
基于衰减消去蜻蜓算法的小麦粉蛋白质近红外特征波长优选
2022-08-02 03:11吴彩娥熊智新
食品科学 2022年14期
陈 勇,吴彩娥,熊智新*
(南京林业大学轻工与食品学院,江苏 南京 210037)
小麦粉中蛋白质质量分数约为7%~15%,决定着小麦粉的营养品质和加工品质,所以小麦粉蛋白含量的检测具有重要意义。小麦蛋白含量测定有化学法和物理法,前者虽然具有较高的准确度,但需要对实验材料进行繁杂的化学处理,比较耗时费力,同时实验使用的化学药品会造成一定的环境污染。与传统的化学方法相比,近红外光谱分析是一种绿色、无损快速检测技术,已经广泛应用于农业、食品、医药、化工等行业。目前,国内外学者利用近红外光谱法对小麦粉中蛋白质、灰分和水分等含量进行了检测分析。然而,近红外光谱有吸收信号弱、谱峰重叠严重以及易受外界环境干扰等缺点,并且一条光谱往往包含着数量众多的波长点,这给建立高质量的预测模型带来了很大的挑战。通过合适的波长选择方法可以在众多近红外光谱波长中筛选出具有特征信息的波长,并对数据进行有效地降维,降低建立预测模型的复杂程度,在一定程度上可提高预测模型的准确性。
常见的波长选择方法有无信息变量消除法、竞争自适应加权采样法、连续投影算法以及群体智能优化算法。群体智能优化算法具有强大的全局搜索能力,使其在特征变量筛选方面潜力巨大,其中遗传算法、粒子群算法、灰狼算法等在波长选择上已有很多成功研究案例。其中,蜻蜓算法(dragonfly algorithm,DA)是Mirjalili等在2016年通过对自然界蜻蜓行为进行观察、总结和抽象后,提出的一种新智能群体优化算法。之后,分别采用连续DA、二进制DA(binary DA,BDA)及多目标DA,通过对几类典型函数进行优化验证了算法的有效性。2019年,Chen Yuanyuan等首次把BDA应用于近红外特征波长筛选,并比较了单群BDA(single-BDA)、多群BDA(multi-BDA)、基于集成学习BDA(ensemble learning-based BDA,ELB-BDA),表明后两种算法可以明显提高波长选择的稳定性以及分析模型的泛化能力。然而,使用BDA进行波长筛选最终得到的波长位置和波长数量具有强随机性。尽管使用multi-BDA和ELB-BDA在一定程度上降低了波长数量并进一步筛选出特征波长,提高了算法的稳定性,但是这两种策略操作复杂,需要多次进行single-BDA运算,导致运行时间远多于single-BDA,不利于快速建模。并且由于multi-BDA和ELB-BDA的内核还是single-BDA算法,选出的波长分布随机性仍然较大。为了加快变量选择速度,Yun Yonghuan等基于达尔文自然进化论中简单有效的“适者生存”原则,在变量组合集群分析的变量选择策略中采用指数衰减函数不断缩小搜寻空间以加快算法速度。借鉴这一思想,在single-BDA算法中引入指数衰减函数,使算法能在迭代过程中由快趋缓地剔除无用变量,有利于保留重要变量,但不利的是由于衰减曲线末端趋向平缓可能造成无效计算,或末端迭代删除变量数大于1而漏掉某一组或多组变量组合中可能存在的最优变量。为此,本研究尝试用线性衰减函数代替末期的指数衰减函数,保证算法末期每迭代一次剔除一个变量。Single-BDA算法的改进因此分为两个阶段:第1阶段使用指数衰减函数对变量进行快速挑选;第2阶段采用线性衰减函数对变量进行精细挑选。本研究把改进算法命名为衰减消去BDA(attenuation elimination-BDA,AEBDA),以期能从小麦粉近红外光谱中尽快挑选出数量少且稳定的特征波长,并建立精度较高的蛋白质近红外分析模型。
1 材料与方法
1.1 材料
市购不同品牌以及不同批次的160 个小麦粉的样品,置于保鲜袋中于室温(20~23 ℃)保存。
1.2 仪器与设备
Micro NIR Pro 1700便携式近红外光谱仪 美国Viavi Solutions公司;D200杜马斯定氮仪 海能未来科技有限公司。
1.3 方法
1.3.1 小麦粉蛋白质含量的测定
参照GB 5009.5ü2016《食品中蛋白质的测定》中的燃烧法进行测定。
1.3.2 近红外光谱采集
对小麦粉样品在室温(20~23 ℃)环境下不做前处理进行光谱扫描。光谱仪机身采用金属试管架夹持固定,探头向下垂直对准深1 cm的圆盘样品池,样品池顶部与探头底部相距1 cm。采集光谱时,小麦粉样品铺平样品池,按120°的角度间隔采集,得到3 条不同检测点的光谱,取平均作为该样品的最终采集光谱。仪器的波长范围为908~1 650 nm,光谱分辨率为6.25 nm,有125 个波长通道,并用与仪器配套的测控软件MicroNIRTM Pro v2.5采集和储存信号。
1.3.3 预处理方法
常见的预处理方法有移动平滑法(moving average filter,MAF)、卷积平滑法(Savitzky-Golay filter,SGF)、一阶导数(1st D)、标准正态变量变换(standard normal variate transformation,SNV)等。使用这4 种预处理方法的3 种组合(MAF与SNV、SGF与SNV、1st D与SNV,预处理窗口宽度为5)以求达到最好的建模预测效果。
1.3.4 建模与模型评估方法
建模方法采用偏最小二乘回归(partial least square regression,PLSR)算法,交互验证采用留一法;single-BDA和AE-BDA算法中采用的适应度函数为PLSR回归建模中交互验证标准偏差(root mean square error of cross validation,RMSECV)。
使用RMSECV、预测标准偏差(root mean square errors of prediction,RMSEP)、决定系数()对所建立的校正模型进行评估,计算方法如下:

式(1)~(3)中:y为第个样品化学值的测定值;y为预测过程中第个样品的预测值;为所用样品集样品数;为化学值测定值的均值。
在建模预测过程中,越接近1,表示模型的回归或者预测结果越好;如果为负值,表示拟合效果极差。RMSECV与RMSEP的值越小表示所建立的模型的稳定性与精确度越好。
1.3.5 波长变量选择方法
1.3.5.1 Single-BDA波长选择
蜻蜓通常通过5 种主要策略改变它们的位置:避撞、结队、聚集、觅食、躲避。应用到波长选择方法中,食物即最优解,敌人即极差解,通过不断改变位置即迭代更新运算直至到达食物的位置即求得最优解。据此建立的位置更新计算方法如表1所示。

表1 蜻蜓5 种主要位置更新策略的数学建模Table 1 Mathematical modeling of five major position shift strategies of dragonfly
采用single-BDA算法进行波长选择时,位置向量X的每个元素值只能是0或1,因此蜻蜓位置更新并非如表1所示的直接在原有位置X后加上更新速度值Δ,而是只能在0和1之间切换。这就需要对Δ进行连续域到离散域的转换。最简单、最有效的方法是采用传递函数(式(4)),以Δ作为函数输入,返回一个[0,1]之间的数值,表示位置变化的概率。

计算所有个体位置的变化概率后,应用式(5)更新蜻蜓在空间中的搜索位置:
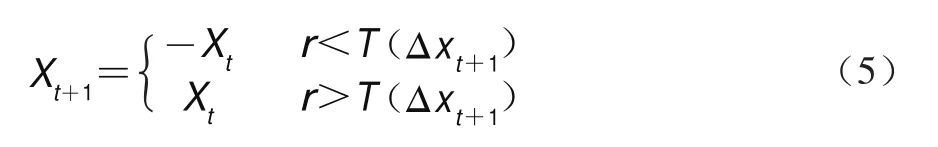
式(5)中:为0到1之间的随机数,负号表示逻辑取反运算。
1.3.5.2 AE-BDA波长选择
AE-BDA算法是经single-BDA算法结合指数和线性衰减函数改进而来,其在波长筛选过程中主要分为前后两个部分:快速挑选和精细挑选,两部分流程如图1所示。设定最优波长组合比例,AE-BDA算法在迭代运行过程中,统计每次迭代single-BDA计算完毕产生的所有个体中前h个最优RMSECV个体中波长出现的次数。出现的频率越高,表示波长越重要。然后,按指数或线性衰减函数所计算的当前AE-BDA迭代应保留的变量数,确定需要剔除的无用波长。AE-BDA算法采用均等抽样法(equal sampling method,ESM),产生算法迭代中single-BDA第一代初始二进制矩阵,保证每个波长具有相同的被选中机会。
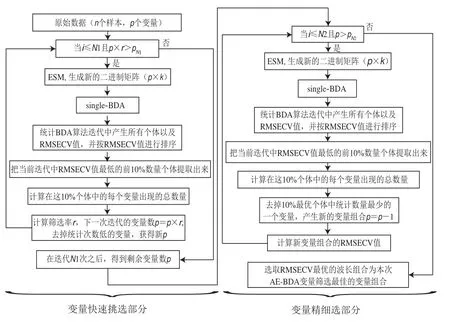
图1 AE-BDA流程图Fig.1 Flow chart of AE-BDA
波长快速挑选部分:算法开始,在全波段中无用波长数所占比例高,随着迭代的进行其所占比例逐步降低,根据指数衰减函数曲线特点,波长剔除速度由快到缓。在这一步中,设置种群数中个体数为,原始变量数为,快速筛选部分筛选变化率,算法运行结束保留的波长个数为p(1为快速挑选部分迭代次数),如果当前迭代变量数hr<p,则快速挑选部分结束;通过不断的迭代更新,波长数量呈指数级减少,达到所设置保留的波长个数p为止。每次迭代所保留的波长数为:

式(6)中:为当前迭代次数;为波长筛选率;p为第次迭代后所剩的理论波长数。
精细挑选部分:根据线性衰减函数曲线特点,保证在算法末期每代可剔除一个变量。设置最终波长数p(2为精细挑选部分迭代次数),筛选过程中每次迭代并剔除出现次数最少的1 个波长,利用当次迭代得到的波长组合建立PLSR模型,记录校正集的RMSECV。每次迭代所保留的波长数为:

式(7)中:为当前迭代次数。
当波长数减少到最小设定值p时,迭代终止。选取全部RMSECV记录中最小的波长组合作为AE-BDA波长优选结果。
图2中,曲线1为AE-BDA算法波长数量的衰减趋势图(以初始变量数=500 个,p=30 个,最终波长数p=10 个为例)。在快速挑选部分,受指数函数性质影响,波长数量经过1次迭代快速降低到p个,然后再由精细挑选进一步压缩波长数量至最小波长数p个;曲线2为指数衰减函数变量衰减曲线,曲线1相比较于曲线2在算法末端(p至p阶段)逐个波长剔除,不会导致某一波长点数被跳过。图2的柱状图为每一次迭代剔除的无用变量数量,在快速挑选部分,随着迭代次数的增加每次迭代剔除的无用变量数也呈指数减少;在精细挑选部分,每一代消去1 个无用变量,保证无用变量被精细均匀剔除。
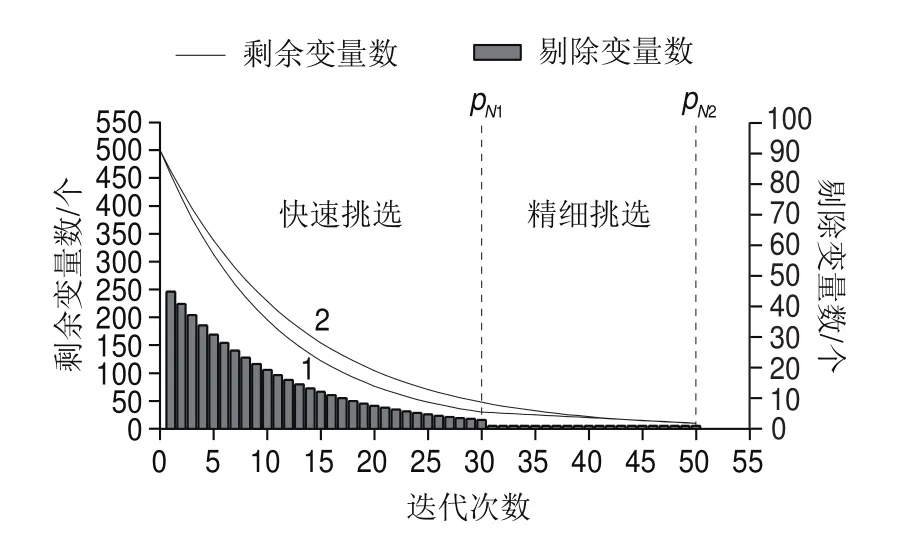
图2 AE-BDA算法波长数衰减图Fig.2 Decreasing number of variables in AE-BDA
1.4 数据处理
使用MATLAB 2016a软件以及实验室自主开发的NIRSA 5.9.4化学计量学软件,采用主成分分析和马氏距离相结合的方法检测异常样本,主成分分析结合Kennard-Stone的方法对校正集和预测集进行划分。
2 结果与分析
2.1 小麦粉近红外光谱图
图3为小麦粉近红外光谱部分原始光谱,共有160 条小麦粉近红外光谱,每条光谱含125 个波长通道。

图3 小麦粉近红外光谱部分原始光谱Fig.3 Selected original near-infrared spectra of wheat flour
2.2 小麦粉蛋白质含量
由表2可知,所选样本的蛋白质含量基本覆盖小麦粉中蛋白质质量分数(7%~15%)且分布较为均匀,表明实验所选样本具有代表性。

表2 小麦粉蛋白质含量统计表Table 2 Statistics of protein content of wheat flour
2.3 样本异常值剔除与样本集划分
样品、采集环境和仪器在一定程度上会产生异常样本数据,严重影响所建模型的稳定性与预测能力,所以在建模前必须将异常样本数据从集合中剔除。3 种预处理组合各自检测出的异常样本集的并集(共8 个样本)作为总异常样本集予以剔除。最后,划分剩余的152 个样本为校正集和预测集;共得到98 个校正集样本,54 个预测集样本。如表3所示,校正集与预测集的样本分布较宽,具有良好的代表性。
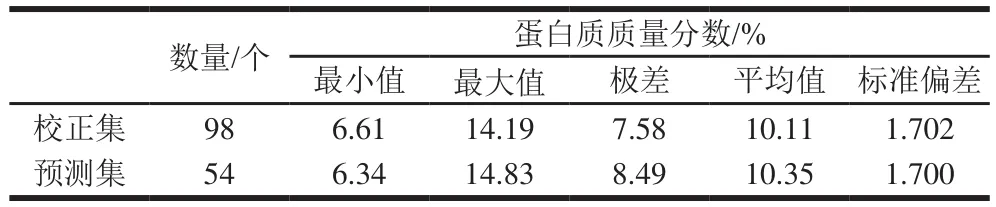
表3 校正集与预测集小麦粉蛋白质含量统计表Table 3 Statistics of protein content of wheat flour in calibration and prediction sets
2.4 预处理方法对全谱段PLSR建模及预测的影响
由表4可知,MAF与SNV预处理组合的PLSR模型除

表4 不同预处理方法全谱PLSR模型性能Table 4 Performance of full-band PLSR models developed using different preprocessing methods
值略低于SGF与SNV预处理组合的PLSR模型外,各指标均优于其他建模方法。这说明采用MAF和SNV组合的预处理方法建立PLSR全谱校正模型可以提高小麦粉近红外全谱段模型稳定性和预测精度。因此,后续波长选择算法研究中光谱都采用MAF与SNV组合进行预处理。
2.5 2 种算法对波长选择建模及预测的影响
分别用single-BDA和AE-BDA 2 种方法进行波长筛选后建模,16 次建模及预测实验结果的比较列于表5。实验S1~S8波长选择方法为single-BDA,实验A1~A8波长选择方法为AE-BDA。其中,AE-BDA算法设置种群数为200 个,衰减率为0.9,p设置为20 个,p设置为10 个,每次迭代中内核single-BDA迭代次数为10 次。经过程序运行后AE-BDA共迭代28 次(快速挑选迭代18 次,精细挑选迭代10 次),其内核single-BDA共迭代280 次。为了便于改进前后方法对比,single-BDA设置种群数量为200 个,迭代次数为280 次,筛选率为20%。
由表4和表5可知,无论是single-BDA还是AE-BDA算法,挑选后的波长进行建模及预测效果均明显优于全谱段建模。使用single-BDA进行波长选择时,实验S1~S8所挑选出的平均波长数为28.38 个,占原始波长数(125 个)的22.7%;而使用AE-BDA方法进行波长选择时,实验A1~A8所挑选出平均波长数为15.8 个,为原始波长数的12.6%,相较于single-BDA方法筛选出建模波长数量更少。同时可以看到,AE-BDA方法挑选出的波长建模和预测评价指标相应都较接近,且其预测效果总体上好于single-BDA方法。尽管single-BDA方法建立的模型评价指标及RMSECV总体上比AE-BDA好,但预测效果却相对略差,这说明single-BDA方法选择的波长过多,建立的模型可能存在过拟合现象,导致预测结果变差。
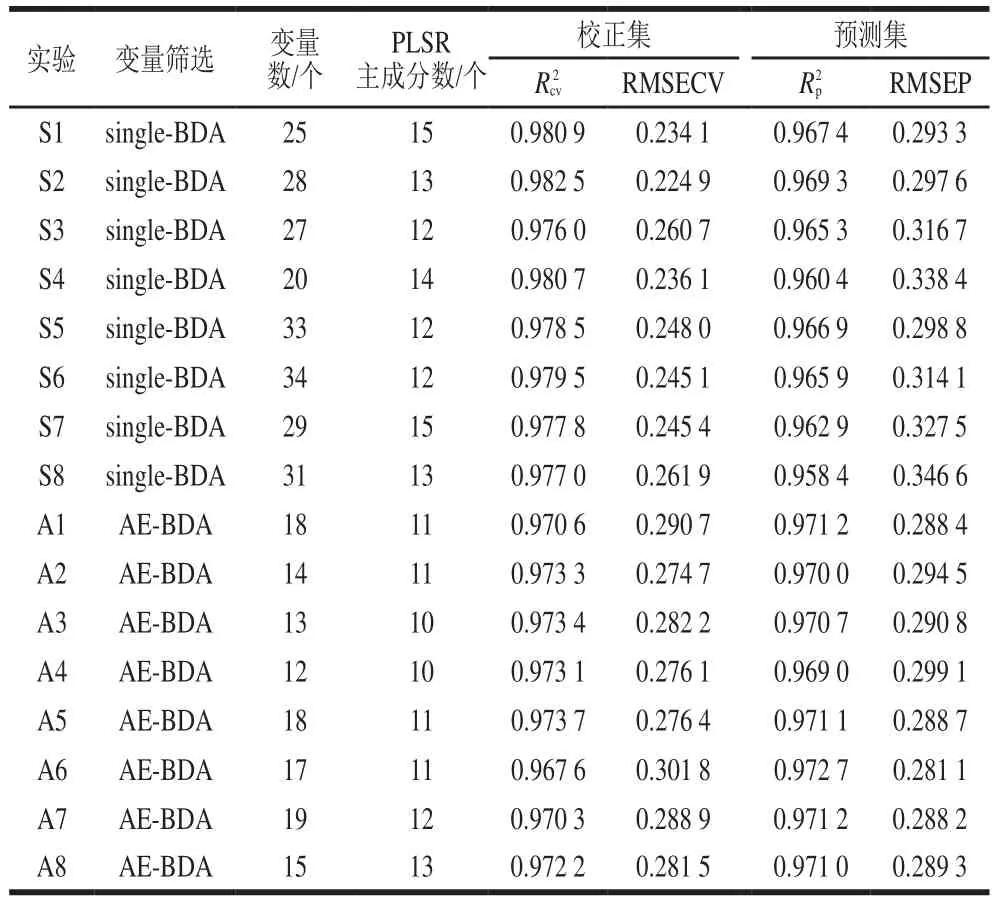
表5 Single-BDA与AE-BDA建模及预测性能比较Table 5 Comparison of modeling and prediction performance between single-BDA and AE-BDA
由图4和图5可知,尽管两种方法都是采用随机算法更新决策变量,但AE-BDA与single-BDA相比所挑选的波长点少,分布范围更加集中,且AE-BDA中有3 个特征波长(1 385.07、1 508.95 nm和1 589.48 nm)在8 次实验中均被挑选出来,而single-BDA方法挑选出频次最多的2 个波长(908.1、1 502.76 nm)只有7 次。这说明AE-BDA挑选波长的随机性要弱于single-BDA方法,结果更加稳定。
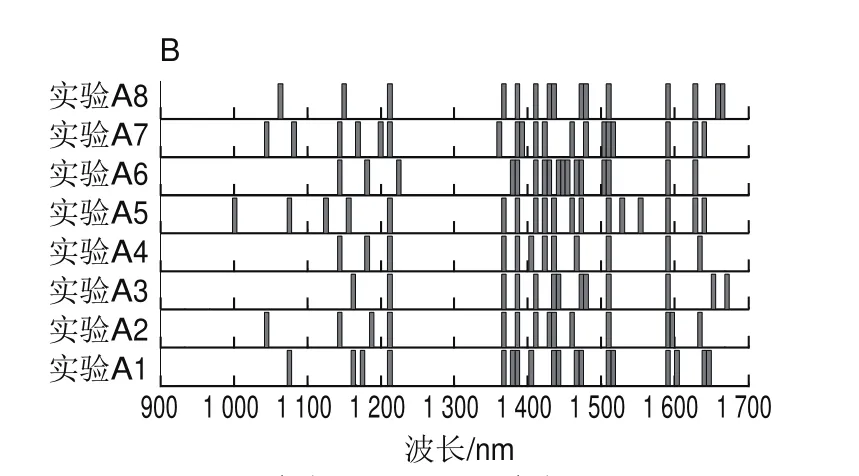
图4 Single-BDA(A)和AE-BDA(B)实验入选波长位置Fig.4 Selected wavelength locations in single-BDA (A) and AE-BDA (B) experiments
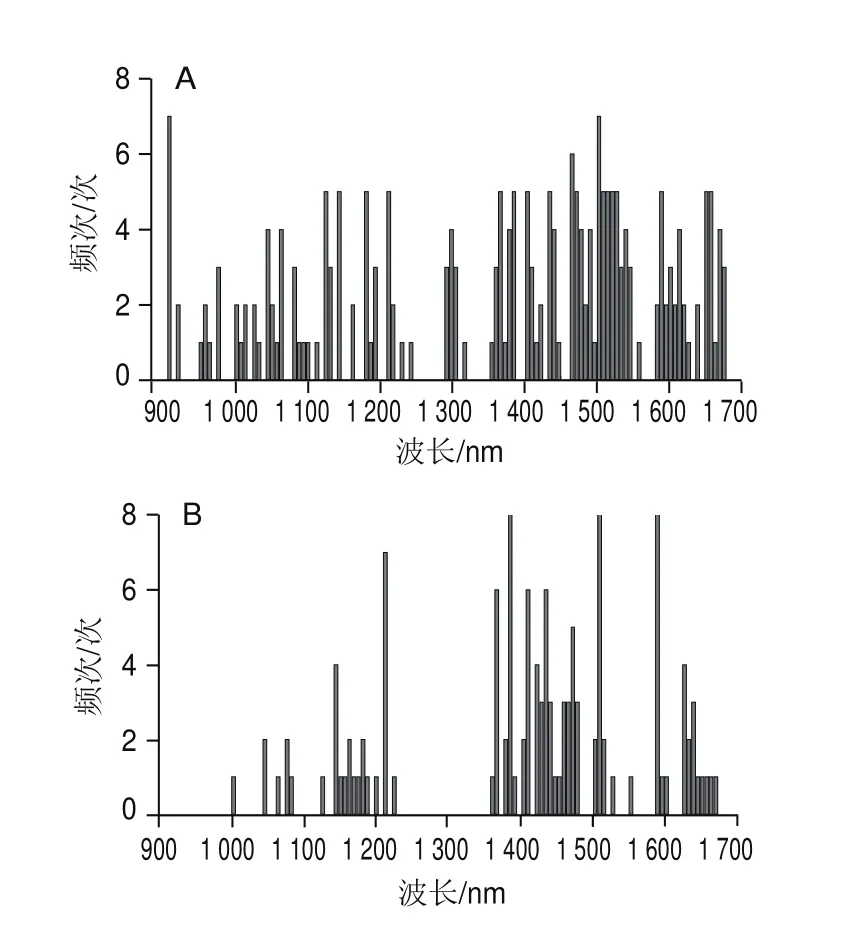
图5 Single-BDA(A)和AE-BDA(B)实验中波长出现频次图Fig.5 Frequency of appearance of wavelengths in single-BDA (A) and AE-BDA (B) experiments
AE-BDA相较于single-BDA方法计算效率更高。由图6可知,种群数相同(200 个)的情况下,随着迭代次数的增加,AE-BDA参与迭代计算的总波长数呈指数下降,意味计算量也呈指数级降低,计算过程逐步加速;而single-BDA算法在迭代过程中,进入每一次迭代的总波长数是不变的,计算量不变,运算速度保持相对恒定,运算时间较长。

图6 Single-BDA和AE-BDA在迭代过程中初始波长数变化曲线Fig.6 Change in initial number of wavelength in single-BDA and AE-BDA as a function of number of iterations
虽然近红外光谱带重叠严重且很难清晰地指出各谱峰对应的具体基团信息,但根据近红外主要谱带归属仍可对所选波长的合理性做出必要分析。本研究仅讨论8 次AE-BDA实验中每次都被挑选出的3 个波长点。蛋白质分子中含有氨基,NüH键伸缩振动的一级倍频吸收带位于1 510 nm波长附近,1 508.95nm波长处为-氨基酸中的氨基的吸收峰;甲基和亚甲基中CüH键的伸缩振动的一级倍频和变形振动的基频吸收带位于1 360~1 395nm波长处,1 385.07 nm波长处为CüH吸收峰;波长1 589.48 nm处位于OüH键的一级倍频吸收谱区,由于模型中其标准回归系数为负且较大,可以判断为主要由非蛋白质分子中OüH键吸收引起(波长点位置见图7)。这可以作为对小麦粉中淀粉、脂肪等强背景组分的修正。通过进一步对照分析可以看出,所选其他波长点大部分也位于以上谱带区域内或者附近。

图7 出现8 次的波长点在全谱段的位置Fig.7 Locations of wavelengths that appeared eight times in the full-band spectrum
3 结 论
针对常规的single-BDA在近红外光谱波长筛选过程中出现的问题,引入指数衰减函数和线性衰减函数对其进行改进,形成AE-BDA,并结合PLSR建立了小麦粉蛋白质近红外分析模型。通过对AE-BDA所挑选出的波长进行特征分析表明,这些波长较好地分布于蛋白质分子的主要官能团吸收区域。蛋白质分子中重要的NüH键的吸收波长(1 508.95 nm)每次都能被挑选出来;其他反映蛋白质分子的甲基、亚甲基以及次甲基的CüH键吸收波长也因出现频次高而作为挑选出的特征波长用于建立小麦粉蛋白质近红外分析模型,提高了模型的可解释性。
改进后的AE-BDA运算速度快,所选波长稳定,且一定程度上克服了过拟合,所建模型精度高。这为小麦粉蛋白质近红外光谱提供了一种可靠、有效的波长挑选方法,对于其他分析对象的近红外光谱的变量选择也有重要的借鉴意义。在后续研究中可以优化算法中各因子的取值范围,探讨其对AE-BDA的影响,进一步提高算法的运行效率和自动化水平。
猜你喜欢
粮食加工(2022年5期)2022-12-28
今日农业(2022年14期)2022-11-10
北京航空航天大学学报(2022年8期)2022-08-31
杭州电子科技大学学报(自然科学版)(2022年3期)2022-06-08
阅读(科学探秘)(2021年8期)2021-09-01
食品安全导刊(2021年21期)2021-08-30
空间科学学报(2021年1期)2021-05-22
中国科学院大学学报(2019年1期)2019-01-21
航天返回与遥感(2014年4期)2014-07-31
食品工业科技(2014年23期)2014-03-11
