
基于分布式技术的气象大数据共享服务系统设计与实现
2022-08-10 08:11陈凯华武国良李庆博李宝桐姜罕盛
计算机应用与软件 2022年7期
雷 鸣 陈凯华 武国良 李庆博 李宝桐 姜罕盛
1(天津市气象信息中心 天津 300074) 2(南京恩瑞特实业有限公司 江苏 南京 210000)
0 引 言
全国综合气象信息共享系统(CIMISS)是由国家气象信息中心于2009年组织建设,集数据收集、分发、处理、存储和共享于一体。2013年,该系统推广部署在全国各省级气象数据中心,为各省级部门提供了良好的气象数据服务和业务支撑[1-3]。
但是近年来,随着气象业务的不断拓展以及数据量的不断增加,现有省级CIMISS的数据处理能力已经显得不足,特别是数据的响应速度和存储能力,已无法满足现有的数据服务要求。截至2019年,CIMISS系统存储的气象数据已经超过31亿条,存储的数据量已达46.5 TB,且仍以每天40.1万条、62.2万个文件、118.3 GB的数据量不断增长。CIMISS的数据存储能力已经无法满足业务要求。
1 现状与需求
目前,CIMISS业务应用系统间的数据交换和文件存储,都是基于共享文件系统GPFS(General Parallel File System)实现,从而达到所有节点(在资源组内的)均能并行访问整个文件系统。
支撑CIMISS系统运行的后台则使用的是Oracle RAC数据库、TonglinkQ消息中间件和MapGIS DCServer服务管理器,而其核心则是Oracle数据库。对于地面、高空等结构化的气象数据,Oracle透过数据表存储其要素值[4-5];对于数值模式产品、雷达资料等非结构化数据,Oracle则仅存储文件对应的元数据和索引,再透过GPFS系统实现文件的存储管理[6-8]。
现有气象服务对数据的快速响应要求越来越高,而由于GPFS动态扩展能力较弱、Oracle RAC数据库节点较少(省级仅2个)、硬件设备陈旧等诸多原因,导致现有CIMISS无法较好满足气象服务对数据的敏捷性要求,特别是在长序列历史资料的影响上面。因此,对气象业务,诸如天气过程回溯分析、气候预测等支撑能力不足[9-11]。
在今天的数字化时代,云计算、互联网、社交媒体、大数据的发展使得数据量呈现爆炸式增长。传统存储在应对这些海量数据需求时,面临着诸多挑战,已经很难满足不断增长的数据需求,包括超大规模的横向扩展、越来越高的性能要求、数据长期存储的可靠性、统一资源池的管理、更低的TCO总体拥有成本等,而且传统存储的软硬件紧耦合方式,也限制了硬件迭代的速度、选型的灵活性。
2 系统设计
随着科学技术的发展,特别是大数据存储技术的长足进步,涌现很多分布式技术的解决方案,并在相关行业取得了较好的效果[12-16]。
因此,考虑利用可靠成熟的分布式存储技术,进行天津市气象局气象数据共享服务系统的设计与实现,如图1所示。即通过分布式文件系统和分布式数据库来分别提升气象数据的储存管理能力与数据的服务和支撑能力,并与CIMISS系统实现无缝对接。
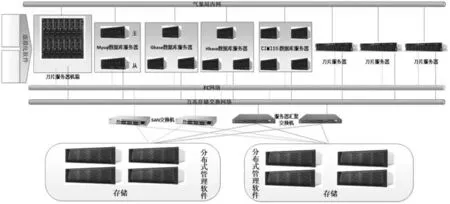
图1 天津市气象局大数据中心物理架构
2.1 分布式文件系统
分布式文件系统(Hadoop Distributed File System,HDFS)被设计成适合运行在通用硬件上的文件系统。它与现有的分布式文件系统有很多共同点。但同时,它与其他分布式文件系统的区别也比较明显。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。同时,因为HDFS放宽了一部分POSIX约束来实现流式读取文件系统数据的目的,从而获取数据访问的高吞吐量,非常适合大规模数据集上的应用。它所具有的高容错、高可靠性、高可扩展性、高获得性、高吞吐率等特征为海量数据提供了不怕故障的存储,为超大数据集的应用处理带来了很多便利。
因此分布式文件系统可以有效解决数据存储和管理的难题,将整个分布于不同网络节点的数据资源统合成为一个高度集约化的数据中心[17-18]。从而极大便利业务应用系统的使用,而无须关心数据存储在何处。
同时,透过网络附属存储(Network Attached Storage,NAS)技术,提供数据共享服务。在NAS存储结构中,存储系统不再通过I/O总线附属于某个特定的服务器或客户机,而是直接通过网络接口与网络相连,便于用户访问或管理数据。NAS实际上是一个带有瘦服务的存储设备,能够大大降低存储设备的成本,并有效地保护数据。
2.2 分布式数据库系统
分布式数据库系统(DDBS)包含分布式数据库管理系统(DDBMS)和分布式数据库(DDB)。它将分布于不同的局部数据库中存储、由不同的DBMS进行管理、在不同的机器上运行、由不同的操作系统支持、被不同的通信网络连接在一起的数据进行统合,形成一个逻辑上统一的数据库。这与Oracle RAC共享缓存和磁盘机理不同,分布式数据库将所有花销分摊于网络上多个节点,从而获得更大的数据服务和存储能力。而且分布式数据库系统能方便地把一个新的节点纳入系统,不影响现有系统的结构和系统的正常运行,提供了逐渐扩展系统能力的较好途径,有时甚至是唯一的途径[19-20]。
同时,所有数据的出入均通过CIMISS的气象数据统一服务MUSIC接口(Meteorological Unified Service Interface Community)提供数据共享服务。因此,无论对于气象数据用户还是业务应用而言,均是无影响、无感知的。
气象数据大致可以分为结构化和半/非结构化数据。前者数据结构化程度高,数据结构固定,如站点数据,故采用关系数据库形式对此类数据进行存储,简化了数据存储逻辑,有利于提高数据存取效率以及分析速度。考虑到数据中心需要存储海量数据,故结构化数据需要在存储集群内进行分库分表存储,以保障数据库的并发性能。关系数据库以数据来源(如雷达站、基准设备)进行分库存储,各个数据存储节点采用GBase 8a、GBase 8t等高性能数据库,保证在大数据场景下能够实现数据的高效存取。
针对半/非结构化气象数据,采用HBase分布式数据库存储和气象数据分块压缩技术,进行气象数据存储和处理。数据分块压缩技术路线如图2所示。
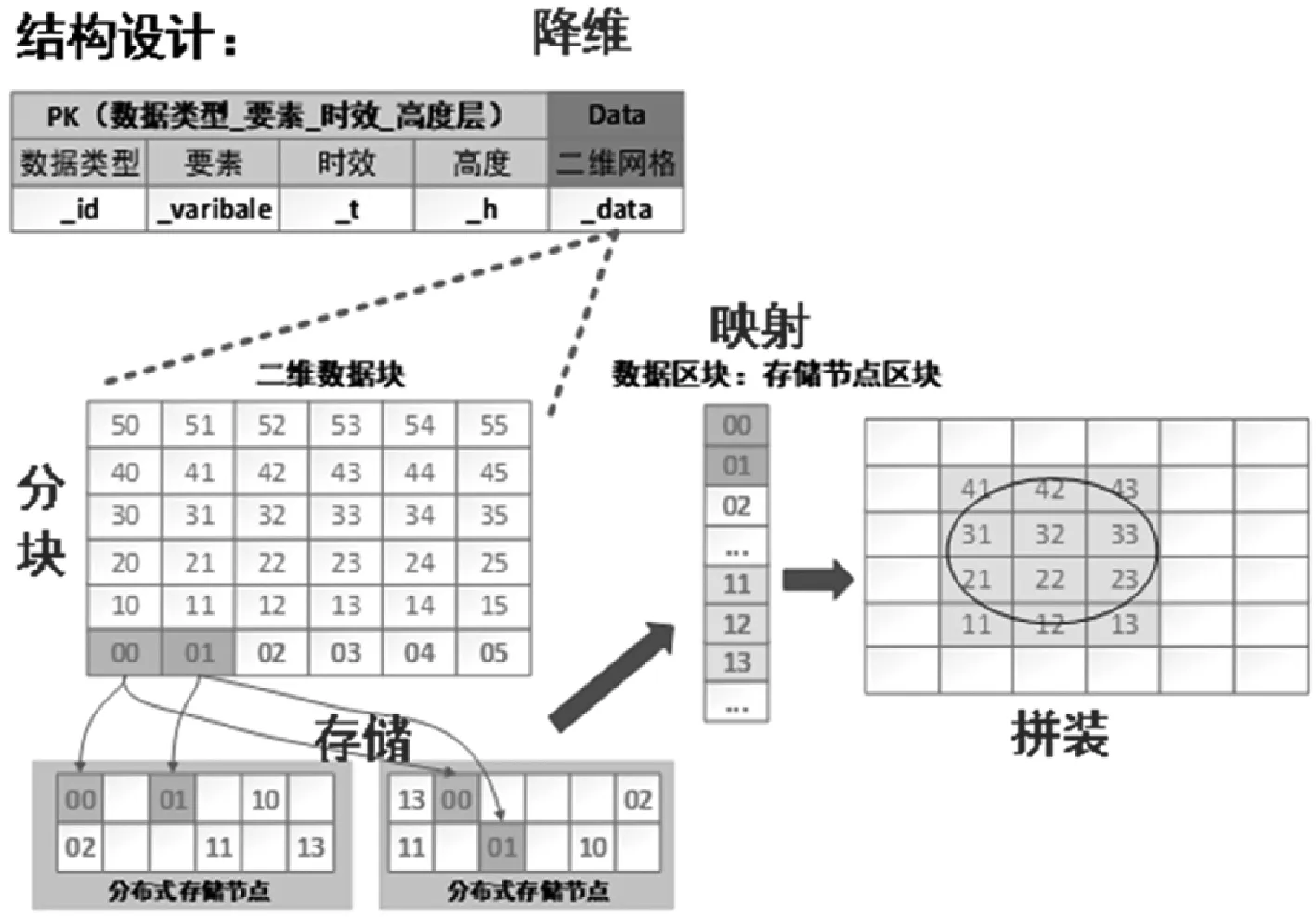
图2 数据分块压缩技术路线
所涉及的各个数据库和任务分工,如表1所示。
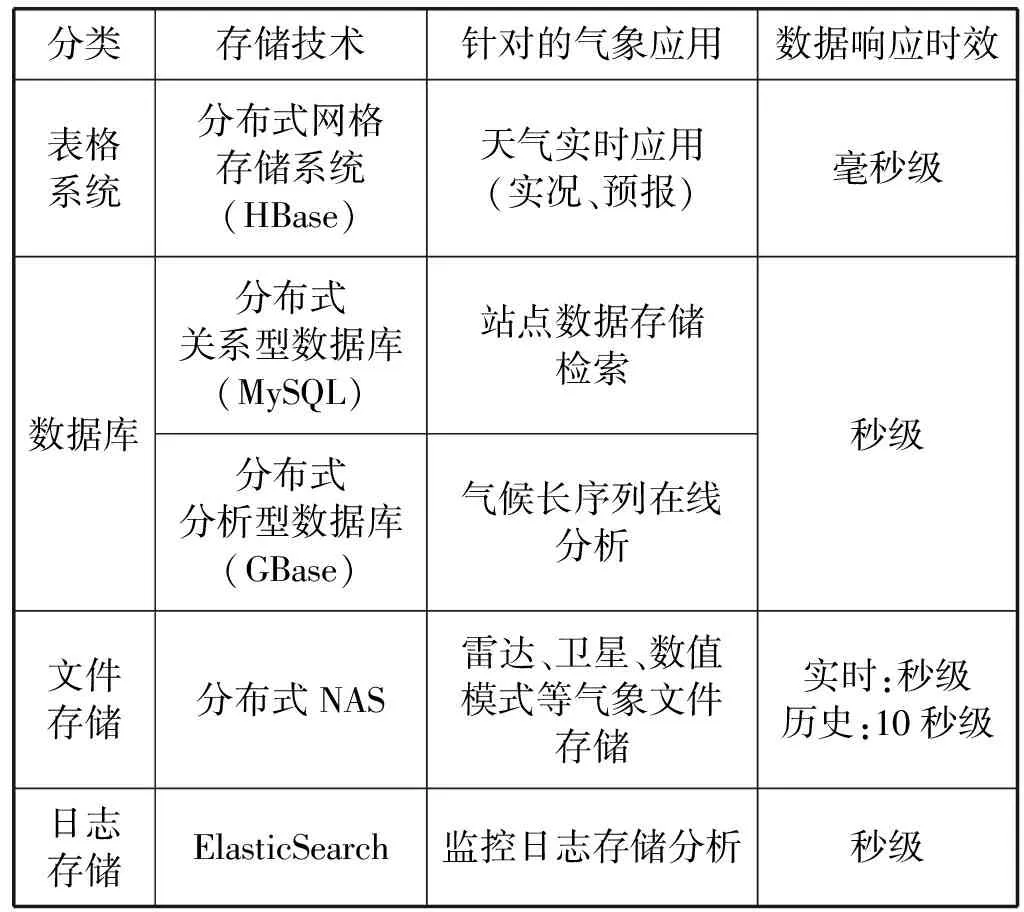
表1 天津市气象局数据存储分类表
2.3 数据架构设计
系统的数据架构设为四层结构,如图3所示,分别为数据采集层、数据处理层、数据存储层和数据服务层。
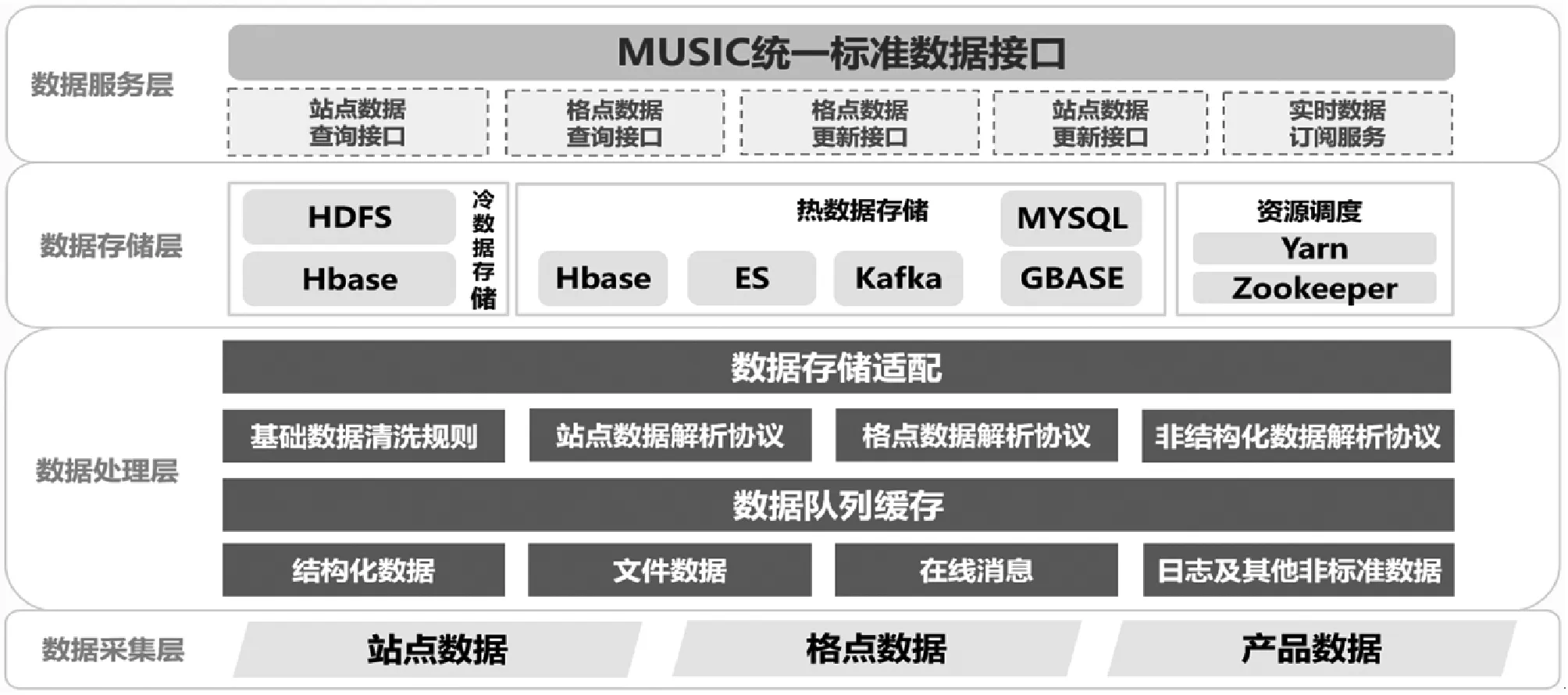
图3 整体数据架构设计图
(1) 数据采集层。在最底层的数据源层将数据主要分为站点数据、格点数据和产品数据三大类,依靠数据传输系统分别将数据传输至数据采集层,数据传输系统分别支持FTP、SFTP、HTTP、FILE四种数据通信协议,在传输过程中支持对数据的重命名、解压缩处理等基本数据预处理功能。
(2) 数据处理层。数据采集层负责进行数据入库前的站点数据以及格点数据标准化处理,同时按照存储设计规范进行入库。数据在数据采集层按照气象业务分为结构化数据、文件数据、在线消息和日志及其他非标准数据四类,通过消息队列缓存机制及多机集群配置进行统一数据分布式处理。数据经过清洗和解析按照基础数据清洗规则、站点数据解析协议、格点数据解析协议、非结构化数据解析协议形成可入库管理的数据流,通过数据存储适配后,进入相应的数据存储组件汇总,如图4所示。
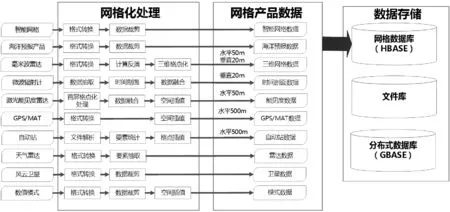
图4 数据处理层数据流向
(3) 数据存储层。在数据存储层根据数据存取的频繁度将数据分为冷数据和热数据。
站点数据处理流程:通过实时解析到MySQL库后,利用日志同步机制实时同步到GBase数据库中。
格点数据处理流程:通过实时解析到HBase数据库,通过将RowKey存储Elasticsearch(ES)中实现快速寻址,快速获取得到需要查询的数据,提高对格点数据的查询效率。
ES是一个实时的分布式搜索和分析引擎,可以快速处理大规模数据。常用于全文搜索、结构化搜索及分析,主要被用来存储有聚合及筛选的热数据,如:存储近几年的站点数据和格点数据索引,方便搜索及聚合查询。
HDFS主要用作数据仓库,存放格点数据文件的冷数据,即超过一年或不常用的数据。HDFS是分布式文件系统,应用它一次写入、多次读出的场景特性,当数据服务需要使用这部分冷数据时,可直接通过ES快速获取文件找到对应数据解析后返回结果并存储到HBase组件中。
Kafka主要用来实现热数据的缓存,以减少数据处理过程中的缓存压力。
为了有效应对气象数据种类多、增长迅速的特点,将热数据存储层设为第一级,冷数据存储设为第二级。同时,将超过1年的数据存储在H3C中,设为第三级。利用H3C优秀的存储性能进行存储管理。
(4) 数据服务层。在数据服务层与MUSIC接口服务系统融合,通过统一的MUSIC接口提供对格点和站点数据的查询、更新服务及实时数据的订阅服务。
MUSIC是跨平台、多语言、多协议,为应用系统提供直接支撑服务。它将多源的数据组合在一起,形成一个统一、规范的出口,提供服务。
通过接口(API),实现应用与数据解耦,保障前端应用系统稳定,不受后端异构数据环境干扰、实现技术变化无影响。从而实现数据管理与应用分离,接口保持稳定不变。其结构示意图如图5所示。
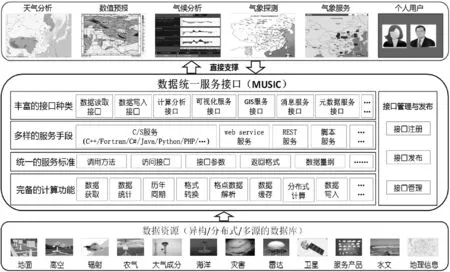
图5 MUSIC接口服务支撑架构
3 实践与测试
目前,GBase数据库中入库了所有建站以来的数据,库中共有155 281 334 700条记录。为了检验系统性能,特针对站点结构化数据进行数据查询的性能测试:发挥查询聚合的性能,利用MPP并行数据库优势,使用分片分布式的特长,采用分治法计算长时间的数据聚合请求。分别统计天津各站点一定时间内的小时平均气温与累计降雨。各项性能如表2所示。
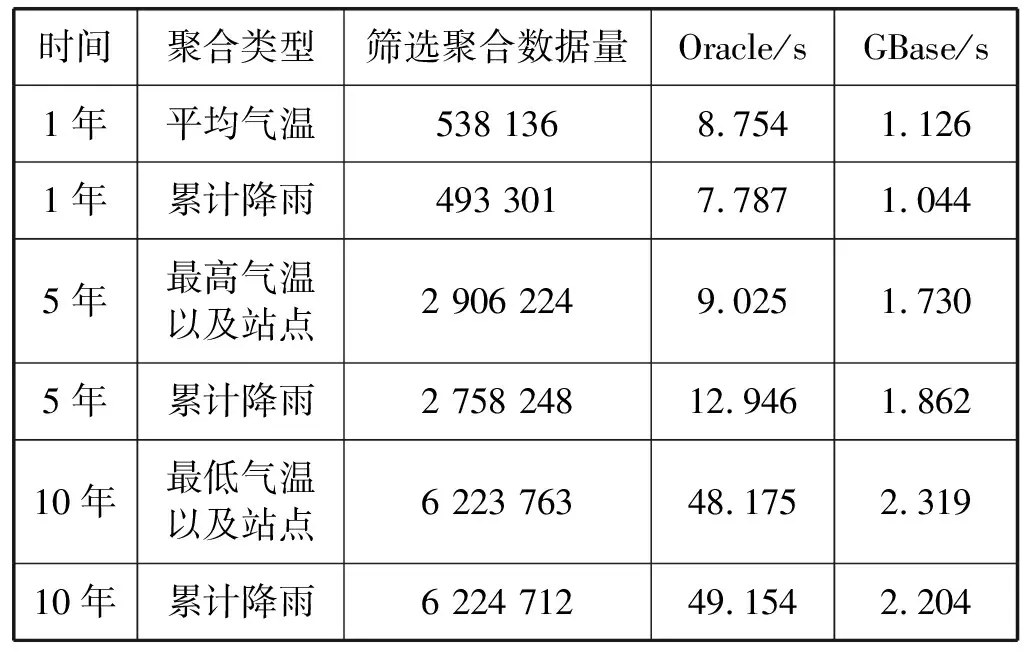
表2 站点数据查询性能测试表
目前,CIMISS统计天津所有站点过去1年内的平均气温需要8.7 s,而通过GBase数据库建设,统计过去1年平均气温大概需要1.1 s,性能比现有CIMISS提升7倍左右,而随着数量的进一步增大,性能提升的优势更加明显,甚至高达22倍以上。
针对格点数据,为了提升查询性能,特别使用ES作为数据检索,发挥查询聚合的性能;使用HBase作为点位数据存储,发挥IO的性能;为了减少传输的时间,将JSON结果集数组化为相应的经纬度矩阵,将矩阵写入.csv文件后压缩成.tgz文件返回给前端。
通过模拟过去2个月欧洲中心全部数据,数据环境总大小约7 409 247 350个格点数,获得如表3所示测试结果。
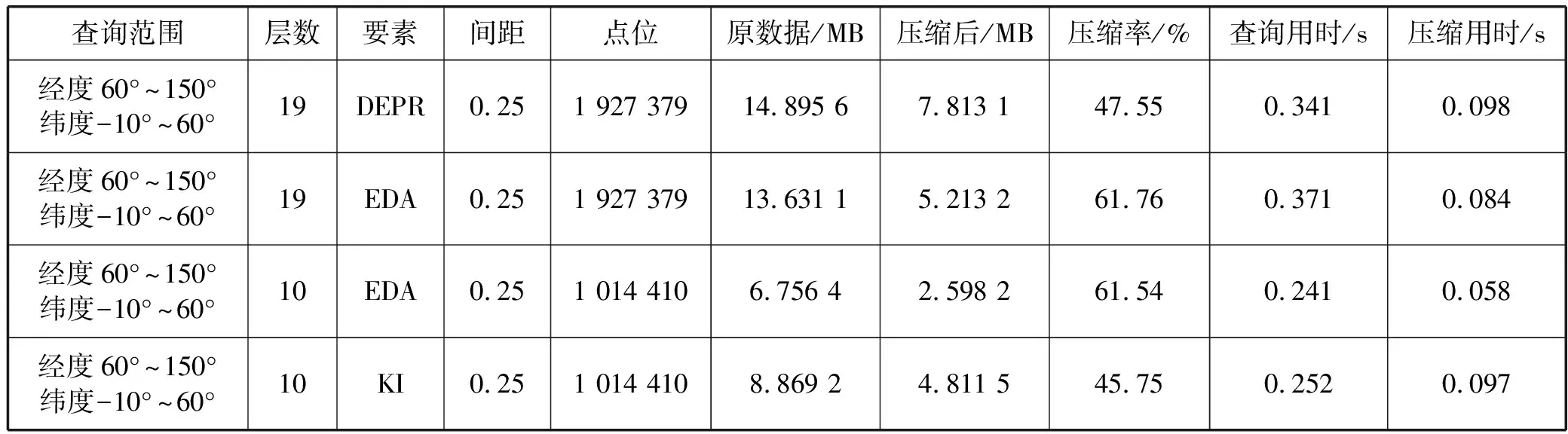
表3 格点数据查询性能测试表
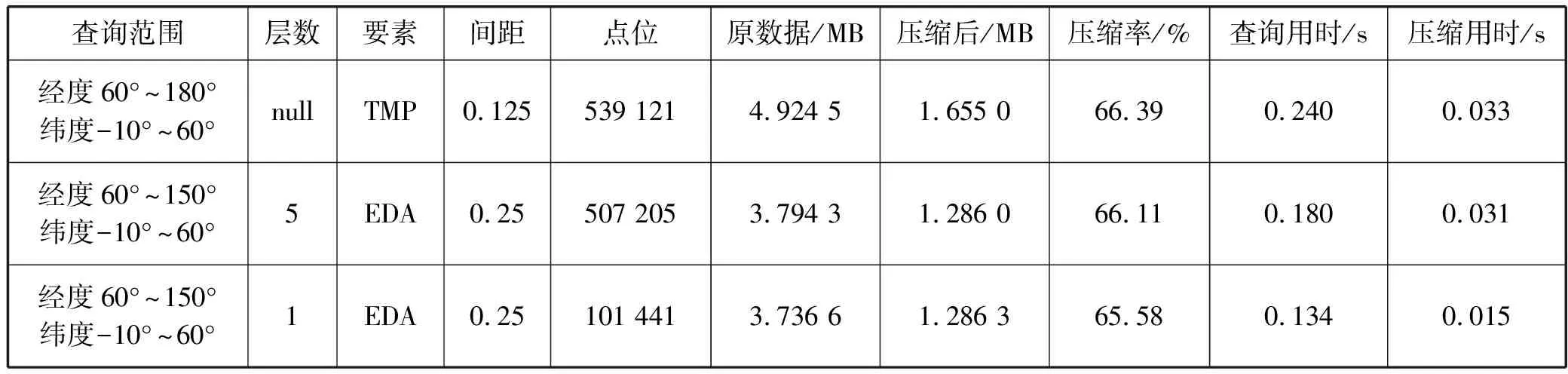
续表3
现状对比:采用天津1 km网格6个月历史数据进行性能测试,结果表明查询数据可在0.3 s内到达应用终端,与格点数据在天津省局一体化平台中的应用相比,性能提升了5倍左右。针对温度和阵风的详细查询测试情况如图6和图7所示。

图6 天津网格预报整点温度查询显示
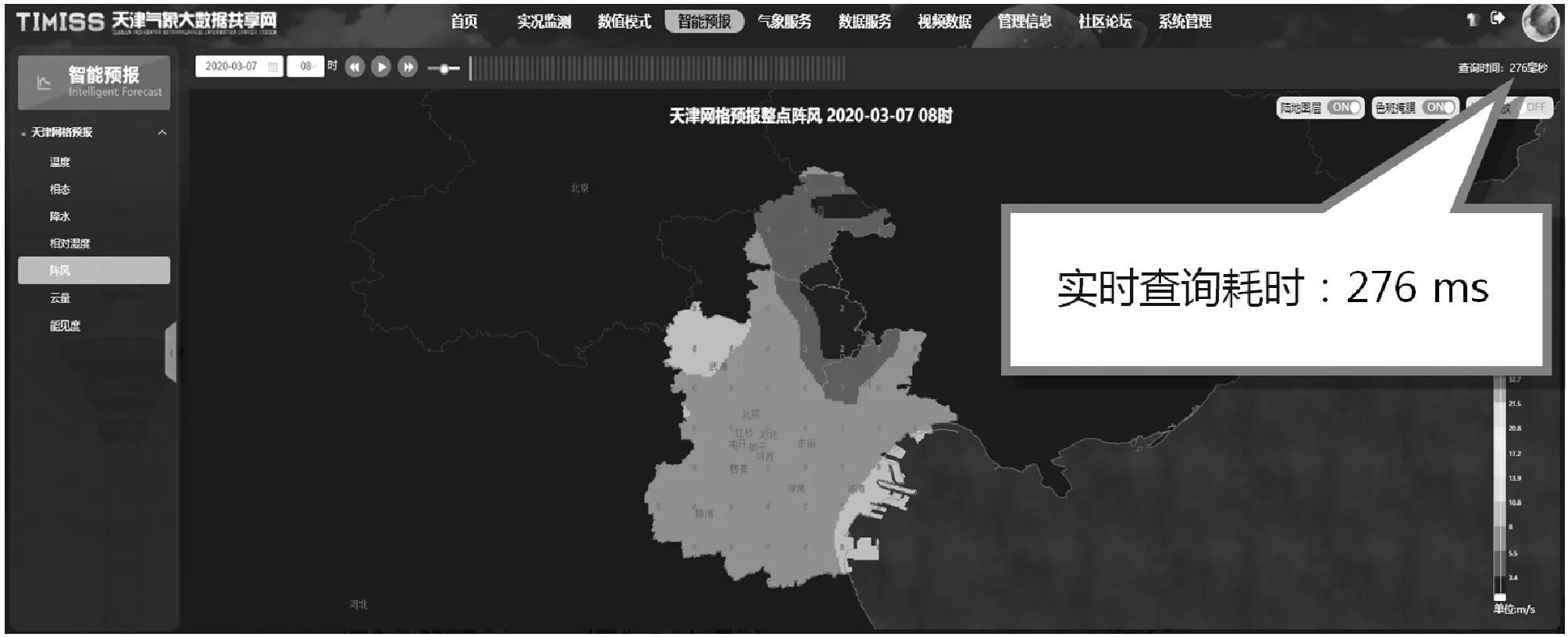
图7 天津网格预报整点阵风查询显示
4 结 语
结合气象业务需求,本文在不改变现有业务系统和系统架构的基础上,实现与省级CIMISS系统的无缝对接,并通过原有CIMISS传统气象数据服务性能与现有分布式技术架构下的气象数据服务性能的对比分析,可以明显看到,基于分布式技术的气象数据共享服务系统具有更卓越的优势:数据聚合能力强,其并发性、安全性和可靠性更高。而且分布式存储技术具有良好的横向扩展能力,非常适合应用于数据范围和数据维度随着时间不断增长的行业需求。
目前,作为有效支撑天津市省局CIMISS气象数据服务系统的关键功能组件,分布式数据库系统与分布式文件系统已经通过性能测试和功能测试,为数据服务实时性要求较高的气象业务提供了有力保障,并随着气象业务的发展不断完善和优化。
猜你喜欢
经济研究导刊(2022年25期)2022-11-05
房地产导刊(2022年10期)2022-10-18
课堂内外·好老师(2022年3期)2022-04-25
学习与科普(2022年17期)2022-04-23
现代计算机(2021年16期)2021-08-06
科学与财富(2021年35期)2021-05-10
云南教育·小学教师(2021年12期)2021-03-23
福建基础教育研究(2020年3期)2020-05-28
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
