
基于动态矩阵分解模型的电影推荐系统研究∗
2022-07-10 02:16杜宇超
电子器件 2022年2期
王 璇 杜宇超 杜 军 邹 军
(1.南京信息职业技术学院电子信息工程学院,江苏 南京 210023;2.加州大学圣地亚哥分校电子与计算机工程系,圣地亚哥CA 92093;3.中兴通讯股份有限公司,广东 深圳 518057;4.清华大学电机工程与应用电子技术系,北京 100084)
在如今的互联网时代,电子商务市场迅速发展,出现了品种繁多的推荐系统,这与大量互联网用户对个性化信息日益增长的需求密不可分。许多电子商务企业抓住这个机会,在大数据分析的基础上,再运用数学模型和相关高级算法,推出能够预测用户喜好的产品推荐系统,吸引了更多潜在客户以实现盈利的目的[1]。例如,美国媒体服务公司NETFLIX已将其在线电影和电视节目流数据应用到在线用户平台的推荐系统中,实现了可观的播放量增长以及用户会员比例上升[2]。本文基于机器学习和数据分析技术,在MATLAB 环境中使用优化算法来研究更加可靠的适用于NETFLIX 平台的电影推荐系统。数据集中包含9000 部NETFLIX 电影的历史评分,算法应用了两种核心方法——高效处理数据的“矩阵分解(Matrix Factorization,MF)模型”,以及用于训练目的的“随机梯度下降(Stochastic Gradient Descent,SGD)算法”。研究最终结论为使用动态偏置的MF 模型,在数据集与特征数量远小于一般市场所用的情况下,可将推荐系统的预测准确度提高3.3%,从而为NETFLIX 客户提供令人信服的个性化电影推荐。
1 算法与模型
1.1 稀疏数据结构
一般情况下,所有用户对电影的实际评分值由一个普通的U×M评分矩阵存放,U表示用户数量,M表示电影数量。由于对电影进行评价的用户数量有限,并且每位用户可能只对有限的电影进行打分,因此该评分矩阵中的大多数评分值都是未知的,表1 是一个简单的例子。所以从节约存储空间的角度可以设计一个稀疏矩阵R来存储实际电影评分,其中R中的每个值rum代表用户u对电影m的评分等级(整数1~5 分),而u和m是整数ID 号,代表特定的用户和电影。稀疏结构的优点是可节省数据空间,具体来说,那些未知的评分值在稀疏举矩阵中默认为零,所以不占用实际空间。这里的稀疏矩阵只需要3 列数据:电影ID,用户ID 和评分,如表2 所示。很明显,正常矩阵中需要5×6=30 个空间单位,而在稀疏矩阵中仅需要3×7=21 个空间单位。当影片和用户数量足够大时,这种存储单位的节约量会更加显著。
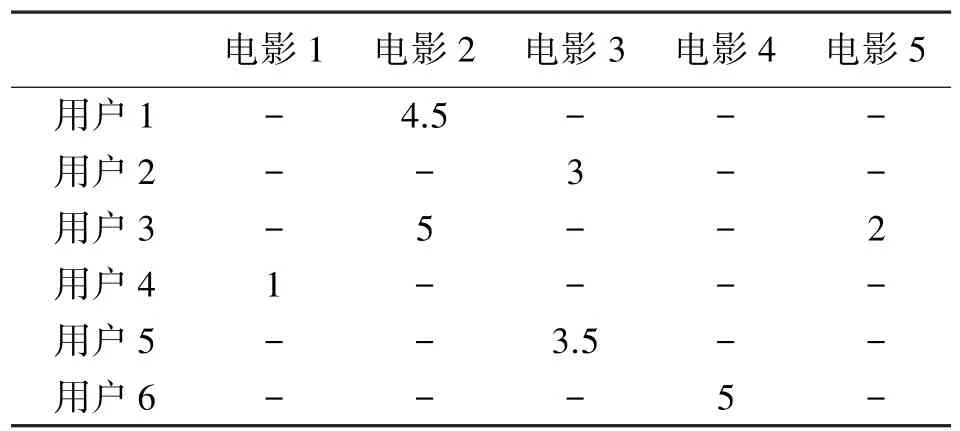
表1 一个普通评分矩阵的简单例子
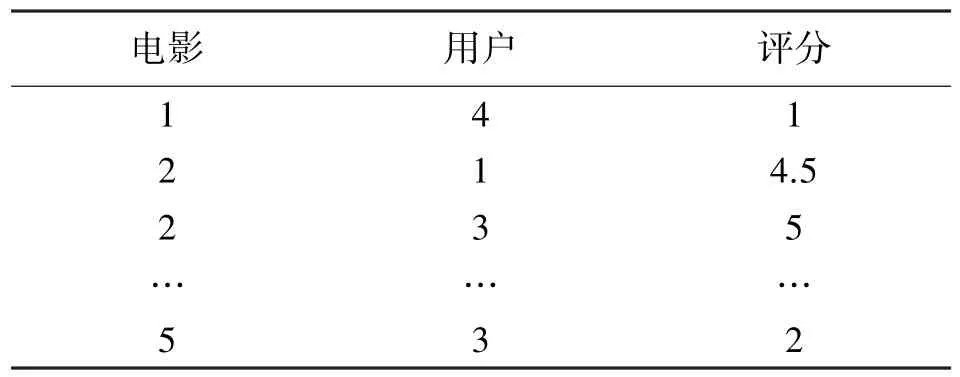
表2 一个稀疏矩阵的简单例子
1.2 基础矩阵分解模型
推荐系统中的数据预测方法通常有两种——直接使用电影属性和用户偏好之间相关性的内容过滤[3-4],或者仅识别具有相似偏好用户的协作过滤[5]。后一种方法是面向项目的,相比前一种基于内容的方法更准确[6]。因此,基于协作过滤的这一优点,业内已经开发了用于分析“用户-用户”相似性的k最近邻算法(k nearest neighbour,kNN)[6]和潜在因素模型[7]。kNN 实现简单,但是数据库中的稀疏性很高。另外,潜在因素模型通过复杂的代码实现降低了稀疏性的负面影响,能够更好地解决实际问题。
潜在因素模型通常使用一定量的特征因素(通常为20 个~100 个)代表用户和电影。因素代表电影的实际特征或用户喜欢的样式类型。MF 模型是潜在因素模型的一种实现与应用,它将预测的矩阵分解为两个较小的因素矩阵,如图1 所示。

图1 矩阵分解图示
U×M矩阵中的每个值代表用户u(行)对电影m(列)的预测评分。将该矩阵分解为两个维度分别为U×f和f×M因素矩阵P和Q,以简化评级数据的存储。f是潜在因素的数量,此处f=2,例如因素f1与f2。具体地,它们可能代表“动作”、“喜剧”等特征。每个评分可以由从两个因素矩阵中分别提取的两个因素向量的乘积表示:

此处假设qm与pu都初始化为列向量。于是qm的转置作为因素行向量表示电影m的特征分布(正或负值),pu作为因素列向量记录了用户u的兴趣分布(正或负值)。以下是一个简单的示例,
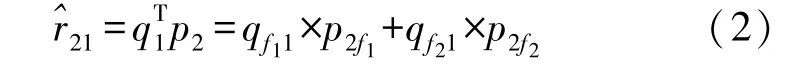
公式(3)说明使用MF 的原因是有效降低了空间复杂性。
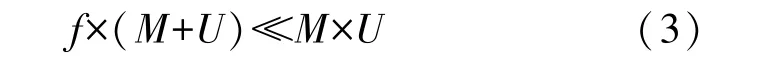
M×U是原始数据空间的大小;f≪M,f≪U;f×(M+U)是应用MF 后减小到的空间大小。
我们把以上模型称为基础MF 模型。基础MF 模型要求在显式反馈条件下使用,该显式反馈指的是用户u在电影m上的实际评分,例如rum。如果没有显式反馈,则使用隐式反馈,是一种间接反映用户偏好的方法,包括购买记录、浏览历史记录或鼠标移动等[8]。
1.3 随机梯度下降算法
基于如上所述的MF 模型,使用随机梯度下降[9]作为训练算法。为了减小预测误差,在此方法中应使用误差方程eum。

分别求关于pu和qm的导数。根据导数结果的正或负值,添加或减少一个参数值以修改假定的。L和K均为常数,用于数据规范化,经过预测试选取L=0.001,K=0.02。

值得注意的是,每个特征都应被单独训练。每次循环将在先前训练的所有特征找到最优值后,生成这轮训练中特定特征的最优值,以便能最大程度地减小误差。一个完整的循环包括对固定数量的所有特征进行训练。
1.4 均方根误差
基于稀疏矩阵的实际评分以及经过SGD 算法训练后获得的预测评分,有必要评估预测准确度以实现优化目的。最终的目标是最大程度地减少预测误差,从而提高预测的准确度。使用均方根误差(Root Mean Square Error,RMSE)作为评估标准。

式中,rum是实际评分值;是预测值;S是(u,m)的全集合;N是评分总个数。RMSE∈[0,1],其中RMSE=0 表示无误差,RMSE 越接近1 表示准确度越低。
Koren Y 和他的团队获得NETFLIX 奖第一名的解决方案添加了时间动态分析,并包含超过100 亿个电影与用户特征,最终得到的最小RMSE 为0.880[10]。与该团队获得此奖项时的市场产品相比,准确度提高了10%。本研究的最终目标是实现并继续提高预测准确度。
1.5 具有静态偏置的MF 模型
为了对基础MF 模型进行优化,将考虑另外一个因素——偏置。如下列公式所示,μ表示所有电影的总平均评分,bm与bu分别表示对特定电影m以及固定用户u的评分与平均水平之间的偏置。
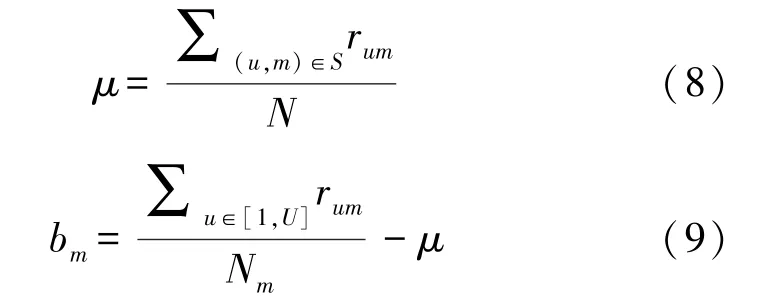
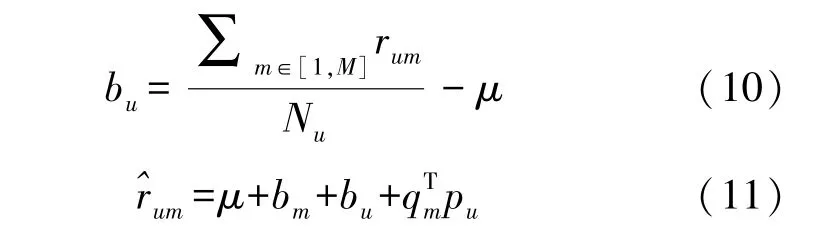
M是已知实际评分的总数量;Nm是评价电影m的用户数;Nu是用户u评价的电影数量。式(8)~式(10)分别计算偏置μ、bm和bu。如公式(11)所示,是考虑了所有偏置值的预测值计算。由于μ、bm和bu偏置固定不变,所以称为静态偏置。
1.6 具有动态偏置的MF 模型
对于一个创新的SGD 算法,将偏置bm和bu首先初始化为0,与被训练的训练特征值同时进行动态训练,这样在MF 模型中就形成了动态结构。训练的核心思想仍然是梯度下降。
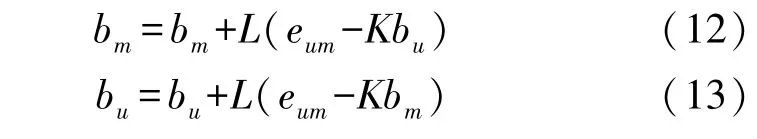
式中:m代表随机电影,而u代表随机用户;L=0.001,K=0.02。最终,误差eum和RMSE 的计算都应考虑训练过程中的动态偏置值。
2 算法训练
本研究的数据集包括了2 649 429 位NETFLIX用户,训练过程一共需经过120 轮循环。每次全新独立的训练过程都包含四个基本设置参数,分别是MF 模型的类型、用户数量、电影数量和特征数量。MF 模型有三种不同的类型:基础MF 模型、具有静态偏置的模型(静态MF 模型)和具有动态偏置的模型(动态MF 模型)。默认情况下特征数量为40[9],并且所有用户特征值和电影特征值即因素矩阵P和Q中的所有数据都统一初始化为0.1。
训练评估应将数据集分为训练集(随机选择90%)和测试集(10%)。训练集用于算法的实现,得到可靠的MF 模型;测试集旨在检查训练结果的真实准确度,并检验算法与模型的可靠性。训练集和测试集都应生成RMSE,训练集的RMSE 旨在证明SGD 的功能性,而测试集的RMSE 则用于评估其功能性的实际表现。每次循环训练或测试都应该产生一个RMSE 值,在所有训练或测试结束之后,以循环次数为横坐标轴、RMSE 为纵坐标轴绘制结果曲线图。
2.1 训练步骤
根据前面算法和模型,设计对数据集的训练步骤如下:
(1)固定一个特征因素fn,n的初始值为1;
(2)基于特征因素fn;
(a)遍历实际评分矩阵R中所有用户对所有电影的实际评分值,每次遍历得到第u位用户对第m部电影的评分rum;
(b)对第u位用户、第m部电影,根据公式(1)计算预测评分值;
(c)在中添加静态偏向值——计算对应电影m的偏向值bm,计算对应用户u的偏向值bu
(d)根据公式(4)得到误差eum;
(e)应用随机梯度下降算法,根据式(5)、式(6)更新对应电影m的特征向量qm、对应用户u的特征向量pu;
(f)使用新的特征值计算特征因素fn下第u位用户对第m部电影的预测评分值rum;
(3)进入下一个特征因素fn+1,重复(2),直至计算出所有的特征因素下所有用户对所有电影的预测评分值rum;
体育活动能够增强运动者的体魄、舒缓运动者压力以及促进运动者身心健康发展。由于体育活动是一个长期过程,因此,要提高体育运动的效果,就必须“从小开始”,即必须注重对小学生的体育行为与习惯的教育。近年来随着新课标的贯彻落实,小学体育学科教学得到了快速的发展。在新时代背景下进一步明确体育学科教学发展方向并进行实践创新,是进一步推动小学体育学科教学发展的重要保障。
(4)总共重复(1)~(3)120 次进行循环预测计算。
2.2 训练准确性
2.2.1 不同MF 模型的比较
表3 列出了三种不同类型MF 模型的基础参数,电影数量是5 000,特征数量是40,由此训练出的训练集RMSE 变化趋势如图2 曲线所示。

表3 图2 基础参数设置
RMSE 越小意味着预测准确度越高。根据图2,具有被训练偏置的动态MF 模型由于RMSE 最小(0.816)表现最佳,与无偏置和静态偏置模型相比分别提高了10.4%和6.42%。因为偏置的添加会让电影受欢迎程度或用户偏好程度明确体现在预测评分值中。而偏置经过迭代动态训练,会更加突出这些个性化程度。

图2 三种MF 模型的训练集RMSE
图3 显示了三种不同类型MF 模型分别针对训练集与测试集RMSE 值的变化趋势对比,表4 则列出了图3 中所有情况下的RMSE 终值。
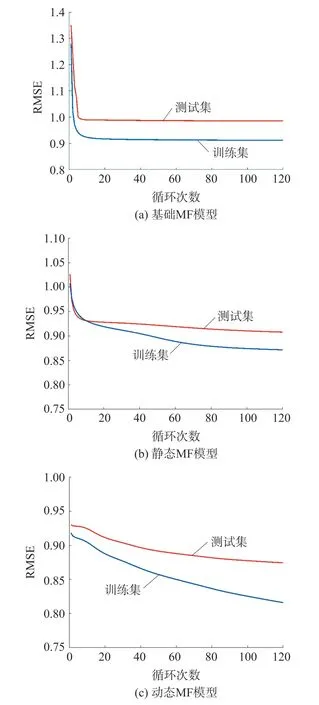
图3 训练集与测试集RMSEs
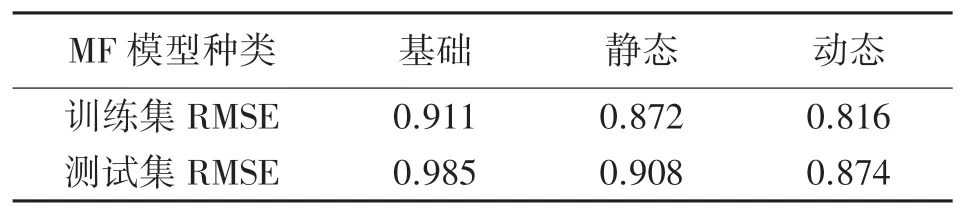
表4 不同模型设置下RMSE 的终值
根据表4 中数据进行如下计算,以对比不同MF模型对应的RMSE 值即预测准确度。
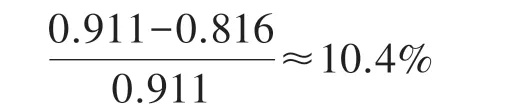
(2)动态模型训练集相比静态模型训练集RMSE 值减少百分比:
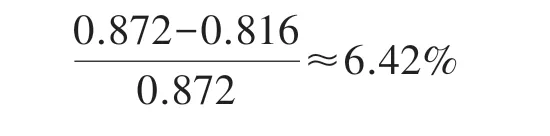
(3)测试集相比训练集RMSE 值平均增加百分比:

(4)静态模型测试集相比基础模型测试集RMSE 值减少百分比:
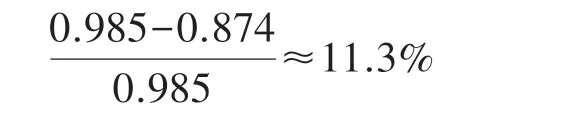
(5)动态模型测试集相比静态模型测试集RMSE 值减少百分比:

测试集的RMSE 平均比训练集的RMSE 大6.45%。这种准确度的降低是正常现象,同时表明该算法是可靠的,因为测试和训练集之间的准确度差异小于10%,即6.45%<10%。此外表4 显示,经过训练的偏置与静态偏置相比,静态偏置与没有偏置相比,分别将测试集的预测准确度提高了3.74%和11.3%,证明了动态MF 模型能有效地提高推荐系统的预测准确度。
2.2.2 动态MF 模型中不同特征数量的比较
表5 列出了训练动态MF 模型时不同特征数量的基础参数设置,电影数量为5 000,特征数量为20、40、80、160。

表5 图4 基础参数设置
依据图4 中4 种不同特征数量设置下的训练集RMSE 变化趋势,表6 列出对应的训练集与测试集的RMSE 终值。
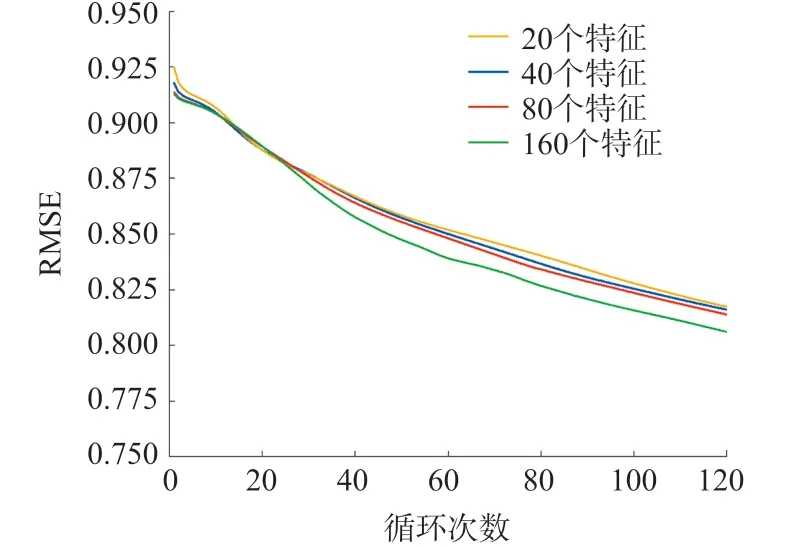
图4 不同特征数量的训练集RMSEs
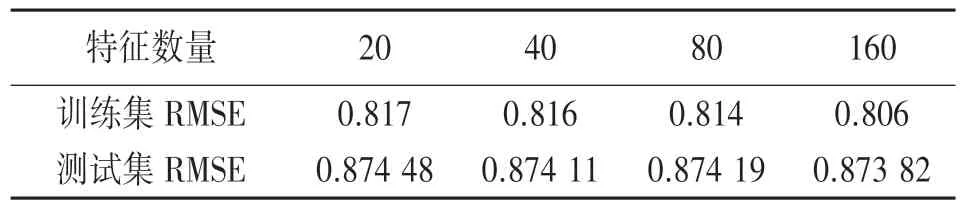
表6 不同特征数量的训练集RMSE 终值
根据表6 中数据,相关RMSE 值比较如下:
(1)训练集中特征数量成倍增加时RMSE 值减少百分比:

(2)测试集中特征数量成倍增加时RMSE 值减少百分比:

不同特征数量对应的训练集RMSE 值曲线见图4。随着特征数量的增加,RMSE 减小,这意味着更多特征可以更准确地描述电影属性和用户兴趣。但是,总结了详细RMSE 值的表6 指出,在训练和测试中,特征增加只会稍微提高准确度。经过计算,翻倍的特征数量仅能够使RMSE 减少最多1%,说明特征数量增多对预测准度的提高影响细微。但可以观察到,随着翻倍次数增多,RMSE 减少百分比呈类指数性增长。所以,针对特征数量对预测准确度的影响,只有设定大量特征数量供训练验证,比如500 个~1 000 个特征,才有可能实现较显著的准确度提高。但实际上,复杂化的特征数量设置会大大增加执行时间,从而降低了推荐系统的实用性。所以特征数量不需过大,通过试验进行利弊权衡,找到合适的数值即可。
2.2.3 数据集中包含不同电影数量的比较
表7 列出了动态MF 模型训练时不同电影数量的基础参数设置,电影的数量为1 000、2 000、5 000、9 000,特征数量固定为40。

表7 图5 基础参数设置
不同电影数量的训练集RMSE 变化曲线见图5,图中说明训练更多电影预测准确度会更高。
表8 是依据图5 的不同电影数量的训练集RMSE 列出的4 种不同电影数量的训练集及测试集RMSE 终值。

表8 不同电影数量的RMSE 终值
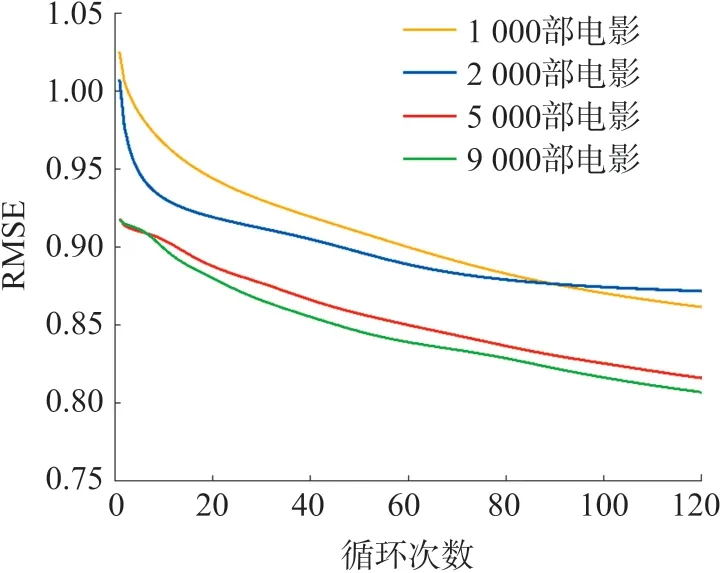
图5 不同电影数量的训练集RMSE
根据表8,不同电影数量的RMSE 数据比较如下:
(1)训练集中电影数量从1 000 到5 000,每增加1 000 部时RMSE 值平均减少百分比:

训练集中电影数量从5 000 到9 000,每增加1 000 部时RMSE 值平均减少百分比:
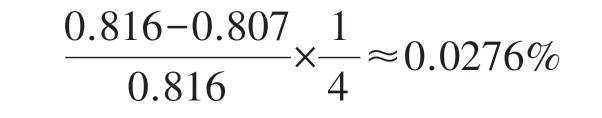
(2)测试集中电影数量从1 000 到5 000,每增加1 000 部时RMSE 值平均减少百分比:

测试集中电影数量从5 000 到9 000,每增加1 000 部时RMSE 值平均减少百分比:
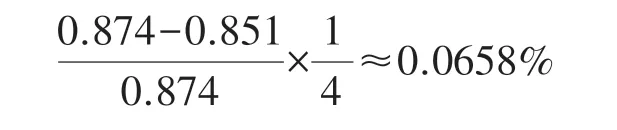
根据表8,在数据集中每增加1 000 部电影,训练和测试中RMSE 总体下降平均都只有约1%,而当电影数量持续增大时,下降幅度甚至都小于0.1%。因此,累计增加的电影数量越多,尽管预测准确度会有效提高,但增加幅度会逐次递减,这与增加数量导致的运行内存与时间增长相比,弊远大于利。当然,如果拥有高性能处理器的计算机,就能够解决运行内存的瓶颈,增加包含特征数量与电影数量等训练参数则可以有效提高推荐系统的准确度。
此外,表中存在一个例外结果:将电影编号从1 000 增加至2 000 时,训练集的RMSE 增加而不是减少。这可能是由于,增加的1 000 部电影的所有特征值在训练过后仍然相同或仍为初始值而导致的。添加的1 000 部电影(第1 001 部到第2 000 部电影)可能都具有相似的特征属性,而它们的真实特征值可能都远大于或远小于初始值0.1。因此,即使经过一些训练,预测的特征值仍然与其真实值相差很远,所以准确度仍然很低,甚至低于电影数量更少的情况。更多的训练次数可能会解决这个问题。另外,新增的1 000 部电影可能都是新电影,几乎没有用户提供实际的评分数据,所以他们无法在训练中体现他们的特征偏置。
值得一提的是,NETFLIX 奖获胜者Y.Koren 团队的推荐系统对比使用了多种方法,包括静态偏置的MF 模型、隐式反馈模型以及多种时间动态模型,最终测试集得到的最优RMSE 为0.880[10-12]。从表9 中可看出,其最优RMSE 值对应的参数设置包含上亿级的特征数量,其使用的数据集包含了全部(1.8 万)NETFLIX 电影。而本文最终选取的拥有最高推荐准确度的数据集仅仅使用了40 个特征和9 000 部电影,该数据模型最终却实现了将测试集的RMSE 降低到0.851。与获奖者相比,预测准确度提高了3.3%。
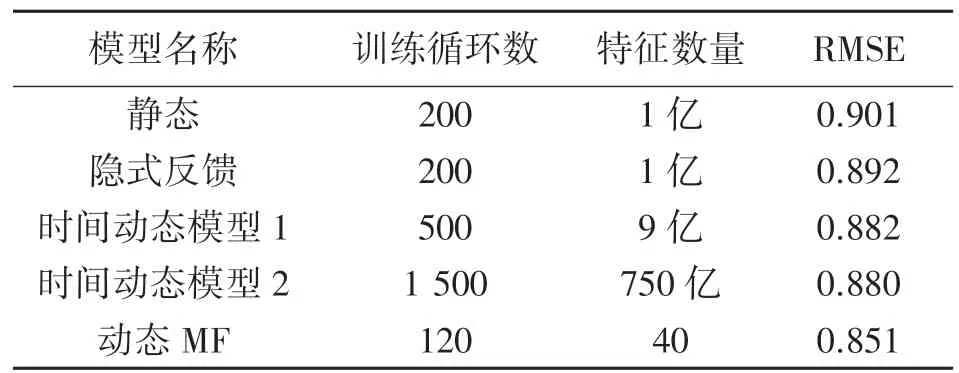
表9 不同推荐系统训练模型准确度对比
总之,SGD 算法以及动态MF 模型可以在数据有限的条件下,为用户提供更准确的推荐。
2.3 特征分布
图6(a)和(b)分别显示了基于5 000 部电影和9 000 部电影在动态MF 模型、40 个特征设置下随机选择10 个电影的特征预测分布。包含更多电影的训练使得随机选择的电影在二维坐标中分布在更准确的特征位置。图中,X轴表示“喜剧”特征值,两部喜剧«Forbidden Zone»和«Blow Dry»在X轴上显然为正。另一个特征值是“幻想主义”,其中惊悚片«Under Siege»在Y轴上出现在较大正值区域,而纪录片«Dinosaur Planet» 和«Last of the Mississippi Jukes»则明显在Y轴负值区域。以上表明,基于动态MF 模型的SGD 算法能比较准确地预测各类型电影的具体特征。
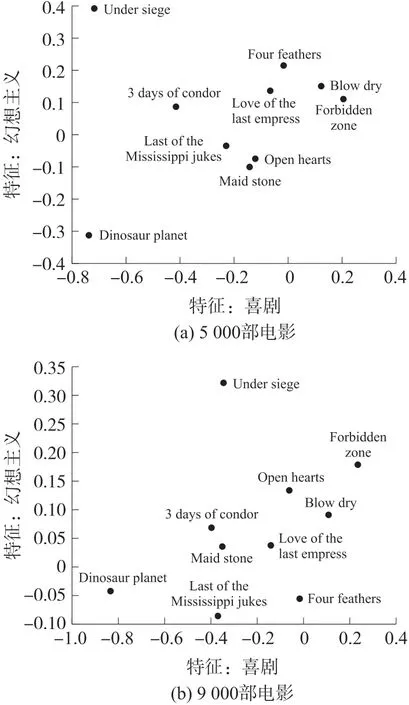
图6 特征分布
3 结论
本文基于NETFLIX 平台9 000 部电影的用户评分数据集,在MATLAB 环境中研究了一个可靠的电影推荐系统。此推荐系统有效预测计算了电影的观众评分,在数据集与特征数量远远小于一般市场所用的情况下,将预测准确度提高了3.3%。动态MF 作为简化的数据模型可以高效地处理数据。同时,基于具有动态偏置的MF 模型的SGD 训练算法设计可用于提高推荐系统的预测准确度。此外,提高推荐准确度的潜在方法是通过设置适当数量的特征并扩大电影范围。最终,每位用户都可以获得具有其个人最高预期评分、可靠的个性化电影推荐。
猜你喜欢
汽车实用技术(2022年15期)2022-08-19
中国信息化(2022年5期)2022-06-13
科海故事博览·下旬刊(2022年4期)2022-05-07
数学小灵通(1-2年级)(2021年10期)2021-11-05
小学生学习指导(低年级)(2019年3期)2019-04-22
电子制作(2017年13期)2017-12-15
价值工程(2016年32期)2016-12-20
北京航空航天大学学报(2016年6期)2016-11-16
小猕猴智力画刊(2016年6期)2016-05-14
