
基于深度学习的合同分类及要素抽取模型
2022-07-29 06:54张晓芳饶攀军周郴莲王浩畅赵铁军
智能计算机与应用 2022年8期
张晓芳,欧 睿,饶攀军,郑 元,张 雷,陈 科,周郴莲,王浩畅,赵铁军
(1 太极计算机股份有限公司,北京 100083;2 东北石油大学 计算机与信息技术学院,黑龙江 大庆 163318;3 哈尔滨工业大学 计算机科学与技术学院,哈尔滨 150001)
0 引言
合同是民事主体之间设立、变更、终止民事法律关系的协议,依法成立的合同,受法律保护。近年来,经济活动持续增长,各企业需要审查的合同数量逐年上升,合同审查陷入“数多人少”的困境。科学有效地提高合同的审查速度及准确率已然成为一个亟待解决的问题。
随着自然语言处理技术的发展,越来越多的研究者开始关注特定领域的任务。其中,文本分类(Text Classification,TC)任务对数据的管理至关重要,是信息检索和文本挖掘的基础,利用自然语言处理、数据挖掘和深度学习等技术,对各类文本内容进行自动分类。信息抽取(Information Extraction,IE)是从海量的文本、图片和视频等数据中自动抽取用户感兴趣的结构化信息的过程。
本文研究合同文本的分类和要素抽取,需要解决3 个问题:
(1)针对合同类型和要素的划分不合理的问题,研究描述合同体系以及知识点之间的关联关系的方法。
(2)根据合同文本的特点训练适合的分类和要素抽取的方法。
(3)确保合同要素抽取的准确率,解决合同文本训练数据少的问题。
针对上述合同文本中存在的问题,结合自然语言处理技术,本文提出了基于深度学习的合同分类及要素抽取模型,通过人工标注构建合同文本语料库。为了能够及时、有效地对合同文本进行分类,提出了改进的Bert-BiLSTM+Attention 深度学习模型;针对合同文本存在的信息难以抽取问题,提出了基于BiLSTM-CRF 深度学习模型获取准确的合同要素信息。实验表明,这2 个模型在合同分类与合同要素抽取中取得了较好的效果。
1 合同文本语料库构建
1.1 数据来源
本文原始语料的收集是以《民法典》为基准、常用合同类型为中心,合同数据来源于企业已过滤掉隐私信息的真实合同,主要包括买卖、建设工程、技术服务、租赁、承揽、运输、委托、借款这8 类合同。在人工采集合同文档时,会先去除合同文本中空白数据与不符合要求的合同数据,确保原始语料的质量。标注前,对合同文本原始数据进行预处理,主要是转换原始合同数据的格式,将其保存为json 格式的.txt 文档。
1.2 标注过程
本文合同文本标注,遵循3 个原则:
(1)根据不同类型合同要素的特点,进行合同数据预标注,同时汇总整理合同要素标注过程中遇到的问题,如标注要素在文本中出现多次、标注要素不准确、标注错误等,给出相应的解决方案,再进行正式标注。
(2)对于有争议的问题,参考《民法典》细则或者与领域专家商议后解决。
(3)合同标注数据一致性需达到了90%以上。
本文采用了多轮标注的方法,可以获取大规模合同文本标注数据,研究展开的标注过程具体如下:
(1)第一轮标注。标注人员平均分组,每组的标注人员分别单独标注同一份合同,对比每组标注人员的标注结果,对合同文本语料中存在标注不一致的问题,根据专家意见及结合《民法典》进行修正。
(2)第二轮标注。根据第一轮的标注结果,完善标注方案后进行第二轮标注,每名标注人员将会独立标注数据,并对标注后的数据进行汇总。
(3)第三轮标注。根据前两轮标注结果进行方案完善,对不同类型的合同再次进行标注,纠正标注不一致性的数据。
为了确保合同文本标注数据的一致性,每一轮标注都会对标注人员重新进行分组,保证标注数据的准确性。
2 合同文本分类模型
文本分类是指按照一定的分类体系或者规则对文本实现自动划归类别的过程。
2.1 标题分类
合同文本的标题可以较直观地对合同文本进行分类,但是在处理大批量的合同数据时,借助分类模型可以加快分类速度,本文采用的是基于注意力机制(Attention Mechanisms,AM)的双向长短期记忆网络(Bi -directional Long Short -Term Memory,BiLSTM)模型对文本标题进行分类,模型如图1 所示。该模型主要由4 部分组成:
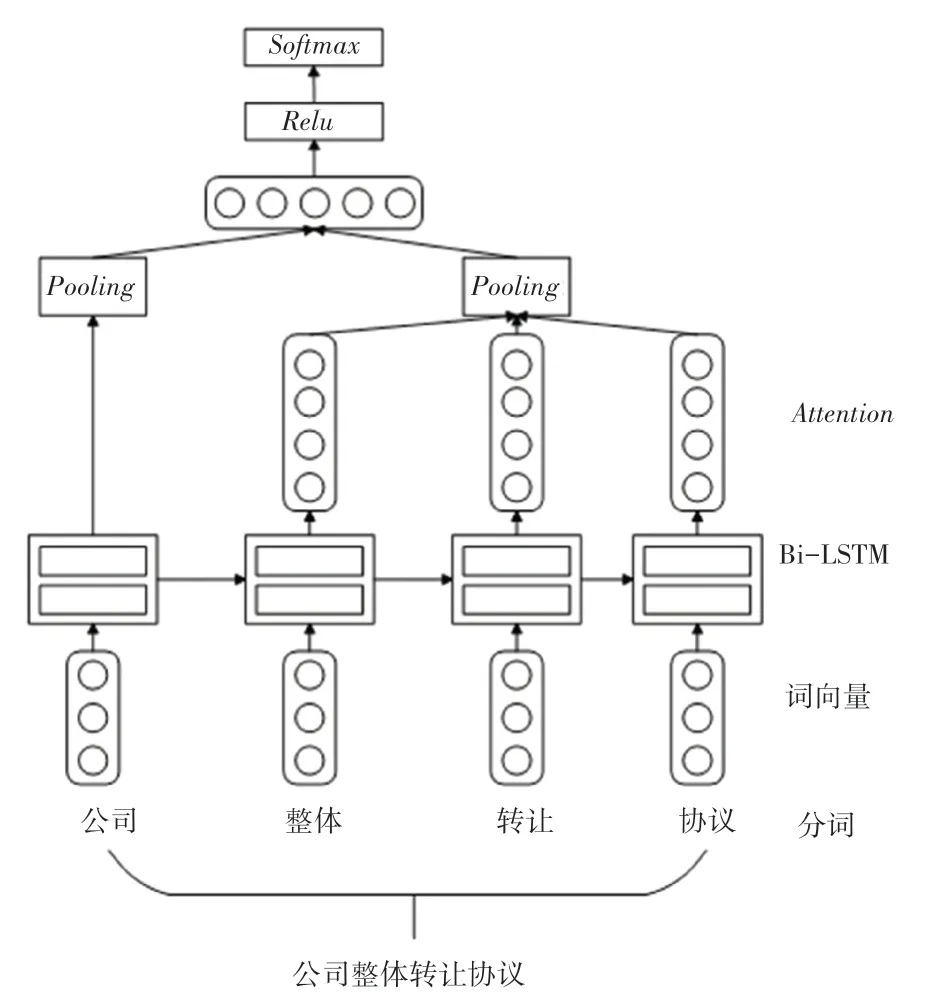
图1 基于注意力机制的BiLSTM 模型Fig.1 BiLSTM model based on attention mechanism
(1)采用词向量表示合同标题。
(2)利用BiLSTM 模型获取合同标题的特征。
(3)引入AM 表示不同合同文本标题特征的重要性。
(4)经过池化后,将利用分类器进行合同标题分类。
采用BiLSTM 模型实现合同文本标题分类,在训练阶段将预定义的8 类合同文本标题嵌入到模型中。首先,将合同文本的标题进行分词处理,输入层在词向量中嵌入其维度,BiLSTM 层提取每个合同标题的特征;拼接双向的特征,将相应单词的特征作为输出;在层对每个词语进行加权求和训练;输出层使用全连接层,作为激活函数,输出的是合同标题的分类结果。
2.2 文本分类
合同标题虽然可以较好地完成大部分的合同文本分类任务,但也存在一些通过标题分类无法确定其类型的合同文本,此时就需要利用合同文本内容来辅助其分类。本文采用层次注意力网络(Hierarchical Attention Networks,HAN),模型结构如图2 所示。由图2 可知,该模型由词序列编码器、词级Attention 层、句子序列编码器和句子级Attention层组成。
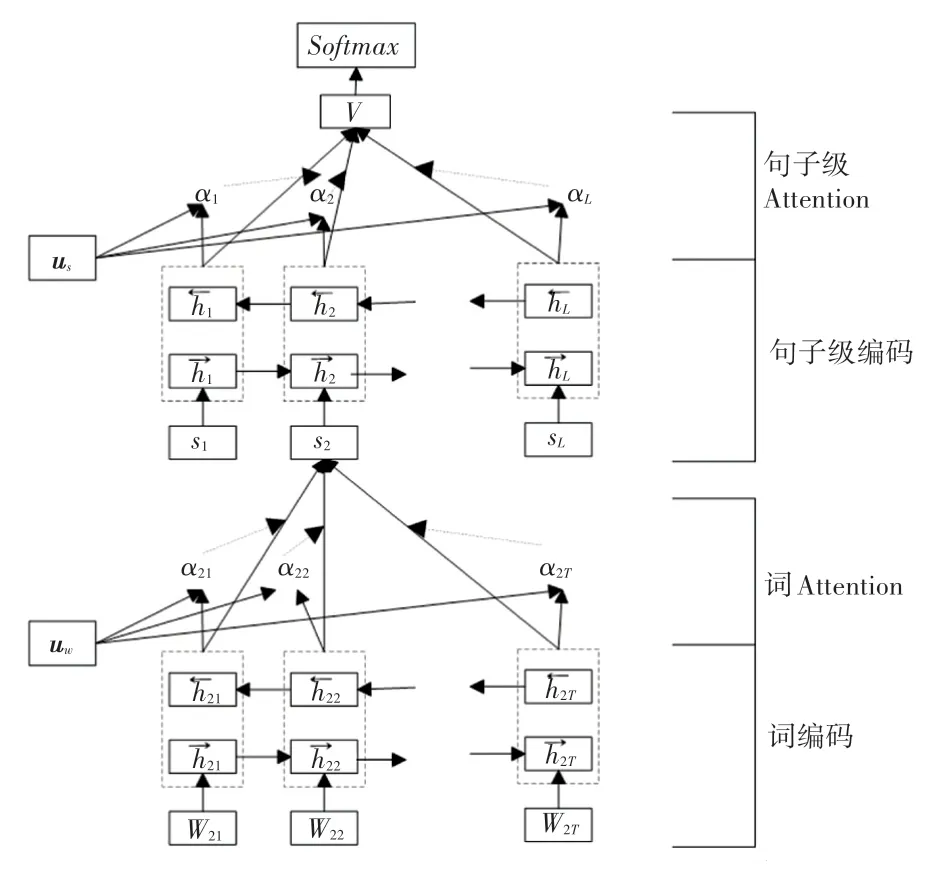
图2 HAN 模型结构图Fig.2 Structure diagram of HAN model
研究中,设一份合同由个句子组成,第s(∈[1,])个句子包含T个单词。对此拟做剖析分述如下。
(1)在词编码器部分,已知句子词序列w,∈[1,] 组成句子,句子中每个单词的词向量经过词嵌入矩阵W把词转换成词向量,这里需用到的数学公式见式(1):
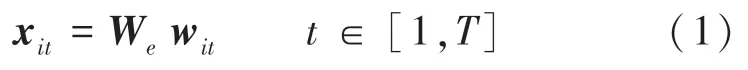
其中,w表示句子中的第个单词,为句子的总长度。
使用双向门控循环单元(Gate Recurrent Unit,GRU)对词嵌入后的句子进行编码,结合正反向的上下文信息,获取隐藏层的输出,经过式(2)、式(3)的操作后,得到编码向量h,h包括了w两个方向的信息。式(2)、式(3)具体见如下:
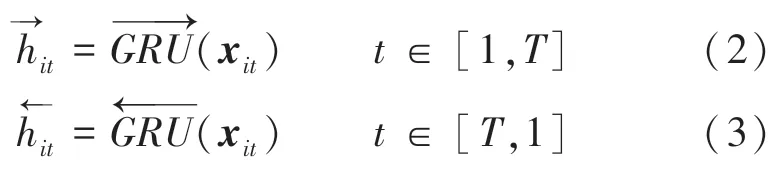
(2)词级Attention 部分。首先使用一个单层的感知机,计算编码向量h,得到句子中的第个单词的隐层向量u,即:
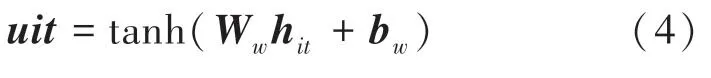
其中,W表示权值矩阵,b表示偏置向量。
计算词级上下文向量u的相似性,测量单词在隐层向量u中的重要性;通过进行标准化操作,得到归一化权重矩阵α,α表示句子中第个词的权重。该值可由如下公式计算求出:
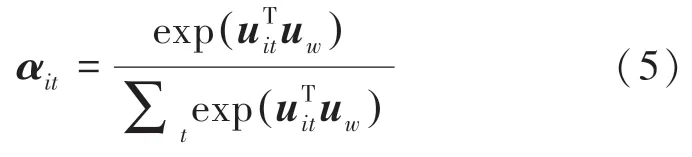
另外,标准化时,上下文向量u是随机初始化的,同时在训练过程中也不断改变。最终一个句子的表示就是权重α与编码向量h的和,也就是s,计算过程如式(6):

需要指出的是,这里的维度与编码向量一致。
(3)句子编码器部分。连同句子级Attention,与上面提到的2 层本质一样,只是将单词换成了句子,研究后推演可得:

其中,为句子的总长度,为句子的总数。
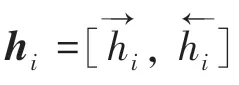
计算编码向量h,得到一个隐层向量u,求得的数学表述如下:
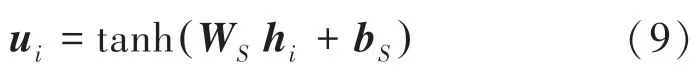
其中,W表示权值矩阵,b表示偏置向量。
(4)句子级Attention 部分。提出了一个句子级别的上下文向量,计算句级上下文向量的相似性,测量句子在隐层向量u里的重要性;通过进行标准化操作,得到归一化权重矩阵α,数学定义可表示为:
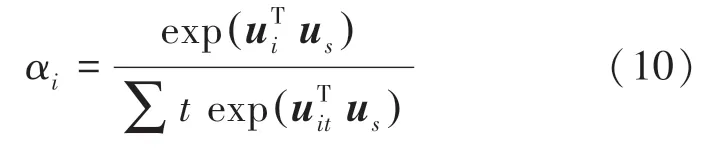
其中,u表示句级上下文向量。
在此基础上,通过式(11)计算得到合同文本的特征向量:

3 合同要素抽取模型
合同要素抽取、即抽取合同文本中用户需要的要素信息,如:合同编号、签订时间等。
3.1 数据预处理
对完成标注的合同数据进行预处理,获取合同要素抽取数据集。首先,将标注后的合同数据从标注软件中导出;其次,提取标注要素的信息与合同原文,提取的要素信息中如存在20%未出现任何要素的语句,则将其删除,同时定义合同要素词典;最后,根据合同要素词典将提取的标注要素信息与经过处理的合同原文融合,转换成适用在要素提取任务的BIO 格式的.txt 文档。其中,BIO 格式是将每个合同要素标注为“B-X”、“I-X”或者“O”,这里的“B”表示实体的开头位置,“I”表示实体的中间或结尾位置,“O”表示不属于实体的标签。
在数据清洗中,需清除数据集中所有的空数据;在不破坏文本要素完整性的前提下,每100 行处添加截断标志,避免输入语句过长。另外,不同类型的合同存在的要素信息有部分不一致,如“技术服务合同”中是出卖人和买受人,而“油工合同”则是发包方和承包方,这会影响抽取的效果。因此,本文需要对要素词典的类型进行部分删减,重复上述步骤,得到BIO 格式的.txt 文档。
3.2 模型框架
本文针对合同要素抽取难以实现以及抽取效率不高等问题,提出了基于BiLSTM-CRF 的合同抽取深度学习模型,如图3 所示。该合同要素抽取模型基于字符的序列标注模型,由输入特征层、BiLSTM 中间层、条件随机场(Conditional Random Field,CRF)输出层这3 个部分组成。首先,把合同要素拆成单个的字,其中每个字都用拼接的特征向量表示;然后,使用BiLSTM 神经网络层对输入的合同要素文本序列进行建模;最后,利用CRF 输出层生成对应的类别标签序列。这里,对模型中的各个组成部分拟给出重点解析如下。
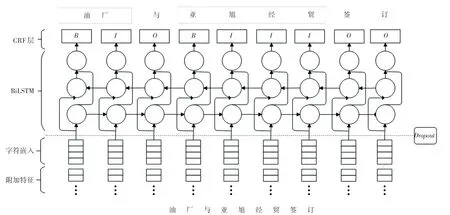
图3 基于BiLSTM-CRF 的合同抽取深度学习模型Fig.3 Contract extraction deep learning model based on BiLSTM-CRF
(1)输入特征层。本文将训练集文本看作是字的聚合,每个字在模型的输入层由字向量(Char Embedding)与额外的特征向量(Additional Features)联结而成。
(2)BiLSTM。LSTM 是具有记忆长短期信息的能力的神经网络,前向的LSTM 与后向的LSTM 结合成为BiLSTM 神经网络,网络结构如图4 所示,可以更好地捕捉双向的语义依赖。由图4 可知,对LSTM 的计算过程可做分析表述如下。
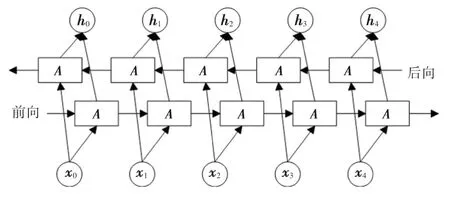
图4 BiLSTM 神经网络结构Fig.4 Structure of BiLSTM neural network
设时刻的遗忘门、输入门和输出门的输出为f、i、o,由此计算得到的数学公式为:
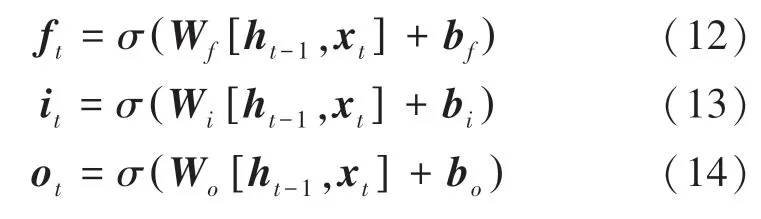
其中,x是时刻的输入向量;h是时刻的隐藏层的向量;表示使用的激活函数是函数;W、W、W分别为时刻的遗忘门、输入门和输出门对应的权重矩阵;b、b、b分别为时刻的遗忘门、输入门和输出门对应的偏置向量。
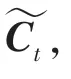
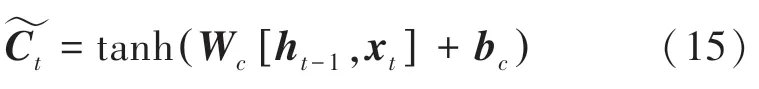
其中,W是权重矩阵,b是偏置向量。
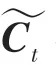
紧接着,计算长记忆C与短记忆h的值,C是时刻的单元状态,h是隐节点的输出。具体数学公式可写为:
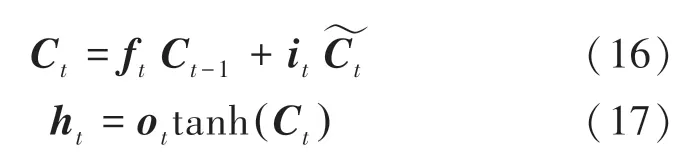
其中,f、o分别是时刻的遗忘门、输出门的输出。
输入序列信息是BiLSTM 循环神经网络提取的合同要素,结合前后向的LSTM 输出,传进CRF 层。
(3)CRF 模型输出层,得到合同文本的要素抽取结果。在BiLSTM-CRF 模型中,首先定义了句子输出标签序列的分值(,),这里推得的数学运算式可写为:

其中,是转移矩阵,表示将所有状态向下一步转移的概率;是LSTM 输出的矩阵。
利用维特比算法推断合同要素标签,搜索具有最高条件概率的合同要素标签序列,计算公式的数学表述如下:
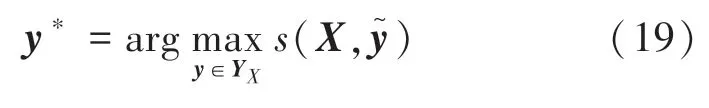
在输入层和BiLSTM 层中间,使用一个正则化,使得模型中神经网络的节点随机失活,在训练时不会出现某一个节点权重过大的情形。
4 实验结果与分析
4.1 评价指标
本文在合同文本分类和要素抽取的任务中,采用准确率()、召回率()和值作为评价指标,各指标的数学运算公式见如下:

其中,为实际值和预测值均为正值时数据的数量;为实际值为负值、预测值为正值时的数据数量;为实际值为正值、预测值为负值时数据的数量。
4.2 合同分类实验
在合同分类中,选用合同文本的中文文本数据集。从合同数据中抽取了2 000 条标题和2 000 条文本数据,其中的1 500 条作为训练集,500 条作为验证集。合同文本包括8 个类别,即买卖、建设、服务、租赁、承揽、运输、委托、借款。
神经网络模型取得良好性能的关键是选择合适的超参数。合同分类模型参数设置:层数为30 层、词向量维度为768 维、的值为0.5 和学习衰减率为0.001。
4.2.1 标题分类
为了验证本文提出的基于注意力机制的BiLSTM 模型用于合同标题分类中的有效性,将本文模 型 BiLSTM+Attention 与 TextRNN、LSTM 和BiLSTM 模型进行合同标题分类的对比实验,其实验结果见表1。
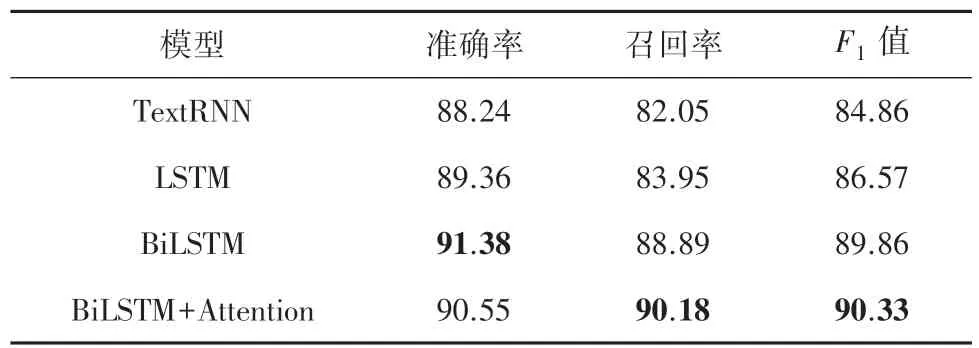
表1 标题分类不同模型的实验结果Tab.1 Titles test results of different models %
由表1 可知,在合同标题分类中,本文模型的召回率和值比其他3 个对比模型高。TextRNN 模型的准确率、召回率和值分别比本文模型低2.37%、8.13%和5.67%;LSTM 模型准确率、召回率和值比本文模型低1.19%、6.23%和3.76%;BiLSTM 模型准确率比本文模型高0.83%,但召回率和值却比本文模型低1.29%和0.47%。综合来看,在标题分类性能对比中,本文提出的BiLSTM+Attention 模型标题分类效果最好。
4.2.2 文本分类
将本文模型BiLSTM+HAN 与TextRNN、CNN 和RCNN 模型进行文本分类的实验,验证该模型用于文本分类的有效性,实验结果见表2。
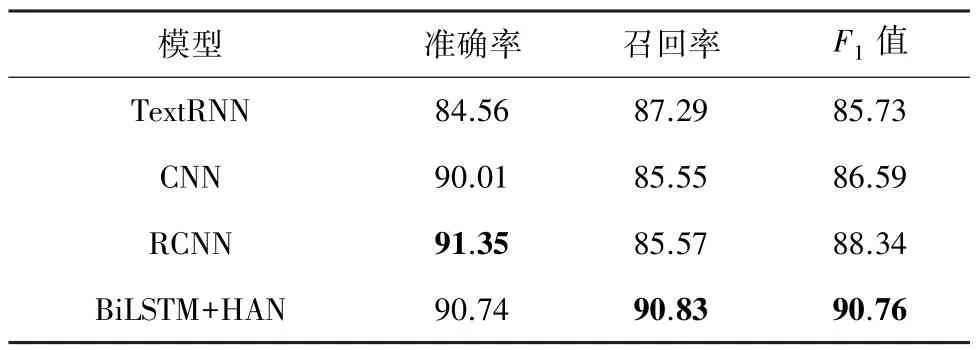
表2 文本分类不同模型的实验结果Tab.2 Text test results of different models %
由表2 可知,BiLSTM+HAN 模型的要素抽取值达到了90.76%,且在准确率和召回率上的值都达到了最佳。本文模型比TextRNN 模型准确率、召回率和值分别提高了6.18%、3.54%和5.03%;比CNN 准确率、召回率和值分别提高了0.73%、5.28%和4.17%;虽比RCNN 准确率低0.61%,但召回率和值却提高了5.26%和2.42%。本文提出的BiLSTM+HAN 模型在合同文本分类上效果明显优于其他模型。
4.3 合同要素抽取
合同要素抽取模型中各参数设置如下:学习率为0.015、隐藏层大小为200、的值为0.5、层数为32 层和学习衰减率为0.05。
为了验证本文提出的基于BiLSTM-CRF 的合同抽取模型的有效性,将本文模型与CRF、LSTM、Flat 和Lattice LSTM 模型进行合同要素抽取的对比实验,抽取效果见表3。
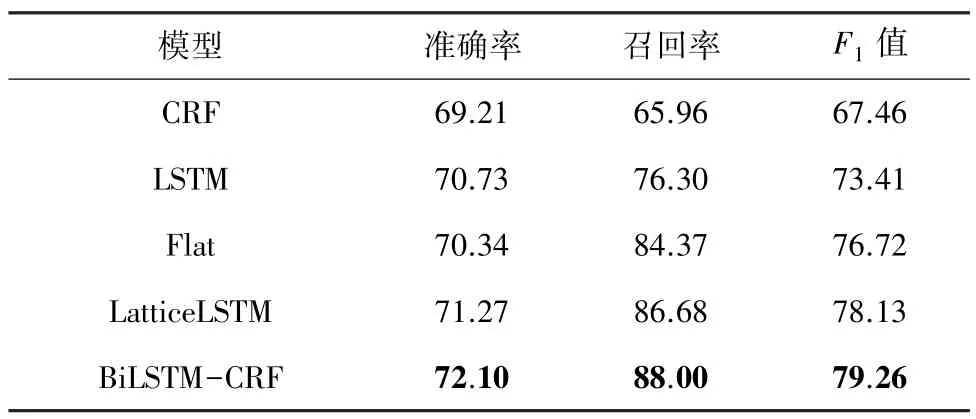
表3 不同模型的合同要素抽取效果Tab.3 Contract elements extraction effect of different models%
由表4 可知,相较于其他要素抽取模型,本文提出的BiLSTM-CRF 模型的抽取效果最好。与判别式模型CRF 相比,本文模型的准确率、召回率和值分别提高了2.89%、22.04%和11.8%;与Lattice LSTM 模型相比,本文模型的准确率、召回率和值分别提高了0.83%、1.32%和1.13%。综合来看,本文提出的基于BiLSTM-CRF 的合同抽取模型在进行合同要素抽取的任务上,明显优于其他模型。
5 结束语
本文根据《民法典》、合同文本及要素的特点,构建了合同文本的语料库,提出了基于深度学习的合同分类及要素抽取模型,实现了对合同文本标题分类、文本分类和要素抽取,并实验验证了本文提出模型的有效性。
在合同文本分类中从标题分类与文本分类两方面展开研究,提出了一种基于注意力机制的BiLSTM模型,采用词向量表示合同标题,利用BiLSTM 模型获取合同标题的特征,实现了对合同标题的分类任务;提出了一种基于改进的HAN 深度学习模型,经过词序列编码器、词级Attention 层、句子序列编码器和句子级Attention 层实现了对合同文本分类。提出了一种基于改进的HAN 深度学习模型,将合同要素拆成单个的字,使用包含前向和后向的BiLSTM神经网络层对输入的合同要素文本序列进行建模,利用CRF 层作为模型的输出层生成对应的类别标签序列,实现合同要素抽取,并实验证实了合同要素抽取模型的有效性。
在未来工作中,将尝试实现更多不同类型合同分类和抽取任务,进一步提高合同文本分类与要素抽取的性能。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
债券(2015年9期)2015-09-29
债券(2015年7期)2015-08-08
