
基于分类规则挖掘算法的火电厂智慧化耗差分析系统设计
2022-08-12 09:30焦开明夏尊宇周亚男徐亚豹
工业仪表与自动化装置 2022年4期
焦开明,夏尊宇,周亚男,徐亚豹
(1.内蒙古大唐国际托克托发电有限责任公司,内蒙古 呼和浩特 010206; 2.中国大唐集团科学技术研究总院有限公司华北电力试验研究院,北京 100040;3.北京博望华科科技有限公司,北京 100045)
0 引言
由于火电行业的迅猛发展,导致能源的需求量增长强劲。但随着能源的日益减少,节能降耗成为电力生产的一项关键任务[1]。耗差分析以煤耗作为指标,是指导火电厂优化运行的理论依据,即将火电厂机组各运行参数的实际值与目标值间的偏差状况反映到煤耗偏差上[2],利用机组的各个运行参数的耗差反映火电厂机组的运行状况,协助运行人员及时调控机组的运行,确保火电厂优化运行[3]。
近年来,国内外众多学者在耗差分析方面做出了大量研究,如郑中原等[4]提出的基于云平台的耗差系统,该系统通过云平台的采集与主站系统实现节能减排,但该系统涉及部门多,任务繁重,工作效率不高;又如孙建梅等[5]提出的基于SE-DEA的火力发电厂耗差系统,该系统存在建模过程繁琐,挖掘的各个能耗指标不完整的缺陷。
数据挖掘是指从海量的不完全数据中提取出人们需要的、隐藏的信息的过程,数据挖掘涉及的领域很多,而分类规则挖掘即是其中的一种[6],分类规则挖掘算法能够依据隐藏在数据集中的某些数据的特征属性,对每个类进行精准描述,实现分类。
因此,该文设计基于分类规则挖掘算法的火电厂智慧化耗差分析系统,对火电厂耗差进行有效分析,实现火电厂优化运行。
1 火电厂智慧化耗差分析系统设计
1.1 系统总体结构
图1为火电厂智慧化耗差分析系统总体结构。火电厂智慧化耗差分析系统由数据单元、业务单元块、应用单元组成。在数据单元中,系统在信息管理MIS与实时数据采集DAS数据库内获得火电厂能耗实时数据,利用OPC(过程控制对象链接与嵌入)技术[7],传送到数据采集容错模块中进行火电厂能耗数据容错处理后,再通过数据提取模块提取火电厂能耗数据,经数据处理模块处理后,传输到业务单元的机组性能计算模块中,利用增量式遗传算法的分类规则挖掘火电厂能耗数据,将获取的火电厂能耗数据分类结果输入到耗差分析数据库服务器中进行耗差分析,通过TCP/IP协议将耗差分析结果传输至应用单元,在应用单元中利用浏览器
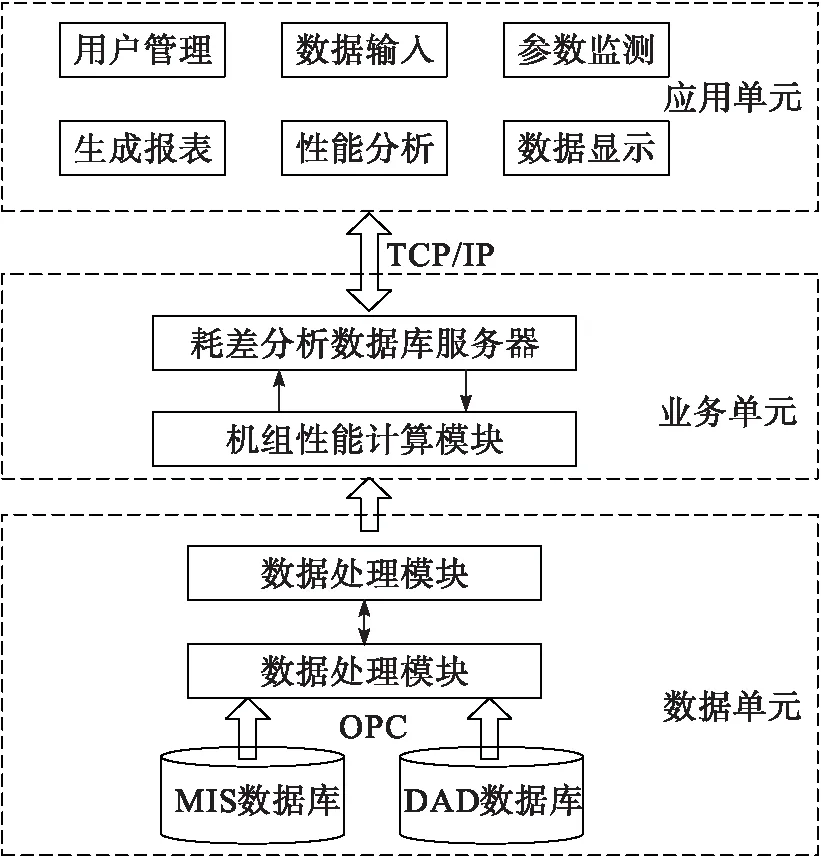
图1 系统总体结构图
进行浏览查询,并完成用户管理、报表生成、性能分析、参数监测等功能。
1.2 数据采集容错模块
图2为系统数据单元的数据采集容错模块结构图。

图2 数据采集容错模块结构
数据采集容错模块结构由主节点、分布式协调节点、配置节点与工作节点构成。其中,主节点对数据采集容错模块进行任务分配、能耗数据更新、状态监控、配置检测等管理。工作节点可对数据节点间的火电厂能耗数据传输、任务处理单元的启停、监测等具体任务进行执行[8];配置节点以插件、任务、更新能耗数据等为主,数据采集容错模块可利用对配置节点的监视实时获得最新的火电厂能耗信息数据,分布式协调节点可作为数据采集容错模块元数据的存储节点,可利用ZooKeeper的监听与通知机制[9],使数据采集容错模块对更新的火电厂能耗信息数据快速响应。
1.3 火电厂机组性能计算模块
图3为系统业务单元火电厂机组性能计算模块结构图。

图3 火电厂机组性能计算模块结构
火电厂机组具有非常复杂的热力系统结构,包括试验与煤质数据转换、锅炉与汽机性能计算模块三部分。火电厂机组局部参数与锅炉、汽机等设备的变化可产生煤耗偏差,当机组参数与锅炉、汽机设备变化时,会导致抽汽份额产生变化,可利用等效焓降法运算机组的煤耗偏差,此外,汽机中的凝汽器系统能损也可通过循序渐进耗差分析运算。当被监测的热力试验参数、锅炉耗差参数与汽机耗差参数与其额定值相偏离时[10],采用标准煤耗率的增加值代表火电厂机组经济性的影响,使运行人员实时掌握热力系统内不同参数、设备对火电厂机组经济性的影响,采取及时有效的方法确保机组处于最优运行状态。
1.4 基于增量式遗传算法的分类规则挖掘火电厂能耗
系统业务单元火电厂机组性能计算模块采用增量式遗传算法的分类规则,挖掘火电厂能耗数据,并采用SMOTE算法填补缺失火电厂能耗数据,为耗差分析数据库服务器的火电厂能耗数据耗差分析提供数据基础。
正常情况下,火电厂能耗数据库内会有源源不断的新的能耗数据输入,能耗数据规则集随着能耗数据集的不断更新而不断变化,针对该无限更新过程,遗传算法对通过增量方式得到的新能耗数据具有增量式的演变能力。
原有的火电厂能耗知识在增量式火电厂能耗数据挖掘时可进行保留,只挖掘新的火电厂能耗数据中的能耗知识模式[11],通过增加、删除、修改原有能耗知识,获得精度较高的能耗知识。
训练实例集选取火电厂能耗数据库内的能耗数据,采用遗传算法搜查到一个最优火电厂能耗数据规则集;火电厂能耗数据由火电厂耗差分析系统进行接收,通过当前最好的火电厂能耗数据规则集进行分类。若对火电厂能耗数据分类错误,则把原始能耗数据集与增量能耗数据同时当作训练实例集,这两个能耗数据集的最优能耗规则集可重新采用遗传算法进行搜查遮盖,与前一次遗传算法的差别在于,已有的最优能耗数据规则集已存在如今的遗传算法原始群体内[12]。若对火电厂能耗数据分类正确,则无需采用遗传算法。依据以上方法,针对下次需要接收的增量火电厂能耗数据,可连续采用新获得的火电厂能耗数据规则集对其进行分类。增量式遗传算法流程为:
步骤1 依据火电厂能耗知识,明确其特征属性与类别属性集合A,在火电厂能耗数据库内构建火电厂能耗数据集R,且R由A构成;
步骤2 通过清理能耗数据,离散连续属性操作预处理R,获得RD;
步骤3 在火电厂能耗数据库内将初次采用遗传算法1产生的一个最优能耗数据规则集进行保存;
步骤4 再次采用遗传算法2约简最优能耗数据规则集,约简之后的能源数据规则集依然保存在火电厂能耗数据规则库里[13-14];
步骤5 判断火电厂能耗数据集是否需要更新,若否,则转至步骤11;若是,则操作步骤6;
步骤6 对增量能耗数据集进行读入,并对其清理、离散化处理后获得ΔRD数据集;
步骤7 分类ΔRD,可采用火电厂能耗数据规则库内的最优能耗数据规则集,进行火电厂能耗数据分类,可一次完成则按步骤6进行操作,操作步骤6之前需合并ΔRD与原RD,获得新的能耗数据集RD,否则,按步骤8进行操作;
步骤8 采用修改之后的蚁群算法1,原最优火电厂能耗数据规则集由新产生的最优能耗数据规则集替代;
步骤9 采用遗传算法2,原约简能耗数据规则集由约简之后的能耗数据规则集替代;
步骤10 转步骤5;
步骤11 将约简之后的火电厂能耗数据规则集进行输出,获取火电厂能耗数据挖掘结果。
由于上述获得的火电厂能耗数据挖掘结果,易受到环境等因素的影响,导致火电厂能耗数据存在缺失的情况,因此,采用SMOTE(Synthetic Minority Over-sampling Technique)算法填补缺失数据,使火电厂能耗数据更加完整。SMOTE算法为:
用Rs描述火电厂能耗数据集R中的少数类,用x描述Rs中的火电厂能耗数据样本,运算x到其他少数类火电厂能耗样本的欧式距离,获得最小距离的近邻火电厂能耗样本,且该样本有k个。用w描述采样倍数。对于每个x,在其k个近邻中,任意选择w个火电厂能耗数据样本,记为x1,x2,…,xw。线性随机插值可在x与xi(i=1,2,…,w)间实现,构建新的少数类火电厂能耗数据样本ri(i=1,2,…,w)。
ri=x+rand(0,1)xi-rand(0,1)x,i=1,2,…,w
(1)
公式中,在大于0小于1之间的一个随机数用rand(0,1)描述。用Rt={r1,…,rw}描述将新生成的少数类火电厂能耗数据样本,将Rt={r1,…,rw}与R进行合并,获得新的比较平衡的火电厂能耗数据训练集。利用SMOTE算法插值计算缺失的火电厂能耗数据近似值后采用多重填补思想计算填充值。
设缺失的火电厂能耗样本x中,火电厂能耗数据缺失的维度为q1,q2,…,ql,其中l=m-j且{p1,p2,…,pj}∪{q1,q2,…,qm-j}=[1,m]。
x中不缺失与缺失的火电厂能耗数据属性构成的向量分别用x′与x″描述,且x′=(x(p1),x(p2),…,x(pj)),x″=(x(q1),x(q2),…,x(qm-j)),则{x(p1),x(p2),…,x(pj)}∪{x(q1),x(q2),…,x(qm-j)}={x(1),x(2),…,x(m)}。

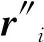
(2)
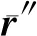
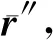
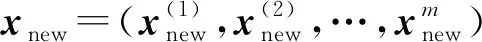
通过以上采用SMOTE算法填补缺失数据过程,获得更加完整的火电厂能耗数据。
2 实验分析
为验证该文系统对火电厂耗差的分析效果,实验选取某火电厂680 MW燃煤发电机器为耗差分析对象,利用C++BUILDER6.0、SQL Server 2019数据与Matlab7.0共同开发火电厂智慧化耗差分析系统。
实验选取2000个该火电厂的能耗数据,以及700个增量能耗数据,采用遗传算法与该文系统采用的增量式遗传算法分别对原火电厂能耗数据集与加入增量能耗数据后的火电厂能耗数据集进行能耗数据挖掘,统计不同原始能耗数据量下,加入不同大小增量能耗数据时,这两种遗传算法的挖掘性能,结果如图4所示。
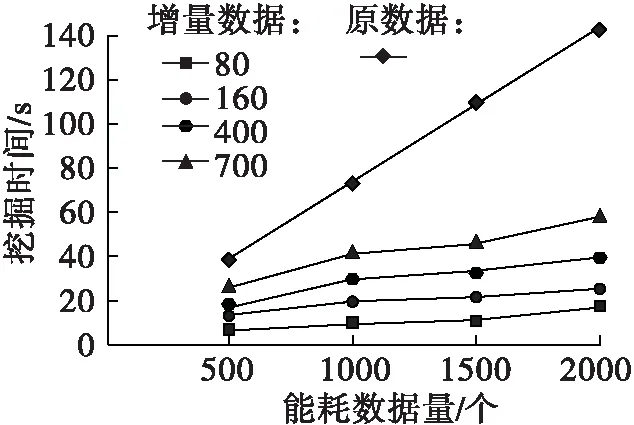
图4 挖掘性能结果
由图4可看出,采用遗传算法挖掘原能耗数据集所需时间随着火电厂能耗数据集的增大而增长,当火电厂能耗数据分别为500个与2000个时,遗传算法的挖掘时间分别为39 s与120 s;由于该文系统采用的增量式遗传算法基于原数据集挖掘结果,当增量数据比较小时,原挖掘结果可提高增量式遗传算法的收敛速度,如当增量能耗数据为80,160时,采用增量式遗传算法挖掘时间远远小于遗传算法所需时间,随着增量能耗数据集的不断增大,挖掘时间虽呈增长趋势,但增长幅度较小,如当增量能耗数据为80个与700个时,该文系统采用的增量式遗传算法最长挖掘时间分别为18 s与60 s,两者仅相差42 s。实验表明,该文系统采用的增量式遗传算法可有效挖掘能耗数据集,且其挖掘时间短、收敛速度快。
表1为该火电厂2020年11月与12月份在纯凝工况、额定供热工况、火电厂抽汽供热工况、火电厂热泵+抽汽供热四种工况下的能耗与耗差分析数据。
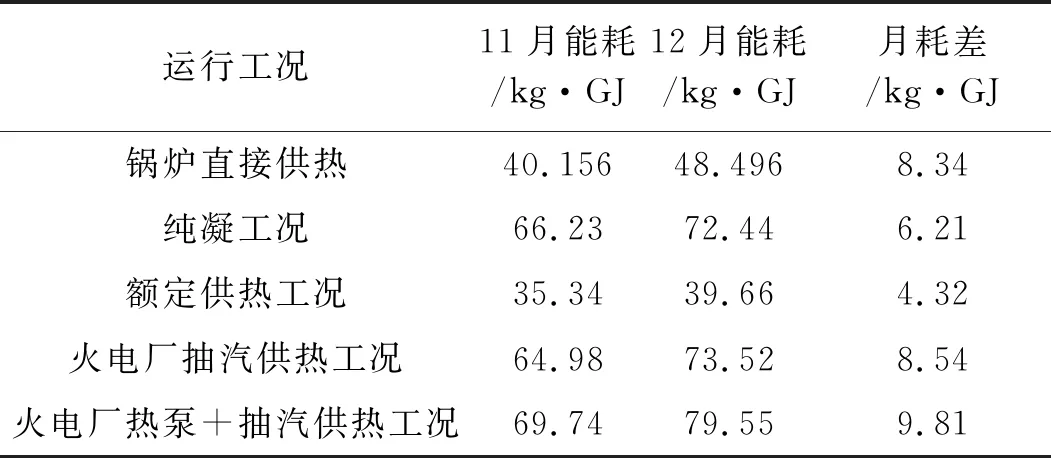
表1 火电厂的能耗与月耗差分析结果
由表1分析可得,采用该文系统可得出四种工况下各个月份的能耗与耗差。其中,火电厂热泵+抽汽供热工况月耗差最大,远高于纯凝工况与额定供热工况,为火电厂智慧化耗差分析提供有利依据。
实验分别选取40%、80%与100%三种负荷额定(ECR)工况对火电厂机组各运行参数变化引起的耗差进行计算,验证该文系统在不同负荷额定工况下的火电厂机组各个运行参数变化引起的耗差统计结果,如表2-4所示。
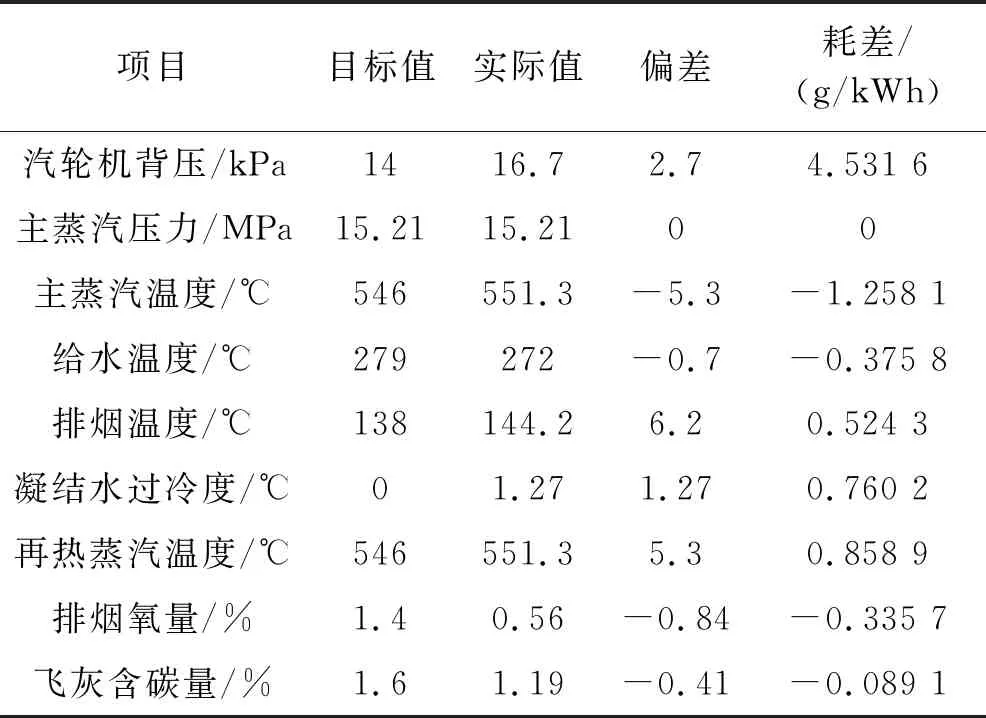
表2 100%ECR工况(680 MW)耗差计算结果
由表2可看出,100%ECR工况下,该火电厂机组大部分运行参数实际值和目标值间的偏差比较小,对耗差的影响也不大,说明机组具有良好的运行状况与极高的热经济性。但汽轮机背压、排烟温度、凝结水过冷度,再热蒸汽温度这些参数导致耗差数值增加较大,尤其是汽轮机背压增加了4.531 6 g/kWh的耗差,故当该火电厂在100%ECR工况下运行的过程中,需对上述耗差增加数值较大的参数进行重点监测,尤其需重点监测汽轮机背压。
由表3可看出,80%ECR工况下,机组部分实际值与目标值间具有较大的偏离幅度,机组在较低的水平下运行,热经济性低。汽轮机背压耗差由100%ECR工况下的4.531 6 g/kWh降为1.625 8 g/kWh,其耗差虽仍然很高,但其下降幅度较为明显;机组主蒸汽温度、排烟温度与排烟氧量分别使耗差增加了1.012 1 g/kWh、1.377 1 g/kWh、1.602 1 g/kWh,因此,在80%ECR工况下,应对主蒸汽温度、排烟温度与排烟氧量的运行水平进行重点监测。
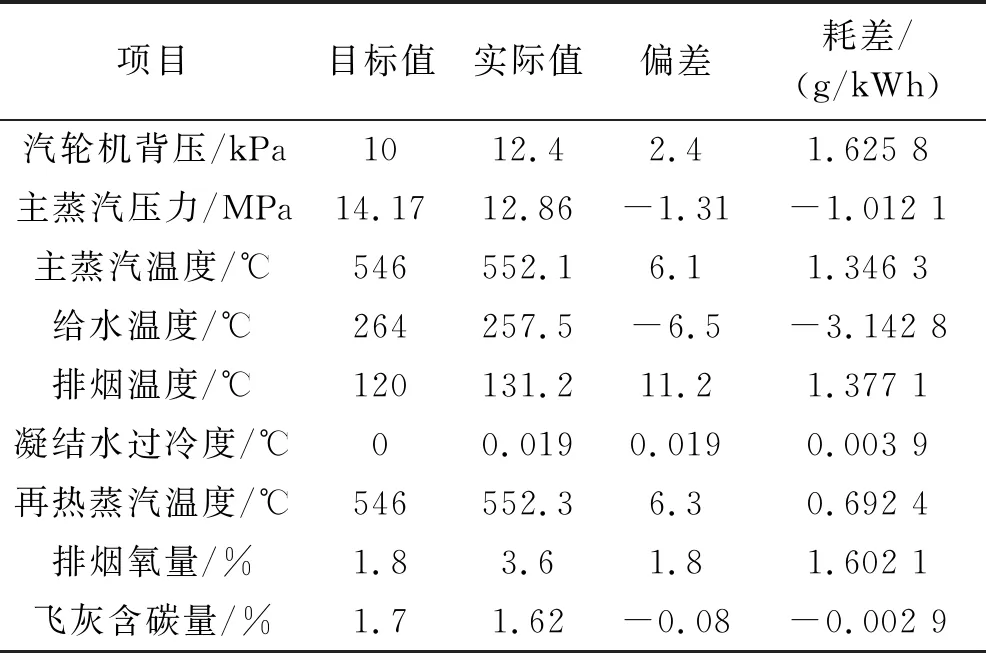
表3 80%ECR工况(544 MW)耗差计算结果
由表4可看出,40%ECR工况下,该火电厂机组绝大部分运行参数实际值和目标值间的偏差较大,机组热经济性变得更低。

表4 40%ECR工况(272 MW)耗差计算结果
综合表2~表4结果可得,机组在高负荷运行时,具有较好的运行状况,在火电厂机组实际运行调控过程中,需采用不同的调控方法应对不同的负荷情况,确保机组具有较好的运行状况及较高的热经济性,实验表明,该文系统可有效分析火电厂耗差变化情况,使运行人员对火电厂机组的运行状况做到实时了解,实现火电厂经济运行。
通过该文系统界面查看主蒸汽温度耗差计算结果,如图5所示。
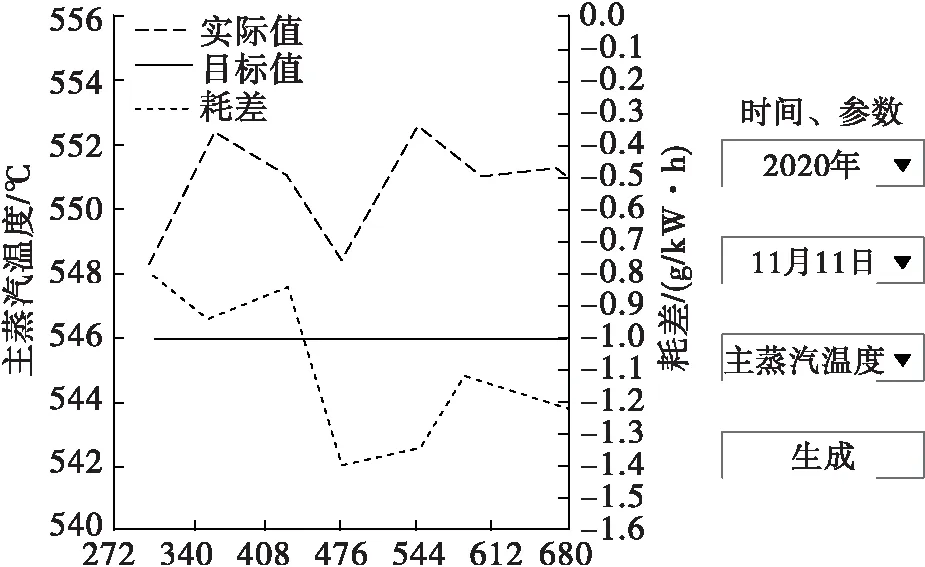
图5 主蒸汽温度耗差计算结果
由图5可以看出,该文系统将主蒸汽温度耗差计算结果以曲线的方式通过界面图显示出来,使运行人员更加直观便捷地监测到主蒸汽温度在不同负荷下对耗差的影响过程。实验表明,该文系统可有效分析火电厂耗差变化情况,并将分析结果通过界面形式清晰地展现出来,使运行人员有针对性的对火电厂机组各个运参数的耗差进行监测调控,实现火电厂机组的优化运行。
3 结论
该文设计基于分类规则挖掘算法的火电厂智慧化耗差分析系统,经实验验证,该文系统的优势为:
(1)采用的增量式遗传算法可有效挖掘火电厂能耗数据集,且其挖掘时间短、收敛速度快;
(2)可有效分析不同工况下的火电厂各月份的能耗与耗差,为火电厂智慧化耗差分析提供有利依据;
(3)通过该系统可有效分析不同负荷额定工况下的火电厂耗差变化情况,确保运行人员实时了解火电厂机组的运行状况,实现火电厂经济运行;
(4)该系统通过界面形式将主蒸汽温度耗差计算结果进行清晰的展现,使运行人员更方便快捷地监测到火电厂机组各个运参数的耗差,实现火电厂机组的优化运行。
猜你喜欢
消费电子(2022年6期)2022-08-25
北京航空航天大学学报(2022年5期)2022-06-06
当代陕西(2022年6期)2022-04-19
当代水产(2021年8期)2021-11-04
汽车工程(2021年12期)2021-03-08
中学生数理化·中考版(2019年9期)2019-11-25
活力(2019年22期)2019-03-16
活力(2019年22期)2019-03-16
电子制作(2019年24期)2019-02-23
山东工业技术(2016年15期)2016-12-01
