
基于Python的新浪微博爬虫程序设计与实现
2022-07-17 12:16孙握瑜
科技资讯 2022年12期
孙握瑜



摘要: 在互联网时代,各类新媒体平台出现使得信息数据得到广泛传播。为加强对新浪微博内容的监管和分析,应对舆情分析的需求,该文主要研究采用Python语言设计新浪微博爬虫程序,在对网络爬虫基本概念和原理研究的基础上,设计了具有配置、爬取、存储、分析这4个功能模块的应用程序,为媒体内容监管和数据分析提供了技术支持。
关键词: Python 新浪微博网络爬虫舆情分析
中图分类号:TP393.092;TP391.1 文献标识码:A 文章编号:1672-3791(2022)06(b)-0000-00
Design and Lmplementation of Sina Weibo Crawler Program Based on Python
SUN Woyu
(School of Information and Artificial Intelligence, Anhui Business College, Anhui Province,241000 China)
Abstract: In the era of information explosion, various new media platforms appear to make the information and data widely disseminated. In order to strengthen the management of sina Weibo information and meet the needs of public opinion analysis, this paper focuses on the design of sina Weibo crawler program in Python language. Based on the research on the basic concept and principle of web crawler, an application program with four functional modules of configuration, crawling, storage and analysis is designed, which provides technical support for media content management and data analysis.
Key Words: Python; Sina Weibo; Web crawler; Public opinion analysis
隨着互联网技术的快速革新,新媒体平台层见叠出,广大网民可以通过互联网平台发表观点和记录日常生活,各类消息事件也得到了广泛传播,为我们带来了信息爆炸的时代,拓宽了广大人民群众的视野,同时也带来了一系列舆情风险。对社交网络舆情的有效监管,是在新形势下应对国家安全环境新变化、新发展的必然要求[1]。新浪微博自 2009 年正式投入使用以来,活跃用户就一直保持着爆发式增长[2],2021年微博月活跃用户达到5.3亿,日活跃用户达到2.3亿,用户年轻化趋势明显。尽管抖音、快手等短视频类平台不断崛起,但是由于文字内容更新速度的优势,新浪微博仍然是公共事件爆发的原点和信息传播平台。
在日常工作中,需要管理好本单位或组织的新浪微博资讯,像高校等组织管理账号较多,人工监管显然是跟不上信息更新速度的,这就需要利用软件技术自动抓取和分析新浪微博信息。尽管一些第三方软件提供了新浪微博部分数据访问接口,使管理人员内容较为快捷地抓取一些信息,进行舆情分析。但是通过访问接口抓取数据容易出现被限制情况,从而导致接口服务被禁用,而且数据还可能出现不精准的情况。该文主要参数使用Python技术设计开发新浪微博爬虫程序,用于分析获取指定微博用户的舆情信息,为做好舆情分析提供基础的数据来源。基于Python开发的网络爬虫云平台具有开发周期短、应用便捷、技术维护方便等优点[3]。
1相关概念
1.1 Python
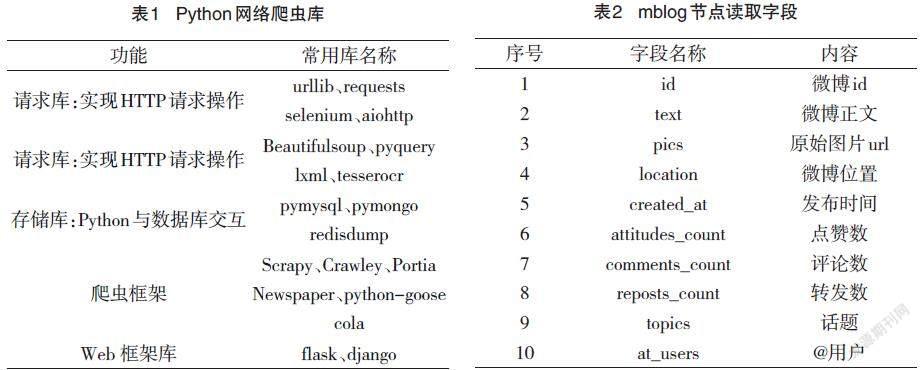
近年来,大数据、AI和物联网等技术不断兴起和革新,Python已经成为当前流行的编程语言之一。Python从本质上来说属于一种开源编程语言,其具有功能强大、语法简便、适用性良好等优势特性[4]。它是一种跨平台的面向对象计算机程序设计语言,可以很方便地调用别的语言(如C++、Java)编写的功能模块,将它们有机结合在一起形成更高效的新程序。另外,Python有着丰富、强大的库支持,比如:基于Python 的网络爬虫库就非常完备,如表1所示。
1.2 网络爬虫概念和原理
爬虫就是通过编写程序模拟浏览器上网,按要求在网上抓取数据的程序[5],可以按照设定的规则自动获取互联网上的信息。网络爬虫根据不同的系统结构和运作原理分为四种类型,该文采集新浪微博的数据信息主要使用通用网络爬虫。除此之外还有深层、聚焦和增量式等三种类型网络爬虫,下面主要对通用网络爬虫的原理进行详细介绍。
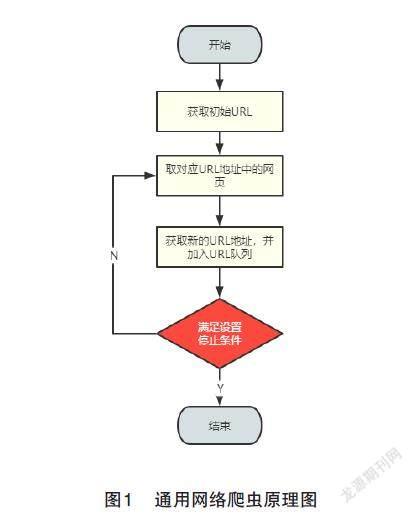
通用网络爬虫可以将互联网上的Web页批量爬取并下载的本地进行存储,其实现过程如图1所示。
首先根据需要,由用户指定初始URL。然后根据URL保存对应的网页内容到数据库中,对其页面中的内容进行解析,获取页面中一系列URL地址,把这些URL地址加载到URL队列中。接下来对新获取的URL地址不断进行重复解析和存储,直到满足设置的停止条件,如没有设置停止条件,爬虫会不断工作下去。另外在爬取网页的过程中,会不断将爬取过的网页URL存储到列表中,作为参照避免重复爬取。
2新浪微博爬虫程序设计
2.1 爬虫设计思路
首先配置一个或多个需要获取的微博用户,其中包括微博UID、微博名称等,并配置其他相关属性,用较为简便的方法完成数据采集。由于新浪微博Web版页面请求被JS加密过,因此抓取移动端页面较为简便一些。首先,在电脑上访问移动端页面,并同时保持用户登录状态,才能访问指定用户的页面。通过观察发现页面URL的规则是“https://m.weibo.cn/u/用户编号”,通过提交该请求会返回格式如getIndex?type=uid&value=用户编号&containerid=107603+用户编号的JSON信息,如图2所示。JSON是一种轻量级的数据交换格式,易于阅读和编写,也易于机器解析和生成[6]。JSON数据主要返回微博内容、发布时间、浏览数、点赞数、分页数等内容,只要使用Python对JSON信息进行解析分析,获取其中需要的内容,然后再根据分页数逐个获取每一页的微博信息,最终完成抓取任务。
2.2 功能实现
按照网络爬虫的原理和爬虫程序设计思路,程序共包括四大模块。
2.2.1配置模块
主要配置用户UID、微博名称、信息开始时间、存储数据格式等信息,并把配置信息加载到对象中,可以是同时配置多个指定用户微博。
2.2.2爬取模块
通过配置对象初始化爬虫信息,然后获取微博页数,然后根据页码数进行循环抓取每一页的内容。在每页信息抓取过程中,需要将JSON信息中的data节点中的cards节点内容加载到对象中,如果card_type=9,进一步读取mblog节点中的内容,具体对应关系表2所示。在抓取的过程中为避免爬虫速度过快被系统限制,通过加入随机等待避免被限制,模拟人工操作的特征,每访问一些页面适当的随机等待一段时间。在系统设计中,我们采用每爬取1~5页随机等待6~10 s,其中这个Sleep时间可以根据实际情况进行调整。通过实践证明该方法可以基本上规避被系统限制的情况。
2.2.3存储模块
通过爬虫程序的不断抓取,在指定范围内容的每页微博信息均完成了采集工作,为了后期数据分析,需要进行存储。对于海量数据存储来说,需要用到Mangodb等数据,该文设计的爬虫程序只针对于单个用户的微博信息,内容较少,因此只采用csv格式进行数据存储,通过Python创建csv文件,每爬取50页信息写入一次文件,存储完成的文件如图3所示。在记录信息的通知还可以下载与微博信息对应的原始圖片。
2.2.4分析模块
舆情分析主要根据网络爬虫获取并存储的网络数据,在该文中使用 Python开发设计爬虫程序,指定对“安徽商贸职业技术学院”的新浪微博数据进行抓取,然后对其发布内容、参与话题圈、@用户情况和@话题圈情况进行了可视化分析,如图4~图6所示。通过可视化的分析,可以看出安徽商贸职业技术学院微博主要以发布气象、固定时间问候为主,另外还发布诗集、要闻、通知等。参与话题圈众多,主要以体育、娱乐、节气、政治节日、重要事件等为主,多为正能量较强的话题。在发布内容时,主要@的用户有人民日报、央视新闻、新浪视频、新浪音乐等,和发布的话题类型也是相符的。另外最后还可以看出@的话题圈也与上述分析的结果是一致的。
3 结语
经过分析研究,采用Python 语言设计新浪微博爬虫程序,在程序设计上语法简便、功能强大,且具有较高的可行性。程序通过配置、抓取、存储、分析四大模块,抓取新浪微博指定用户的内容,并进行数据分析。实验结果表明:该爬虫性能稳定良好,爬取内容全面无遗漏,可以对指定用户的新浪微博信息进行抓取,并且对数据进行储存,可视化分析能够直观地了解微博的运行状态,实用性很强。
参考文献
[1] 张柳. 社交网络舆情用户主题图谱构建及舆情引导策略研究[D].长春:吉林大学,2021.
[2] 孟宝灿.Python网络爬虫应用探讨[J].广播电视信息,2022,29(3):108-110.
[3] 毕志杰,李静.基于Python的新浪微博爬虫程序设计与研究[J].信息与电脑:理论版,2020,32(4):150-152.
[4] 杜晓旭,贾小云.基于Python的新浪微博爬虫分析[J].软件,2019,40(4):182-185.
[5] 于学斗,柏晓钰.基于Python的城市天气数据爬虫程序分析[J].办公自动化,2022,27(7):10-13,9.
[6] 黄秀丽,陈志.基于JSON的异构Web平台的设计与实现[J].计算机技术与发展,2021,31(3):120-125.
猜你喜欢
读者(2021年20期)2021-09-25
现代信息科技(2021年21期)2021-05-07
计算机与网络(2020年11期)2020-07-29
智能计算机与应用(2018年5期)2018-10-20
电脑知识与技术·经验技巧(2018年1期)2018-05-30
花火B(2017年8期)2017-09-13
消费电子(2016年12期)2017-01-19
网络传播(2014年12期)2015-03-16
网络传播(2014年11期)2015-01-14
环球时报(2009-09-29)2009-09-29
