是一个自由软件,语言简洁清晰。其语言特点是语言缩进强制使用空白符。因为Python是一个开源软件,所以它有丰富的第三方库,使得Python使用更加方便高效[4]。Python语言丰富的第三方库中就包括为了解决网络爬虫问题而设计的库,语言结构精简,因此在网络爬虫方面Python语言有着其他语言所没有的优势[5]。
1.2 MySQL
MySQL是一种小型的数据库,体积很小,运行的速度较快,使用的成本比较低,使用方便简洁,个人使用便捷,所以被大量用户用于个人使用[6]。
2 系统功能及市场需求分析
在目前的互联网上有大量的图书评论和图书排行榜。但是,这些图书很多都是网络小说,只在网络上流行,没有出版实体书,仅仅依靠在网络上获取关注[7]。网民们更加喜欢这种简单直白的文字小说,所以在一些图书类网站为了迎合网民口味,更多的关注网络小说,而对于传统的出版图书却有很少的关注。以至于只有豆瓣这一家是较为可靠并且大型的图书评论和图书排行网站[8]。但是,随着豆瓣图书排行越来越受到关注度,所以引来了众多水军参与图书评价,导致豆瓣的图书评分系统存在一定的不合理性[8]。而且豆瓣的图书相关功能里面并没有图书推荐功能。只是在每年年末提供当年的新书推荐[9]。本项目弥补这一项的不足,因此依靠豆瓣图书数据重新给图书进行评分,并按用户喜欢的图书类型为用户提供高分书籍。这也弥补了图书市场推荐功能的不足。并且图书推荐和分值计算采用了已有的和豆瓣图书数据,有一定的数据合理性基础。
2.1 系统功能需求
功能上要满足以下两点:(1)用户通过输入关键词,系统能够为用户推荐相关的书籍信息。(2)用户可以直接搜索某本书的基本信息。
2.2 系统性能需求
在数据收集在过程中,使用Python语言制作的爬虫爬取约为四万条数据,因此需要采用多线程的方式加快爬虫进度。但是这样会给服务器带来巨大的压力。如果因为给服务器带来巨大压力,导致爬虫程序被禁止提供服务,则爬取完全失败。所以在爬虫运行的过程中要限制爬取速度。按照网站的要求,遵守网站的规则,不获取网站禁止获取的内容,尤其是在爬取豆瓣网图书信息的时候,由于豆瓣限制访问速度为150次每小时,所以爬取豆瓣图书数据非常缓慢。
综上所述,豆瓣网的爬虫采用单线程的方式进行爬取,避免被豆瓣网禁止访问;而当当网的爬虫可以使用多线程爬取,用于节约时间。
3 项目完整流程
首先是爬虫文件,用于收集当当网小说部分的图书信息。获取的信息包括图书的全球唯一编号、国际标准书号(International Standard Book Number, ISBN)、图书的名称、图书的作者、图书价格、图书所在的当当网页面地址。然后依据图书ISBN信息,通过豆瓣API接口访问豆瓣数据库,获取图书信息。然后把图书信息进行解析,得到具体数据。接着把数据保存到数据库中,做数据分析。最后制作用户接口,与用户进行信息交互。
4 项目文件及功能实现
本小节主要介绍本项目的文件以及文件作用和文件中的一些重要代码。
4.1 GetDangdangbookWriteToMySQL.py
文件作用:从当当网上获取图书信息并保存到数据库中。以下为获取页面中二级页面URL链接的函数代码。
def get_two_level_url(soup,url_list):
# 获取网页信息
# 解析网页信息
# 得到主要内容
4.2 GetDangdangXiaoshuoWriteToFile.py
文件作用:获取当当网上小说部分的图书URL(Uniform / Universal Resource Locator,统一资源定位符)信息并保存到文件中。以下为获取页面中所需要的信息的函数代码,把获取的信息保存到字典格式的数据中。
def get_book_info(soup,dict,isbn_list):
# 依据给定的ISBN号获取当当网上图书页面的图书信息
4.3 GetTagsAndValue.py
文件作用:获取图书标签并按照标签出现的次数排序。以下代码为遍历每个列表中的数据,然后按照出现次数排序。
for i in results:
# 清理获取到的图书信息
# 将图书信息保存到数据库中
4.4 GetUrlWriteToDoubanbookinfolMySQL.py
文件作用:从数据库中读取图书ISBN信息,并通过豆瓣API(Application Programming Interface,应用程序编程接口)获取豆瓣网上图书的信息。
4.5 start.py
與用户进行交互的接口程序。
4.6 NewValue.Py
文件作用:计算图书的综合得分。以下代码为计算图书综合评分的代码。
for i in results:
# 获取数据库每本图书的信息
# 计算图书新的得分
# 将新的得分信息保存到数据库中
4.7 getTagValue.py
文件作用:用于计算图书标签的得分。
5 网页数据处理技术
获取的网页有两种格式:Html和Json。
Html格式是互联网最为常用的一种网页格式。该格式网页可以通过BeautifulSoup库进行直接的解析,获取网页内的标签元素和信息,然后对信息进行收集和处理。这里主要用于当当网上图书信息收集。主要步骤为:(1)通过ruquest库中的函数获取给定的URL的网页信息。(2)使用Beautifulsoup库中的函数解析获取的网页信息。(3)获取到的图书信息以字典格式存储,然后保存到bookspider数据库中的dangdangbookinfo表中。
Json格式的数据需要用到Python的第三方Json库对该格式信息进行解析。主要用在通过豆瓣网API获取图书信息。主要步骤为:(1)读取数据库库中的ISBN信息并以列表形式存储。(2)把读取到的ISBN和豆瓣API接口连接起来组成字符串,然后依据该URL通过request库中的函数后去该URL指定的网页信息。(3)通过json库中的函数解析获取的页面信息,然后以字典的格式存储数据。(4)把图书信息存储到bookspider数据库中的doubanbookinfo表中。
6 数据清洗和处理以及数据库存储
在获取的当当网图书信息时,有的图书信息错误或者信息不完善。所以要对不完善的信息进行补全,错误在信息进行修正。有的图书信息内容错误或者格式不正确,需要删除此图书的信息。有的图书信息和其他书籍信息相互颠倒,需要删除。在经过对数据的清洗后,本项目以全球唯一图书编号ISBN作为主键,把图书数据存储到本地的MySQL数据库中。
在获取当当网关于图书的信息之后,项目系统根据豆瓣网提供的API,按照ISBN号码获取豆瓣网上该图书的信息。在获取图书信息时可能会出现的错误包括ISBN重复、没有该ISBN号码的图书信息肯存储到数据库错误。
7 数据分析及分数重计算
在获取数据并存储到数据库中之后需要对数据进行清洗,之后进行数据分析,计算综合得分。之所以对豆瓣图书进行重新评分,具体原因有:(1)豆瓣评分来源于用户的自主评分,用户在评分时没有考虑到该图书的易读性,由于人的主观因素这是不可避免的。(2)豆瓣部分图书评分有水军参与,刻意降低了该图书的评分。
综合得分是在原有的豆瓣评分的基础上添加了评价人数得分和标签得分。这样就增加图书易读性得分,使得图书评分考虑到了让用户能够读懂该图书。
计算综合得分的公式为:
a×5+ln(b)×2.5+c×2.5(1)
式(1)中,a为该书豆瓣得分,b为该书评价人数,c为该书标签综合得分。
c的计算公式为:
(2)
式(2)中,d为该图书所有标签中某一标签个数,e为另一标签个数,f为另一标签个数,n为总标签数。即求出每个标签出现次数的自然对数字,然后把每个值相加求和再除以总标签数。
8 程序设计与编码实现
8.1 当当网爬虫程序
当当网的圖书主页使用的是html格式的网页文件。本项目程序使用Python中的requests库来获取页面源代码。使用BeautifulSoup库解析网页格式,然后获取主要信息。该过程首先是获取当当网上小说分类下的所有网页。在这一级页面下获取每个图书的URL链接,然后进入下一页获取图书详情页的链接,最后获取所有图书详情页URL链接,并保存到链表中。循环遍历这个链表,依次访问这些图书详情页的网址连接,通过程序获取在当当网上的图书信息。获取的图书信息包括:图书国际标准编号ISBN、书名、作者、出版社、价格和当当网上该图书在URL。最后把数据存储为字典类型的数据,统一保存到bookspider数据库下的dangdangbookinfo表中。
8.2 豆瓣网爬虫程序
豆瓣网为用户提供了API接口,所以可以使用API便捷的爬取豆瓣网对应的图书信息。但是,API限制了用户访问服务器的速度,需要申请API接口的key用于解锁用户身份。但是豆瓣在早些年的时候由于内部原因取消了访问申请,所以现在只能以游客的身份进行爬取。没有注册的用户访问速度受到限制,只能以每小时150次访问的速度进行访问。
按照豆瓣网信息服务提供页提供的API说明,豆瓣网所提供的数据是json格式。因此需要对获取的数据进行解析,解析完的数据保存在一个字典类型在变量中,最后批量保存到自定义的bookspider数据库的doubanbookinfo表中。其保存的图书信息有:图书国际统一编号ISBN、书名、作者、作者简介、标签、评价人数、评分、豆瓣ID、包装、页数、出版社、原标题、豆瓣链接、图片和评论。
8.3 分数计算
标签分数计算。标签计算分数主要是考虑到该图书的易读性。如果该图书的标签在其他图书中出现,而且出现次数很多,则说明该图书较为通俗,能让大部分读者接受,具有较高的易读性。标签出现次数的价值增长随着出现次数的增多而逐渐变慢,所以采用对数建模比较合适。求出每个标签价值的总和后再求平均数,可使数据范围在给定的范围之间。
综合得分计算。综合得分计算主要有三部分组成。豆瓣得分反应大家对该图书的主观评价得分,评价人数和标签得分反应该图书的易读性得分。综合起来,给予豆瓣评5.0的权值,给予评价人数得分和标签得分各2.5的权值,使得最后的最高综合得分约为100分。该权值的分配是考虑到该图书本身的价值和该图书易读性的价值。在为用户推荐相关图书时能够更加准确满足用户需求。
8.4 用户交互界面
本项目采用了一个Python自带的简单地与用户交互的界面。用户可以在这个界面里查找图书相关信息和获取推荐的图书信息。该界面采用Python consoleline,通过用户输入信息与用户进行交互。拥有交互界面的主要原因是,通过用户输入的信息去搜索含有该标签的书籍,然后按照综合评分排序为用户推荐书籍。
图1为程序运行时进行搜索的实例,通过搜索“三体”一词获取图书信息中ISBN,或书名,或作者名中包含“三体”一词的图书信息,然后再界面中显示出搜索到的图书信息,包括ISBN、书名,作者名,评分人数,豆瓣评分和豆瓣网链接。用户可以通过豆瓣网链接直接查看豆瓣网上该图书的详细信息。
图1 图书搜索运行截图
图2为系统运行时进行图书推荐的实例,通过“小说”一词获取图书信息标签中包含“小说”一词的图书信息,然后再按照图书的综合评分由高到低排列,在界面中显示出推荐的前十名图书的图书信息。显示的图书信息包括图书ISBN号码、图书名称、作者名称、评分人数、豆瓣评分和豆瓣网链接。
图2 图书推荐运行截图
9 数据存储
数据存储在MySQL数据库中。使用该数据库主要是因为使用方便,操作简单,容易用户使用。本系统创建的数据库名称为bookspider。主机名或IP地址为localhost,端口号为3306,用户名为root,密码为root。其中共有三个数据表,分别是dangdnagbookinfo,doubanbookinfo和tagvalue,在此只列举前两个数据表。
9.1 dangdangbookinfo表
该表保存了从当当网上爬取的图书信息,其中ISBN作为全球图书唯一编号可以作为主键。表1列出了该数据表中的字段名,相应的字段描述,字段类型,是够为主键以及是否允许为空。
9.2 doubanbookinfo表
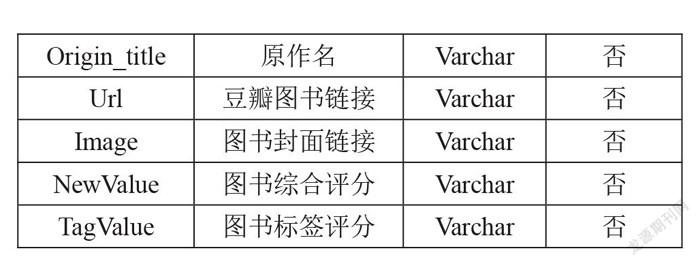
该表保存了豆瓣网爬取的图书信息,其中ISBN作为全球图书唯一编号可以作为主键。表2列出了该数据表中的字段名,相应的字段描述,字段类型,是够为主键以及是否允许为空。
10 结 论
本项目是主要功能是图书推荐和图书查找。图书推荐的依据是豆瓣网上的图书信息。通过对豆瓣数据库的爬取,获取图书信息,之后对数据进行清洗和处理。本项目实现了为用户推荐图书功能,这是豆瓣没有提供的,也是其他大型图书网站所没有的。在为用户推荐图书时,采用了一種新的图书评分计算方法,其中参考了豆瓣评分和评价人数,之后计算出综合评分。相比较于豆瓣的评分更加合理。本项目通过豆瓣数据进行重新处理和优化,使数据更加准确,能为用户提供更加可靠的图书推荐。
参考文献:
[1] 李琳.基于Python的网络爬虫系统的设计与实现 [J].信息通信,2017(9):26-27.
[2] 杨国军.基于Python的数据爬虫的设计与实现 [J].数字技术与应用,2020,38(10):153-154+158.
[3] DONEY A B.像计算机科学家一样思考Python [M].赵普明,译,北京:人民邮电出版社,2016.
[4] LAWSON.用Python写网络爬虫 [M].李斌,译,北京:人民邮电出版社,2016.
[5] NELLI F.Python数据分析实战 [M].杜春晓,译,北京:人民邮电出版社,2016.
[6] 刘增杰.MySQL 5.7从入门到精通(视频教学版) [M].北京:清华大学出版社,2016.
[7] 王文民.中国图书市场分析 [D].成都:西南交通大学,2007.
[8] 刘高军,印佳明.基于图书特征及词典的豆瓣图书垃圾评论识别 [J].计算机技术与发展,2019,29(11):107-112.
[9] 丁媛媛.浅析豆瓣图书“一星运动” [J].新闻研究导刊,2020,11(9):71-72.
作者简介:孙俊(1994.12—),男,汉族,河南郑州人,助教,硕士,研究方向:人工智能、自然语言处理;李秋月(1992.01—),女,汉族,河南周口人,助教,硕士,研究方向:网络信息安全、物联网技术、人工智能应用;赵晨悦(1994.06—),男,汉族,河南郑州人,助教,学士,研究方向:应用程序开发、计算机网络。
猜你喜欢
小学阅读指南·低年级版(2017年12期)2017-12-26
延河(2017年6期)2017-06-23
出版参考(2014年17期)2014-11-05
全国新书目(2009年24期)2009-07-17
