
非侵入式负荷识别的电流序列可视化方法
2022-07-20 01:44崔昊杨吴轶凡江友华许永鹏
电力自动化设备 2022年7期
崔昊杨,吴轶凡,江友华,江 超,韩 韬,许永鹏
(1. 上海电力大学电子与信息工程学院,上海 200090;2. 国网电力科学研究院有限公司,江苏南京 211106;3. 上海交通大学电子信息与电气工程学院,上海 200240)
0 引言
居民智慧用电与高效用能是促进“3060”双碳目标实现的重要举措。以非侵入式负荷监测NILM(Non-Intrusive Load Monitoring)技术为核心的终端设备能源消耗监测手段,可为用户及时、精准反馈各时段家用电器的运行状态及能耗信息,使用户了解自身行为习惯,合理规划电器的使用策略。自20 世纪90年代美国George Hart 教授提出NILM 概念[1]以来,负荷特征如何选取一直是NILM 研究中的一项热点问题[2]。早期研究人员通过手动选取特征的方式为负荷赋予标签,但居民侧用电负荷数量和类别的骤增导致该方式的效率愈发低下,且通常手动选取的单个特征携带的信息量不足,作为负荷标签代表性不强,这导致对性质相似的负荷易产生误判,造成负荷识别的准确度不高,难以满足实际应用需求。因此,如何选取辨识度高的负荷特征并建立性能优异的分类模型是目前该领域亟需解决的问题[3]。
负荷识别包含特征提取和分类识别2 个环节。以机器学习算法为基础的负荷识别方法,主要通过筛选、组合特征的方式提升负荷识别准确率,但其包含的信息量有限,大多仅能在统计学方面体现负荷特性。近年来,深度学习快速发展,有效解决了人工选取特征效率低的问题,它依靠独特的网络结构和训练方法,能够自动地从大规模样本数据中寻找本质特征,网络性能优异[4-5]。由于深度学习在图像分类、目标检测等领域的优异表现,研究人员根据时间序列二维可视化的思想[6-7],将序列识别问题转换为适合用深度学习处理的图像分类任务[8-10]。在NILM领域,V-I轨迹是最早将电信号转换成可视化图像的方法之一[11-12]。文献[13-15]表明利用V-I 轨迹将负荷识别问题转移至图像分类领域是有效的,但由于图像细粒度不足且未加入颜色信息,识别精度不够理想。文献[16-17]以改进的递归图作为可视化途径,得到了更好的分类效果,但其性能受限于递归图相关超参数的选择,较为繁琐。尽管时间序列二维可视化的思想大幅改善了负荷识别效果,但单特征携带信息量不足且模型优化问题尚未完全得到改善,在识别准确度上依然有进步的空间。
考虑到NILM研究中采集的原始电压、电流信号是与时间相关的非线性序列,本文提出一种基于时间序列二维可视化和迁移学习的非侵入式负荷分类识别方法。利用Fryze 功率理论将采集到的稳态电流信号分解为有功和非有功分量[18],扩大电流信号的差异程度。引入格拉姆角场GAF(Gramian Angular Field)将一维非有功电流序列转换成二维矩阵并将其可视化为图像,并加入颜色信息,在充分保留原始数据时间相关性的基础上提升信息量。基于迁移学习的思想,利用预训练模型Inception_v3提取并学习GAF 图像特征,并且对负荷进行分类识别。基于公开数据集PLAID(Plug-Load Appliance Identification Dataset)和WHITED(Worldwide Household and Industry Transient Energy Dataset)对所提方法进行验证,识别准确率分别达到98.88%和98.94%,所提方法为居民侧电力能耗分析提供了基础。
1 负荷标签可视化方法
根据投切事件分离出单台设备的电压、电流,并基于电流信号标定负荷标签。为进一步扩大电流信号间的差异程度,提取一个周期的稳态电流并利用Fryze 功率理论将其分解为有功和非有功分量。将电流的非有功分量序列进行标准化、极坐标编码并代入GAF 矩阵,通过隐含电流大小信息的三角函数扩充数据量,以达到升维的目的。然后,赋予矩阵颜色信息使其可视化,提高负荷标签的辨识度。
1.1 数据提取与预处理
居民侧总线中的电压、电流数据可通过智能电表等能源监控设备进行采集。总线数据的波动往往表示有负荷进行了投切,假设同一时刻只有1 个负荷完成状态切换才可将其进行分离。投切事件检测和负荷分解已有大量成熟算法,本文不再赘述。
由于电力系统长期处于稳定运行状态,各类家用电器的电压信号总是近似于正弦波形,而电流信号则会由于负荷性质、投切事件等影响存在较大差异,因此许多负荷标签都是基于电流信号进行标定的。将总线中投切事件前、后若干整周期的电压和电流数据分别用von、voff和ion、ioff表示,则单台设备的电压和电流分别为v=(voff+von)/2、i=ioff-ion[19]。为了确保电流波形ioff和ion可以在时域中直接相减,应使它们的初始相角相同。为此,可以利用快速傅里叶变换等频谱分析方法计算出基波电压的相角,将相角为0°时的采样点作为初始采样点。
获取电流数据后,对其进行差异化处理。根据Fryze 功率理论,负荷电流可分解为有功和非有功分量[18]:
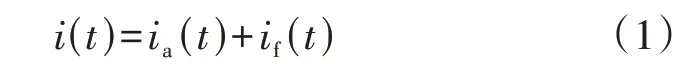
式中:i(t)为t时刻负荷电流瞬时值;ia(t)为t时刻负荷电流有功分量,定义为原始电流在电源电压方向上的投影,因此ia(t)与电压成正比,能够反映负荷的电阻信息,如式(2)所示;if(t)为t时刻负荷电流非有功分量,其与电源电压正交,反映负荷的非电阻信息。
式中:Pa为有功功率;v(t)为t时刻负荷电压瞬时值;vrms为电压的有效值;Ts为一个基波周期总时刻数。
通过式(2)—(4)推导得到if(t)为:
图1 展示了利用Fryze 功率理论分解电流的效果。考虑到功率因数,有功分量的占比通常更大。此外,由于有功分量与电源电压成正比,其波形也接近正弦波,因此,将非有功分量可视化后作为负荷标签比使用原始电流更具辨识度。
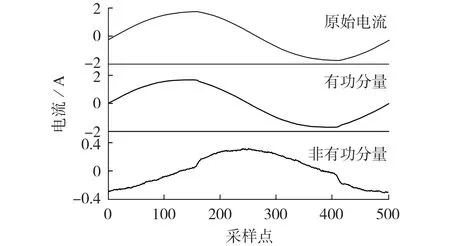
图1 Fryze功率理论分解电流效果Fig.1 Effect of current decomposition by Fryze power theory
1.2 序列可视化流程
由于电流本质上可视作与时间相关的一维序列,根据时间序列二维可视化的思想,本文将GAF法[6]引入NILM 领域,为非有功分量构建可视化图像。假设X={x1,x2,…,xn}为包含n个电流非有功分量采样值的序列,将其转换为GAF图的步骤如下。
1)将X中元素标准化处理到[-1,1]区间,即:
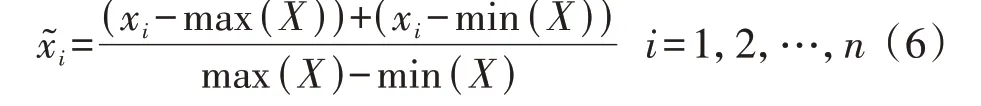
2)对标准化处理后的序列进行极坐标编码,即:
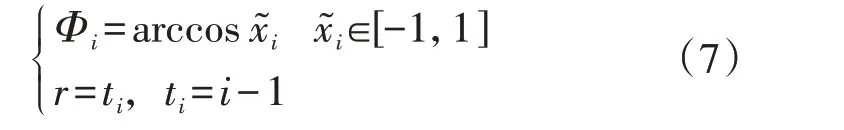
3)完成对标准化序列的极坐标变换后,本文采用GAF 将一维序列转换成n阶矩阵,将矩阵中元素的值映射到蓝-红颜色区间,使矩阵成为具有颜色和纹理分布的二维图像。GAF有2种定义方式,分别为格拉姆和角场GASF(Gramian Angular Summation Field)和格拉姆差角场GADF(Gramian Angular Difference Field),对应的矩阵AGASF和AGADF分别为:
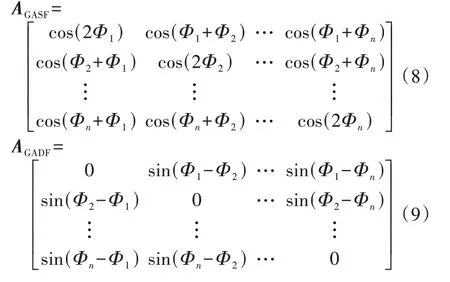
附录A 图A1 给出了二维可视化的流程。GAF是基于格拉姆矩阵演变而来的,采用极坐标系代替笛卡尔直角坐标系表示时间序列,通过三角函数细化序列中每2 个采样点间隐含的电流差值信息来扩充数据量,从而提升序列的维度。与一维序列相比,二维图像显著提高了负荷标签的辨识度。
对电流非有功分量进行极坐标编码具有如下优势:极坐标变换满足双射条件,每个采样点在极坐标系中有且仅有唯一的映射结果,保证了编码过程的唯一性;极坐标变换后,从矩阵元素左上角到右下角位置时间不断增加;与直角坐标系相比,极坐标同时保留了采样点间的电流大小关系和时间信息。
2 负荷识别模型
NILM 的实际应用场景没有充足的计算资源和时间资源来从头开始训练用于负荷识别的复杂模型,即使建立一个庞大的数据库来训练分类模型的泛化能力,随着家用电器数量和种类的增加,维护这样的数据库也将十分困难,而迁移学习可将现有成熟模型应用到新的场景,无需如同自定义网络训练大量参数,因此可大幅提升网络的学习效率和性能。
成功应用迁移学习的前提是源域和目标域间存在相关性,可通过1个或多个中间域来连接2个不相关或弱相关的领域,称为传递性迁移学习[20]。GAF作为一种可将序列可视化的途径,有可能成为计算机视觉和NILM间的中间域。虽然还没有专门为NILM建立的分类模型,但在图像识别领域已有众多性能优异的网络架构,如AlexNet、GoogLeNet、VGGNet 系列、ResNet 系列、Inception 系列、DenseNet 系列等,这些模型是基于包含大量图像的大型数据集ImageNet训练得到的。综合考虑准确率、占用内存、参数量、计算成本和功耗等因素,本文采用Inception-v3网络。
根据传递性迁移学习原理,本文制定基于预训练网络的NILM 模型迁移方案:将预训练网络Inception-v3 的卷积基进行冻结,保证其不受分类器训练的影响,然后改进分类器以匹配应用场景。当新的分类器训练完成后再与卷积基进行级联,从而应用到NILM 领域。该方案可以推广到任意其他数据集,只需将负荷标签进行可视化表示,且最后全连接层的输出与负荷类别数量保持一致。Inception-v3模型采用随机梯度下降法进行训练,并设置了学习率自适应调整机制。若损失函数出现下降平台期,则将学习率调整为原来的1/10以优化模型。在训练过程中,为适应计算机显存资源,将模型的初始学习率配置为5×10-4,每次训练的样本数设置为32,模型的训练轮数设置为75。
3 实验结果与分析
3.1 实验条件
为验证所提方法的有效性,本文在PLAID[21]和WHITED[22]公共数据集上进行实验。由于PLAID 和WHITED 的采样频率分别达到30、44.1 kHz,相比低频采样有更丰富的原始数据,因此这2 个数据集被较多地用于评估负荷分类识别方法的有效性和实用性。PLAID包含美国匹兹堡市55个家庭11种电器的电流和电压数据1074组。WHITED包含全球3个地区55种设备的电流和电压数据1339组。2个数据集的区别在于PLAID 有较高的类内差异,而WHITED有较高的类间差异[19],因此,2 个数据集在统计规律上并非独立同分布,可以验证迁移学习模型的普适性。此外,采集前期负荷大多处于启动的暂态过程,电流波形不稳定。为了减少不确定性,保证所选负荷标签具有较强的代表性和较高的辨识度,实验所用数据均为2 个数据集每条记录中设备启动几秒后的稳态周期数据。
3.2 PLAID的实验结果
根据第1 节的数据预处理和序列可视化流程,对PLAID中的电压、电流进行处理,提取设备启动几秒后1 个稳态周期(500 个采样点)的电流非有功分量序列构建GAF 图。附录A 图A2 为PLAID 中11 种电器的GADF 图(n=500)。由图可知:11 种电器的GADF 图存在显著差异,可辨识性很强;尽管部分电器的GADF 图整体视觉效果较相似,如洗衣机和电风扇、笔记本电脑和节能灯,但仍可通过局部细节辨别;矩阵AGADF的性质是主对角线上的元素均为0,且其他元素以主对角线为对称轴呈反对称,因此,映射到蓝-红颜色区间的GADF 图对角线均为绿色,且主对角线两侧形状对称但颜色相反。
Inception-v3 模型在2 个数据集上的训练过程如图2 所示,最终PLAID 和WHITED 的验证集识别准确率分别达到99.31%和98.74%,验证了时间序列二维可视化方法可以有效提高负荷特征的辨识度。
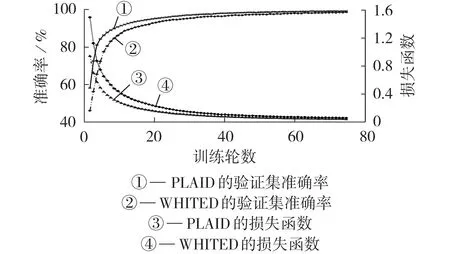
图2 预训练模型在2个数据集上的训练结果Fig.2 Training results of pretrained model on two datasets
图3 是根据PLAID 的测试集实验结果绘制的混淆矩阵示意图。矩阵示意图对角线上的值表示预测类别与真实类别相同,即识别正确的个数,非对角线上的值则表示识别错误的个数。

图3 PLAID测试集实验结果的混淆矩阵Fig.3 Confusion matrix of experimental results of PLAID’s test set
文献[23]给出了用于评价NILM 模型分类性能的指标,其中正确率与召回率的调和平均值Fscore使用最广泛,它是统计学中一种用来衡量二分类模型精确度的综合性评价指标,定义如下:
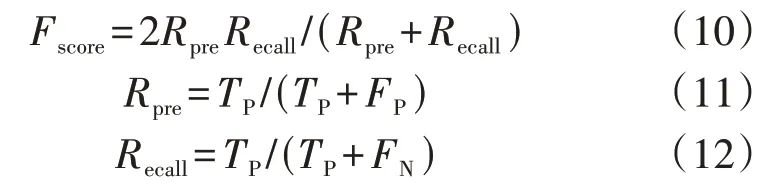
式中:Rpre为正确率;Recall为召回率;TP为真阳性(即电器实际打开且识别正确);FP为假阳性(即电器实际关闭且识别错误);FN为假阴性(即电器实际打开且识别错误)。以冰箱为例,如图3 混淆矩阵所示,TP=33,FP=5,FN=1,因此冰箱的正确率约为86.84%,召回率约为97.06%,Fscore≈91.67%。最终PLAID 在测试集上的整体识别准确率约为98.88%。
由图3 可见,冰箱和空调的预测结果更容易与其他电器发生混淆,且由表1 所示PLAID 中11 种电器的Fscore可知,所有电器Fscore的均值Fmacro≈98.20,冰箱和空调的Fscore均低于Fmacro,其原因在于冰箱和空调有多种运行状态,且不同状态下负荷特征差别较大,易与其他电器混淆。例如,空调在制热模式下可能与加热型电器吹风机混淆。因此,需要研究多态模型来表示这类电器或采用其他方法对其进行区分,目前该问题尚未得到有效解决。
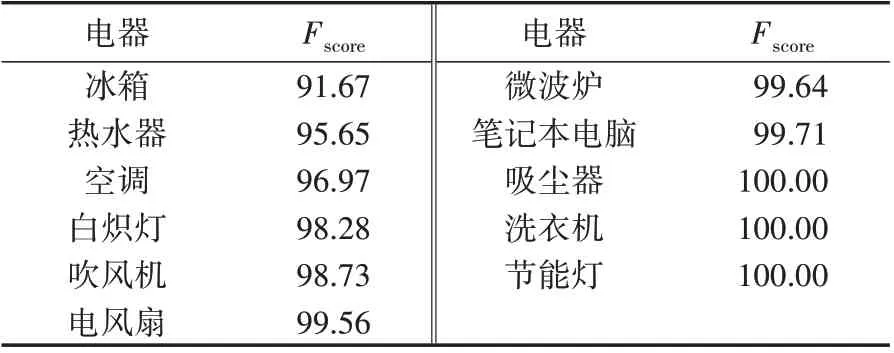
表1 PLAID中11种电器的FscoreTable 1 Fscore of 11 electrical appliances in PLAID
3.3 WHITED的实验结果
WHITED 的模型参数设定及数据可视化过程类似于PLAID。由于部分电器样本数过少,在验证时几乎不产生误判,因此仅在模型训练时对其进行保留,在结果展示中忽略这些电器。最终WHITED 在测试集上的整体识别准确率约为98.94%,混淆矩阵与Fscore值分别见附录A 图A3 和表A1。由结果可见,咖啡机、熨斗、烧水壶、烤箱、电灯泡、电烙铁和热水器之间更易产生误判,这是由于这些电器都是典型的电阻型负荷,功能都属于加热范畴,因此这些电器间的预测结果易出现混淆。与PLAID 不同,WHITED 中空调和冰箱的分类准确率都很高,原因在于这2类电器的样本数很少(均为10),在WHITED中仅涵盖1种工作状态。
同种类型不同品牌的家用电器因设备参数不同,GADF图会存在差异,附录A图A4为WHITED中4 种不同品牌吹风机的GADF 图。为了验证所提方法能够区分同种类型不同品牌的设备,选取WHITED中品牌数量最多的6 种电器,分别为充电器、风扇、吹风机、烧水壶、LED 灯和电灯泡,共有40 个品牌,实验结果显示仅发生1 例误判,识别准确率达到99.74%,证明了所提方法具有区分同种类型不同品牌设备的能力。但巨大的类内差异也对负荷标签的泛化性能提出了更高的要求,为此,重复使用基于PLAID 训练的Inception-v3 模型对WHITED 中相同类别的11 种电器进行识别。实验结果显示分类准确率仅达到36.83%。因此,如何提升负荷标签的泛化能力,从而实现跨数据集、跨区域的非侵入式负荷识别需要进一步研究。
3.4 分析与讨论
在实验中,每张GADF图是基于1个电流周期得到的,不同周期数的GADF 图如附录A 图A5 所示,由图可见,2 个周期的GADF 图仅是1 个周期GADF图的复制,与1 个周期GADF 图并无本质区别。当PLAID每条电流记录所取的样本数分别为1、2、5、10时,模型的验证集准确率与最终在测试集上的准确率分别如图4 和图5 所示。由图4 可见,样本数越多,验证集准确率曲线越平滑,模型的性能越好。由图5 可见:测试集准确率随样本数的增加不断提高,即使样本数仅为1或2,也能达到相对理想的识别效果;当每条记录的样本数大于5 时,模型的识别准确率能维持在98%以上,此时识别准确率提升幅度较小,曲线逐渐趋于饱和。因此,所提方法能较好地适用于小样本的场景。
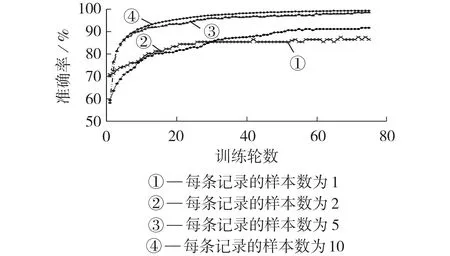
图4 不同样本数对模型性能的影响Fig.4 Influence of different sample numbers on model performance
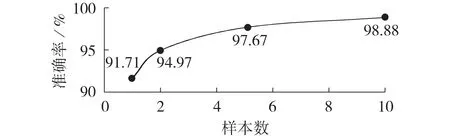
图5 不同样本数的准确率对比Fig.5 Comparison of accuracy among different sample numbers
表2 为本文方法以及与本文使用相似模型和相同数据集的其他文献方法的对比结果。文献[2]采用二值V-I 轨迹作为负荷特征,利用随机森林(RF)算法对负荷进行分类;文献[13]采用灰度V-I 轨迹作为负荷特征,并使用自定义的卷积神经网络(CNN)进行负荷识别。这2种方法虽然将电压、电流数据进行可视化,但图像色调单一,未考虑颜色维度,且文献[13]的网络结构比较简单,最终导致识别准确率不高。文献[16-17]采用改进的递归图作为可视化途径,添加了颜色信息使得图像在视觉上更具辨识度,因此分类准确率得到了提升,但其模型性能受限于递归图相关超参数的选择,较为繁琐。与文献[16-17]的方法相比,本文负荷标签的构建过程简单,摒弃特性相似的电压数据,保留电流数据,同时根据Fryze功率理论分解出电流的非有功分量,扩大了负荷特征相互间的差异,通过序列可视化的方式进行升维,扩充了信息量,在采集场景复杂的高频数据集PLAID、WHITED上获得了更高的识别准确率。
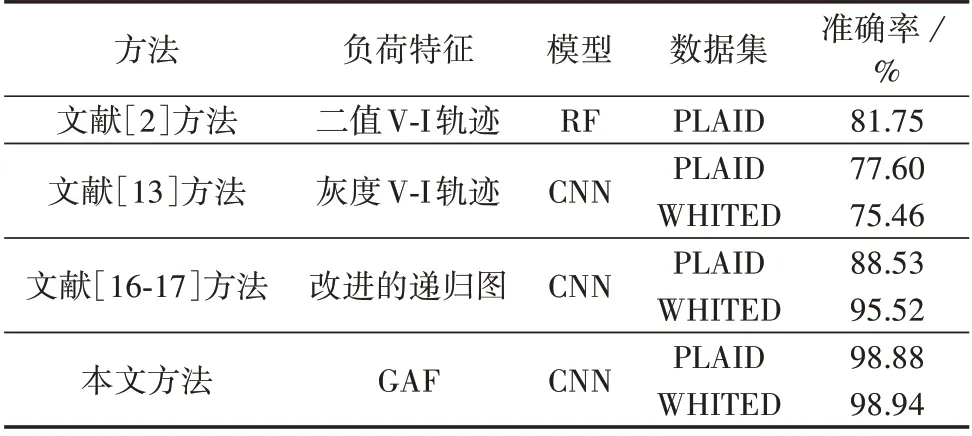
表2 本文方法与现有方法的对比Table 2 Comparison between proposed method and current methods
4 结论
本文提出了一种基于时间序列二维可视化和迁移学习的非侵入式负荷分类识别方法。通过数据预处理和序列可视化等流程,选取二维图像——GAF作为负荷标签,不同的家用电器可以通过GAF 图的纹理和颜色分布进行辨别。同时,GAF 图作为中间域有效结合了计算机视觉与NILM 领域,将负荷识别问题转换为适合用CNN 处理的图像分类任务。在公共数据集上的实验结果验证了本文方法的准确性和有效性。但所提方法目前仅适用于高频采样数据,对采集装置的硬件要求较高。负荷间的类内差异导致现有负荷标签的泛化能力不足,跨数据集、跨区域的非侵入式负荷识别仍然难以取得理想效果。此外,为多状态负荷设计具有代表性的多态模型依然较为困难。因此,如何在保证负荷识别准确率的同时降低应用成本,如何选取适合的负荷标签以最小化同类负荷的差异并最大化不同类负荷的区别,将是未来非侵入式负荷识别研究的核心。
附录见本刊网络版(http://www.epae.cn)。
猜你喜欢
世界科学技术-中医药现代化(2022年3期)2022-08-22
文萃报·周五版(2022年14期)2022-04-12
师道·教研(2022年1期)2022-03-12
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
海洋信息技术与应用(2020年1期)2020-06-11
中国品牌(2019年10期)2019-10-15
传媒评论(2019年4期)2019-07-13
