
国内追踪数据分析方法研究与模型发展*
2022-08-09 11:05都弘彦温忠麟
心理科学进展 2022年8期
刘 源 都弘彦 方 杰 温忠麟
国内追踪数据分析方法研究与模型发展*
刘 源1,2都弘彦1方 杰3温忠麟4
(1西南大学心理学部;2认知与人格教育部重点实验室, 重庆 400715) (3广东财经大学新发展研究院/应用心理学系, 广州 510320) (4华南师范大学心理学院/心理应用研究中心, 广州 510631)
追踪研究因其可以得到比横断研究更有说服力的变量关系论证, 在心理学等科学中具有重要地位。梳理国内以心理学为主的相关领域中追踪数据分析方法研究的发表现状、主要解决的研究问题和模型发展。追踪研究可以进行均值差异比较、分析多变量相互影响、描述总体发展趋势及差异和探究心理动态变化过程。近20年的研究热点和发展思路也集中在上述研究问题当中, 特别是总体发展趋势及差异、多变量相互影响、总体发展趋势与多变量相互影响的融合、追踪研究设计、缺失数据等议题上。最后, 比较国内外研究的差异, 并结合交叉学科对国内追踪研究未来发展做出展望。
追踪研究, 相互影响, 增长趋势, 动态变化
追踪研究(longitudinal study), 因其对同一个或同一批被试重复的观测, 可以得到比横断研究(cross-sectional study)更有说服力的变量关系论证,在心理学、教育学、管理学等社会科学中具有重要地位。新世纪以来, 随着统计方法的发展, 运用结构方程模型、多水平模型、时间序列分析等技术分析追踪数据, 能关注更多的信息, 比如发展趋势及个体差异、影响个体差异的各水平的因素等。追踪数据的研究越来越细化, 所关注的问题也越来越深入。
首先, 检索了新世纪以来国内以心理学为主的相关领域的追踪研究方法文章, 概述了发文现状。然后根据这些发文内容, 总结了追踪研究的一般研究问题及其方法。在此基础上, 梳理了国内追踪研究目前的研究热点和发展思路。最后, 对比国外前沿的追踪研究, 提出了建议和发展方向。
1 国内追踪数据分析方法研究现状概述
进入中国知网(https://www.cnki.net/)进行专业检索。文献分类目录选择社会科学中所有跟个体相关的研究领域: 哲学与人文科学当中的心理学、社会科学II辑全部、经济与管理科学全部; 自然科学中的跟生物医药相关领域: 基础科学−生物、医药卫生科技全部; 发表时间为2001年1月1日至2020年12月31日; 仅包含来自“学术期刊”的文章; 关键词包括追踪、纵向、纵贯、交叉滞后、潜变量增长、密集、时变、潜转移、潜在转移、混合增长、多层、多层线性、多水平、多阶段、自回归、经验取样、EMA、经验采样、因果、潜在转变。特别地, 时间序列分析虽然也属于追踪研究范式, 但是其主要涉及随机过程, 不在本文的关注重点中。通过限定词排除了与个体发展不相关的文献, 并根据篇名、摘要进一步排除实证研究类的文章, 得到符合要求的文章75篇。
国内发文现状在新世纪前10年快速增长(表1)。对照一下, 2000年以前发表的符合检索要求的只有1篇, 对追踪研究范式提出了建议, 但不涉及统计方法。对比不同学科, 心理学的相关研究最多, 其次是医学/药学。
从研究主题关键词来看, 潜增长模型最多(包括混合增长模型, 17.3%), 然后依次是经验取样(13.3%)、领域评述(13.3%)、多水平模型(12.0%)、缺失数据(10.7%)、因果模型(9.3%)、面板数据(5.3%)、自回归(5.3%), 剩余其他内容占13.1%。从学科领域来看, 心理学论文多涉及潜增长模型及其拓展模型(25.9%)、经验取样(18.5%), 除此之外还有学科领域的综述, 涉及到诸多模型(14.8%);管理学更关注经验取样(57.1%); 医学更关注多水平模型和缺失数据(各22.2%)。可见每个学科都有其“惯用”的研究方法。

表1 近20年不同领域发文数一览
注: 综合性科学包括综合科技、综合社科。文章所属学科先后按期刊检索来源(CSSCI、北大核心)学科以及文献被知网收录所属专题(非核心期刊)进行划分。
2 追踪数据设计的一般研究问题及其常用方法
根据近20年发文的内容、方法的发展以及前人研究的总结(刘红云, 孟庆茂, 2003; 唐文清等, 2020), 可将追踪研究解决的科学问题分为4类: (1)均值差异比较, (2)多变量相互影响(reciprocal relations, 或往复式影响), (3)总体发展趋势及差异, 以及(4)动态变化过程。
2.1 均值差异比较
均值差异比较的追踪设计可以少到2次测量, 只要对同一批被试进行重复测量, 传统的配对样本检验或重复测量方差分析就能解决。由于重复测量方差分析所给的主效应为多次测量的均值, 故若第一次测量为初始状态(并非干预后的效果)时, 此时的均值并非效应均值。可考虑排除第一次测量或采用协方差分析(将第一次测量作为协变量), 或将实验处理作为组间自变量进行混合设计方差分析(郑卫军, 何凡, 2020)。这些方法无法对违背方差假设(如球形假设)的数据进行分析, 也不能解决数据偏态、缺失值、等级数据等问题。
2.2 多变量相互影响
第二类是分析多变量的(双向)相互影响或(单向)因果影响(causal effect), 关注不同变量之间孰先孰后的影响模式(刘红云, 孟庆茂, 2003; 温忠麟, 2017)。在每次测量多个变量的情况下, 此类数据也称为面板数据(panel data)。主要采用交叉滞后模型(cross-lagged model, CLM, 全称为交叉滞后面板模型, cross-lagged panel model, CLPM, 也译为自回归交叉滞后模型; Jöreskog, 1970; Kenny & Harackiewicz, 1979)。
交叉滞后模型中的一个理论基础是自回归(autoregression), 可以分析所测变量随时间变化的稳定性。自回归方程为:

其中,y为结果变量, 表示被试在第次测量的观测值;y(t–1)为被试在第−1次测量的观测值;μ为截距项;d为残差; 系数β为自回归系数, 它描述了自回归效应的大小, 即个体的跨时稳定性(temporal stability; Hamaker et al., 2015, 也见:张荷观, 2012; 2015)。
两个变量之间的自回归与交叉滞后关系包含两个方程:

同方程1,β和β为自回归系数; 而研究者对模型中最感兴趣的参数为交叉滞后系数γ和γ, 表示在控制了一个变量上一时间点的水平后, 另一个变量上一时间点的水平对该变量当前水平的预测效应。相互影响反映了其中任何一个变量的变化都会带来另一个变量的历时性变化(Usami et al., 2019)。此类方法发展得相对较早, 分析方法也容易借用结构方程模型(structural equation model, SEM)当中路径分析的思路来解决(分析步骤和方法可见: 刘文等, 2015)。也可以借用到多水平模型的思路对面板数据建模(张旭, 石磊, 2010; 郑昱, 王二平, 2011)。
特别地, 因果模型是验证多变量相互影响的一种更为严格的方法, 可采用实验法或问卷法来论证(郝娟, 2009; 杨向东, 2007; 章奇, 2008)。其中, 在使用问卷法过程中需确定变量先后顺序(如区分特质变量和状态变量)、控制无关变量、分析变量之间相关。故历时性因果需要通过追踪研究来实现因果关系的验证(详见: 温忠麟, 2017)。
2.3 总体发展趋势及差异
第三类是描述总体的发展趋势, 以潜增长模型(latent growth model, LGM)和多水平模型(multilevel modeling, MLM, 又称多层/阶层线性模型, hierarchical linear model, HLM)为主要研究方法(刘红云, 孟庆茂, 2003)。
LGM以SEM的视角定义发展趋势(McArdle & Epstein, 1987), 使用带有均值结构的验证性因子分析模型, 通过定义载荷的大小来实现增长趋势的描述。以等距测量时间点的线性LGM为例, 定义两个潜变量: 截距0i和线性斜率1i, 测量部分和结构部分方程分别如下:
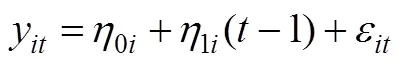

MLM可以构建和潜增长模型相同的分析框架(Goldstein & Woodhouse, 2001), 只不过在测量部分建模不同, 将方程3改写成第一水平(测量水平)方程:
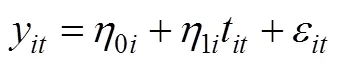
方程5中,1i的系数t是一个随机变量, 不必像LGM那样固定成特定的数值, 可以直接用时间来代替, 具有更强的灵活性。第二水平(个体水平)建模参见方程4, 即考虑截距和斜率的随机效应(即个体差异), 也可以灵活定义(分析步骤和方法可参考: 刘红云, 2005; 王孟成, 孟向阳, 2018; 肖丽华等, 2019。也见: 盖笑松, 张向葵, 2005; 王启文等, 2007; 王艳梅等, 2007; 吴晓云等, 2003; 杨会芹, 何俊华, 2008; 周叶芹, 2006)。
2.4 动态变化过程
最后一类研究收集的数据相对复杂, 测量的数据称为密集型追踪数据(intensive longitudinal data), 即按一定的程序在现实情境下对被试进行大量密集地测量(唐文清等, 2020; 温忠麟等, 2021)。这类方法主要关注目标变量随时间的动态变化过程, 对个体间与个体内的变化过程进行分离。通常采用多水平模型、时变效应模型(time- varying effect model)等方法。近年来也出现了将前几者综合起来的动态结构方程模型(dynamic structural equation model, DSEM)等方法(郑舒方等, 2021; 详见第3节) , 借鉴时间序列分析(time- series analysis)的相关建模过程。
采用MLM探究动态变化过程的研究仍关注个体随时间的发展趋势及个体差异的问题。特别是经验取样的数据收集范式, 国内研究者几乎都采用MLM建模(刁惠悦等, 2019; 段锦云, 陈文平, 2012; 李文静, 郑全全, 2008; 卢国庆等, 2019; 邵华等, 2011; 王若宇, 2020; 邢璐等, 2019; 张银普, 骆南峰等, 2016; 张银普, 石伟等, 2017; 张昱城等, 2019)。参见方程4和方程5。
时变效应模型(Shiyko et al., 2012)表示为:

其中,x是随时间变化的自变量,0()是截距, 表示x= 0、在时间时, 结果变量的均值;1()是斜率, 表示在时间时,x与y之间关系的强度和方向。这里0()和1()是时间的函数, 可定义为任意的函数关系(如高次、指数、周期等), 其中,0()表示某心理特质的平均水平随时间推移呈动态变化,1()表示x对y的效应随时间推移呈动态变化(唐文清等, 2020)。
3 国内追踪数据分析方法的发展
以上的几类研究方法各自在其主要模型上做增删和拓展, 可以解决很多复杂的研究问题。接下来将参考第二节中的研究问题及前人对新世纪追踪研究方法的总结(温忠麟等, 2021), 梳理国内的追踪研究目前的研究热点和发展思路。
3.1 总体发展趋势及差异模型的发展
3.1.1 潜增长模型的拓展
不难发现, 新世纪的追踪研究文章主要集中在第三类, 即“总体发展趋势及差异”为主导的研究问题。被引次数达到30次以上的8篇论文均涉及该研究问题。此类研究也得益于SEM技术的发展与应用, 以及相关软件(如Mplus, R, Amos等)的普及。
目前已有专著和文献论述LGM的方法和应用, 包含LGM的建模、增长形态的变化(通过对时间系数灵活多变的定义而达到二次型、不定义曲线类型/自由时间参数估计、单因子模型等)、不连续的增长趋势(如多阶段增长模型, piecewise growth model)、多元LGM (关注多指标、多组比较、高阶LGM)、包含时变(time-varying)和非时变(time-invariant)协变量、贝叶斯算法等议题(刘红云, 2005; 刘源等, 2013; 王婧等, 2017; 王孟成,毕向阳, 2018; 温忠麟, 刘红云, 2020; 张沥今等, 2019)。基于SEM, 能比较容易地定义LGM, 且测量次数仅为3次就能达到线性模型识别的要求。只要是有SEM基础的研究者, 推广到追踪研究当中, LGM是一个很好的选择。
3.1.2 潜类别分析与潜增长模型的融合
潜类别分析主要关注类别差异。它与潜增长模型融合之后关注发展趋势的异质性(heterogeneity)问题, 即“发展的类别”, 研究焦点包括增长混合模型、潜类别增长模型和多阶段混合增长模型。
增长混合模型(growth mixture model; 刘红云, 2007; 王孟成等, 2014)首先关注增长趋势, 用到LGM的建模思路, 再根据增长趋势来分类, 可以得到增长混合模型(方程7和方程8即方程3和方程4的多类别形式):



混合模型的议题当中, 潜类别数目的确定是讨论的焦点(王婧等, 2017; Nylund et al., 2007)。因为分类过程是一个探索性过程, 类别数目的确定需要根据一系列的拟合指标来综合判断, 但各个指标最终指向可能并不统一, 研究者往往需要综合数据与理论得出结论。
3.1.3 潜在转变分析
除了对发展趋势进行分类, 还可以关注潜类别随时间的发展, 个体归属的变化过程, 即“类别的发展/变化”, 包括潜在转变分析和随机截距潜在转变分析。
潜在转变分析(latent transition analysis, 或潜在转移/转换分析)是先根据潜类别分析, 在不同时间点上同时对样本分类, 再关注分类结果随时间变化的不同, 或在何条件下(协变量)哪些个体会“转移”到另一个类别(刘源, 刘红云, 2015; 王碧瑶等, 2015)。可以粗略地看成是类别变量的自回归分析。近年来, 潜在转变分析模型也拓展出包含随机截距因子的随机截距潜在转变分析(random intercept latent transition analysis, Muthén & Asparouhov, 2020; 温聪聪, 朱红, 2021)。它将个体间变异与个体内变异分离, 避免了高估保留在初始类别的概率。
3.2 多变量相互影响的模型发展
3.2.1 因果模型
除了前文提到的因果模型的哲学探讨和研究设计之外, 也有研究者提出了采用倾向分数(propensity score)、工具变量(instrumental variable)和回归间断点(regression discontinuity)等统计方法对因果模型进行检验(辛涛, 李峰, 2009)。还有研究使用了多次测量的面板数据, 引入了动态面板数据模型, 借鉴了时间序列分析的思路, 在交叉滞后模型基础上探讨非平稳、非线性、异质性、随机系数等概念(白仲林, 2010; 龙莹, 张世银, 2010; 皮天雷, 2009; 邢进良, 2007)。在自回归分析中, 也引入了折扣最小二乘估计(张俊等, 2014)。
3.2.2 追踪数据的中介效应
目前有关中介效应的文章大多采用横断研究, 如果变量之间的影响关系是历时性的, 横断研究存在缺陷(甘怡群, 2014; 温忠麟, 2017)。此时, 追踪研究可以确保“自变量→中介变量→因变量”这一传递链时序的正确性。追踪研究的中介分析方法可以从MLM、交叉滞后模型和LGM入手, 但只有基于交叉滞后模型的中介分析, 才能分析历时性影响(如: 方杰等, 2021; 刘国芳等, 2018)。
基于MLM的中介分析, 即多水平中介模型, 考虑多水平下自变量、中介变量和因变量三者的同时效应。将重复测量看成第一水平, 个体变量看成第二水平。使用的同时效应模型为:
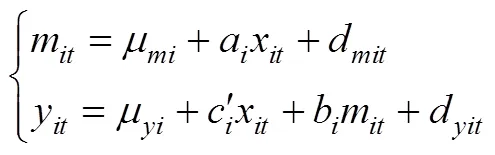

基于滞后效应模型的中介分析, 考虑单一水平下自变量对中介变量、中介变量对因变量的滞后影响。方程如下:

其中β、β和β分别表示自变量、中介变量和因变量的自回归系数。方程10可以有多个变式, 例如可根据实际情况定义一阶或二阶滞后; 也可将交叉滞后模型当中的参数看成是随机效应。
将交叉滞后模型与MLM的结合则可以产生多水平自回归中介模型(multilevel autoregressive mediation model), 即将方程10当中的系数和截距项均加上下角标, 考虑个体差异(第二水平变异)。还可以考虑连续时间模型和多水平时变效应中介模型(详见: 方杰等, 2021)。
基于LGM的中介模型中, 自变量、中介变量和因变量各自建立LGM, 分别检验三者在截距因子与斜率因子上的中介关系。后者更受到关注, 且一般在单独做斜率因子的中介模型时需要控制因变量的初始状态(方杰等, 2021)。
3.2.3 追踪数据的调节效应
温忠麟和刘红云(2020)讨论了基于LGM的交互作用分析, 即对自变量、调节变量和因变量分别构建LGM, 使用自变量和调节变量的截距因子和斜率因子之交互项分别预测因变量的截距和斜率。和LGM的中介效应类似, 截距的作用可以简化。实践中, 可以使用潜调节结构方程方法来替换差积指标进行估计, 但可能会有收敛问题(温忠麟, 刘红云, 2020)。
此外, MLM建模过程中可以直接检验调节效应, 即构建跨水平调节(交互)效应。如2.3节中介绍的, MLM在纵向模型中, 方程4中增加个体水平自变量, 如方程11所示。

其中, 系数11表示的就是个体水平变量x和时间t的调节效应(将方程11带入方程5即可得到交互项), 表示随时间的变化,x对y影响的变化。
3.3 总体发展趋势与多变量相互影响的融合
近年来, 交叉滞后模型在变异分解上更为深入, 可以借用SEM框架, 分离个体间变异与个体内变异, 衍生出来一系列模型。在历时性相互影响过程中, 如果包含非时变成分, 即跨时稳定的特质, 则可以通过抽取一个随机截距因子, 排除“个体间”的稳定变异, 在剩余的“个体内”变异中考察自回归和交叉滞后的影响。
最具代表性的拓展模型为随机截距交叉滞后模型(random intercept cross lagged model, RI-CLM; 方俊燕等, 印刷中; 刘源, 2021; Hamaker et al., 2015):

可观察到方程12比方程2多抽取了随机截距因子η和η, 表示数次测量之间的公共因子, 且设定系数为1; 每个个体在数次测量之间仍继续考虑自回归和交叉滞后影响(y(t–1)和x(t–1)的影响)。加入随机截距因子之后, 通过估计因子方差来表示非时变的稳定特质(个体间变异); 此时, 自回归系数β和β表示跨时稳定性(个体内变异), 称为个体内滞留参数(within-person carry-over; Hamaker et al., 2015)。如果将RI-CLM的η和η的系数限定成0时, 就成为一个标准交叉滞后模型, 表示没有跨时间的稳定特质。分离出个体间变异和个体内变异, 将稳定的发展特质定位到个体间, 而将波动与变化定位到个体内, 更精确地估计不同水平的变量间的影响。
如果进一步将RI-CLM中的随机截距因子看成是一个只包含截距因子的LGM, 则容易将斜率因子也纳入到模型中(即在方程12中继续增加潜变量因子, 同方程3)。甚至还能考虑测量误差(或测量信度), 在潜变量上建立自回归和交叉滞后影响。这些模型之间具有嵌套关系, 可以在统一框架中进行限定或拓展而相互转换(方俊燕等, 印刷中; 刘源, 2021)。比如潜变量自回归潜增长模型(latent variable autoregressive latent trajectory)是在交叉滞后模型的基础上添加潜增长因子和测量误差; 因子结构化潜增长模型(factor latent curve model with structured reciprocals)则是在潜增长模型的基础上增加交叉滞后参数, 二者建模的最终形式得到统一(刘源, 2021)。


3.4 追踪研究设计的发展
3.4.1 加速追踪设计
加速追踪设计主要关注群组效应(cohort effect,也叫朋辈效应、群组序列设计、混合纵向设计等), 是选择相邻的多个群组同时进行的短期追踪研究,获得的是有重叠的群组数据。加速设计同时纳入了群组效应和年龄效应, 比单群组的追踪包含更多的信息。一般采用LGM或MLM分析加速追踪设计数据(唐文清, 张敏强等, 2014)。
利用SEM多组比较方法, 即分别建立不同群组的LGM, 约束不同群组的相同年龄在斜率因子的时间载荷上相等, 进一步可以释放约束模型中的某些条件以检验群组差异。另一个思路是采用条件MLM, 即构建测量水平嵌套于个体水平的两水平模型, 再将群组变量作为第二水平的协变量构建条件模型。若第二水平的条件模型和无条件模型无统计差异, 则说明具有群组一致性。二者的建模思路殊途同归: 多组比较侧重考察组间差异(或组间一致性), 其实是一种调节效应的建模; MLM在第二水平加入协变量, 其对随机斜率的影响本身就是跨水平交互作用。核心都在于考察以年龄效应建立的发展趋势模型是否有群组差异。
3.4.2 密集追踪法
密集追踪法是对经验取样、生态瞬时评估、即时数据获取、日记法等方法的统称, 是按一定的程序收集被试在日常生活中特定时刻的数据, 获得几十甚至上百个测量点的追踪数据收集方法(唐文清等, 2020)。一般地, 如果观测点超过10个, 间隔时间更短(数天或数小时), 则更应采用此类研究范式(Castro-Alvarez et al., 2021; McNeish & Hamaker, 2020; 郑舒方等, 2021)。此类数据收集方法所探讨的研究问题重点是“个体内的波动”, 因而在分析时不关心整体变化趋势。所以在分析之前可以做“去趋势”处理; 如果关心趋势, 也可以在模型中增加描述趋势的部分。对密集型追踪数据的分析方法, 主要包含基于整体水平的MLM、时变效应模型、动态结构方程模型(Asparouhov et al., 2018; Asparouhov & Muthén, 2020), 以及基于个体水平的向量自回归模型(vector autoregressive model; Chatfield, 2003; 樊重俊, 2010)、组迭代多模型估计(group iterative multiple model estimation, GIMME; Gates & Molenaar, 2012)。在心理学或相关社会科学研究当中, 经验取样的数据更加适合研究动态过程; 但目前的状况看来, 经验取样数据多以MLM为方法, 其核心关注的仍然并非“波动”, 而是“趋势” (如: 李文静等, 2008),关注波动更合理的是时变效应模型和DSEM。
时变效应模型当中的截距和斜率随着时间的变化而变化, 是一种连续时间模型(唐文清等, 2020)。区别于LGM当中截距和斜率的估计都是固定的, 不随时间变化而变化; 也区别于MLM中,t为时间离散变量。时变效应模型的分析思路属于函数型数据分析(焦璨等, 2010), 即将离散变量转换成函数, 进行拟合和平滑。近期也有研究者发现模型中的协变量相关越高, 斜率函数的参数估计的准确性越低(黄熙彤, 张敏强, 2021)。

以上的几类方法假设研究对象是整体的、同质化的群体, 个体间存在相同的模型路径, 不同被试之间可能只是效应大小有所不同。而基于个体的方法, 主要对单个个体的一系列变量在不同时间、不同情境下的关系进行分析, 比如向量自回归模型。另有针对个体模型, 结合群体共享信息的优势, 提出的组迭代多模型估计方法。该方法将自回归和交叉滞后效应分解为个体效应和群体效应两个部分, 在对数据预处理之后, 同时包含了群体模型和个体模型的建立两个阶段。可以在R和LISREL上实现(郑舒方等, 2021)。
3.5 追踪研究的缺失数据处理
由于心理学等社会科学的特殊性, 以人为研究对象的数据收集过程中, 往往会产生大量的缺失数据。近10年的文献中, 有8篇关于缺失数据的研究。常见的3种缺失机制中, 完全随机缺失(missing completely at random)几乎可以使用所有的传统插补、基于模型的极大似然估计和多重插补; 随机缺失(missing at random)和非随机缺失(missing not at random)可以采用基于模型的极大似然估计、多重插补和贝叶斯估计等方法得到较为稳健可靠的处理结果(鲍晓蕾等, 2016; 陈丽嫦等, 2020a; 申宁宁等, 2015; 叶素静等, 2014)。其中, 非随机缺失的主要问题是在实证当中不能被检测出来, 但是在追踪研究中又可能会遇到。研究焦点集中于采用一种最优方法使得未被检测的缺失机制在进行插补或估计之后偏差最小(陈楠, 刘红云, 2015)。
在诸多缺失值处理方法中, 表现优良的基于模型的极大似然估计, 在追踪的情境下也需要基于LGM来建模, 所以LGM成为此类研究问题中需要采用的一个基础模型。比如, Diggle-Kenward选择模型在LGM的基础上, 建立每次测量的缺失数据虚拟变量, 认为数据缺失概率受到该时间点和上一时间点−1测量的目标变量y和y–1的影响(张杉杉等, 2017)。另外, 模式混合模型对于混合缺失机制有较好的估计效果(陈丽嫦等, 2020b)。此外, 贝叶斯方法也是处理缺失数据的备选方法之一(杨林山, 曹亦薇, 2012)。
3.6 其他议题
学科评述的文章有9篇。这些评述包括了心理学(焦璨等, 2010; 刘红云, 孟庆茂, 2003; 唐文清, 方杰等, 2014; 林丰勋, 2005)、社会学(风笑天, 2006; 宋时歌, 陈华珊, 2005)、管理学/组织行为学(胥彦, 李超平, 2019)、经济学(汪心怡等, 2020)、医学(汤宁等, 2019; 谢雁鸣, 徐桂琴, 2007)。其中包括了综述类文章, 介绍了诸多模型; 也有针对发文内容进行的实证研究, 总结了研究者常用的追踪次数、常用的追踪持续时间、更青睐的缺失数据处理方法等, 指引研究者应该如何更加科学进行追踪研究设计。
此外, 还有其他的议题。王力宾和张文专(2003)介绍了经济计量研究中纵向数据模型EM算法的作用。赵振等(2006)介绍了广义估计方程, 并且对医学领域的案例进行实践指导。廉启国等(2007)介绍了Stata软件中的两个纵向数据指令的差异。纪林芹和张文新(2011)论述了以个体定向为研究范式的发展心理研究方法, 包含了诸多潜类别模型。叶宝娟等(2012)讨论了追踪研究中的信度, 指出R和R系数单次时间点和整个追踪过程信度估计的优良性。庄严等(2015)介绍了非正态数据对估计效果的影响。
4 比较与展望
4.1 国内外研究的比较
进入新世纪, 国内追踪研究呈现出积极的发展态势。针对不同的研究问题均有较为完备的综述和教材介绍基本模型, 在基本模型基础上也深入探讨了模型的拓展与整合、算法的优化、参数估计的影响因素、不同模型的适用条件等议题。这些议题的探索和突破在国际同行当中都是处于先进地位的。从研究问题来看, 国内外的问题焦点保持一致; 然而, 就某一方面问题, 国内的追踪研究发文主题和方法使用上相对单一和集中。
4.1.1 国外研究中模型的变式
在发展趋势的研究问题当中, 发展形态的复杂化是此类模型拓展的一个焦点。目前, 国内研究大多集中在多阶段增长模型, 探讨模型估计的影响因素(刘源等, 2013; 王婧等, 2017)。但是, 多阶段增长模型在借用SEM框架定义时间的时候有先天的理论不足。该模型定义时间参数为固定参数, 即转折点已知, 是一个事先过程; 在没有理论假设的情况下无法对转折点进行估计。国外研究进一步深入, 利用随机系数模型、SEM数理转换或贝叶斯方法, 实现了未知转折点的估计(Harring et al., 2006; Kohli et al., 2015)、多个未知转折点的估计(Liu et al., 2018)、转折点随机效应的估计(Harring et al., 2021)等问题。
此外, 国外研究还会用到特殊的发展形态, 这些发展形态在国内鲜有文献提及。包括指数效应、高阶或幂分布模型、尖点突变模型(cusp catastrophe model, 利用高次方的函数关系, 关注断点和突变的发生及其多维影响因素)、惩罚样条模型(penalized spline model, 可对非连续形态进行平滑处理)等主题(Chow et al., 2015; Estrada & Ferrer, 2019; Setodji et al., 2019; Suk et al., 2019)。同时, LGM中时间参数的“重参数化” (reparameterization)可以将LGM当中的类似于“测量次数”的时间参数重新公式化, 使其具有实际意义而不是单纯仅有统计意义(Johnson & Hancock, 2019; Preacher & Hancock, 2015)。在数据类型方面, 也有国外研究提出了二分数据、计数数据发展趋势的分析方法(Peugh et al., 2020; Wang et al., 2016)。
在将潜增长模型与交叉滞后模型融合的过程中, 国外研究拓展的模型非常丰富。例如, 因子交叉滞后模型(factor cross-lagged model)在交叉滞后模型上考虑了每个指标的测量误差(或测量信度), 进一步将其与随机截距交叉滞后模型结合得到特质−状态−误差模型(trait-state-error; Kenny & Zautra, 2001)。特质−状态−误差模型分解出测量误差变异后, 真分数的变异继续被分解成两个部分: 一部分是稳定特质的变异, 另一部分是状态之间的相互影响。在此模型基础上进一步引入潜变量自回归潜增长模型(latent variable autoregressive latent trajectory, Bianconcini & Bollen, 2018), 即将每个测量时间点的特质用潜变量来表示, 考虑多个测量指标的问题。除此之外, 潜变化分数模型(latent change score model)也是同一时期衍生出来的模型(McArdle & Hamagami, 2001), 用两次测量之间的差异分数作为指标构造增长因子。在统计上, 潜变化分数模型可以粗略地看成是因子交叉滞后模型的一般形式(Usami et al., 2016); 而上述提及的模型大多可以通过约束或释放一些参数而得到另一个模型, 具备嵌套关系(Usami et al., 2019)。
最后, 在动态变化过程的研究中, 除了最近被引进国内的动态结构方程模型, 密集型追踪数据随着数据收集方法的多样化, 如电生理指标、计算机自适应测验数据、社会网络数据, 国外研究都提出了一些新方法可供研究者使用(Brinberg et al., 2021; Gates et al., 2020; Nahum-Shani et al., 2020)。
4.1.2 国外研究中模型的应用
国外追踪数据分析方法研究的另一个特点是会刊登一些较为“接地气”的文章。有一些教学类文章会有发表——像并不是有跨时代贡献的, 仅仅是一些模型拓展、不同模型的融合、如何实现各种软件包的操作(如R包, Mplus代码)等。这类研究对于大多数应用研究者而言才是能“看懂”、可以参考、高被引的文章, 特别是一些软件包或代码的共享。国内方法类文章和研究者在撰写文章的时候, 可以借鉴一部分教学类文章的文书形式——方法的来龙去脉写清楚, 但又比教材更精炼、研究问题更新颖, 并共享代码。国际前沿方法的引进需要教学类文章为应用研究者提供指导, 拉通国际话语, 提升国内研究平台。
4.2 国内研究的交叉学科思路
随着国内心理学学科的发展, 不同的领域分支采用了不同范式收集数据。除了传统诸如实验、行为、问卷等研究范式, 经验取样的丰富化(如长期追踪的电生理指标)、认知神经科学当中的纵向数据(如脑电数据、眼动数据、任务态脑影像数据)、教育当中的过程性数据(如作答反应时、按键次数、停留时间)均能收集到大量追踪数据。对数据挖掘的不充分, 使得收集到的庞大数据资料流于一般。研究者可以多采用(动态)结构方程模型, 包括采用时间序列分析的建模思路增强数据挖掘的充分性, 提出更合理的数据解读范式。
不同的学科也有“青睐的”统计模型。从本文梳理的国内发文现状来看, 心理学论文常用潜增长模型建模, 统计学、经济学、管理学则常用自回归、经验取样等方法。由于心理学研究的追踪次数较少, 2~3次的研究占绝大多数(75%, 参见: 唐文清, 方杰等, 2014), 不常用密集型追踪数据的方法来建模。纵观国际, JCR心理学领域当中有专门的“数理心理学”这个分支(Psychology, Mathematical), 其下有13本杂志均被2个或2个以上领域的索引收录, 每一本杂志都交叉于数学、教育学、社会学、统计学、生命科学等其他门类。其他学科的追踪研究范式也可以借鉴融合到心理学研究中, 比如生命科学中复杂的生长形态(灾变模型、弧形、分叉等)、教育中的过程性数据(机器学习、计算机自适应干预设计数据)、信息技术中的复杂文本数据(社交网络大数据、文本分析)等。和不同的学科进行交叉, 扩大心理学研究范式的边界, 这也是国内追踪研究可以发展的一个方向。
值得一提的是, 本文对研究问题的分类是根据前人研究的总结和拓展(刘红云, 孟庆茂, 2003; 唐文清等, 2020), 并非唯一的分类方法。实际上, 带有交叉滞后效应的模型可以归类到“多变量相互影响”; 而带有自回归效应的模型即可看成是“动态变化过程”。随着研究问题的深入和统计模型的发展, 不同的研究问题相互交叉, 统计模型也相互融合。例如, 随机截距交叉滞后模型解决的是同时考虑特质与状态的问题, 将多变量相互影响和总体发展趋势两个研究问题结合; DSEM不仅解决了个体波动, 同时也纳入个体变异和时间变异, 其实是融合了动态变化过程、多变量相互影响和个体差异的研究问题。未来的研究方法也会继续交叉融合, 不断突破已有的边界, 推动学科发展。
一个学科的良性发展也离不开基础数理研究方法的进化与更新。相信更优、更快、更精的追踪研究方法和模型能推动心理学和其他相关领域的发展, 真正从“描述和相关”研究中走出来, 朝向“解释和预测”的目标而为人类造福。
白仲林. (2010). 面板数据模型的设定、统计检验和新进展.,(10), 3–12.
鲍晓蕾, 高辉, 胡良平. (2016). 多种填补方法在纵向缺失数据中的比较研究.,(1), 45–48.
陈丽嫦, 衡明莉, 王骏, 陈平雁. (2020a). 定量纵向数据缺失值处理方法的模拟比较研究.,(3), 384–388.
陈丽嫦, 衡明莉, 王骏, 陈平雁. (2020b). 多种缺失机制共存的定量纵向缺失数据处理方法的模拟比较研究.,(20), 3684–3687+3697.
陈楠, 刘红云. (2015). 基于增长模型的非随机缺失数据处理: 选择模型和极大似然方法.,(2), 446− 451.
刁惠悦, 宋继文, 吴伟. (2019). 经验取样法在组织行为学和人力资源管理研究中的贡献、应用误区与展望.(1), 16−34.
段锦云, 陈文平. (2012). 基于动态评估的取样法:经验取样法.(7), 1110−1120.
樊重俊. (2010). 贝叶斯向量自回归分析方法及其应用..(6), 1060–1066.
方杰, 温忠麟, 邱皓政. (2021). 纵向数据的中介效应分析.,(4), 989−996.
方俊燕, 温忠麟, 黄国敏. (印刷中). 纵向关系的探究:基于交叉滞后结构的追踪模型.
风笑天. (2006). 追踪研究: 方法论意义及其实施.(6), 43−47.
盖笑松, 张向葵. (2005). 多层线性模型在纵向研究中的运用.,(2), 429−431.
甘怡群. (2014). 中介效应研究的新趋势——研究设计和数据统计方法.,(8), 584−585.
郝娟. (2009). 社会科学研究中因果分析方法的比较与应用.(24), 34–36.
黄熙彤, 张敏强. (2021). 协变量相关对时变效应模型参数估计的影响.(5), 1231−1240.
纪林芹, 张文新. (2011). 发展心理学研究中个体定向的理论与方法.(11), 1563−1571.
焦璨, 熊敏平, 张敏强. (2010). 心理学研究数据类型与统计方法——谈函数型数据分析的引入.(8), 1314−1320.
李丽霞, 郜艳晖, 张敏, 张岩波. (2012). 潜变量增长曲线模型及其应用.,(5), 713−716.
李文静, 郑全全. (2008). 日常经验研究: 一种独具特色的研究方法.(1), 169−174.
廉启国, 高尔生, 涂晓雯, 楼超华. (2007). Stata中xtmixed与xtgee相对于纵向数据分析的比较.(5), 463–466.
林丰勋. (2005). 心理学纵向研究方法的新进展.(5), 79−82+92.
刘国芳, 程亚华, 辛自强. (2018). 作为因果关系的中介效应及其检验.(11), 665−676.
刘红云. (2005).. 北京: 教育科学出版社.
刘红云. (2007). 如何描述发展趋势的差异: 潜变量混合增长模型.(3), 539−544.
刘红云, 孟庆茂. (2003). 纵向数据分析方法.(5), 586−592.
刘文, 刘红云, 李宏利. (2015).. 杭州: 浙江教育出版社.
刘源. (2021). 多变量追踪研究的模型整合与拓展: 考察往复式影响与增长趋势..(10), 1755− 1772.
刘源, 刘红云. (2015). 潜变量量尺的拓展及研究展望., (6), 8−12.
刘源, 刘红云. (2018). 非连续性与异质性——多阶段混合增长模型在语言发展研究中的应用.,(1), 137−148+166.
刘源, 骆方, 刘红云. (2014). 多阶段混合增长模型的影响因素: 距离与形态.,(9), 1400−1412.
刘源, 赵骞, 刘红云. (2013). 多阶段增长模型的方法比较.,(5), 415−422+450.
龙莹, 张世银. (2010). 动态面板数据模型的理论和应用研究综述.,(2), 30−34.
卢国庆, 谢魁, 张文超, 刘清堂, 张妮, 梅镭. (2019). 面向即时数据采集的经验取样法: 应用、价值与展望.,(6), 19−26.
吕浥尘, 赵然. (2018). 群组发展模型——干预研究的新方法.,(1), 91−96.
皮天雷. (2009). 面板数据建模中存在的问题、对策及最新进展.(23), 1−6.
邵华, 吕晓峰. (2011). EMA——一种生态主义取向的研究模式.(5), 1236−1241.
申宁宁, 房瑞玲, 高宇钊, 李少琼, 张军锋, 刘桂芬. (2015).纵向研究缺失数据多重填补及混合效应模型分析.,(7), 901–905.
宋秋月, 伍亚舟. (2017). 纵向数据潜变量增长曲线模型及其在Mplus中的实现.,(8), 1132– 1135.
宋时歌, 陈华珊. (2005). 纵贯性数据与生长模型在社会科学实证研究中的应用.(5), 69−91+244.
汤宁, 宋秋月, 易东, 伍亚舟. (2019). 医学纵向数据建模方法及其统计分析策略.,(3), 441– 444+447.
唐文清, 方杰, 蒋香梅, 张敏强. (2014). 追踪研究方法在国内心理研究中的应用述评.,(2), 216−224.
唐文清, 张敏强, 方杰. (2020). 时变效应模型及在密集追踪数据分析中的应用.,(2), 488−497.
唐文清, 张敏强, 黄宪, 张嘉志, 王旭. (2014). 加速追踪设计的方法和应用.,(2), 369−380.
汪心怡, 屈莉莉, 程杨阳. (2020). 结构方程模型及其在经济领域的应用研究综述.(27), 23–25.
王碧瑶, 张敏强, 张洁婷, 胡俊. (2015). 基于转变矩阵描述的个体阶段性发展: 潜在转变模型.(4), 36−43.
王婧, 唐文清, 张敏强, 张文怡, 郭凯茵. (2017). 多阶段混合增长模型的方法及研究现状.,(10), 1696−1704.
王力宾, 张文专. (2003). 经济计量研究中纵向数据模型的EM算法.(07), 83–87.
王孟成, 毕向阳. (2018).. 重庆: 重庆大学出版社.
王孟成, 毕向阳, 叶浩生. (2014). 增长混合模型: 分析不同类别个体发展趋势.,(4), 220−241+ 246.
王启文, 王洁贞, 薛付忠, 王艳梅, 徐凌中. (2007). 多元多层分析模型在纵向研究资料中的应用研究.(4), 333–335+339.
王若宇. (2020). 经验取样法方法论述及其应用展望.(4), 234−235.
王艳梅, 王洁贞, 丁守銮, 薛付忠, 孙秀彬, 王启文, 徐凌中. (2007). 多水平模型在纵向研究资料中的应用.(7), 658–661.
温聪聪, 朱红. (2021). 随机截距潜在转变分析(RI-LTA) ——个案自我转变与个案间差异的分离.(10), 1773−1782
温忠麟. (2017). 实证研究中的因果推理与分析.(1), 200−208.
温忠麟, 方杰, 沈嘉琦, 谭倚天, 李定欣, 马益铭. (2021). 新世纪20年国内心理统计方法研究回顾.(8), 1331−1344
温忠麟, 刘红云. (2020).. 北京: 教育科学出版社.
吴晓云, 曾庆, 周燕荣. (2003). 多水平模型的最新进展.(2), 152–154.
肖丽华, 郑建清, 黄碧芬, 苏菁菁, 吴敏. (2019). 利用SAS软件实现基于多水平模型纵向数据的Meta分析.,(5), 614–621.
谢雁鸣, 徐桂琴. (2007). 纵向数据分析方法在中医临床疗效评价中的应用浅析.(9), 711–713.
辛涛, 李峰. (2009). 社会科学背景下因果推论的统计方法.(1), 47–51.
邢进良. (2007). 面板数据分析模型方法及应用浅析.(5), 9−11.
邢璐, 骆南峰, 孙健敏, 李诗琪, 尹奎. (2019). 经验取样法的数据分析: 方法及应用.(1), 35−52.
胥彦, 李超平. (2019). 追踪研究在组织行为学中的应用.,(4), 600−610.
杨会芹, 何俊华. (2008). 多层线性模型在心理和教育纵向研究中的运用.,(3), 71−74+102.
杨林山, 曹亦薇. (2012). 贝叶斯理论框架下的2种纵向缺失数据处理方法的比较——以潜在变量增长曲线模型为例.,(5), 461−465.
杨向东. (2007). 教育评价中的因果关系及其推断.(9), 13–21.
叶宝娟, 温忠麟, 陈启山. (2012). 追踪研究中测验信度的估计.,(3), 467−474.
叶素静, 唐文清, 张敏强, 曹魏聪. (2014). 追踪研究中缺失数据处理方法及应用现状分析.,(12), 1985−1994.
袁帅, 曹文蕊, 张曼玉, 吴诗雅, 魏馨怡. (2021). 通向更精确的因果分析: 交叉滞后模型的新进展.,(2), 23−41.
张晨旭, 谢峰, 林振, 贺佳, 金志超. (2020). 基于组轨迹模型及其研究进展.,(6), 946–949.
张荷观. (2012). 存在自相关时检验和估计方法的改进——基于自回归分布滞后模型的自相关检验和参数估计.27(4), 44–49.
张荷观. (2015). 存在自相关时自回归模型的估计和检验.32(3), 147–160.
张俊, 吕效国, 施夏楠. (2014). 基于自相关的自回归模型参数的折扣最小二乘估计.(2), 160−161.
张沥今, 陆嘉琦, 魏夏琰, 潘俊豪. (2019). 贝叶斯结构方程模型及其研究现状.,(11), 1812−1825.
张杉杉, 陈楠, 刘红云. (2017). LGM模型中缺失数据处理方法的比较: ML方法与Diggle-Kenward选择模型.,(5), 699−710.
张旭, 石磊. (2010). 多水平模型及静态面板数据模型的比较研究.,(3), 22−26.
张银普, 骆南峰, 石伟. (2016). 经验取样法——一种收集"真实"数据的新方法.(2), 305−316.
张银普, 石伟, 骆南峰, 邢璐, 徐渊. (2017). 经验取样法在组织行为学中的应用.(6), 943−954.
张昱城, 葛林洁, 张山杉, 张龙. (2019). 经验研究的新范式——经验取样法.(1), 8−15+69.
章奇. (2008). 社会科学中的因果关系及其分析方法.(3), 2–12+125.
赵振, 潘晓平, 张俊辉. (2006). 广义估计方程在纵向资料中的应用.(5), 707–708.
郑舒方, 张沥今, 乔欣宇, 潘俊豪. (2021). 密集追踪数据分析: 模型及其应用.(11), 1948− 1969.
郑卫军, 何凡. (2020). 重复测量资料的统计分析方法.,(8), 863–864.
郑昱, 王二平. (2011). 面板研究中的多层线性模型应用述评.,(3), 111−120.
周广帅, 范冰冰, 王春霞, 游顶云, 刘言训, 薛付忠, ... 张涛. (2020). 交叉滞后路径分析在变量因果时序关系研究中的应用.,(6), 813–817.
周叶芹. (2006). 多层线性模型在管理学研究中的应用.(10), 180−182.
庄严, 杨嘉伟, 陈平雁. (2015). 非正态纵向数据随机生成的Monte Carlo模拟方法.,(3), 404– 406.
Asparouhov, T., Hamaker, E. L., & Muthén, B. (2018). Dynamic structural equation models.,(3), 359−388.
Asparouhov, T., & Muthén, B. (2020). Comparison of models for the analysis of intensive longitudinal data.,(2), 275−297.
Bianconcini, S., & Bollen, K. A. (2018). The latent variable- autoregressive latent trajectory model: A general frameworkfor longitudinal data analysis.(5), 791−808.
Brinberg, M., Ram, N., Conroy, D. E., Pincus, A. L., & Gerstorf, D. (2022). Dyadic analysis and the reciprocal one-with-many model: Extending the study of interpersonal processes with intensive longitudinal data.(1), 65−81. https://doi.org/10.1037/met0000 380
Castro-Alvarez, S., Tendeiro, J. N., Meijer, R. R., & Bringmann, L. F. (2022). Using structural equation modeling to study traits and states in intensive longitudinal data.(1), 17−43. https://doi.org/10.1037/met0000 393
Chatfield, C. (2003).(5th ed.). Boca Raton, FL: Chapman & Hall/CRC.
Chow, S.-M., Witkiewitz, K., Grasman, R., & Maisto, S. A. (2015). The cusp catastrophe model as cross-sectional and longitudinal mixture structural equation models.,(1), 142−164.
Estrada, E., & Ferrer, E. (2019). Studying developmental processes in accelerated cohort-sequential designs with discrete- and continuous-time latent change score models.,(6), 708−734.
Gates, K. M., Fisher, Z. F., & Bollen, K. A. (2020). Latent variable GIMME using model implied instrumental variables (MIIVs).,(2), 227−242.
Gates, K. M., & Molenaar, P. C. M. (2012). Group search algorithm recovers effective connectivity maps for individuals in homogeneous and heterogeneous samples.(1), 310−319.
Glynn, R. J., Laird, N. M., & Rubin, D. B. (1986). Selection modeling versus mixture modeling with nonignorable nonresponse. In H. Wainer (Ed.),(pp. 115−142). New York, NY: Springer New York.
Goldstein, H., & Woodhouse, G. (2001). Modelling repeated measurements. In A. H. Leyland & H. Goldstein (Eds.),(pp. 13−26). England: John Wiley & Son, Ltd.
Hamaker, E. L., Kuiper, R. M., & Grasman, R. P. P. P. (2015). A critique of the cross-lagged panel model.(1), 102−116.
Harring, J. R., Cudeck, R., & du Toit, S. H. (2006). Fitting partially nonlinear random coefficient models as SEMs.,(4), 579−596.
Harring, J. R., Strazzeri, M. M., & Blozis, S. A. (2021). Piecewise latent growth models: Beyond modeling linear- linear processes.,(2), 593− 608.
Johnson, T. L., & Hancock, G. R. (2019). Time to criterion latent growth models.,(6), 690− 707.
Jöreskog, K. G. (1970). A general method for analysis of covariance structures.(2), 239−251.
Kenny, D. A., & Harackiewicz, J. M. (1979). Cross-lagged panel correlation: Practice and promise.(4), 372−379.
Kenny, D. A., & Zautra, A. (2001). Trait-state models for longitudinal data. In L. M. Collins & A. G. Sayer (Eds.),(pp. 243−263). Washington, DC, US: American Psychological Association.
Kohli, N., Hughes, J., Wang, C., Zopluoglu, C., & Davison, M. L. (2015). Fitting a linear-linear piecewise growth mixture model with unknown knots: A comparison of two common approaches to inference.,(2), 259−275.
Little, R. J. A., & Rubin, D. B. (2002).. New York, NY: Wiley-Interscience.
Liu, Y., Liu, H., & Zheng, X. (2018). Piecewise growth mixture model with more than one unknown knot: An application in reading development.,(4), 485−507.
McArdle, J. J., & Epstein, D. (1987). Latent growth curves within developmental structural equation models.(1), 110−133.
McArdle, J. J., & Hamagami, F. (2001). Latent difference score structural models for linear dynamic analyses with incomplete longitudinal data. In L. M. Collins & A. G. Sayer (Eds.),(pp. 139−175). Washington, DC, US: American Psychological Association.
McNeish, D., & Hamaker, E. L. (2020). A primer on two-leveldynamic structural equation models for intensive longitudinal data in Mplus.,(5), 610−635.
Nahum-Shani, I., Almirall, D., Yap, J. R. T., McKay, J. R., Lynch, K. G., Freiheit, E. A., & Dziak, J. J. (2020). SMARTlongitudinal analysis: A tutorial for using repeated outcome measures from SMART studies to compare adaptive interventions.,(1), 1−29.
Nylund, K. L., Asparouhov, T., & Muthen, B. (2007). Deciding on the number of classes in latent class analysis and growth mixture modeling: A Monte Carlo simulation study.,(4), 535−569.
Peugh, J. L., Beal, S. J., McGrady, M. E., Toland, M. D., & Mara, C. (2020). Analyzing discontinuities in longitudinal count data: A multilevel generalized linear mixed model..(4), 375−397.
Preacher, K. J., & Hancock, G. R. (2015). Meaningful aspects of change as novel random coefficients: A general method for reparameterizing longitudinal models.,(1), 84−101.
Setodji, C. M., Martino, S. C., Dunbar, M. S., & Shadel, W. G. (2019). An exponential effect persistence model for intensive longitudinal data.,(5), 622−636.
Shiyko, M. P., Lanza, S. T., Tan, X., Li, R., & Shiffman, S. (2012). Using the time-varying effect model (TVEM) to examine dynamic associations between negative affect and self confidence on smoking urges: Differences between successful quitters and relapsers.(3), 288−299.
Suk, H. W., West, S. G., Fine, K. L., & Grimm, K. J. (2019). Nonlinear growth curve modeling using penalized spline models: A gentle introduction.,(3), 269−290.
Usami, S., Hayes, T., & McArdle, J. J. (2016). Inferring longitudinal relationships between variables: Model selection between the latent change score and autoregressive cross- lagged factor models.,(3), 331−342.
Usami, S., Murayama, K., & Hamaker, E. L. (2019). A unified framework of longitudinal models to examine reciprocal relations.(5), 637−657.
Wang, C., Kohli, N., & Henn, L. (2016). A second-order longitudinal model for binary outcomes: Item response theory versus structural equation modeling.,(3), 455−465. https://doi.org/10.1080/10705511.2015.1096744
Zyphur, M. J., Allison, P. D., Tay, L., Voelkle, M. C., Preacher, K. J., Zhang, Z., ... Diener, E. (2020). From data to causes I: Building a general cross-lagged panel model (GCLM).(4), 651−687.
Methodology study and model development for analyzing longitudinal data in China’s mainland
LIU Yuan1,2, DU Hongyan1, FANG Jie3, WEN Zhonglin4
(1School of Psychology, Southwest University;2Key Laboratory of Cognition and Personality (SWU), Ministry of Education, Chongqing 400715, China) (3Institute of New Development & Department of Applied Psychology, Guangdong University of Finance & Economics, Guangzhou 510320, China) (4Center for Studies of Psychological Application & School of Psychology, South China Normal University, Guangzhou 510631, China)
Longitudinal research plays an important role in sciences since it can reveal a more convincingrelationship between variables compared to cross-sectional research. The present study reviews the methodology studies and model development for analyzing longitudinal data in China’s mainland. Longitudinal research can compare the mean difference, examine the reciprocal relationship between variables, depict the growth trajectory with individual differences, and explore dynamic changes. All these are the popular research topics in recent 20 years, especially the growth trajectory with individual differences, reciprocal relationship between variables, the integration of the growth trajectory and reciprocal relationship, research design, and missing data. We also compare the present study to an international scope and look forward to the future direction from a multidisciplinary perspective.
longitudinal research, reciprocal effect, growth trajectory, dynamic changes
B841
2021-09-24
* 国家自然科学基金项目(31800950, 32071091)
温忠麟, E-mail: wenzl@scnu.edu.cn
猜你喜欢
导航定位学报(2022年4期)2022-08-15
小学生学习指导(高年级)(2021年4期)2021-04-29
中学生数理化·七年级数学人教版(2020年10期)2020-11-26
河北理科教学研究(2020年2期)2020-09-11
汽车导报(2017年5期)2017-08-03
中学生数理化·高二版(2016年4期)2016-05-14
Coco薇(2016年2期)2016-03-22
Coco薇(2015年1期)2015-08-13
小雪花·成长指南(2015年7期)2015-08-11
小雪花·成长指南(2015年4期)2015-05-19
