
基于特征融合深度学习网络的情感分析模型*
2022-08-01 02:49张云纯刘志敏
计算机与数字工程 2022年6期
方 悦 张 琨 张云纯 李 寻 刘志敏 孙 琦
(南京理工大学计算机科学与工程学院 南京 210094)
1 引言
信息化时代以来,随着互联网的迅速发展以及中国网民群体的急剧增长,社交网络在社会上被迅速普及,人们在网络上发表自己的观点和想法变得更加便利。网络与社会生产生活息息相关,基于目前的舆论环境,对网络评论进行便捷精准的情感分析,从而得到直观系统的分析结果变得至关重要。
情感分析的任务是分析和提取带有主观情感的文本信息,对文本的深层情感倾向进行挖掘。情感分析算法历经长时间的研究发展,目前基本被划分为基于情感词典的算法、基于机器学习的算法以及基于深度学习的算法等[1]。
基于情感词典的算法是情感分析的传统算法,主要基于情感知识构建情感词典。Hu 等[2]提出判定情感极性的主要指标是形容词的情感强弱,从而创建情感词典用于情感挖掘。由于大部分情感词典由人工构建,对于复杂多变的文本很难构建完善的情感词典,使其具有很大的局限性。
机器学习技术在情感分析领域曾经被大量使用,朴素贝叶斯、随机森林、最大熵和支持向量机等,都是目前能经常见到的用于情感分析的机器学习算法。刘志明等[3]为提高针对微博文本的情感分析算法的性能,考虑多种因素,对多种机器学习、特征选择以及特征权重计算算法进行了实验证明研究,并通过将一般评论与微博评论进行比较,验证了不同评论风格对机器学习算法情感分类性能的限制。有监督的机器学习情感分析算法相比于情感词典算法有所进步,但机器学习的文本特征标记过于依赖人工,无法与大数据时代相适应。
现如今,基于深度学习的情感分析算法成为主流,被大量应用在自然语言处理(Natural Language Processing,NLP)领域的各个方面。基于深度学习的算法,能够使用神经网络模型处理文本信息,得到更优越的文本表示模型,继而有助于更好地提取文本中的重要语义特征进行情感分析,相较于前两种算法,该算法能够获得更好的分类效果。Hochreiter 等[4]引入梯度对循环神经网络(Recurrent Neural Networks,RNN)进行了改进,研究出长短时记忆网络(Long Short-Term Memory,LSTM),解决RNN 长距离依赖问题,使得LSTM 获得了长时间记忆能力。Pascanu 等[5]为处理RNN 的梯度问题,提出了基于几何知识的梯度范数裁剪策略,在实验部分提供了解决问题的方案。Kim[6]在2014 年,创造性地提出了将图像数据处理领域常用的卷积神经网络(Convolutional Neural Network,CNN),应用于文本分类领域,CNN通过不同大小卷积核在文本信息上滑动,获取多粒度的局部特征,文本CNN 使得深度学习在情感分析方面有了更大的发展。Lai等[7]针对文本信息处理,提出了一种无需人工设计特征的递归卷积神经网络(CRNN),使用一个递归结构尽量对前后文信息进行捕获,来学习文本中的单词表示。李松如等[8]提出了基于情感词注意力的循环神经网络模型,通过在循环神经网络中引入注意力机制,关注文本中情感词的贡献程度,以提高模型分类性能。杜永萍等[9]为了对短文本评论中隐含的语义信息进行有效分析,从而判断情感倾向性,提出了一种串行CNN-LSTM 混合模型的短文本情感分类方法。Vo 等[10]为解决串行模型中,经CNN 提取后,部分上下文语义缺失的问题,提出并行使用CNN 和LSTM 提取文本情感特征,通过特征融合进行分类。
基于以上相关研究工作的讨论,针对神经网络模型的优缺点,本文提出一种双通道CNN 和双向简单循环单元(Bidirectional Simple Recurrent Units,BiSRU)的特征融合情感分析模型(CSRMA)。模型通过GloVe进行词向量化,一个通道使用CNN捕获重点短语,从局部视野提取文本信息的深层次重要情感特征。另一通道利用BiSRU 处理序列化数据的优势,捕捉单词前后文关联语义,提取全局时序情感特征,解决CNN 模型在处理时间序列数据上的不足,通过注意力机制自主捕捉不同单词的重要程度,将BiSRU 提取的特征信息赋予权重,与BiSRU最大池化后的特征进行融合。最后将双通道情感特征融合,充分挖掘文本情感信息,使特征信息更加全面。
2 研究基础
2.1 GloVe词向量
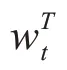

2.2 注意力机制(Attention)
注意力机制的灵感来源于日常生活中人类的视觉注意力,注意力体现在生活中的方方面面,人在观看事物时会将注意力更多集中在自己认为重要的部分,会对整体有侧重的选择,下意识忽略周围的无关信息。Bahdanau 等[14]为提高RNN 模型在机器翻译任务中的效果,结合了RNN 与注意力机制的优势,将注意力机制成功带入NLP领域。Kokkinos 等[15]在情感分析任务中引入了注意力机制,提出自注意力机制,证明了注意力机制在分类任务领域的有效性。注意力机制通过对短语赋予权重,选择与训练任务相关性更强的短语,从而能够直观地得到句子中每个短语的贡献。在情感分析中使用注意力机制,能够强化重要短语的权重,从前后文信息中筛选出最具价值的情感信息,继而达到更好地提取情感特征、提高模型分类能力的效果,如式(2)~(4)所示,对特征向量Fs分配权重进行加权输出。其中,F为经过注意力机制后的向量,tanh为激活函数,wa是注意力层的参数,为随机初始化的数值,在训练过程中会不断通过学习迭代的过程进行调整。

2.3 卷积神经网络(CNN)
CNN 是深度学习最常用也是最重要的模型之一,它不仅在图像视觉领域有优越的表现,自Kim[6]提出用于文本分类的CNN 后,在自然语言处理领域也因其突出的优点被大量使用。在结构上,CNN一般包括输入层、卷积层、池化层、全连接层和输出层,卷积核是其最基本和最重要的组件。CNN通过局部连接、共享参数和池化层,有效减少神经网络中的参数,更好地学习情感信息。CNN在卷积层对多个窗口内的词向量进行卷积运算,获取不同长度短语的语义特征,在卷积层后使用最大池化层或平均池化层,对特征图进行降维操作,提取与保留文本表征的重要信息,在一定程度上,使得卷积神经网络具有更好的泛化能力。
2.4 简单循环单元(SRU)
SRU[16]是循环神经网络的一种变体结构。针对并行计算问题,通过对LSTM 等模型结构进行分析研究,提出了改进结构的SRU模型[16]。循环神经网络具有记忆能力,适合处理时序数据,在自然语言处理任务中被广泛应用。但在比较复杂的现实语言环境中,循环神经网络处理序列的远距离前后依赖时,性能容易受到限制,长期记忆能力较弱,容易造成梯度消失或梯度爆炸,缩放性差。针对RNN[17]无法长时间记忆信息的缺陷,LSTM 通过引入记忆单元和“门”结构,有选择地记忆与遗忘,克服了RNN 对于序列信息的长距离依赖问题,更好地捕捉长序列关系,能有效地保存长期记忆。
一个LSTM 单元拥有一个内部记忆单元,一个输出单元和三个“门”结构,分别是“输入门”、“遗忘门”和“输出门”。“门”结构是一种全连接层,由一个sigmoid 层和一个逐点相乘操作构成,能够有选择性地决定让哪些信息进入记忆单元,继而控制信息的记忆与遗忘程度。但LSTM 单元之间的计算具有前后时间依赖性,难以进行并行化状态计算。
SRU 通过将每一时间步的主要计算部分进行优化,减弱状态计算上的时间依赖关系,从而实现并行化运算。SRU精简了模型结构,使得模型参数减少,引入高速路网络[18](Highway Network),对于无用信息进行丢弃,减少所需参数,减小计算代价,提高模型的并行计算能力,使得其并行度与卷积网络相同,加快了深度递归模型的训练,SRU 单元结构如图1所示。

图1 SRU单元结构图
3 模型结构
3.1 词向量嵌入
本文先对文本w进行文本预处理,再利用预训练好的开源框架glove.6B.300d[13]得出词向量矩阵S∈Rn×d,其中,n是文本中句子的长度,d是词向量维度。使用开源框架预训练得到的词向量,可以更好地度量词语之间的相关性和差异性,提高模型分类效果。将词向量矩阵S经过dropout 后作为模型的输入,对本文提出的CSRMA模型进行训练,CSRMA模型结构如图2所示。

图2 CSRMA结构图
3.2 构建CNN通道
本文先构建卷积神经网络通道提取短语特征,输入层词向量矩阵为S∈Rn×d,Si∈Rd是句子中的第i个单词的d维词向量,Si:m=Si⊕Si+1⊕···⊕Sm是第i个单词到第m个单词的拼接成的局部文本信息,⊕为拼接运算符。卷积层使用滑动窗口大小为h的卷积核M对输入矩阵S进行卷积操作,窗口的意义在于每次作用于h个单词,提取数据的局部深层次情感特征,从Si:i+h-1的窗口得到文本的第i组特征向量Ci,如式(5)所示:

其中b∈R为偏置项,f为非线性激活函数。
本文使用ReLU 激活函数,能够降低模型计算成本并能减轻梯度消失问题,如式(6)所示:

S经过卷积操作后得到特征图C,如式(7)所示:

为防止过拟合,并尽量确保在保留大部分重要信息的前提下,使输入表示的特征维度变得更小,继而使得网络中的参数和计算量减小,本文通过最大池化层对特征图C进行池化操作,为特征图C捕获最重要的功能,提取向量中最重要的信息outputCmax,如式(8)所示:

最后经过dropout 以缓解过拟合,得到CNN 通道输出的特征向量outputC。
3.3 构建BiSRU-MA通道
本文构建BiSRU-MA通道,对词语间的语义依赖关系进行学习,通过联系词语上下文信息,提取全局时序特征。t 时刻词向量St输入SRU 单元,St和单元状态ct-1经过“遗忘门”进行运算,得到ft,如式(9)所示:
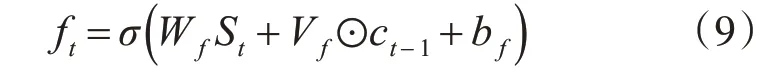
其中Wf为权重矩阵,Vf为参数向量,⊙表示逐点相乘,bf为偏置向量,σ为激活函数sigmoid。
“遗忘门”得到的ft自适应计算ct-1和当前的WSt得到t时刻SRU的单元状态ct,如式(10)所示:
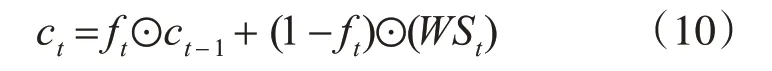
一般门控循环结构在sigmoid 层将ct-1与参数矩阵Vf通过矩阵乘法得到Vf ct-1,ct和ft必须等待ct-1全部计算完成,才能进行t时刻的计算,所以状态难以并行计算。SRU使用逐点相乘Vf⊙ct-1代替矩阵乘法Vf ct-1,使得状态向量的每个维度得以独立,实现计算并行化。
单元状态ct-1和St经过“重置门”进行相应的计算,得到rt,如式(11)所示:

SRU 针对网络进一步加深时容易造成训练困难,最后引入高速路网络,解决梯度信息在深层网络中流动受阻的问题。SRU 中ht不再依赖ht-1的计算,通过跳跃连接(1-rt)⊙St,可将梯度直接传播到前一层,改善伸缩性。rt自适应计算ct和St得到t时刻SRU的输出ht,如式(12)所示:

利用最大池化max-pooling 对前后文时序情感特征向量进行处理,抓取时序中最重要的特征Hmax。
通过注意力机制对BiSRU 输出的特征向量处理,如式(2)~(4),加强对重点词语的关注,提取出重要情感信息,得到加权向量Hatt,从而提高模型判别句子情感倾向性的能力。
最后BiSRU-MA 通道将加权特征向量Hatt融入最大池化特征向量Hmax,得到融合特征向量outputSRMA,如式(13)所示:

3.4 融合分类
融合分类层负责将CNN 通道和BiSRU-MA 通道的特征向量融合,如式(14)所示,作为全连接层的输入。

全连接层对outputCSRMA进行降维处理,使用softmax 进行分类,最终得到文本各类别情感倾向概率P,如式(15)所示:

其中Wd为权重矩阵,bd为偏置向量。
本文利用反向传播算法,通过端对端的方式,采用交叉熵损失函数,衡量目标和预测值之间的差距,对模型进行训练。通过Adam 优化方法对实验参数进行优化,从而选择最优的模型参数。
4 实验结果与分析
4.1 实验数据集
为评估本文提出的模型,本文在实验中采用四个英文公开情感语料数据集。
1)MR 是英文电影评论情感二分类数据集,包括积极和消极两种情感极性(https://www.cs.cornell.edu/people/pabo/movie-review-data/)。
2)CR 是用户对于多种商品的评论,是情感二分类数据集,标注为消极和积极(http://www.cs.uic.edu/~liub/FBS/sentiment-analysis.html)。
3)SST-2 是划分为训练集,验证集和测试集的电影评论情感二分类数据集,情感标签分为消极和积极(http://nlp.stanford.edu/sentiment/)。
4)Subj是用户评论主观性数据集,标注为主观性与客观性(http://www.cs.cornell.edu/home/llee/data/search-subj.html)。
本文对未划分训练集,验证集和测试集的MR和CR数据集,采用十折交叉验证法,进行实验。数据集规模信息如表1所示。

表1 数据集规模信息
4.2 实验超参数设置
本文使用预训练好的300维glove.6B.300d[13]框架进行词向量化,在模型训练时,设置不同的超参数会影响到模型结果,经过验证测试,本文主要采用的超参数设置如表2所示。
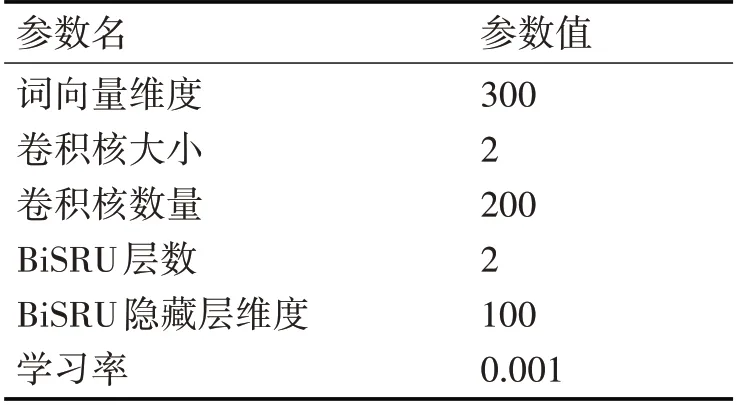
表2 超参数设置
4.3 对比实验设置
词向量维度不同会影响模型的分类效果,本文先对词向量维度进行对比研究,分别使用50 维的glove.6B.50d[13],100 维的glove.6B.100d[13],200 维的glove.6B.200d[13]和300 维的glove.6B.300d[13]进行词向量化,在MR 数据集上对本文提出的CSRMA 模型进行实验,获取最适合的词向量维度进行分类研究,结果如图3 所示,由结果可以得出,词向量维度为300 时,CSRMA 模型在MR 数据集上准确率最好。

图3 词向量维度对比
本文在四种情感语料数据集上测试模型的性能。为了对本文提出的CSRMA模型的有效性进行验证,将本文模型与一些传统神经网络模型进行对比。进行对比实验的模型见表3。

表3 实验对比模型
4.4 实验结果与分析
4.4.1 准确率分析
实验对比结果如表4 所示,将CSRMA 模型与5组模型进行对比。从结果来看,本文提出的CSRMA 模型在4 个数据集上的分类准确率均要优于其余5种模型,证明了本文融合CNN提取的局部特征和BiSRU-MA 获取的上下文特征的模型的切实有效性,对比传统神经网络模型,模型的性能得到了提升,对文本情感分类的准确率有进一步提高。
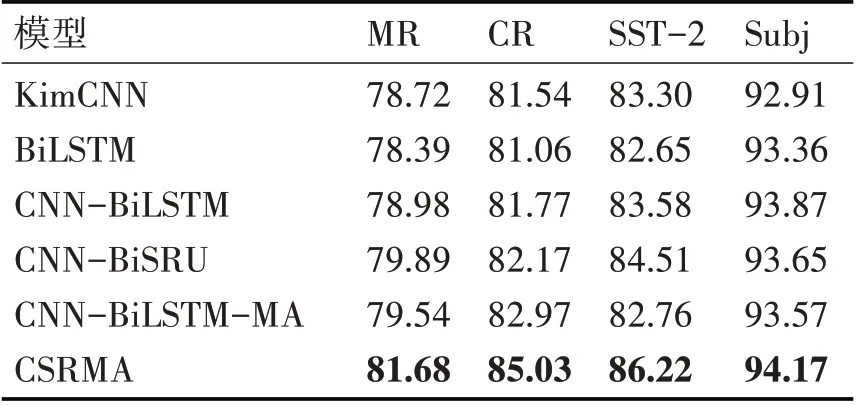
表4 模型对比结果
4.4.2 训练时间分析
将CSRMA 模型与5 组模型在数据集上耗费的训练时间进行分析,检测模型的时间性能,使用模型在SST-2数据集上最后一个epoch花费的时间进行对比。实验对比结果如表5 所示,可以看出本文提出的CSRMA 模型,一个epoch 只需要340ms,远远小于BiLSTM 模型耗费的时间。实验结果证明,模型能够对文本进行并行化处理,缩减了训练耗费的时间。

表5 训练时间
5 结语
本文研究了基于卷积神经网络和双向简单循环单元的特征融合双通道情感分析模型,并引入了最大池化和注意力机制。该模型通过卷积神经网络进行局部特征提取,并通过结合注意力机制和最大池化的双向简单循环单元捕获前后文关联语义信息,结合了两种模型的优势,获取更全面的情感特征,进一步提高情感分类效果,加快训练速度。在本文中与多个传统神经网络模型进行对比实验,验证了本文模型的性能。
本文没有使用文档级情感数据集,下一步的工作重点,是针对文档级数据集进行实验研究。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
舰船科学技术(2022年11期)2022-07-15
中国教育信息化·高教职教(2022年4期)2022-05-13
新高考·高一数学(2022年3期)2022-04-28
计算技术与自动化(2022年1期)2022-04-15
煤气与热力(2022年2期)2022-03-09
上海师范大学学报·自然科学版(2019年5期)2019-12-13
软件(2017年6期)2017-09-23
中国新通信(2017年9期)2017-05-27
高中生学习·高三版(2016年9期)2016-05-14
