
软件定义网络下大象流拥塞路由调度算法
2022-08-03 09:26刘向举徐杨洋方贤进
湖北民族大学学报(自然科学版) 2022年2期
刘向举,徐杨洋,方贤进,赵 犇
(安徽理工大学 计算机科学与工程学院,安徽 淮南 232001)
随着当今网络的飞速发展,网络中业务的承载量也在逐渐增加,互联网应面向业务做出快速的应用请求来满足业务需要,促使业务产生多方向、多层度的网络需求变化.传统网络存在网络部署困难、管理复杂、流量难以控制、难以可视化、分布式架构出现瓶颈、设备不可编程等缺陷.在这样的背景下,产生一种新型网络架构——软件定义网络(software defined network,SDN).SDN的出现促使研究人员可以在不断增长的网络规模中进行集中式自动化的管理,在大型数据中心中部署大量的新兴业务,同时使一些新型的数据中心的网络拓扑如胖树[1]、Bcube、VL2(virtual layer-2)、Helios等得以实现.在数据中心网络(data center network,DCN)[2-3]中同时存在着两种不同类型的流量,分别为数据占比小而承载数据量大的大象流[4-5]与数据占比大而承载数据量小的老鼠流,通过流分类区分出大象流是解决DCN中流量调度的首要工作.SDN在解决DCN中大象流拥塞路由调度时,利用SDN控制器,根据业务需求对转发设备进行转发策略的定义,同时在控制器内进行全局网络链路状态的实时监测,依据网络状态变化,通过转发策略选择空闲链路完成对DCN中流量的调度,从而提高网络质量.在DCN中任意主机间通过多条路径选择最优下发路径避免链路拥塞,进行高效的流调度来提高带宽和网络吞吐量是一个具有挑战性的问题[6-7].
目前,研究者将SDN与DCN结合来解决传统网络中静态路由的问题.等价多路径(equal-cost multi-path,ECMP)[8]算法是解决DCN中路由问题的传统算法,使用ECMP算法进行路由下发时,将产生多条相同开销的路由项.当某路径出现问题时,通过其余相同开销的路由项替换实现网络负载均衡,但由于各路径间存在带宽、时延等开销不一致,产生网路负载不唯一,且ECMP算法无法进行拥塞感知与大小流分类等问题,容易将流分散到剩余带宽较小的链路上,加剧链路的拥塞.郝建华等[9]提出基于路径关键度的重路由(rerouting based on path criticality,RPC)算法,根据启发式算法将链路负载与时延作为评价指标解决链路拥塞问题,算法对时延以及吞吐量有一定的改善,但主机间通信模式的选择及路径中评价参数的选取不完善.Al-fares等[10]利用全局首次适应(global fit first,GFF)算法运用在大象流调度中,通过对链路负载计算,将大象流动态调度到链路负载较低的路径上避免拥塞,但由于路径选择上的随机性以及控制器和交换机之间的频繁交互,指令开销加大.付应辉等[11]为避免链路拥塞的情况,通过对链路进行评估,充分利用网络剩余带宽,根据链路剩余带宽来选择最优的转发路径,算法的稳定性得到一定地提升,但仅局限于数据流的带宽,未多方面考虑传输性质以及评价指标对网络路径选择的影响.张伟东等[12]提出在DCN下进行流分类后对拥塞控制算法的研究,主要选择链路利用率以及时延作为路由权值的计算,通过选择权值小的路径作为最优路径进行数据流地转发提高网络质量,但未考虑主机间的通信模式.Lan等[13]根据单链路的动态负载均衡路径优化(dynamic load-balanced path optimization,DLPO)算法与多链路DLPO算法结合成动态负载平衡优化算法,在流的传输过程中改变流的路径来避免网络拥塞,有效地提高了链路利用率和吞吐量.Cui等[14]提出一种本地的、轻量级的在DCN中用于自适应分组交换的分布式流调度(distributed flow scheduling,DiFS)协议.通过交换机间的控制命令来实现DiFS交换机间的相互协作,减少流量冲突,避免本地和远程碰撞,实现流到链路的平衡.彭大芹等[15]通过对链路实时状态的收集,根据链路特征,将大象流依据路径权重来进行路径选择,对于老鼠流则根据剩余带宽进行路由来提高网络质量,算法本身考虑性能不充分,没从多角度进行性能分析.农黄武等[16]在SDN架构下提出实用性算法,通过控制器进行状态信息监控来实现最优路径下发.何东泽等[17]提出一种基于SDN的数据中心多路径负载均衡算法,该算法通过链路状态信息的收集,以蚁群算法作为寻路算法选择最优路径.但两者未考虑大小流分类问题以及链路是否出现拥塞和拥塞处理.马枢清等[18]采用粒子群优化算法,通过对粒子聚合度的判断,避免产生局部最优问题,减轻网络负载.Zhang等[19]在研究DCN中流调度问题,通过稳定匹配理论为流调度问题建模,证明了该问题为非确定性多项式难问题,通过寻找大象流与交换机之间稳定匹配项,使得该方法在流的完成时间上有所降低,提高网络质量,但未考虑网络中的链路问题.刘振鹏等[20]提出的动态流量调度策略(dynamic traffic scheduling of network load,DTSNL)根据带宽占比为大象流进行路由调度,提高网络质量.黄冰[21]提出的面向服务质量的动态流量调度策略(dynamic scheduling flows,DSFlows),综合考虑路径可用带宽、路径时延、路径带宽均衡制定路由策略,但未考虑链路拥塞的处理状况.
针对上述研究中未考虑大象流流量下链路拥塞以及主机间通信模式选择的问题,本文提出在SDN架构下大象流的拥塞路由调度算法.将路径带宽最优与路径时延的归一化作为多目标评价指标模型,采用改进的带精英策略的非支配排序遗传(bandwidth delay-non-dominated sorting genetic algorithm-II,BD-NSGA2)算法保证全局搜索以及增加个体间遗传机会,通过最佳路径的计算将大象流下发到空闲链路上,以此避免链路拥塞.
1 模型构建
拥塞路由调度问题的解决是建立在网络拓扑及网络实时状态约束下,通过控制器与交换机之间的交互,再根据拥塞路由调度功能,构建出大象流拥塞路由调度模型.所选择的网络拓扑结构为典型的胖树拓扑结构,将网络拓扑构造成有向图G=(N,L)结构,N表示网络中交换机节点的集合,N={n1,n2,…,nz},其中z=|N|表示交换机个数;L表示网路中链路的集合,L={l1,l2,…,le},其中e=|L|表示链路个数.基于BD-NSGA2算法的拥塞路由调度主要包括五大模块:网络拓扑发现、流量监控、链路时延监测、流分类以及链路拥塞判断,模块架构如图1所示.
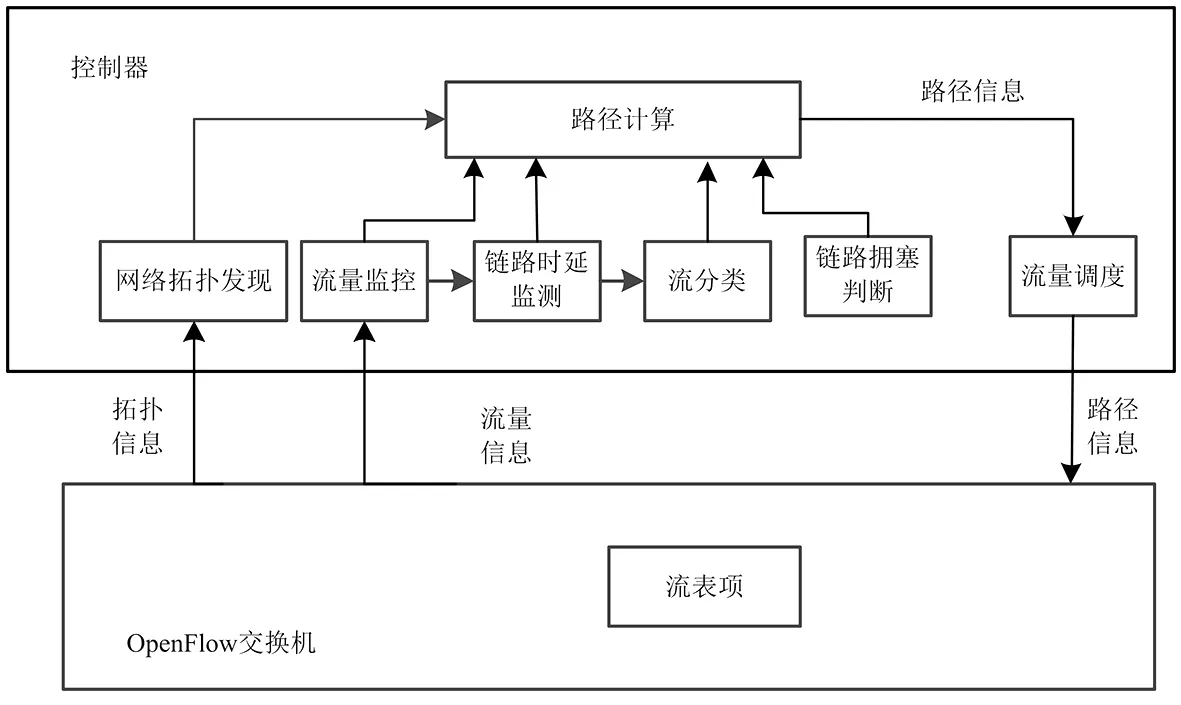
图1 BD-NSGA2模块架构Fig.1 Module architecture of BD-NSGA2
1.1 功能模块
1.1.1 网络拓扑发现 用于网络初始化,通过周期性向网络拓扑中各交换机发送链路层发现协议(link layer discovery protocol,LLDP)数据包获取交换机间的网络连接信息,进而获取全局网络拓扑信息.
1.1.2 流量监控 首先通过Ryu控制器进行SimpleMonitor对象的初始化,然后以周期t运转_monitor方法,并向OpenFlow交换机发送OFPFlowStatsRequest请求与OFPPortStatsRequest请求,OpenFlow交换机收到请求后向控制器回复相应的统计消息回复报文.控制器解析消息得到流量统计信息txpkts、txbytes、txerror,运用流量统计信息计算链路速率、丢包率以及链路可用带宽等.
定义1链路i速率计算公式:
(1)
定义2链路i丢包率计算公式:
(2)
定义3链路i可用带宽:
Bi=Bmax-sri(Δt).
(3)
定义4路径p可用带宽:
Bp=min{B1,B2,B3,…,Bn}.
(4)
式(1)~(4)中i满足条件i∈[1,n];txbytes(t+Δt)与txbytes(t)分别表示t+Δt时刻与t时刻传输的字节数;txerror(t+Δt)与txerror(t)分别表示t+Δt时刻与t时刻的丢包数;txpkts(t+Δt)与txpkts(t)分别表示t+Δt时刻与t时刻数据包的传输数量;Bmax为链路端口最大带宽.
1.1.3 链路时延监测 通过Ryu控制器在网络链路中的LLDP数据包,产生LLDP时延,其中Tlldp1(k)与Tlldp2(k+1)为交换机与控制器间的LLDP时延,Techoa与Techob为ECHO报文测试的控制器到交换机的往返时延.
定义5链路平均时延:
(5)
定义6路径时延:
(6)
1.1.4 流分类 在DCN中存在两类流量,其中一类为由数据备份产生对带宽需求和时延敏感的大象流,另一类由Web服务以及分布式计算等进程产生对网络中时延较为敏感的老鼠流.本文主要根据流量监控,以Δt时间内流量大小与链路可用带宽的比值w进行大小流划分,并将w>0.1时的数据流定为大象流.
(7)
式中txbytes(t+△t)-txbytes(t)为交换机在时间Δt内的数据流的字节数,且w∈(0,1).
1.1.5 链路拥塞判断 检测DCN中链路是否发生链路拥塞情况,在获取网络状态信息后,通过SDN控制器与汇聚层交换机进行信息交互,获取链路负载信息,根据链路最小带宽与最大带宽的比值进行链路拥塞判断.链路负载评判标准l为
(8)
当l<0.3时,链路处于拥塞状态,并将拥塞链路记录保存.
1.2 路径评价指标模型
在大象流进行流量调度过程中,对时延和带宽较为敏感,因此链路拥塞情况需根据路径带宽最优以及路径时延进行综合考虑,由于指标单位的不同,为了构成更好的路径评价指标,需对两者进行归一化处理.
定义7路径带宽最优归一化:
(9)
定义8路径时延归一化:
(10)
当f1与f2越大,链路可用带宽越大,路径时延越小,对路径选择的能力越强.
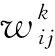
目标函数:最大化f1∪f2.
约束条件:
(11)
(12)
(13)
(14)
式(11)表示链路流量小于或等于链路容量;式(12)满足链路中流量守恒定律;式(13)表示从sk流出的流量与dk流入的流量相等;式(14)表示除sk、dk外,在交换机节点流入的流量值等于流出的流量值.
2 BD-NSAG2算法设计
带精英策略的非支配排序遗传(non-dominated sorting genetic algorithm-II,NSGA2)算法[22]是解决多目标优化的基准算法,该算法将种群中优秀个体大概率保留,提高种群中个体的优质性,同时减少收敛时间.BD-NSGA2算法是建立在NSGA2算法基础之上,对NSGA2算法中存在的全局性搜索无法保证以及个体遗传机会不足等缺点,BD-NSGA2算法通过标准差拥挤度计算、非支配个体层制约的精英策略以及算数交叉算子的交叉方式三方面进行改进,避免算法陷入局部最优.将DCN中Δt时间内流量大小与链路可用带宽比值形成阈值对大小流进行分类,区分出大象流.在大象流的流量调度中,通过链路负载评判标准对链路进行拥塞判断.链路发生拥塞时,首先采用K最短路径计算出k条初始路径,然后采用BD-NSGA2算法解决大象流拥塞路由调度问题.BD-NSGA2算法流程如图2所示.
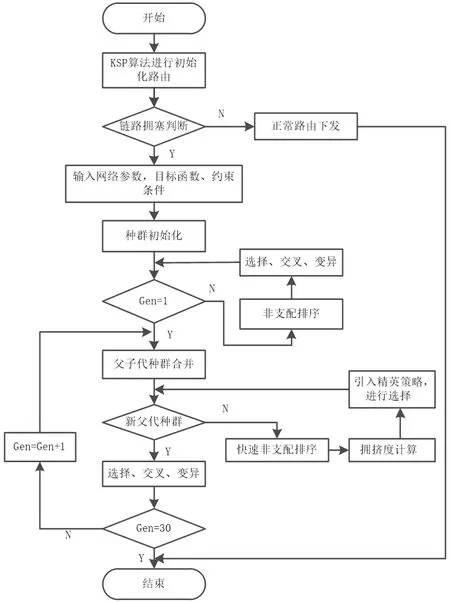
图2 BD-NSGA2算法流程Fig.2 Flow diagram of BD-NSGA2 algorithm
2.1 初始化路由


表1 KSP算法Tab.1 KSP algorithm
2.2 BD-NSGA2算法
在大象流进行流量下发的过程中,当链路发生拥塞问题时,BD-NSGA2算法可以对资源进行重新分配,选择网络中空闲链路进行下发,解决链路拥塞的问题.该算法核心在于快速非支配排序、拥挤度计算、精英策略和交叉变异.
2.2.1 快速非支配排序 设种群大小为P,每个个体为p、解个体数np以及个体支配的解的集合Sp.通过对种群的遍历,找到当np=0时,放入未被其余解所支配的集合fro[1]中.再去遍历fro[1]中每个个体q对应Sq集合中的解,将Sq中解的个体数nq减1,遍历完一次进行fro[i+1],其中若有解对应nq值为0,则保存至fro[i+1],并赋予非支配序irank.重复步骤,直至所有解被划分.
2.2.2 拥挤度改进 对于每个点的初始拥挤度设置为0,令边界上的两个个体拥挤度为无穷大.
f[0]distance=f[i-1]distance=∞.
(15)
NSGA2算法仅考虑相邻个体间的距离,但解集的分布度关乎不同子群间的拥挤距离,当解集分布均匀时,个体间遗传机会增加,有利于保持分布度.因此提出考虑标准差的拥挤距离公式,对种群其余个体利用标准差计算:
(16)
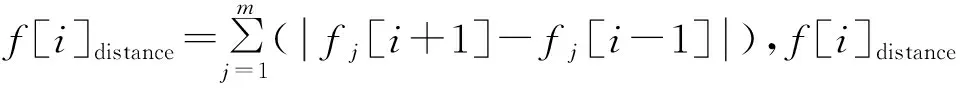
2.2.3 精英策略 传统的精英策略为精英保留策略,在Pareto最优层个体进行大量的交叉变异,而非支配层中的个体数量较少,导致目标偏移产生局部收敛,因此通过对非支配层个体数进行制约来解决Pareto最优层个体数过多所产生的局部收敛问题,具体解决方法如下:
(17)
式中El为第l非支配层个体数,γ∈[0,1]为衰减率,σ为迭代次数.
2.2.4 随机排序选择 BD-NSGA2算法根据快速非支配排序以及拥挤度的计算,对种群中个体含有非支配序irank和拥挤度f[i]Distance进行排序,从而选择种群中个体数.通过随机选择,设每次迭代时种群中个体的数量为固定N,每次从中选出最优解,如Rank0的解,同时满足:
(18)
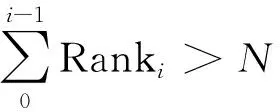
2.2.5 交叉改进 NSGA2算法是采用模拟的二进制交叉方式(simulated binary crossover,SBX)交叉产生新个体,这种交叉方式无法保证种群的多样性计算以及全局性搜索,通过算数交叉算子进行交叉换位产生新个体.进入交叉操作时,随机从父种群中选择两个父本进行位置信息的交换来产生子代个体,对第k+1代个体的位置计算为
(19)
式中Qc1,k+1和Qc2,k+1为父本交叉生成的第k+1代个体的位置信息;Qc,k为当前位置;Qbest,k为当前最优位置;μ1∈[0,1],μ2∈[0,1]且μ1+μ2=1.
2.2.6 多项式变异 变异操作基于自然界染色体变异产生新个体,本文的变异为多项式变异,从父种群中选择一个父本Pk产生第k+1代个体的计算为
(20)
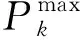
(21)
式中ϑ∈[0,1],ηm为变异分布指数.
2.3 BD-NSGA2算法流程及算法复杂度分析
BD-NSGA2算法在解决大象流链路拥塞调度中,采用KSP算法进行初始化路由,根据式(8)进行链路拥塞判断,当链路发生拥塞时,根据式(9)(10)作为多目标评价指标模型,同时应满足式(11)~(14)的约束条件,再根据2.2节的内容进行路由部署,得到最优路径.BD-NSGA2算法流程如表2所示.

表2 BD-NSGA2算法Tab.2 BD-NSGA2 algorithm
BD-NSGA2算法首先通过步骤1的KSP算法计算k条初始路由路径,算法的时间复杂度为O(kN2),由于k路径数远小于拓扑图的节点数,因此可认为KSP初始化算法的时间复杂度为O(N2);步骤2的时间复杂度主要与链路个数e与种群规模N有关,非支配排序的时间复杂度为O(N2),拥挤度的时间复杂度为O(eNlogN);步骤3的时间复杂度取决于迭代次数σ与种群规模N,精英策略的时间复杂度为O(σNlogN).因此BD-NSGA2算法的最大时间复杂度为O(N2).BD-NSGA2算法经过有限次迭代后收敛,具有实时性与有效性.
3 仿真实验
3.1 实验平台
采用仿真平台为Mininet,控制器的选择为Ryu 4.34,编程语言为Python 2.7.实验机器配置为Intel(R) Core(TM) i7-10710U CPU @1.10 GHz,16.0 GB RAM,操作系统为Ubuntu16.0.4-desktop-64 4.0 GB.实验拓扑采用如图3所示的胖树(k=4)数据中心网络拓扑,该拓扑共有4个Pod,任意两个Pod之间存在4条路径.
3.2 参数设置
实验中KSP算法设置初始路径为13条,网络性能测试时长为60 s,数据流的发送速率以10 Mbit/s为步长,Ryu控制器的监督时间设置为5 s,拓扑发现周期设置为2 s,链路时延监测周期设置为2 s,网络拥塞状态设置为链路容量的70%,链路带宽设置为100 Mbit/s.BD-NSGA2算法参数配置:种群个数N为70,迭代次数σ为30,突变率mr为10%,交叉率cr为100%.利用iperf产生数据流模拟大象流,利用ping产生数据流来模拟老鼠流,其虚拟主机间通信模式为如下两种方式.
1) 随机方式(Random).主机之间以等概率进行随机通信.
2) 交错方式(Staggered(pEdge,pPod)).在网络中,pEdge为同一Pod内相同子网的流量占比,pPod为不同子网间的流量占比,对于不同Pod内的流量占比为1-pEdge-pPod.
3.3 结果分析
实验中,通过平均吞吐量、平均丢包率、链路利用率评估指标对网络性能以及服务质量进行评估.为了确保实验的真实性以及准确性,本文在不同模式下进行仿真实验20次,取20次实验结果的平均值为最终实验结果.
3.3.1 平均吞吐量比较 在流发送速率下,BD-NSGA2算法与ECMP算法[8]、GFF算法[10]、RPC算法[9]、DSFlows算法[21]、NSGA2算法[22]的平均吞吐量比较如图4所示.当流发送速率在10~20 Mbit/s时,由于发送速率较小,网络能容纳这些数据流,几种算法的平均吞吐量接近相等.当数据流不断增长时,网络吞吐量缓慢上升,ECMP算法易于将多条流转发到同一条路径上,导致链路拥塞,因此吞吐量最低.GFF算法由于其低网络地址易于划分,导致留下很多难以利用的小空间,因此GFF算法的平均吞吐量相比RPC算法要低.RPC算法根据链路负载和时延作为关键度指标进行重路由,因为大象流对网络中带宽较为敏感,在模型建立中,未考虑网络带宽,会产生一定程度的偏差.DSFlows算法通过对链路带宽状态的考虑,将大象流转发到负载较低的链路中,平均吞吐量比ECMP算法与GFF算法相比明显上升.NSGA2算法由于可能存在局部最优的情况因此吞吐量低于BD-NSG2算法.BD-NSGA2算法在发送速率上升,数据流不断增长时,当链路发生拥塞时,以路径带宽最优以及路径时延多目标评价模型下,同时避免局部最优的产生,更好地将多条大象流向空闲链路进行转发,因此吞吐量高于RPC算法.当流发送速率为40 Mbit/s时,BD-NSGA2算法与ECMP、GFF、RPC、DSFlows、NSGA2算法相比分别增了36.4%、26.9%、6.1%、18.3%、8.8%;当流发送速率为50 Mbit/s时,相比于ECMP、GFF、RPC、DSFlows、NSGA2算法增加了47.0%、37.4%和10.8%、12.5%、8.1%,可以有效地提高吞吐量.
3.3.2 平均丢包率比较 在网络负载下,BD-NSGA2算法与ECMP、GFF、RPC、DSFlows、NSGA2算法的平均丢包率比较如图5所示.在网络负载较低的情况下,链路出现拥塞的可能性较低,在网络负载为0.1~0.2时,几种算法的平均丢包率接近.在网络负载达到0.3时,RPC算法与DSFlows算法在网络负载较小时比BD-NSGA2算法收敛快,因此BD-NSGA2算法在网络负载0.3时比RPC算法与DSFlows算法平均丢包率多.但随着网络负载的增加,BD-NSGA2算法会避免快速收敛产生的局部最优的情况,因此在网络负载达到0.5时,BD-NSGA2算法平均丢包率比ECMP、GFF、RPC、DSFlows、NSGA2算法减少73.8%、64.7%、10.0%、21.7%、30.8%.
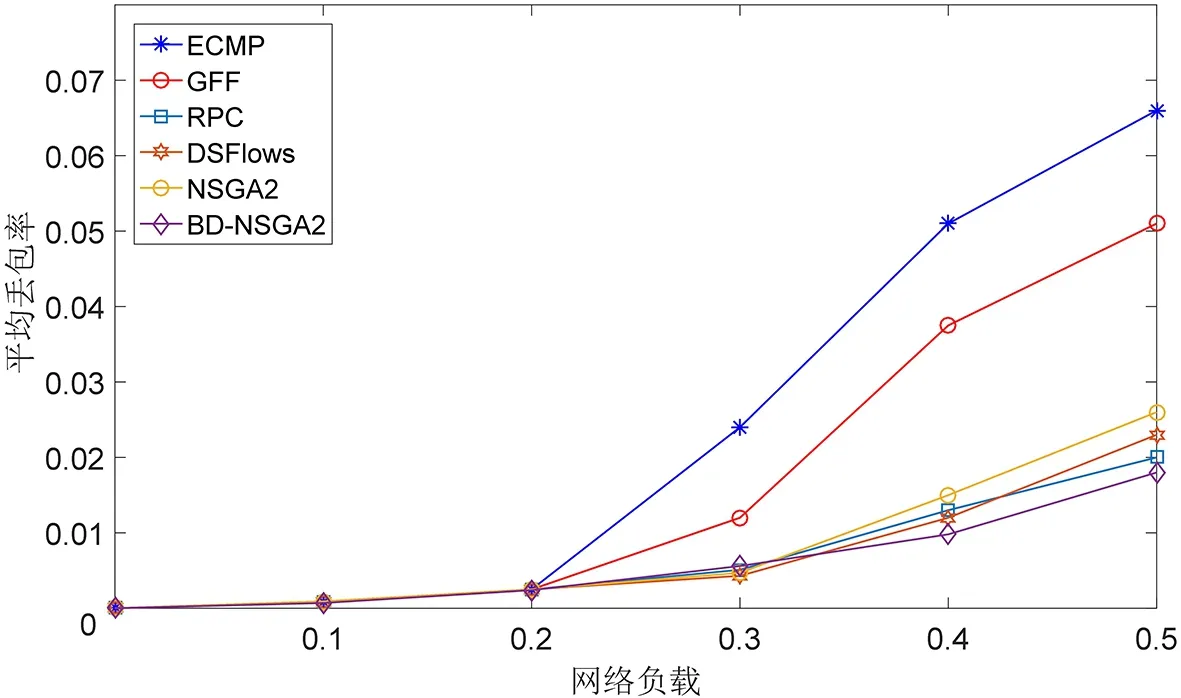
图5 平均丢包率比较Fig.5 Comparison of the average packet loss rate
3.3.3 平均时延抖动比较 在网络负载下,BD-NSGA2算法与ECMP、GFF、RPC、DSFlows、NSGA2算法的平均时延抖动比较如图6所示.在网络负载在0.1时,Ryu控制器在与OpenFlow交换机间进行信息交互,包括控制器中的路由调度算法的计算转发以及流表的安装,导致时延明显上升.随着网络负载的增加,链路带宽的资源更加紧张,因此在链路负载达0.3以后的时延抖动缓慢上升.在网络负载为0.5时,BD-NSGA2算法平均时延抖动比ECMP、GFF、RPC、DSFlows算法与NSGA2算法减少35.9%、22.6%、6.8%、8.9%、14.6%.

图6 平均时延抖动比较Fig.6 Comparison of the average delay variation
3.3.4 链路利用率比较 在不同通信模式下,BD-NSGA2算法与ECMP、GFF、DTSNL[20]、NSGA2算法的链路利用率比较如图7所示.在Random、Stag(0.1,0.2)、Stag(0.2,0.3) 3种通信模式下,由于网络中主机在不同Pod内通信概率较大,存在的流量较多导致链路使用数量增加,因此5种算法的链路利用率都较高.在Stag(0.5,0.3)通信模式下,流量在Pod间通信,链路使用数量减少,链路利用率低于Random、Stag(0.1,0.2)、Stag(0.2,0.3)通信模式下的链路利用率.本文在对大象流进行链路拥塞流量调度中,通过BD-NSGA2算法进行流量调度,在Pod间以及Pod内流进行优化,提高其链路利用率.在Random通信模式下,BD-NSGA2算法的链路利用率比ECMP、GFF算法与NSGA2算法相比增加26.4%、3.4%、3.4%,与DTSNL算法持平;在Stag(0.5,0.3)模式下,BD-NSGA2算法的链路利用率比ECMP、GFF、DTSNL、NSGA2算法增加13.6%、8.1%、6.3%、9.8%.

图7 链路利用率比较Fig.7 Comparison of the link utilization
4 结语
研究了DCN中大象流在链路拥塞问题下的调度问题,在SDN架构下大象流调度的BD-NSGA2算法,该算法在对大象流进行流量调度时,能有效地将大象流调度到空闲链路中,避免链路拥塞的情况发生,提高网络质量.通过对比实验表明,该算法可以更好地提高链路利用率和网络吞吐量、降低在传输过程中的丢包率和时延抖动.通过仿真实验进行测试,选取的拓扑网络也是具有规则的数据中心拓扑,因此在真实环境中以及其他规格拓扑中有待进一步探索与研究.
猜你喜欢
火力与指挥控制(2022年8期)2022-09-16
移动通信(2021年5期)2021-10-25
电脑知识与技术(2021年22期)2021-09-14
铁道通信信号(2020年8期)2020-02-06
电子制作(2019年20期)2019-12-04
网络安全和信息化(2019年11期)2019-11-25
花火B(2019年3期)2019-04-27
电子制作(2019年23期)2019-02-23
科技与创新(2018年1期)2018-12-23
宇航计测技术(2018年3期)2018-09-08
