
基于改进YOLOv5算法的复杂场景交通目标检测
2022-08-12 08:48顾德英罗聿伦李文超
东北大学学报(自然科学版) 2022年8期
顾德英, 罗聿伦, 李文超
(东北大学秦皇岛分校 控制工程学院, 河北 秦皇岛 066004)
近年来,自动驾驶、智能交通等领域的研究飞速发展,成果丰硕.基于深度学习和计算机视觉的交通场景目标检测技术已经拥有了非常丰富的应用领域,正在逐渐取代传统算法.但是,深度学习算法的应用往往需要消耗大量的计算资源,不容易实现实时检测.如果能从算法入手,通过算法的改良来提升模型检测精度和推理速度,进而部署到车载摄像头或电子监控等边缘计算设备中,可以有效降低成本,有利于深度学习目标检测算法在交通领域的大规模部署落地和推广应用.
2006年Hinton等学者最早提出深度学习的概念[1],基于深度学习的计算机视觉目标检测算法开始发展.2012年Krizhevsky等提出的AlexNet模型在ImageNet竞赛中实现重大突破[2],深度学习算法又取得了长足的进步.深度学习目标检测算法经历了两个发展阶段,首先是以R-CNN[3]、Faster R-CNN[4]等为代表的两阶段检测算法,需要遍历图片所有区域得到候选框再进行目标分类.Tian等[5]使用改进的Faster R-CNN在相关数据集上对车道线进行检测与标记,获得了比R-CNN更快的结果.然而,此类算法检测精度较低,很难实现实时检测,实际应用效果不佳.其次是以YOLO[6]、SSD[7]等为代表的一阶段检测算法,基于边框回归的端到端目标检测可在单个神经网络内实现目标的分类与定位,它的模型检测精度、速度都比前者提升了一个数量级,是目前主流的目标检测算法.周攀等[8]采用ResNext网络代替原YOLOv3结构中基于ResNet的残差结构,并采用K-means算法聚类分析模型的锚框参数,在KITTI数据集上检测精度达到87.60%.
为了解决传统深度学习模型推理速度慢、部署效率低的问题,人们也曾提出过YOLOv3-tiny[9],YOLOv4-tiny[10-11]等轻量化网络.但是,多个数据集上的测试结果证明,相比于原YOLOv3和YOLOv4网络,这些经过轻量化处理的网络会造成模型精度损失,准确率不高[11].因此,本文采用改进前后的YOLOv5网络进行对比训练,再将得到的模型用于交通目标检测的测试和仿真部署.
1 YOLOv5的介绍与改进
1.1 原始YOLOv5的结构
作为一阶段检测算法的典型代表,YOLO系列目前已经由Ultralytics公司发展到第五代YOLOv5[12].它可以通过调整网络的深度和宽度自由设定模型结构,兼顾了检测精度与速度,适合作为计算性能有限的设备的部署模型.原始YOLOv5的网络结构拥有输入层、骨干层、颈部层和预测层4个部分,如图1所示.
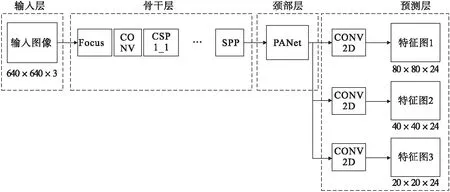
图1 原始YOLOv5的简要结构
本文所采用的输入图像像素尺寸为640×640和通道数为3,YOLOv5算法首先在输入层对输入图像进行预处理,包括基于遗传算法迭代的K-means聚类自动计算最佳anchor(锚框)尺寸,以及对训练集中4张随机图像进行四合一自适应拼接缩放的Mosaic数据增强.前者有利于预设的anchor更加贴近真实框,提升模型的拟合能力,后者能够提升模型训练速度和学习小目标特征的能力,学习到比单张图片更为丰富的特征信息.Mosaic数据增强在本文数据集上的效果如图2所示.
原始版本的YOLOv5骨干层包含Focus模块、SPP(spatial pyramid pooling,空间金字塔池化)模块和BottleneckCSP网络.Focus模块对预处理后的640×640×3图像采用切片和卷积操作,最终变成320×320×32的特征图.BottleneckCSP将输入特征图一分为二,分别进行卷积运算再通过局部跨层合并,即类似ResNet[13]的跳跃连接,目的是加快网络的计算,丰富网络提取到的特征.随后SPP模块的最大池化和张量拼接,则提升了模型的感受野.另外,骨干层3×3的卷积模块步长为2,与CSP(cross stage partial,跨阶段局部融合)模块交替排布对图像进行下采样,最后网络输出80×80,40×40,20×20三种像素尺寸的特征图进入颈部层.

图2 Mosaic数据增强的效果
颈部层的主要组成部分是由FPN(feature pyramid networks,特征金字塔网络)改进而来的PANet(path aggregation network,路径聚合网络)[14].PANet增加了卷积下采样部分,得到三种不同尺寸的特征图输入预测层.预测层特征图深度为3×(5+K),K是检测目标的类别个数.
在损失函数方面,YOLOv5预测层的损失函数分为cls,obj,box三部分,分别对应物体分类、置信度和检测框的损失,前两者采用BCE with Logit Loss,而算法本身为box提供了GIOU_Loss损失函数[15],相较于普通的IOU_Loss更能准确地描绘检测框的偏差程度,如式(1)和式(2)所示.式中A,B分别代表真实框和预测框,C为包含A,B的最小外接矩形.分别计算出三部分损失函数后求和即得到最终的总损失函数.
(1)
(2)
1.2 YOLOv5的改进
自YOLOv5的原始版本问世后,算法本身也在随着时间的推移不断发展,本文基于其v5.0版本作出了改进,主要集中在网络结构和损失函数两方面.首先是将原始的网络结构替换为更复杂的P6网络结构[16],如图3所示.
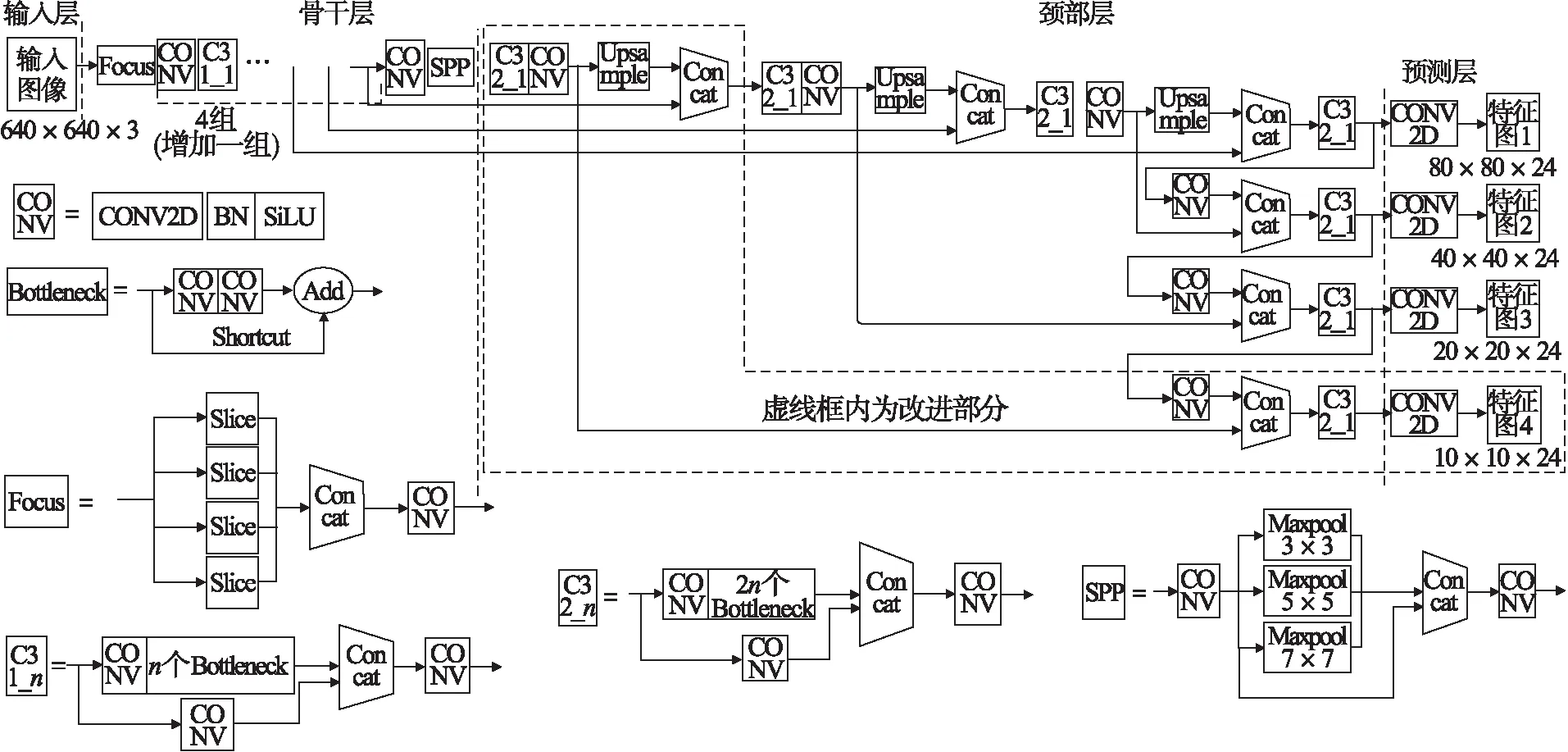
图3 改进后的YOLOv5网络结构
具体来看,网络中骨干层的BottleneckCSP模块已经被C3模块所取代,SPP模块中的5×5,9×9,13×13卷积核调整为3×3,5×5和7×7,卷积模块的激活函数由LeakyReLU(式(3))变成SiLU,后者借鉴了ReLU系列函数的思想,但更为平滑,如式(4)和式(5)所示.
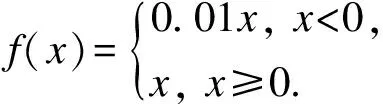
(3)
f(x)=x·sigmoid(x) ;
(4)
(5)
SPP模块前增加了一个卷积下采样模块,获得尺寸更小的10×10特征图,因此对应的颈部层中也需要增加一次上采样.最后,PANet自下而上的下采样部分增加1个10×10的特征图送入预测层,能够输出4种不同尺寸的特征图.特征图的种类越多,将图像划分的网格与预测的锚框数量也就越多,容易检测出尺寸较小或互相重叠的目标,在推理速度稍微降低的同时提升检测能力.另外,本文在计算损失函数的box部分中引入理论效果更好的CIOU_Loss来替换原有的GIOU_Loss,提升模型检测效果和鲁棒性,CIOU_Loss如式(6)~(8)所示.
(6)
(7)
(8)
式中:ρ(Actr,Bctr)是预测框和真实框的中心点欧氏距离;c为包含A,B的最小外接矩形的对角线长度;wA和hA代表真实框A的长和高;wB和hB代表预测框B的长和高.原有的GIOU_Loss在目标框完全包含相同大小的预测框时,无论预测框的位置如何变化,函数值不变.鉴于这一缺陷,CIOU_Loss增加影响因子v,考虑到2个框的相对位置、中心点距离、宽高比三种因素,能更为精确地反映模型训练时的损失情况.
2 实验的设置
2.1 数据集的准备
本文采用交通目标数据集KITTI作为算法测试的数据来源,该数据集由德国卡尔斯鲁厄理工学院和丰田美国技术研究院联合创办,通过车载摄像头和传感器,采集城市道路、高速公路、校园等多个复杂交通场景的真实交通图像,适合目标检测、光流、3D跟踪等计算机视觉任务的使用[17].数据集的标签细分为Car,Van,Truck,Pedestrian,Person_sitting,Cyclist,Tram,Misc以及Dontcare等若干类.本文选择的是其中的2D目标检测数据集,包含7 481张有标注的图像和7 518张无标注图像.由于交通环境下移动目标多为车辆和行人,为了降低轻量化模型的检测难度,不再细分车辆的种类和行人的姿态,将原数据集标签重新整理,“Van”“Truck”“Tram”标签合并到“Car”类,“Person_sitting”标签合并到“Pedestrian”类,忽略“Misc”和“Dontcare”两类.最终得到需要检测的“Pedestrian”“Cyclist”“Car”三类标签.然后重新划分KITTI数据集有标注的图像,得到训练集5 440张,验证集1 280张,测试集761张.
2.2 训练策略的改进
KITTI数据集除了7 481张有标注的图像之外,还有7 518张无标注的图像,为了进一步提升检测的准确性,可以将这部分图像进行充分利用,采用伪标签的形式加入划分好的训练集中.伪标签是机器学习中一种常见的半监督学习方法,其核心思想是使用大量无标注的数据使模型能够在监督学习之外学习到一定的额外信息,当预测的置信度超过一定的阈值(本文为50%)时,可以认为这一伪标签的标注结果正确,再与有标注的数据相结合,以提高模型在有标注的测试集上的表现.将原标签数据和预测正确的伪标签数据结合起来作为新的训练数据集再进行训练得到最终的检测模型.
2.3 训练方法与评价指标
本次实验采用AP(average precision,每一类目标的精度均值)和mAP(mean average precision,所有类别目标的平均精度均值)作为模型评价指标.每个模型的改进策略如表1所示,实验分别采用原始YOLOv5算法预训练权重YOLOv5s,以及改进后的预训练权重YOLOv5s6在KITTI数据集上进行训练,得到原始模型A和改进后的模型B.然后改变训练策略,使用伪标签策略以模型B为基础再次进行训练,得到最终训练模型C.最后划分好的测试集对3个模型进行对比测试,得到它们的评价指标和推理速度.为了验证改进YOLOv5算法损失函数的有效性,额外增加一组训练模型A1,该模型与原始模型相同,仅将损失函数的box部分替换为CIOU_Loss.
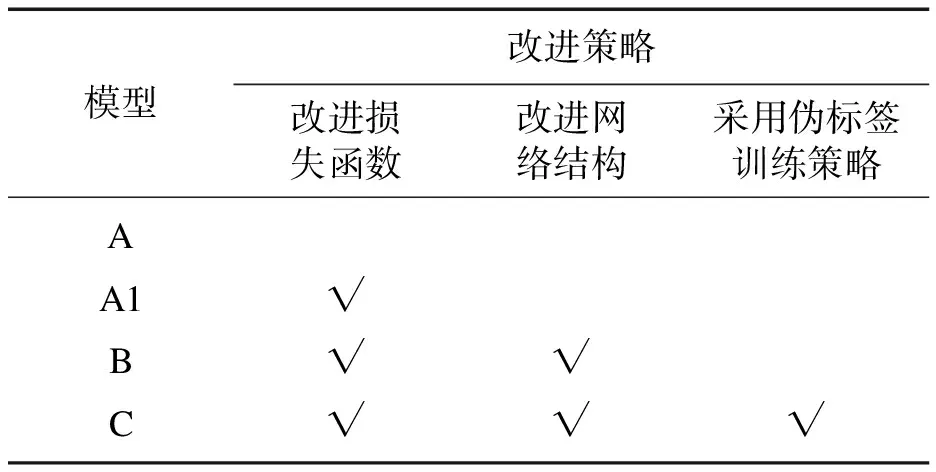
表1 每个模型的改进策略Table 1 Improvement strategies for each model
每次模型训练均采用SGD优化器,其余参数如下:图像batchsize(每批次训练量)为32张;迭代次数为400;动量因子为0.937;权重衰减系数为0.001.采用余弦退火策略动态调整学习率,初始学习率为0.1,IOU阈值设为0.5.
3 实验结果分析
本次实验的A,B,C三个模型训练过程的损失函数和mAP变化曲线如图4所示.
训练过程显示,迭代次数为400时,3个模型的训练集和验证集损失函数均达到最低,mAP达到最高且在一段连续过程中都不再有太大变化,可以视为完成了收敛.对训练后的模型测试每一类的检测精度均值AP和所有类的平均精度均值mAP,结果如表2所示.

图4 模型训练过程中mAP和损失函数的变化
表2的结果说明,在本文划分的KITTI交通目标测试集上,改进后YOLOv5模型B对比原始YOLOv5模型A的mAP提升了2.5%,在模型C采用伪标签训练策略后又提升了0.5%,两次共计提升3%.对行人和骑车人这两类较小的目标,检测精度的总提升分别达到了5.4%和3.5%,本文训练的YOLOv5检测模型在交通目标的检测上做到了平均精度和小目标检测精度的提升,证明算法和训练策略的改进是成功的.而YOLOv5算法本身对车辆等中大型目标检测效果较好,原始模型已经取得不错的检测效果,3个训练模型对车辆的检测精度大体相当的结果是可以接受的.改进损失函数的模型A1的mAP和行人、骑车人的检测精度等指标也比原始模型有所提升,说明算法网络结构和损失函数的改进都能使检测效果得到增益.
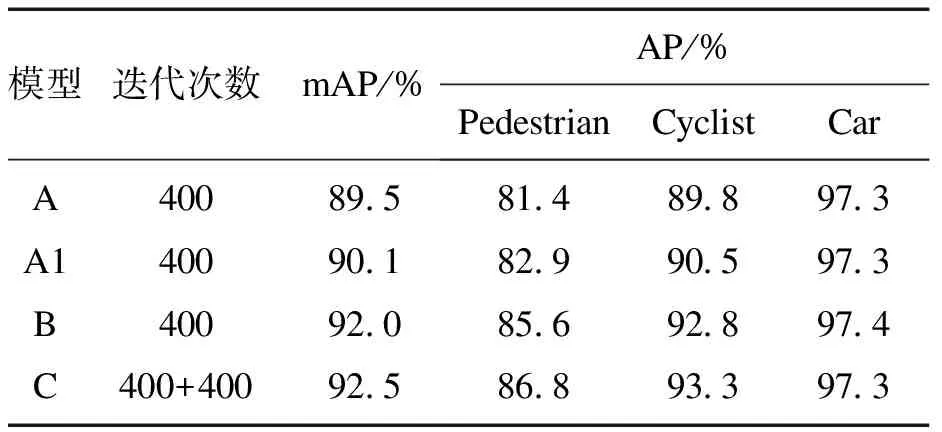
表2 模型测试结果对比Table 2 Comparison of model test results
本文的目标检测算法与其他经典的目标检测算法在KITTI数据集上的对比结果如表3所示,实验结果表明,相比Faster R-CNN,SSD和YOLOv3系列算法,本文采用的改进YOLOv5算法检测精度达到了一个更高的水平.

表3 改进YOLOv5与其他算法的测试结果对比Table 3 Comparison of test results between improved YOLOv5 and other algorithms
图5a显示模型在光照强度反差较大场景的检测结果,图中亮部的目标较小的车辆和骑车人,暗部的车辆都能被模型识别和定位.图5b是光照较弱的遮挡场景,模型检测出了互相遮挡的车辆、骑车人和被车辆遮挡的行人等目标,对于此类目标较多的场景没有发生漏检和误检.图5c存在被图像边缘遮挡的行人和车辆,还有互相遮挡的行人和骑车人,行人和骑车人目标特征有相似之处,模型能将它们准确定位且互相区分体现了其良好的检测性能,仅仅漏检远处1个极小的车辆目标.
从以上结果可以看出,经过改进的YOLOv5模型实际检测图像时不容易受不良条件影响,具有较好的鲁棒性.但是,仅仅训练出精准的模型是不够的,还需要将其移植到实际应用的嵌入式平台并且做到实时检测,方能体现出它的实用性.

图5 不同条件下的检测结果
4 模型的嵌入式移植与推理加速
4.1 Jetson Nano嵌入式平台介绍
训练模型的嵌入式设备采用NVIDIA Jetson Nano,相较于其他同类设备,其价格优势明显,并且体积更小,设备的布置更为便利.它配备了四核Cortex-A57 CPU、128核Maxwell GPU和4GB内存,使用集成CUDA、OpenCV、TensorRT等环境的NVIDIA JetPack开发组件,支持TensorFlow和Pytorch等常见的人工智能框架,支持CSI、USB等摄像头图像输入.本次模型部署采用10 W高性能运行模式.设备实物图如图6所示.
4.2 TensorRT的原理
TensorRT是 NVIDIA 公司推出的推理加速引擎,内部使用CUDA和C语言进行编程,适合应用于驾驶辅助等推理速度比较重要的目标检测场景.

图6 Jetson Nano实物图
TensorRT通过GPU对网络层进行水平和垂直整合来达到优化和加速的效果,优化过程没有改变模型参数量和网络底层的计算,只需要对计算图进行重构,就可以让模型高效运行.例如本文图1和图2的YOLOv5网络包含大量的卷积模块和张量合并,TensorRT可以将前者的卷积、BN正规化和激活三个步骤一次性融合完成计算,而张量合并的Concat层输入可以直接进入网络下一层,不再单独进行合并计算,减少了计算步骤和数据传输的时间.TensorRT的过程首先把Pytorch框架下训练的交通目标检测模型的.pt权重文件转化为.wts中间文件,再使用.wts文件构建用于推理的引擎(.engine)文件,使用推理引擎推理即可获得加速.
4.3 结果分析
本文从KITTI的原始数据集中选择了100张未经标注的连续图像进行复杂交通场景模型推理测试,在Jetson Nano平台模拟从摄像头逐帧读取需要检测的视频,结果如表4所示.
从表4可以看出,原始YOLOv5网络的模型A平均每张图像推理时间为163 ms,改进网络结构的模型B和C这一推理时间为195 ms,二者的推理速度相当于5~6帧/s,速度较慢.经过TensorRT加速,3个模型每张图像的推理时间在73 ms到83 ms不等,平均每张图像推理时间均为77 ms,约合13帧/s,图像推理速度大幅提高,能够满足检测实时性要求.另外,网络改进后的模型加速效果更明显,推理速度与体积更小的原始网络模型A相当,此前未经加速时推理速度会因为改进模型而下降的问题得到了解决.图7以图5a为例展示了原模型和改进后的模型经过推理加速后检测的画面效果,TensorRT加速使得目标种类的编号取代了名称和置信度,编号0,1,2分别代表Pedestrian,Cyclist和Car,画面更为简洁.二者推理生成的检测框几乎没有差异,不会造成检测精度损失.由此,本文在嵌入式平台仿真实现了实时的复杂场景交通目标检测,YOLOv5模型出色的检测能力也得到验证.

表4 TensorRT加速前后推理时间对比Table 4 Comparison of inference time before and after TensorRT acceleration ms

图7 TensorRT加速后模型的检测效果
5 结 语
为了实现复杂场景下的交通目标实时检测,本文提出一种基于改进YOLOv5的交通目标检测算法,采用更复杂的网络结构和更精确的损失函数,对训练过程采用伪标签的形式进行优化.在KITTI数据集上的训练和测试结果表明,经过本文方法改进的训练模型检测性能指标优于原始YOLOv5训练的模型,用于实际的交通目标检测任务中效果较好.鉴于将模型移植到Jetson Nano嵌入式平台后推理速度较慢,本文使用TensorRT对模型推理进行加速,不仅实现了复杂场景交通目标检测,检测速度也能满足实时性要求.后续工作可以尝试将摄像头与嵌入式平台连接并在真实交通环境下实时采集并处理图像或视频数据,以验证模型的泛化能力,还可以对宽度和深度更高的YOLOv5网络进行轻量化处理,将得到的模型与现有的YOLOv5s系列模型进行对比,发掘检测效果和速度更好的方案.
猜你喜欢
导航定位学报(2022年5期)2022-10-13
机械工业标准化与质量(2022年8期)2022-10-09
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
海峡姐妹(2018年3期)2018-05-09
中学生数理化·八年级数学人教版(2016年4期)2016-08-23
理科考试研究·高中(2016年9期)2016-05-14
Coco薇(2015年11期)2015-11-09
新高考·高二数学(2015年7期)2015-10-22
少儿科学周刊·少年版(2015年2期)2015-07-07
少儿科学周刊·儿童版(2015年2期)2015-07-07
