
融合共同评分数量和质量的协同过滤个性化推荐算法
2022-08-05 02:41蔡依芳
软件工程 2022年8期
蔡依芳,艾 均,苏 湛
(上海理工大学光电信息与计算机工程学院,上海 200093)
worldchinacai@126.com;aijun@outlook.com;suzhan@foxmail.com
1 引言(Introduction)
近年来,信息技术与移动网络的飞速发展使得互联网每天都产生海量信息,在网络上畅游的用户在寻求满足自身需求时必然面临过多的选择。大量相似的选择和质量未知的信息增加了用户的困惑,让选择更加困难,这就导致用户不仅没能从海量数据中获取便利,还要花费大量的时间进行目标筛选,这种现象被称为信息过载。
推荐系统是解决信息过载问题的一个有效方案,它通过学习用户历史行为偏好主动预测用户对未评分或反馈的物品潜在的反应,并将那些预测评分较高或偏好正面的物品,通过推荐列表等形式自动化、个性化地推荐给不同用户,从而帮助他们更快速地找到需要或喜欢的物品。这种技术的成功应用有效提升了用户对系统的好感,也可以帮助商家寻找对某物品感兴趣的潜在用户群体,既解决了用户的困扰,又为商家创造了价值。因此,推荐系统目前已被广泛应用于多个领域,例如电子商务平台、在线流媒体网站、电影推荐网站、在线音乐网站或应用、社交网络平台,等等。
本文通过分析推荐算法过程中用户共同评分物品的数量和质量问题,设计用户间的相似性度量方法和对应的协同过滤个性化推荐算法,并通过在真实的电影评分数据集上实验以验证算法的有效性。
2 推荐算法分类(The classification of recommendation algorithms)
2.1 算法分类
个性化推荐算法通常分为三类:基于内容的推荐算法、基于内存和模型的协同过滤算法以及混合推荐算法。
三种算法存在不同的使用限制。(1)基于内容的推荐算法通过分析物品的内容信息(新闻、图书等)预测或形成推荐,但其非常依赖内容信息的数据质量,也非常容易给出那些显而易见的推荐,但推荐的准确性和多样性受限。(2)协同过滤算法只要系统提供用户对物品的评分信息集合就可以工作。其中,基于内存的协同过滤利用相似用户打分的习惯,使用近邻算法筛选邻居并预测未知评分;基于模型的协同过滤,例如贝叶斯分类器、模糊算法和矩阵分解模型,使用历史评分数据训练不同的模型用于推荐或预测。(3)混合推荐算法则融合不同类型的算法,试图结合它们各自的优点进行推荐,但其计算复杂性更高,推荐结果可解释性较差。
2.2 经典算法及其问题
在各类算法中最知名的是协同过滤算法,它的出现标志个性化推荐系统的诞生。作为当今应用最为广泛的推荐算法,协同过滤算法较其他算法复杂度更低,可解释强,部署方便,可以有效缓解信息过载问题。
所有协同过滤算法的目标都是尽可能地减小预测误差,提高推荐列表多样性,增强推荐列表的排序质量。但是,受到冷启动和稀疏性这两个推荐系统固有问题的影响,传统的基于用户或基于物品的协同过滤相似性计算方法(例如,Cosine相似性和Pearson相似性)总是因冷启动问题使新用户没有邻居参考,或因稀疏性问题导致评分数据不足,选择的邻居不准确,预测结果不理想。对于这些问题,许多研究人员提出了相应的改进方法,例如,NIKOLAOS等人将Pearson相似性值进行分级处理以增加相似性高邻居的权值;HE等人利用观点传播的理论,通过归一化之后的评分来计算推荐系统用户之间的相互影响,并以此为依据进行预测;基于信息熵的协同过滤将熵的概念与传统的相似性度量相结合以提高推荐系统的性能,等等。
这些方法在一定程度上确实提高了预测的准确性,但是,仅考虑用户共同评分数值差异是不全面的,也应同时考虑利用用户之间共同评分物品集合中物品的数量。因为即便两个用户对相同物品评分差异较大,但只要这两个用户具有一个较大的共同评过分的物品集合,就可以推测这两个用户间的相似性较高。
更进一步来说,还应该考虑这个共同评分物品集合的质量,以区分共同评分物品集合大致相等时,集合中不同物品特征对用户相似性的影响。如果用户的共同评分集合中热门物品较多,其相似性应低于共同评分集合中以冷门物品为主的用户,因为那些喜欢小众物品的用户之间显然更具有偏好上的相似性。
综上所述,本文研究共同评分在总评分数中占比的问题和用户共同评分物品中热门物品的影响度量问题。设计融合共同评分数量和质量的相似性度量,以及在此基础上的个性化推荐算法,以实现提高推荐系统性能的目标。
3 算法设计(Algorithm design)
3.1 基于共同评分数值度量用户相似性
协同过滤推荐的核心假设是相似的用户具有相似的偏好,在此基础上,可以选择相似性较高的邻居,利用这些邻居对目标物品的评分来预测目标用户对该物品的评分。在这类算法中,计算用户间的相似性是算法学习过程的核心步骤。两个用户相似性越大,该邻居用户在推荐的过程中的影响就越大。一般来说,计算用户相似性的主要依据就是两个用户对同一集合中物品评分的差异。理论上,评分数值差异越小,两个用户的偏好和品味就越相似;反之,数值差异越大,偏好差异也就越大。
本文采用Pearson相关系数来度量两个用户间基于共同评分物品集合的评分数值,以度量相似性的一部分权重。Pearson相关系数是统计学上求两个变量关系的方法,可以用来度量两个用户对相同物品集合的评分差异。具体说来,Pearson相关系数对用户评分的偏差进行加权平均,结果作为用户或物品的相似性,且其取值范围为-1.0至1.0,计算公式如式(1)所示:

3.2 融合共同评分集合数量和质量的相似性度量
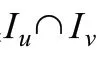
共同评分集合元素数量多的用户间相似性应该大于共同评分数量少的用户,但如果两个用户是共同评分物品集合中物品较为热门的情况,则他们的相似性应低于相似条件下物品集合中物品较为冷门的情况。本文采用杰卡德相似性来度量两个用户因共同评分物品集合元素数量而决定的相似性权重。
Jaccard系数公式如式(2)所示,它计算了用户和用户都评过分的物品个数与两个用户评过分的物品总个数之比。该值越大,说明这两个用户之间共同评过分的物品集合与两人评过分物品的总数之间的比例越高,说明在不考虑评分数值的情况下,这两个用户对物品的选择是相似的。
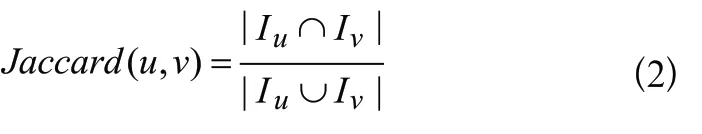
为了进一步度量用户共同评分物品集合中热门物品的特征,即用户共同评分集合的质量,本文设计了如式(3)所示的(,)系数以降低含有热门物品的共同评分集合的权重。其中,共同评分物品集合中每个物品被训练集中所有用户选择的次数记为物品度值d,给定共同评分物品集合中热门物品特征,由该集合所有物品d的最大值表示。基于式(3),如果两个用户共同评分物品集合中存在一个非常流行,即度值很高的物品,则这两个用户之间的共同评分物品集合的质量就相对较低,其权值在相似性计算过程中被降低。
在此基础上,融合共同评分集合数量和质量的相似性由式(4)度量,称该系数为共同评分数量和质量系数(Common Rating Quantity and Quality,CRQQ)。
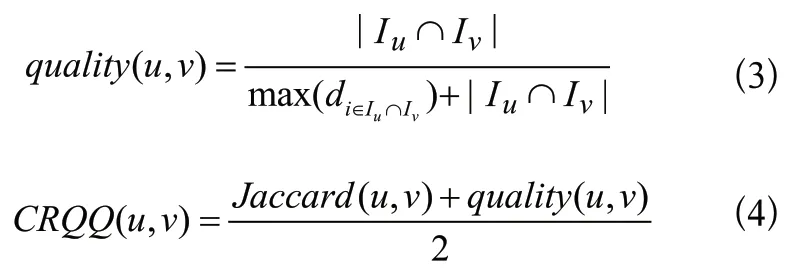
最终,本文设计的综合考虑共同评分物品数值差异与集合数量和质量的相似性计算公式如式(5)所示,即两个用户间评分差异小,并且共同评分物品集合数量和质量均较高时,两个用户最相似。如共同评分物品数量、共同评分物品质量或共同评分数值差异三者当中只有一项到两项较高时,其权重被降低,以便更加准确地度量不同用户间的特征差异。
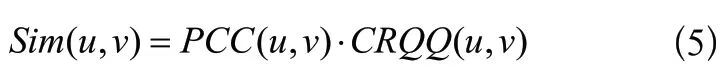
3.3 未知评分预测方法
基于相似性计算结果,以及按照相似性从高到低选择的个邻居,本文使用式(6)把邻居用户对预测目标物品的评分和该邻居平均评分的差值做加权计算,基于该邻居和目标用户相似性,来实现预测用户对未知物品的评分。

4 实验设计(Experimental design)
4.1 数据集与基准算法
本文使用MovieLens数据集进行对比实验,该数据集有610 个用户对9,742 部电影的100,836 条评分信息。为了保证实验的有效性,实验采用折十交叉验证进行,即数据集被分成10 份,每次实验取其中一份作为测试集,另外9 份作为训练集,共进行10 次实验,最终取10 次结果的平均值作为最终实验结果进行比较。
为了验证本文设计的CRQQ算法,用来对比的基准算法有三个,分别是:多层级协同过滤(Multi-Level Collaborative Filtering,MLCF)、用户观点传播算法(User Opinion Spreading,UOS)以及使用了信息熵的Pearson算法(Pearson Entropy)。
4.2 评价指标
本文使用平均绝对误差(Mean Absolute Error,MAE)、均方根误差(Root Mean Squared Error,RMSE)衡量算法对未知评分的预测误差,使用半衰期(Half Life Utility,HLU)度量推荐列表排序质量,采用Accuracy和F1比较各个算法对用户偏好分类的预测准确率。
MAE和RMSE公式如式(7)和式(8)所示,其计算由算法预测值和真实值的差值加权构成,因此两个误差度量参数均为越低越好。
HLU代表算法的排序能力,算法将用户喜欢的物品排在前面的能力越好,HLU值越大,其计算方法如式(9)所示:

Accuracy和F1指标是推荐系统分类预测指标,这两个指标的计算公式如式(10)—式(13)所示:

其中,在一次预测中,代表算法推荐了用户喜欢的物品的总体数量,代表算法推荐了用户不喜欢的物品的总体数量,代表系统未推荐用户喜欢的物品的总体数量,代表系统未推荐用户不喜欢的物品的总体数量。这几个参数的数值越高,算法对用户偏好分类(喜欢或不喜欢)的预测就越准确。
5 实验结果与分析(Experimental results and analysis)
图1展示了四种算法随邻居数变化的MAE误差结果。邻居数为1时,CRQQ算法比Pearson Entropy算法误差低6.68%。随着邻居数的增加,所有算法误差都随之降低,但是CRQQ算法总是能在最少的邻居数下最先达到最小误差值,其次是UOS、Pearson Entropy、MLCF,最终CRQQ算法将准确率提高了0.57%—6.68%。结果表明,本文设计的算法能够更快速地选取最合适的邻居,从而得到最精准的预测结果。
图1 几种算法的MAE结果对比Fig.1 Comparison of MAE results of different algorithms
图2展示了四种算法的RMSE误差对比。RMSE对大误差加大了惩罚,此时,CRQQ算法的误差依旧是所有算法中最低的,这代表CRQQ算法预测结果很少出现大误差,结果最准确。随着邻居数增加,CRQQ算法误差结果迅速下降,优势更加明显,分别比Pearson Entropy误差降低了0.48%—8.41%,比UOS误差降低了1.40%—3.24%,比MLCF误差降低了0.92%—3.23%。由此可知,CRQQ算法无论是大误差还是小误差都比其他算法少,进一步说明本文在预测准确性上的改善能力。
图2 不同算法的RMSE结果对比Fig.2 Comparison of RMSE results of different algorithms
图3是四种算法的HLU排序能力指标,值越大说明算法排序能力越好。总体来说,所有算法的HLU得分前期增长明显,后期略微下降。但不变的是,CRQQ得分一直是第一,它在邻居数为26时取值最大为1.02。相同邻居数下,UOS值为0.99,Pearson Entropy和MLCF算法为0.96,差别不大,但MLCF后期得分比Pearson Entropy算法更加平稳。CRQQ算法在排序能力上比其他算法提高了0.63%—10.21%,这说明共同评分数量和质量在推荐算法排序能力上的优势也比其他算法大。
图3 不同算法的HLU结果对比Fig.3 Comparison of HLU results of different algorithms
图4是算法的Accuracy得分对比。Accuracy代表算法预测用户喜欢与否正确的概率,可以判断系统分类是否有效。CRQQ算法得分稳定在0.704上下,排名第一;Pearson Entropy得分在0.703上下,排名第二;第三、第四分别是MLCF(0.700)和UOS(0.699)。CRQQ比其他算法高了0.14%—0.71%,代表本文算法在对用户喜欢和不喜欢某物品的分类上准确度最高。
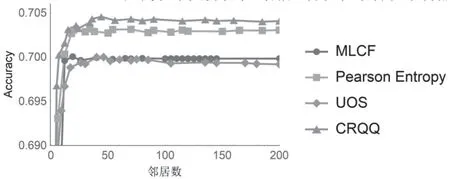
图4 不同算法的Accuracy结果对比Fig.4 Comparison of Accuracy results of different algorithms
F1代表Precision和Recall的综合得分,得分越高,说明模型或算法的效果越理想。从图5中可以看到,CRQQ算法从邻居数为1时就具有领先的优势,UOS第二,Pearson Entropy第三,MLCF最差。在邻居数为0至50之间,CRQQ算法总是能够取得最高的F1得分。此时,CRQQ算法比其他算法高出了0.24%—1.05%。由此可见,使用共同评分数量和质量校正的算法分类精度效果更好。
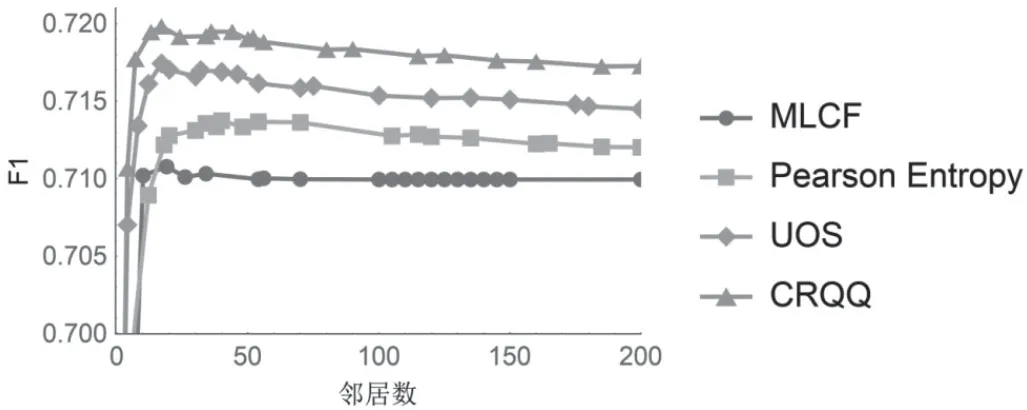
图5 不同算法的F1结果对比Fig.5 Comparison of F1 results of different algorithms
以上分析了四种算法的整体表现,表1则记录了在相同邻居数下,CRQQ算法与其他算法在各指标的对比中提升的最高百分比。
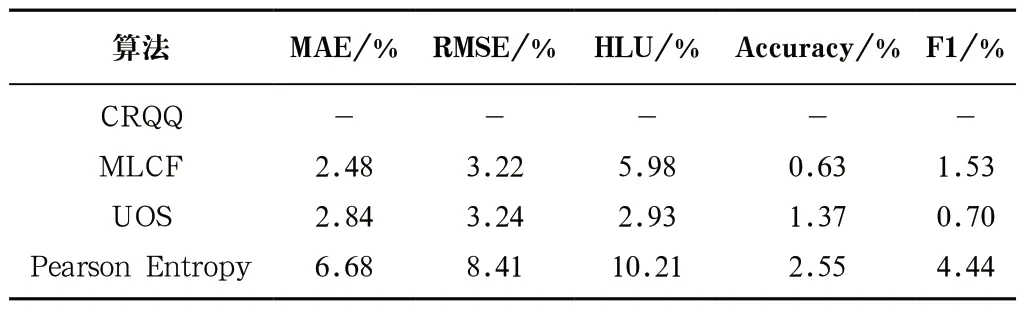
表1 最高提升百分比Tab.1 Best improvement percentage
由表1可知,本文算法在五种指标上分别高出MLCF算法0.63%—5.98%,高出UOS算法0.70%—3.24%,高出Pearson Entropy算法4.44%—10.21%。
总体而言,本文设计的算法CRQQ综合表现领先,Pearson Entropy算法次之,UOS算法第三,多层级协同过滤算法MLCF第四。但当考虑算法在相同的、且较少邻居数下的对比效果时,Pearson Entropy算法表现较差,因其达到最优预测效果,在相同条件下需要更多的邻居。值得注意的是,CRQQ算法不但各个指标领先,且需要的邻居数量也最少,体现出一定的性能优越性。
6 结论(Conclusion)
为提高协同过滤个性化推荐算法的预测准确性,提升推荐列表排序质量,增强算法对偏好分类的准确性,本文研究了两个用户间共同评分物品集合的数量和质量对用户相似性度量的影响,设计了融合共同评分数量和质量的相似性度量方法和对应的协同过滤个性化推荐算法。并在MovieLens电影评分数据集上与领域内几个典型协同过滤算法对比,研究发现本文设计的融合用户共同评分数量和质量的协同过滤个性化推荐算法可以将预测误差降低8.41%,将推荐列表排序性能提高10.21%,将偏好分类预测准确率提高2.55%。实验证明,改良后的算法无论是预测准确性还是分类或排序能力都有较大的提升,充分说明共同评分物品对推荐算法评分预测的影响。在未来的工作中,可以继续挖掘用户公共评分的其他影响,进一步提高算法性能。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
上海文化(文化研究)(2022年3期)2022-06-28
小学生学习指导(低年级)(2022年5期)2022-05-31
数学年刊A辑(中文版)(2022年4期)2022-02-16
疯狂英语·初中天地(2021年11期)2021-02-16
河北画报(2020年8期)2020-10-27
数学年刊A辑(中文版)(2019年3期)2019-10-08
少年漫画(艺术创想)(2019年2期)2019-06-06
浙江大学学报(工学版)(2016年2期)2016-06-05
中国学术期刊文摘(2016年1期)2016-02-13
