
基于混合域注意力机制的鞋印检索算法
2022-07-19 08:20韩雨彤唐云祁张家钧
中国人民公安大学学报(自然科学版) 2022年2期
韩雨彤, 郭 威, 唐云祁, 张家钧
(中国人民公安大学侦查学院, 北京 100038)
0 引言
鞋底花纹特征是犯罪侦查过程中极具价值的证据之一,但鞋印痕迹检索在实践应用中发挥的作用大小受到图像特质、设备引擎、算法技术以及专业职业素养等因素的影响。根据Alexandre[1]的报道显示,在犯罪现场中,大概有30%的现场鞋印可以被提取,但这些被提取的鞋印不一定都能成为侦查破案的线索。 在现场勘查中,通过摄影或者静电吸附的方式将鞋印从地面提取,通过扫描来实现数字化。鞋印图像检索任务如图1所示,给定一个犯罪现场提取的嫌疑鞋印,调查人员在数据库中搜索出与之较为相似的清晰的样本鞋印。在公安实践中,这一检索过程需要调查人员在一个大型的图像数据库中手动搜索,会造成巨大的人工成本和时间成本浪费。因此,将基于计算机视觉的图像自动检索技术引入鞋印检索领域,并在公安实践工作中发挥作用是非常重要的一项工作。

图1 鞋印检索任务
1 相关工作
在多年的鞋印自动化检索研究过程中,研究人员提取不同鞋印图像特征,如形状特征,纹理特征等经典图像特征,将其作为特征描述符进行特征检索,并都在当时取得了较好的识别效果。
近年来,随着卷积神经网络在各个领域的广泛应用,鞋印检索算法的研究方向也逐渐发生转变,很多研究人员以神经网络作为基本架构,训练大量鞋印图像数据,以期让计算机自动提取鞋印图像特征,并根据提取到的特征,计算特征距离进行匹配。
Zhang等人[2]对预训练的VGG-16[3]网络进行了微调,该网络在公开数据集[4]上取得了良好的效果,但该方法没有对残缺鞋印图像进行实验,存在一定的局限性。史文韬等人[5]将预训练的VGG-16网络在鞋印数据集上进行了微调并直接展开卷积层特征进行检索实验,该实验证明微调的VGG-16网络对残缺的鞋印图像检索效果并不理想。之后,史文韬[6]等又提出了基于选择卷积描述子的算法,并将完整鞋印和残缺鞋印分开检索,提取不同的卷积特征进行检索,其在CSS-200数据集上top1%的识别率达到了92.5%。Kong等人[7-8]将ResNet50网络提取到的卷积神经网络对图像的深度特征采用多通道归一化互相关的方法进行匹配。该算法在公开数据集FID-300上取得了较好的检索效果。但是该方法由于通过滑动窗和一定角度之间的旋转获得了多个局部区域,在检索过程中耗费了大量时间,并不适用于实际应用中。
Cui等人[9]采用深度信念网络(Deep Belief Networks,DBN)提取局部特征,并通过空间金字塔匹配得到从局部到全局的匹配分数。在该实验中,前10名的累计匹配得分为65.67%。Cui等人[10]对鞋印图像进行预处理,旋转补偿之后划分图像为顶部和底部两区域,计算两个区域神经编码的余弦相似度的加权和,得到两张比对图像的匹配分数。经过实验,top10%的累计匹配分数为88.7%。该法经过PCA降维后发现,当降低至原图像特征的95%时检索精度最高。
Ma等人[11]在2019年使用多部分加权卷积神经网络(Multi-Part Weighted Convolutional Neural Network,MP-CNN)提取鞋印特征,在FID-300数据集上进行实验,top10%的识别率达到了89.83%。
张弛等人[12]使用LeNet-5网络在183类鞋印数据集上进行分类,top5%的分类准确率为99.49%。Wu等人[13]利用基于领域的相似度估计,提取了鞋印图像的区域特征、全局特征和Gabor特征,提升了鞋印检索算法的性能。
大连海事大学周思越[14]提出了一种基于局部语义滤波器组的低质量鞋印检索算法,该算法采用相似度曲线封闭区域面积的多相似度自适应融合方法,在MUES-SR10KS2S、FID-300和CS-Dacabase上实验都取得了优秀的检索结果。但由于数据依赖大量人工处理,因此检索结果并不稳定。
2019年彭飞等[15]基于局部语义块并改进了流行排序的鞋印检索算法,在低质量鞋印图像数据集上的top1%的识别率达到了90.3%。
通过对近几年鞋印检索领域经典方法的归纳梳理,卷积神经网络在鞋印图像中提取到的是全局特征,对于残缺鞋印的检索效果有限,因此自动提取细节特征、提升残缺鞋印的检索精度仍然是当前研究的重点。基于此,本文提出了一种嵌入混合域注意力机制的鞋印检索算法,对预训练的ResNet34网络加入注意力机制后在鞋印数据集上进行微调,提取改进网络中layer2和layer4的卷积层特征,直接展开作为特征描述符。实验结果表明,该方法能够有效提升残缺鞋印的检索效果。
2 算法结构
2.1 混合域注意力机制
注意力机制在机器翻译领域率先应用,经过迁移发展,在深度学习领域大放异彩。卷积神经网络依靠卷积核获取通道和空间信息融合来提取图像特征,注意力机制具有可以使神经网络具备专注于输入特征的能力。因此,神经网络加入注意力机制模块后获得需要重点关注的区域,在卷积特征的重点区域产生更大响应。在计算机视觉领域中,研究人员将注意力机制与深度学习结合使用,并注重使用掩码形成一层新的权重特征,将图像中的关键特征进行标识,以此来让神经网络学习到更重要的区域。基于此种思想,注意力机制形成了两种不同的类型,一种是软注意力机制,另一种是强注意力机制。本文则更加注重通道域和空间域的软注意力,希望以此提高鞋印的检索效果。
2.1.1 通道注意力机制
通道注意力机制(Channel Ateention Module,CAM)目的是在神经网络对图像进行检索的过程中提高对各通道的依赖性,并对各通道进行调整,选择图像中的有用的信息,加强图像特征的选择性。
在本文中,虽然鞋印图片在预处理阶段经过二值化变为单通道图像,但在输入神经网络时均转换为普通的RGB三通道图像。图像经过不同的卷积核后,在各个通道中产生的不同的信号作为该通道的特征表示。
假设图像经过卷积核输出卷积特征U,U有C个通道,输出U不是最优的特征。因为每个通道的重要程度不一样,所以,在提取特征时,有些通道提取到的特征更加重要。我们希望通过注意力机制学习并重新分配每个通道的权重,从而获得基于通道的注意力。在通道注意力机制中(如图2),图像经过卷积层提取到特征,分别经过基于宽度和高度的最大池化层和全局平均池化层,再经过两个全连接层,将两个特征矩阵拼接在一起,经过sigmoid激活函数后生成带有注意力的特征矩阵。将输入通道注意力机制前的矩阵和经过通道注意力机制的特征矩阵相乘作为整个通道注意力机制的输出。通道注意力模块公式为:
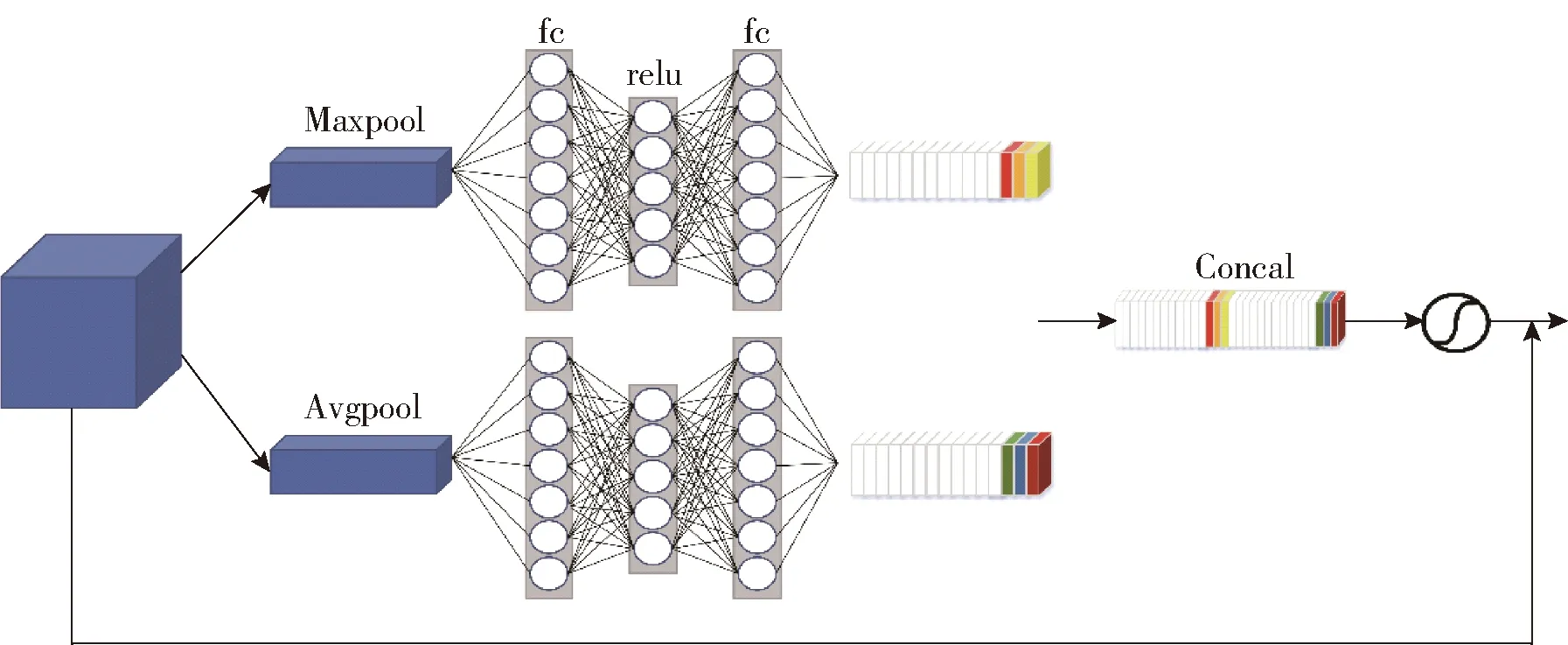
图2 通道注意力机制结构图
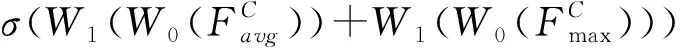
(1)
其中W0∈RC/r×C,W1∈RC×C/r,两个全连接层中间需加入一层Relu函数激活。
通道注意力机制模块结构如图2所示。
2.1.2 空间注意力机制
空间注意力机制(Spatial Attention Module,SAM)是将原始图片中的空间信息映射在另一空间中并保留其关键信息。空间注意力模块作为单独一层加入到原有的神经网络中,并与通道注意力模块一起发生作用。这个模块依旧以上一层的输出特征矩阵U作为该模块的输入:
U∈RH×W×C
(2)
H是上一层特征矩阵的高度,W是上一层特征矩阵的宽度,C是代表通道数。U输入空间注意力模块后进入两条线路,一条线路是信息进入定位网络,另一条线路是原始信号直接进入采样层,其中定位网络经过学习会生成一个变换矩阵,与原始图片相乘之后,可以得到变换之后的矩阵V。
V∈RH′×W′×C
(3)
V是变化之后的图像特征。
如图3所示,在采样路线中,首先对通道进行最大池化和平均池化降维,再使用一个卷积层进行学习,将图像特征降为单通道。在经过sigmoid函数生成变换矩阵。同通道注意力模块一样,空间注意力的输出特征也要与输入特征相乘作为最终空间注意力模块的输出特征。

(4)
其中,7×7为卷积核的大小
空间注意力机制模块结构如图3所示。
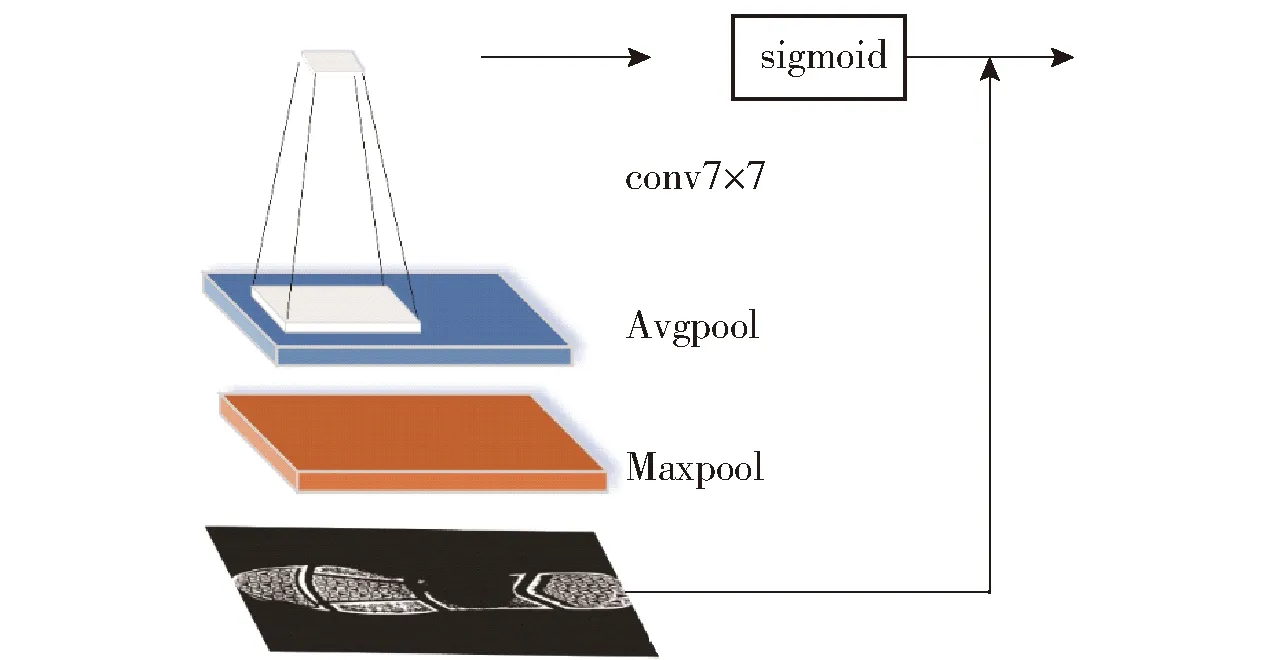
图3 空间注意力机制结构
2.1.3 嵌入混合域双重注意力机制网络
本文在ResNet34骨干网络中嵌入注意力机制并基于迁移学习进行训练。由于注意力机制放入残差模块中将会改变ResNet34的网络结构,无法进行迁移学习,因此,我们在网络的第一层卷积层和最后一层残差模块后分别加入混合域的注意力模块,将通道注意力机制和空间注意力机制融入ResNet34骨干网络,网络结构如图4所示。
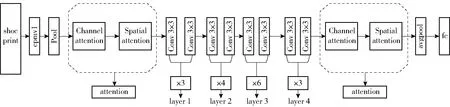
图4 本文网络结构
2.2 提取多层卷积特征融合
在很多的图像检索工作中,融合不同尺度的卷积层特征是提高神经网络检索能力的一个重要手段。低层卷积特征具有更高的分辨率,提取到的特征更加具象,用于度量细粒度相似性,但是由于经过较少的卷积层,具象的特征不能很好地作为图像检索的特征,具有更低的语义性。高层卷积特征提取到的特征更加抽象,不能很好的感知细节,用于度量语义相似性,因此,融合高层卷积特征和低层特征在图像检索中可以获得更好的检索效果。Chaib等[16]提取VGGNet中第一层和第二层全连接层的输出进行融合作为特征描述子,分别采用标准融合和DCA融合两种方法,经过实验证明融合不同层的特征取得了当时最高的精度。Wei等人[17]设计了一个新的映射函数来突出低层的相似性,利用不同卷积层之间的互补特征作为特征描述符进行图像检索,并取得了优于流行检索方法的检索效果。Zhang等人[18]融合了语义分割网络中的高低层特征,增加了低层特征的语义或增加高层特征中的空间信息都带来了一定程度的提升效果。本文提取嵌入注意力机制的ResNet34网络layer2和layer4层的卷积特征直接展开拼接进行鞋印检索实验。
3 实验结果及分析
3.1 实验数据集
3.1.1 训练集
本文在CSS-200[5]的原始数据上进行了不同形式的裁剪,使得残留的鞋印范围更加小,提高模型的鲁棒性。鞋印原始数据来自某市公安机关2018年8个月的犯罪现场鞋印图像和与之对应的嫌疑人标准采集鞋印,共筛选出437类鞋印图像,其中210类为样本鞋印,每类4幅,其余227类鞋印包含嫌疑人样本鞋印和对应的现场鞋印。每类2~50幅。首先,本文对鞋印图像先进行低质量处理来模拟犯罪现场的鞋印,对图片添加高斯噪声,再用Sobel算子提取鞋印图像的边缘特征,如图6;第二步裁剪,文献[5]中对鞋印做了8种不同方式的裁剪,虽然8种裁剪方式尽可能的包括了现场可能出现的各种残缺部分,但是保留下的残缺鞋印面积仍然较大。本文对鞋印图片进行重新裁剪,裁剪出不同的6种残缺的鞋印,如图5,更好地模拟鞋印在现场会出现的残缺和模糊情况。最终经过新一次数据增强,训练集中包含437类,共141 646幅鞋印图像。

图5 训练集鞋印图片的随机裁剪方式

图6 训练集鞋印图片的低质量处理方式
3.1.2 CSS-200测试集
CSS-200测试集和训练集均是来自公安机关的现场鞋印和嫌疑人样本鞋印,但测试集中鞋印种类与训练集中鞋印类别未有重复,共200类现场鞋印和与之对应的样本鞋印。测试集中还有混淆样本 4 800 幅犯罪现场鞋印。
3.1.3 FID-300数据集
FID-300数据集是公开鞋印数据集,其中包含现场鞋印297张,共130类,样本库共1 175张鞋印图片,本文对所有图片进行二值化预处理。
3.1.4 Part-FID测试集
此测试集源于公开鞋印数据集FID-300,从中选取所有的残缺鞋印并删除质量过低,无法有效处理的鞋印图片,共85类139张组成残缺鞋印集,样本库共1 130张鞋印图片。本文用此数据集来测试算法对残缺鞋印图片的检索效果。
3.2 评价指标
鞋印图像检索的目的是希望在大量的鞋印图像中筛选出与嫌疑鞋印更为相似的样本鞋印,在返回的样本鞋印图像中正确的图像结果排在前几名,减少后续的人工筛选,因此本文更加注重查准率,希望正确结果出现在前几名的准确率能够有所提高。我们使用累计匹配曲线(Cumulated Matching Characteristic,CMC)作为本文算法的评价标准。该曲线横坐标为返回的排序值,纵坐标为正确出现在第k位的概率。Rank1(即top1)的值越高即鞋印图像检索效果越好,在本文的实验中,我们分别采用top1、top10、top1%作为主要评价指标。
3.3 实验结果分析
文献[5]已证明经过微调的神经网络模型具有优于预训练的检索能力,本文将ResNet34网络在重新裁剪后的鞋印训练集中进行微调。经过多轮训练测试,通过分类精度的比较,本文最终确定了超参数的设置及损失函数。在训练过程中,损失函数设置为交叉熵损失函数(Cross Entropy Loss Function),训练过程中使用Adam随机梯度优化器,动量设置为0.9,学习率设置为0.001;采用批处理的方式,每次输入64张原始图片进行处理,得到分类精度最好的训练模型,将其用于图像检索实验。
3.3.1 不同卷积层特征检索实验对比结果分析
本文提取ResNet34网络中layer4和layer2的卷积特征直接展开拼接融合作为特征描述符进行检索。表1为不同特征层在CSS-200上的实验结果,由表1可知,本文融合layer2和layer4而得的特征描述符在CSS-200数据集中进行检索时top1准确率提高到了56%,虽然没有达到最高的检索精度,但由图7可知,该方法在前5名的检索结果也比其他融合方式准确率更高;而由表2、图8可知,在part-FID数据集的实验中,本文算法在top1的准确率也达到了17.27%,为所有特征融合方式中最高检索精度。
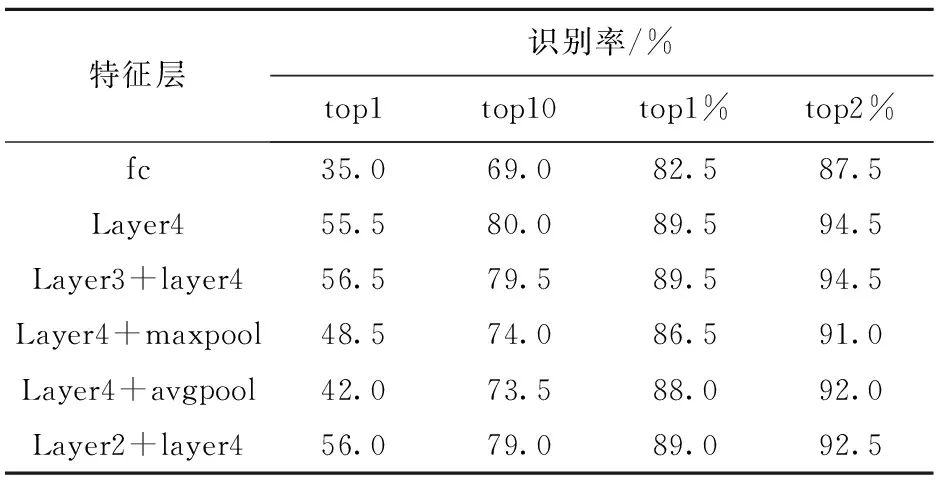
表1 不同特征层在CSS-200上的实验结果

图7 不同特征层融合在CSS-200上的实验结果
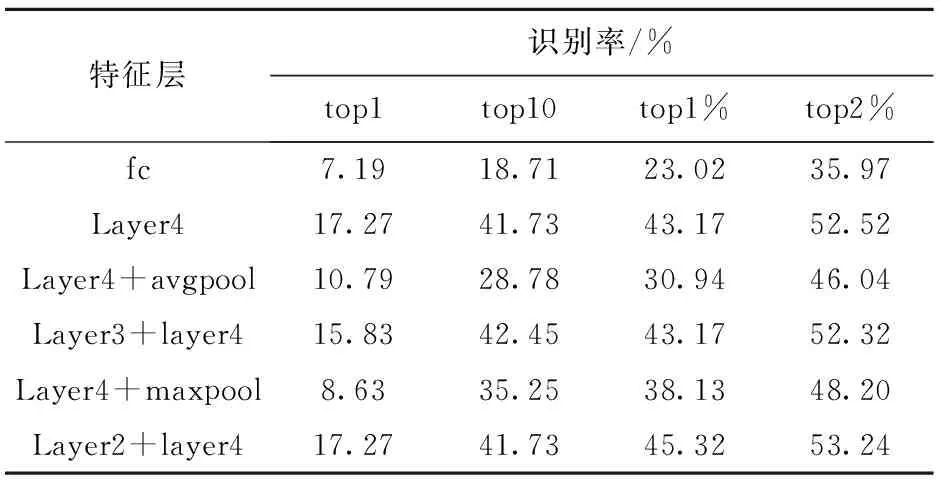
表2 不同特征层融合在part-FID上的实验结果

图8 不同特征层融合在part-FID上的实验结果
3.3.2 不同注意力机制的鞋印检索实验结果对比
为了探究注意力机制在鞋印检索中作用,本文主要从两个维度进行结果比较:①对比添加注意力机制模块的ResNet34网络模型和没有加入注意力机制在鞋印图像中的检索效果;②对比加入不同注意力机制模块在ResNet34网络模型中实验效果。
图9是同一幅鞋印图像在嵌入注意力机制的卷积网络结构和未加注意力机制的卷积网络中输出layer4层的卷积特征可视化图,由图9可知,经过注意力模块的作用,卷积特征更加注重在鞋印的重点图案区域。本文所提出的注意力机制模型能够准确学习到鞋印图案的重要特征并且排除了背景的干扰。

图9 不同网络的卷积特征可视化结果
如图10所示,嵌入混合域双重注意力机制网络在鞋印检索中前5名的准确率高于单注意力机制的网络模型,由表3可知,top1的识别率从未加注意力机制时的53.5%上升至56%,提高了2.5%。

表3 不同注意力机制在CSS-200数据集上的实验结果
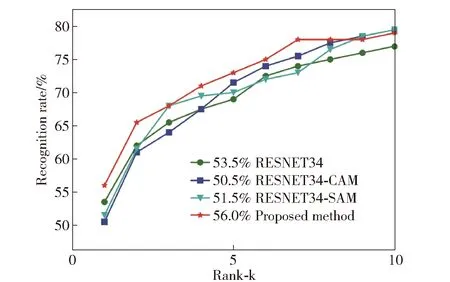
图10 不同注意力机制在CSS-200中的实验结果
在part-FID数据集上的实验结果(见表4)表明:top1的准确率从13.67%上升到17.27%,top1%的准确率也从44.6%上升到45.32%,且由图11可知加入双重混合域的注意力机制在前5名的检索结果都优于其他方法。因为part-FID数据集全部由残缺鞋印组成,所以由该数据集的实验结果证明本文算法有效地提升了残缺鞋印的检索精度。

图11 不同注意力机制在part-FID上的实验结果
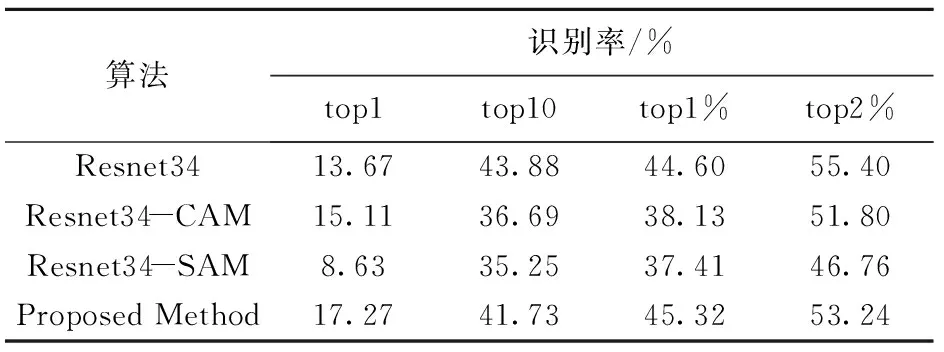
表4 在part-FID数据集上的检索方法的比较
3.3.3 实验结果比较分析
在表5中,本文算法与当前识别准确率较高的鞋印检索算法进行了比较,发现本文算法与其他算法相比鞋印识别准确率有所提高,但与最高检索精度之间仍有所差距。
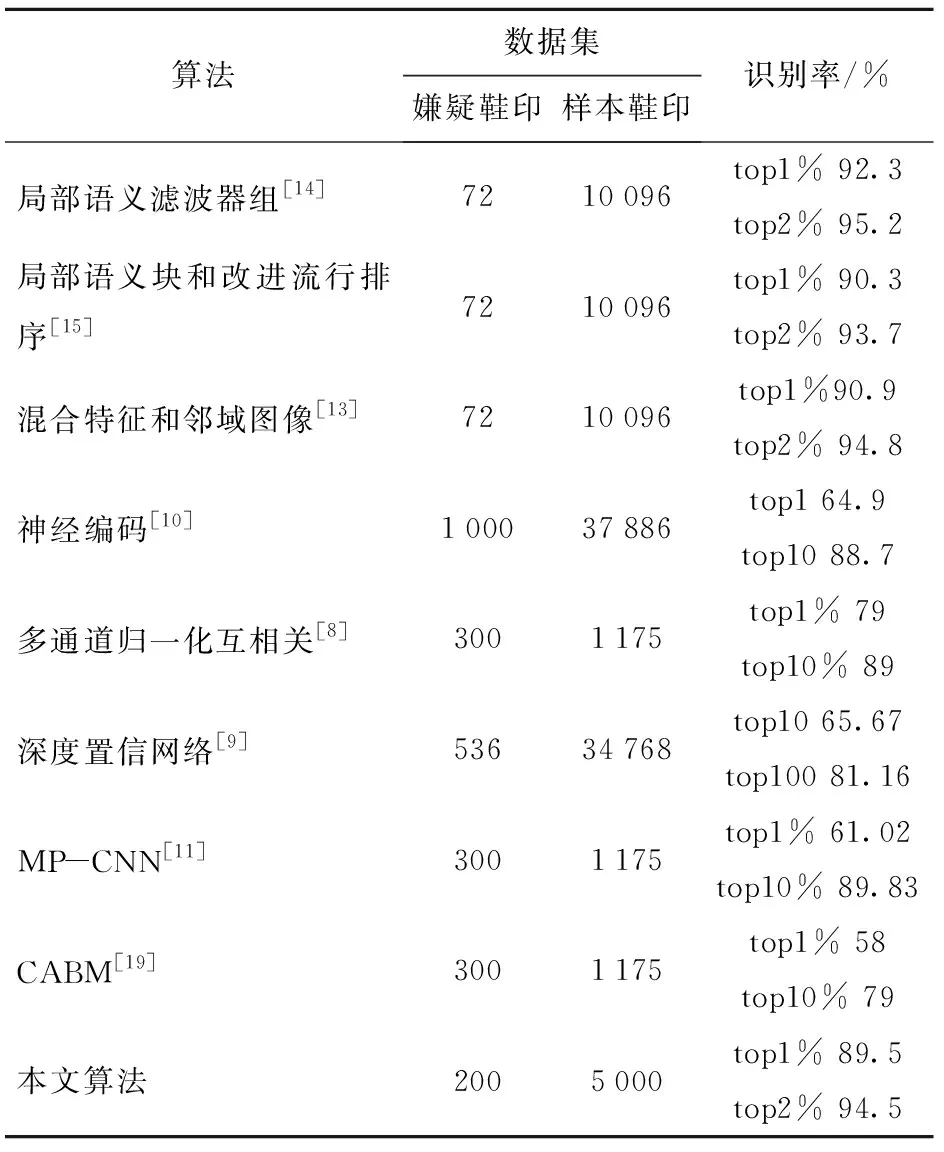
表5 本文算法和鞋印检索领域的其他方法比较
表6是不同算法在同一数据集CSS-200的实验结果,经过对比发现,本文算法较微调的VGG-16算法在top1的识别率提高了4%,虽然不如基于局部选择卷积描述子的检索实验结果,但在前top2%两个方法的识别率基本一致,都达到了最高的检索精度。经过分析,本文算法为有监督的学习检索,训练集中的鞋印种类较少,会降低鞋印检索的精度;其次卷积网络仍然更多地关注在鞋印的整体特征,对鞋印的局部特征的关注仍有不足。
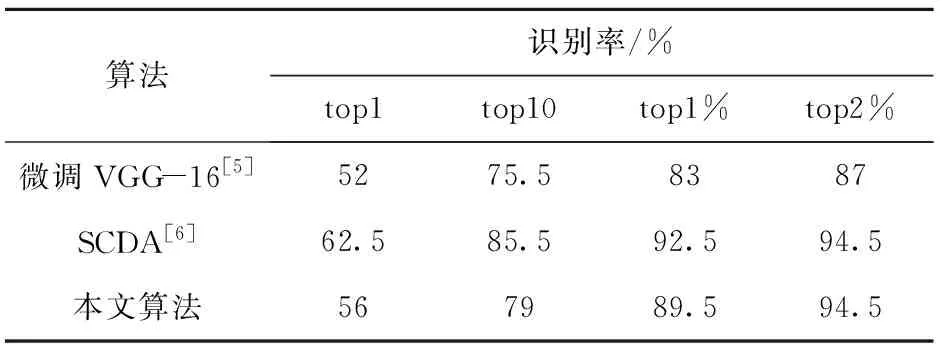
表6 在CSS-200数据集上的实验结果
表7是本文算法在公开数据集FID-300中实验结果与其他方法的比较。在FID-300数据集上,本文算法在top1%的识别率为50.17%,与其他方法相比仍有差距。除了上述原因,本文在对FID-300数据集进行预处理的过程较为粗糙,嫌疑鞋印图片中存在大量的背景干扰,花纹模糊等情况,这些都使得检索结果不如人意,因此在后续的工作中,需要进一步对FID-300数据集进行处理,提高鞋印的数据质量,另一方面需要提高算法对残缺鞋印特征提取的稳定性,以获得更高的检索精度。
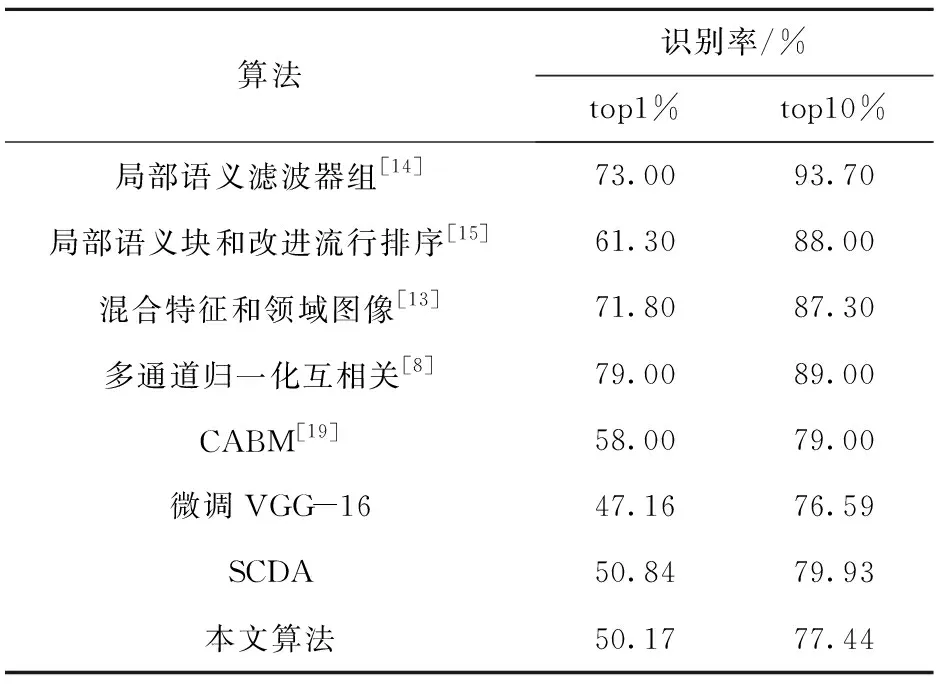
表7 FID-300数据集鞋印检索结果和相关方法比较
表8是不同算法在part-FID数据集上的实验结果。在全部由残缺鞋印组成的part-FID数据集上本文算法top1%的识别率达到了45.32%,较其他算法的检索结果提高了2.87%。在part-FID数据集中删去了背景严重干扰和无法有效处理的鞋印图片,这使得数据集的图片质量高于FID-300数据集中的鞋印图像。因此本文算法对质量较高的残缺鞋印的识别较为有效,但在part-FID数据集上检索精度的提高也证明嵌入混合域注意力机制的卷积神经网络能够更好地在图片中关注到有用的鞋印特征信息,并进行识别。
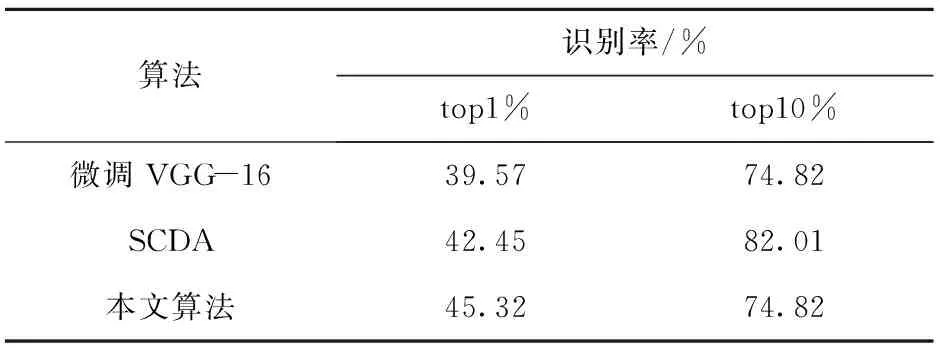
表8 不同算法在part-FID数据集上的识别率
4 结束语
针对残缺鞋印图像数据,本文提出了一种将混合域注意力机制融入ResNet34网络的模型算法,并在鞋印数据集上微调,进一步增强了ResNet网络对重点区域特征的提取能力。同时本文探究了不同卷积层特征融合对鞋印图像检索精度的影响,得出以下结论:通过提取layer2和layer4的卷积特征展开后级联作为特征描述符得到的实验结果最好。为了提高网络模型的鲁棒性,重新对训练集中的数据进行了低质量处理和随机裁剪,改变了残缺鞋印的缺失方式,使得图片中留下的鞋印信息更少,对重新处理的数据集进行学习训练,再进行鞋印图像的检索实验。实验结果表明,本文提出的鞋印检索算法具有较强的应用性。
本文的改进方法也有一定的局限性,本文提取双层卷积特征展开融合作为特征描述符进行检索,该方法虽然有效提高了鞋印检索的精度,但是由于卷积输出特征维数过高,存在占用内存过大,检索时间较长的问题。因此在后续的工作中,将进一步优化算法,降低特征描述符的维度,提高识别精度。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
技术与创新管理(2020年5期)2020-10-09
商情(2020年24期)2020-06-30
科学与财富(2019年27期)2019-10-25
好孩子画报(2017年10期)2017-11-07
科学与财富(2017年28期)2017-10-14
小学生·多元智能大王(2015年10期)2015-09-02
