
平稳随机信号的可预测性分析与熵值估计
2022-08-04 05:10陈斌
中国煤炭地质 2022年7期
陈 斌
(河南省煤炭地质勘察研究总院,郑州 450052)
0 引言
在自回归模型中,平稳随机信号中的任意点xn可由此前的M点xn-1,xn-2,…,xn-M通过线性组合的方式所预测,其参数化模型通常被写为
(1)

(2)
此时的外部噪声sn与模型的组合输出之间必然相互正交,模型的自回归系数可由最小均方差法求得,即要求其预测误差同时也是所引入的外部噪声的均方差为最小:
(3)
对(3)式中的各项ak系数求其导数,并令其值为零,整理后即可得到Yule-Walker(YW)方程:
(4)
矩阵中的r(k)=E{xn-kxn},为信号在k点处的自相关系数。另外在(1)式两边乘以xn-k并求其数学期望,也可得到同样的结果。该方法最早由Yule与Walker等人所提出,线性自回归模型与YW方程以及它的多种变化形式已经被广泛应用于多个学科及工程领域,在数字信号处理领域,它主要被应用于对信号短序列的谱估计研究[1-2]。而由于(2)式Toeplitz矩阵中的信号自相关系数来自于对信号截断序列的估计值,对其直接计算将会导致出现严重的不稳定现象。从1967年开始,Burg,Edward,Bos等陆续提出了对随机信号的最大熵谱估计方法,并说明了它和YW方程之间的一致性关系[3-5],国内最早也可见何樵登、王宏禹等人对此方面工作介绍,该方法首先假设随机信号在高斯分布条件下具有Shannon信息形式的最大熵熵值分布,以此作为约束条件,并将其转换为要求对YW方程中的正向与反向预测误差之和为最小,这样就可不必直接求解YW方程,也能逐阶对模型的自回归系数进行递推求解,从而可以获得更高分辨率的信号功率谱分布[6-7],其具体计算方法可见Stoica与张贤达等人的相关专著[8-9]。
(1)式模型从外部引入谱白化的随机噪声sn以追踪随机信号序列随时间的不确定变化,同时也将此谱白化噪声作为自回归有理参数模型的扰动激励。但若对此模型重复输入相同的扰动激励,将会得到同样的预测输出,可知它所表述的仍然是一个确定性的线性时不变系统。但信号的随机特性决定了它必然具有时变性质,虽然其统计特性可以保持稳态不变,但其具体数值却不可能被先验确定,即便在相同的激励条件下其信号输出也不应重复一致。而随机信号这种随时间变化的不确定关系,决定了不可能对信号进行完全的精确估计,在其预测过程中都将不可避免地会产生预测误差或偏差,这种预测误差或偏差既无法避免也无法消除。因此,自回归模型只能是对随机信号时间序列数据进行某种拟合,其目标应当是使所期望预测到的目标信号在预测输出中的比例或权重达到最大,而非实现完全的精确预测。为此本文通过对模型中的信号空间关系的分析,对随机信号的可预测性即它在何种程度上能被准确预测进行了分析,并提出了相关约束条件,由此建立了随机信号的可预测性与信号分布特征间的计算公式,同时也对信号的不可预测性即不确定性与其熵值特性进行了相应的讨论。
1 空间上的自回归模型


图1 随机信号组合输出向量与其预测目标向量的空间关系Figure 1 Spatial relationship between combined output vector andpredicted vector from random signal
(5)

=∑akE{xnxn-k}=∑akr(k)
(6)
(7)
此时k=1,…M,且有
(8)
即与(2)式中的假设条件相互一致,此时的预测输出有
(9)

这里可以用一个简单实例对上面的分析过程进行说明,若在(1)式中令M=1,即仅用一个以往数据来预测当前值,在k=1时,其最小均方差解为
(10)
这里的w=r(1)/r(0),但此时直接以xn-1作为xn的预测值则更为合理,即
(11)
即相当于剔除(10)式中从外部引入的多余噪声项sn后,再取w=1,将式中两边的输入输出功率调整一致后的结果。
2 预测模型的谱白化滤波因子

(12)
而对于所预期的目标信号有
(13)
(14)
其中w∈[0,1],为目标信号在组合输出中的可预测权重比例,在将全部组合输出作为其预测输出时,它反映了自回归模型所能预测到的目标信号的最大比例,同时它也等于输入输出信号在时差为零时的互相关系数,也就是组合输出与目标信号向量间夹角的余弦值,这时的目标信号与组合输出之间最为接近,两者间具有最大的相似程度。

(15)
若单独以xn-k作为xn的估计值,并如上式将估计值分为期望输出的目标信号部分与剩余偏差两部分,则有
xn-k=r(k)xn+ek
(16)
此时目标信号xn在预测输出xn-k中的权重比例为r(k),提取其中所有的目标信号成分之后的剩余偏差为ek,则必然有
E{xnek}=0
(17)
即此时的xn与ek两序列之间相互正交。分别取k=1,…,M,对各点以相应的自回归系数ak加权后的线性组合输出即构成了取消引入外部噪声后的自回归预测结果:
=∑akr(k)xn+∑akek=wxn+en
(18)
整理后的组合输出yn同样可分为部分权重的目标信号wxn与剩余偏差en两部分,两者间仍然相互正交,其中剩余偏差与目标信号序列间的正交关系通常只是在相互对齐时才严格成立:
E{xnen}=∑akE{xnek}=0
(19)
E{enen}=1-w2
(20)
其中的组合输出信号与目标信号均已进行归一化处理,另外,这里无需对剩余偏差en以及预测误差{yn}-{xn}的状态分布情况给出特别假定。另记以下列矩阵对应的转置行矩阵分别为
(21)
(22)
由随机信号自相关的数学定义,xn序列M+1维的自相关矩阵有
R(M+1)=E{X(M+1)X(M+1)T}

(23)
略去各式中的矩阵维数,对目标信号与模型组合输出之间的差值即模型的预测误差有
=(1-w)xn-en=Hxn-en
(24)

E{(xn-yn)2}=E{ATXXTA}=ATRA
=E{(1-w)2xn2+en2}=2H
(25)

由于组合输出可以看成是将现时信号输入到预测模型之中,经过不同时间延迟后的多点加权组合的再次输出,因此可将信号序列xn本身视为预测模型的输入,经过模型加权组合后的响应作为其预测输出,即
(26)
其中的δ(k)为单位脉冲函数,即自回归模型可以看成是一个随机信号通过延迟加权组合方法预测自身的滤波过程,而模型的自回归系数就是此系统响应过程的滤波因子,即它是对随机信号自身在时间域不断延续的过程的追踪与拟合,这必然要求其输出的预测结果与平稳随机信号的现时值之间尽量保持一致,而这两种情况下都必须要求在时间延续过程中的状态保持平稳不变,其中除要求信号输入输出前后的一阶矩与二阶矩均应保持不变之外,也必须使自回归预测输出的信号功率谱应与原输入信号的功率谱保持一致,这也是对随机信号保持自身状态平稳性的要求,否则就会导致预测输出信号的失真与畸变,即这些约束条件是建立预测模型时所必需具备的先决条件。
由于模型组合中的自回归系数分布情况决定了预测输出中有效信号部分的权重比例大小,但同时还要求保持模型中的信号输出状态的稳定不变,考虑到自回归过程也可被视为输入信号通过预测模型后的滤波响应,模型的自回归系数即为此线性时不变滤波器的滤波因子。不难发现自回归系数当且仅当为谱白化的形式,才能使得预测输出信号的功率谱分布仍与原输入信号仍然保持一致,这样即可维持输入输出前后信号的状态参数的平稳不变。
由于信号在通过谱白化滤波器时,输入输出间仅作相位的改变,即对模型的自回归系数有
(27)
这里的δi,j为Kronecker delta函数,它在频率域上的振幅谱值恒定为1。
若令Pm为输入及输出信号在各频点上的功率谱,θm为两者间的相位差值,且有
∑mPm=1
(28)
∑mcos2θm=∑kak2=1
(29)
由(14)式,预测模型的可预测权重比有
w=∑akr(k)=E{xnyn}=∑mPmcos2θm
(30)
若将随机信号在频率域内进行分解,由于不同频点处信号分量间的相互正交性,(30)式中各分量乘积间的数学期望即等于0,这样在其输出中只需计算输入输出信号在各个同频分量乘积间的数学期望,即它相当于将预测模型分解为频率域中各个相互独立的单频点分量模型后再分别进行预测的结果,且它在各频点上所预测到的有效信号权重比例等于此频点处信号输入输出相位差的余弦平方值,而整个随机信号的可预测权重比则等于各个频点上的可预测权重比与其频点对应的功率谱值乘积的累加。这表明信号中的单个独立分量均只能对自身实现部分的精确预测,而且每个分解后的单频预测模型对其它频点的信号预测并不能起到任何有效作用。
若将信号分解为在其它完备正交基上的投影之和,以上预测方法同样可以适用,各个分量上的预测结果仍然相对独立,但各分量可预测到的有效信号权重比例将会发生相应变化。
由(30)式,对其频率域内的各个频点,当且仅当
Pm=cos2θm
(31)
w值取其极大值,此时
w=∑mwm=∑mPmcos2θm=∑mPm2
(32)
wm为单个频点位置上的信号可预测权重比,信号总的可预测权重比w值的余数H有

=∑mPm(1-Pm)=∑mPm∑n≠mPn
(33)
即自回归模型不可能准确预测到所期望的全部目标信号,其可预测部分的最大权重w值等于信号功率谱密度的平方和,而其余值H=1-w即为对信号不确定性的大小的具体衡量标准。
另外,若强制选择模型的自回归系数为非谱白化的形式,例如令其为单频滤波器时的情况,其预测输出中总的有效信号部分权重比例可以大于输入信号功率谱分布的平方和值,但这样会造成此时预测输出信号的严重失真,因其功率谱分布特征与模型期望输出之间相差过远而失去其意义。
而对于YW方程,所要求的约束条件是使其中的预测误差P值为最小,但所引入的外部噪声不能有效补偿其预测误差时,反而将会增加其预测输出与目标信号间的相对误差。此外,除(2)式中的简化假设条件未必能完全成立之外,方程中也未能体现出对信号输入输出功率谱状态一致性的要求,其结果的稳定性与可靠性都可能存在疑问。
3 Shannon熵编码信号
对于信号的熵值估计,Shannon在其信息理论中提出了3个假设条件:①信号的状态熵值hi是其出现概率pi在[0,1]区间内的连续函数,即它应是一个上凸的光滑连续曲线,且在[0,1]两端的值恒等于0;②在各点pi相等时,信号具有最大的熵值分布,且此时信号总熵值H=∑hi随其状态数的增加而单调增加;③如果选择分为相继的两步,未分步时的信号熵值等于分步选择时熵值的加权和[10]。最后所总结出的信号状态分量的熵值计算函数为
hi=-pilogpi
(34)
在Shannon信息理论中,信号中的所有状态各自都被赋予某个特定的编码,其编码长度与状态的出现概率相对应,信号的总熵值相当于其编码的平均长度,且信号中的各个状态均被视为相互独立,状态之间以及编码之间均不能进行测度意义上的大小比较,相互之间不能替代或部分替代。由于信号状态的编码只是其概率分布情况的反映,而与其中所代表的实际内容并没有直接的关联性,因此可称此类信号为编码(encoding)信号。另外,为保证编码信号中的各个状态都可以获得相应的有效编码,信号状态的总数就必须为有限的数目。而连续分布信号以及无限离散分布信号由于其状态的无限性,都不可能存在相对应的有限字长编码,否则将因其编码长度以及其熵值趋于无穷大值而失去实际意义。
对于编码信号中的任意状态,即便是其出现概率值pi无限接近于0,其熵值hi都必定要大于0,否则将无法为此状态分配一个对应的有限长度编码,这也就必然要求其熵值函数在pi=0点处的导数h′i→∞,即这两者之间是相互等价的关系。如果各状态间的概率调整或变化仅仅只出现其信号内部,此时各状态的出现概率始终有pi>0,因此信号的总熵值仍然保持着连续变化。但在编码信号总的状态数发生改变时,由于必须为新增加或将被消除的状态分配或解除编码,信号的总熵值就会出现跳跃式的而非连续性的变化,这是由于其熵值函数的导数值在pi=0处不能保持连续所致,其实这种变化情况也正是前面信号总熵值应随其概率平均分布时状态个数的增加而单调增加的假设条件所要求的。而且这种熵值的跳变也同时反映了信号各状态间的相互独立与不可替代性,即可以藉此方式以区分不同的信号状态。但是,并非所有类型的信号都具备或者需要这种熵值特性,特别是当信号的小概率状态,当其消失或被其它的状态所替换,而不能或不应当导致信号中信息量的突然或非连续变化,或是其小概率信号状态的本身与其信息变化可被忽略时,这同时也意味着信号状态间的不完全独立与相对的可替代性,对于这种情况Shannon信息理论就并不完全适用。
随机信号是对时间域内连续变化的物理量经数字化处理后产生的信息序列,信号状态的编码是对其物理量的某种量化逼近选择,信号状态之间有着明确且变化不一的空间距离,各相近状态能够互相替代或部分互相替代,而且在时间序列前后的数据状态也并不是相互独立存在。但即便是忽略了在时间域内各个状态之间的相关性,随机信号的遍历性也会导致其状态数存在着无穷变化,这也就意味着无法对它们一一实现相对应的有限字长编码。
因此,为避免时间域内随机信号状态的遍历性以及各点间信号状态的相关性的影响,将信号分解为相对独立的各频点状态分量,以各频点的功率谱值作为其状态分量的出现概率,从频率域的角度分析其熵值特性就显得更为实际与合理。这时整个信号表现为在各频率点对应状态的混合加权叠加以及在时间域上的不断延续,相当于整个随机信号过程是一个在时间域内不断延续的事件(event)。
由于泄露效应,随机信号在任意频点分量的功率谱值都不可能绝对为零,此时采用Shannon熵函数评估每个频点的熵值以及信号的总熵值也将不会直接出现明显的矛盾之处,但实际上随机信号谱密度中的小概率分量大多情况下均可被忽视,而并不是完全独立及无法被替代,这就与前面Shannon信息理论所要求的情况并不一致。
而且信号在其频率域内频点分量的总数发生改变,即它的状态数发生变化时,例如在对信号加密采样或直接改变其延续时长的情况下,继续采用Shannon熵函数所计算出的信号总熵值又将会出现如前面所描述的跳跃式变化,而由于随机信号的时间延续的出现长短变化时其熵值仍应保持相对的稳定,两者之间就会出现明显的不相符合之处,而这实际上仍然是信号在时间域内其状态数的改变转到频率域后再进行熵值计算所带来的同样的问题。
而最根本的问题在于:编码信号的熵值是其状态平均编码长度的反映,但以类似方式应用于随机信号所得到的熵值却不具备相对应的明确物理意义。实际上对这些问题前人早已有所认识,其具体内容可见钟义信等人对此的相关讨论[11],但以往工作着重于对Shannon信息理论在随机信号领域应用方法的修补或重新解释,而并没有考虑到还可以选择其它熵值函数,以满足随机信号的实际要求。
4 随机信号中的预测熵
经过以上讨论,可以认为随机信号的熵值函数在pi=0点处的导数必须为有限值,以适应信号内部不同状态间能够相互替代的实际要求,同时也由于在[0,1)区间内的导数hi′为有限值,因此信号的总熵值H必然存在某个上限,这里不妨假设在完全谱白化分布条件下此上限值为1,即信号的总熵值大小也必然与其状态数无关。若以此条件考虑新的熵值函数将会有多个选择,根据之前对随机信号自回归过程预测误差分析的结果,可以直接引入熵值计算函数为
hm=pm(1-pm)
(35)
它相当于采用自回归模型进行信号预测时,在频率域中单个频点的模型可预测权重比例cos2θm=pm与除此所在频点之外的各频点功率谱累加值之间的乘积,其物理意义在于它是在此频点分量处有效信号不可预测程度大小的衡量标准,因此可称之为随机信号的预测熵(predicting entropy),全部频点处预测熵值的累加就是整个随机信号的总熵值H,同时它也是信号整体可预测权重比w的余值:

=∑mPm(1-Pm)=∑mwm(1-wm)
(36)
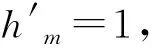
同样,在随机信号的长度发生变化以及信号采样间隔发生改变时,其预测熵值仍将不会出现突变。而且无论是在离散状态下还是在连续状态下信号总的熵值的计算结果是相一致的。
在信号各项分量的出现概率近似相等,即信号为近谱白化分布时,信号的预测熵值趋于最大而接近于1。其自回归模型中的输入输出信号向量夹角α接近直角,其可预测权重比例值w接近于0,此时的输出yn实际已为与输入xn互不相干或正交的白噪信号,信号的总熵值有
H=∑mPm(1-Pm)≅∑1/M(1-1/M)
=1-1/M=(M-1)/M→1
(37)
同理,若随机信号中只存在单个独立分量,例如为单频信号时的情况,这样的信号将能被完全精确预测,可知此时模型空间内的输入输出信号向量夹角α=0,其可预测权重比例值w=1,以及其余值H=0。若信号以某个概率密度接近于1的强振幅分量Pi为主体,并可将其它均以小概率值出现的分量视为干扰波动,此时有
H=∑m≠iPm(1-Pm)+Pi(1-Pi)
≅∑m≠iPm+(1-Pi)=2∑m≠iPm
(38)
即此类信号的熵值约等于其中全部干扰波动分量的功率谱密度和的2倍,且有
E{enen}≅E{(xn-yn)2}=2H
(39)
另外,本文是在付氏变换基上进行的熵值评估,若是采用其它正交变换,估计其可预测权重比将会发生相应改变。而且由于付氏变换的基底为固定值,与信号的实际特征分布无关,因此必然不可能是最佳变换,即不能获得信号的最小熵值估计。从数学意义上只有采用Karhunen-Loeve (KL)变换,最大程度地去除各分量间的相关性时,才能达到使信号分解的最佳效果,这时的熵值函数推测会变为
hm=-(1-Pm)log(1-Pm)
(40)


图2 3种熵值函数曲线的分布形态Figure 2 Distribution form of 3 entropy function curves
另外,对于Burg提出的最大熵假设,除前面所述说明随机信号不存在合理的Shannon熵形式的熵值之外,即使在随机信号为高斯分布或白噪分布时具有对应的Shannon熵形式的最大熵熵值,但信号在非白噪分布情况下也未必为最大熵分布,故在所有情况下均以此前提假设进行模型计算并不能完全符合真实情况。而实际上由于YW模型与Burg最大熵方法均将其预测误差P为最小作为对模型参数计算的约束条件,因此就可不必强求对信号的最大熵假设,直接以(2)式方程中的预测误差P值的大小作为对信号不确定性的度量标准,即视其为随机信号的熵值的替代参数,以进行方程的后续计算。由于此时预测误差P值的大小决定了根据此方法计算所得到的信号分布与模型组合输出之间夹角的大小,这同样也是期望在目标信号与组合输出之间保持最大的相似程度,即期望两者间的夹角为最小,这样它和所计算出的信号熵值H的大小之间存在单调关系,即它与直接将组合输出作为预测输出所要求的期望目标整体上相互一致,但对其中的预测误差分析过程相对复杂且无必要,而直接对两者间的相似性进行分析则更为合理。
5 结论
综上分析认为,随机信号本身的不确定性特征将导致其自回归预测过程中必然会出现误差或偏差,从以往信号中只能部分地预测到现时信号,而随机信号的功率谱分布特征决定了其可预测程度的大小。
自回归模型的全部有用信息只能源于其组合输出部分,故应将其全部保留在预测输出之中,所加入的外部噪声对预测输出没有实质性的帮助而无需存在。
自回归模型与信号谱估计的目标应是在保持模型输入输出信号功率谱稳定不变的条件下,将以往数据中的最大部分转换到预测输出之中,使得此两者间的夹角为最小,即期望得到预测误差与预测熵值为最小的预测输出信号。
自回归模型预测输出中的预测误差或噪声是随机信号不完全可预测性的体现,所对应的可预测权重比例的余值的大小可作为随机信号的预测熵值以评估其不确定性,且无需对其中的信号分布情况进行特定假设。
猜你喜欢
小学生学习指导(中年级)(2021年12期)2021-12-30
空军工程大学学报(2021年2期)2021-05-29
读者·校园版(2020年19期)2020-09-16
汉字汉语研究(2020年2期)2020-08-13
中国新通信(2020年3期)2020-07-06
通信电源技术(2020年2期)2020-02-22
电子制作(2019年22期)2020-01-14
当代陕西(2019年19期)2019-11-23
智族GQ(2019年9期)2019-10-28
疯狂英语·新读写(2018年3期)2018-11-29
