
整车大数据存储与计算优化实现
2022-08-17 10:04韦统边司帅锋温丽梅唐莹苏德
电子测试 2022年14期
韦统边,司帅锋,温丽梅,唐莹,苏德
(上汽通用五菱汽车股份有限公司广西汽车新四化重点实验室,广西柳州,545007)
1 整车大数据存储与计算
当前汽车成为大部分家庭生活必须品。电动化、网联化、智能化和共享化成为新一代汽车的基本要求,汽车上数百个传感器在不间断的采集数据,这些数据的传输和利用蕴藏着巨大的价值,在2030年我国汽车保有量将增长到4.3亿辆,每辆智能网联汽车每秒可产生8.6MB数据[1]。海量数据的传输、存储和计算成本之间的均衡成为当前最急需解决的问题之一。
本文将基于整车大数据目前状况,简要说明常用的数据存储格式优缺点,选择Parquet数据格式原由,并结合数据归类和归档策略,总体上实现存储压缩和计算性能提升的目标。总体上实现存储压缩和计算性能提升的目标。
2 数据存储格式
2.1 Txt数据格式
Txt是微软在操作系统上附带的一种文本格式,主要是用于存储文本信息,此处我们利用txt格式文件按行存储车辆上传的加密数据,所有车辆信号项以及对应的值都以十六进制进行传输,需要使用时再用制定好的规则把十六进制数据解析为明文数据。
优点:没有对应的解密规则无法将数据解密,数据的安全性高。压缩比高,节省网络带宽,因为同样位数的十六进制能比十进制和二进制表达的信息更多。
缺点:当使用数据时必须先解析为明文数据,再进行数据分析,若需要分别实现多个算法,会多次读取源数据,导致数据解析工作重复进行,即使读取一个信号项的值,也必须遍历所有数据后再解析出指定信号项的值,重复解析工作耗费大量的集群计算资源。
应用场景:低频归档数据。
2.2 Json数据格式
一种按行存储的轻量级的数据交换格式,采用完全独立于语言的文本格式,包含对象(键值对)和数组(包含多个对象)这两种结构[2]。由字符串、数字、对象和数组组成的数据结构都可以通过Json来表示,其中对象是有一对大括号{}包裹起来的内容,数据结构为多个{key1:value1,key2:value2,…}形式的键值对,key为对象的属性,value为对象的值,key一般用整数和字符串表示,value可以是Json支持的任意数据类型;而数组是由中括号[]包裹起来的内容,数据结构为 [“java”, 123, “vb”, ...] 的索引结构,同样数组的值也可以是任意数据类型。整车数据解析后转为JSON数据格式再按行存储,文件格式可以是json和txt等。
优点:数据读取速度快,一次解析多次使用,大量节省数据重复解析的时间;按需读取信号项值,省去逐个遍历信号项的时间。
缺点:占用存储空间大,因为每一行数据都重复存储相同的key值,以及大量的冒号、双引号、大括号和逗号等,数据冗余问题较为严重。
应用场景:数据量低于百万级别系统。
2.3 ORC数据格式
一种非单纯的列式存储格式,ORC数据格式遵循“先对行分组,再按列存储”的理念,首先会按行组去分割整个数据表,每一个行组内再进行按列存储,以strip为逻辑单位分为行组,每一个逻辑单位的大小一般与HDFS的block大小一致,保存了每一列的索引和数据,这可以保证逻辑单位内所有行都能保存在一个集群节点上;逻辑单位内的数据再按列存储。这样可以保证读取多列数据时不会出现跨节点通信组装元组的情况[3]。
ORC数据格式读取是从文件的尾部开始,第一次读取16KB大小的数据,尽可能将元数据信息和文件结构信息读入内存,至此数据读取初始化完毕。之后就可以通过元数据信息指定需要读取的列编号,如果不指定列编号则默认读取全部列。同时ORC文件是自描述的,它的元数据使用Protocol Buffers序列化,使用两级压缩机制,首先将一个数据流使用流式编码器进行编码,然后使用可选的压缩器对编码后的数据进一步压缩,达到降低存储空间的目的。
优点:具有极高的压缩比,并且文件是可分割的,可支持更高的任务并行度。
缺点:对多层数据嵌套结构支持不够友好,在使用多层数据嵌套结构时性能和空间损失较大。
应用场景:数据结构较为简单的大数据集群。
2.4 Parquet数据格式
一种以二进制方式存储的列式存储格式,对多层数据嵌套结构支持比较友好,它的文件不可直接读取和修改,它的文件也是自解析的[4]。Parquet数据格式主要分为三层,遵守自下而上的交互方式,最上层为数据存储层,这层定义Parquet的文件格式/类型,包括原始类型定义、page类型、编码类型和压缩类型等;中间层为对象转换层,这层作用是完成其他对象模型与Parquet内部数据模型的映射和转换;最底层为对象模型层,该层定义如何读取Parquet文件的内容,并对外提供接口,实现java对象和Parquet文件的转换。Parquet的存储模型主要由行组(Row Group)、列块(Column Chuck)、页(Page)组成,Row Group:将数据水平分割划分为行组,默认行组大小与HDFS block块大小一致,保证一个行组会被一个Mapper处理,Column Chuck:行组中的每一列保存在一个列块中,每一个列块只包含一种数据类型的数据,并且不同列块可以使用不同的压缩算法,Page:Parquet是按照块页方式去存储数据,每个列块包含多个页,页是最小的编码单位,同样不同的页可以用不同的编码方式。同时在ORC的基础上采用Striping/Assembly压缩算法,通过该算法,Parquet可使用较少的存储空间表示复杂的嵌套格式。
优点:支持的系统多,数据压缩比高,数据使用复杂的嵌套格式时占用存储空间较少。
缺点:压缩比没有ORC数据格式高。
应用场景:数据为复杂嵌套格式的大数据集群。
2.5 数据格式对比
列举的数据格式各项指标对比结果如下[5]:

数据格式指标 Text Json ORC Parquet压缩比 低 极低 高 较高ACID 不支持 不支持 支持 不支持UPDATE操作 不支持 不支持 支持 不支持索引 不支持 不支持 粗粒度索引 粗粒度索引Impala、Drill、Spark、Hive单表查询耗时 — — 9t 10t支持平台 Hdfs Hdfs Spark、Hive
综合以上对比结果,Parquet更适合我们当前大数据业务场景,因为ORC和Parquet查询性能接近,但是Parquet支持更多的平台,方便后续引入其他大数据组件。
3 基于Parquet数据格式存储与计算优化实现
3.1 整车大数据数据流
利用kafka作为消息缓存队列,加密数据全都暂存HDFS,一天数据存入一个文件中,凌晨时解析数据并转为Parquet数据格式,Parquet格式数据用于数据分析,不常使用的加密数据转存备用HDFS中,详情请看图1。

图1 整车大数据数据流
3.2 Parquet文件存储规则
为提高Parquet格式数据计算并行度,每一天数据将划分为多个文件进行存储,对文件存储结构制定如下规则:
(1)解析后数据分类存储:解析后的数据按/车型/采集日期/压缩算法_时段_from_数据接收日期/Parquet文件目录结构进行存储,无法区分车型的车辆统一存储到车型为UNKNOWN的文件夹下。
(2)清洗异常数据:过滤采集时间异常的数据,例如:过滤掉年份不属于2019年至当年年份的数据 ,过滤掉月份不属于1月至12月的数据,过滤掉日期不属于1日至31日的数据,过滤掉时段不属于0时至23时的数据,过滤掉分和秒不属于0至59的数据。
(3)文件大小限制单个Parquet文件大小不允许超过512M,并且同一个文件夹下不允许有多个名称相同,且文件大小都小于256M的文件出现,如果有要求把小文件合并为大文件。
3.3 数据压缩算法实现
整车大数据Text转Parquet压缩算法实现如下:
(1)按行读取Text文件,讲数据转为便于计算的RDD数据集。
(2)将数据解析为key-value形式,key为采集的信号项名称,value为信号项值。
(3)过滤采集时间异常的数据。
(4)对过滤后的RDD数据集分组,分组key为车型和数据采集日期拼接的字符串,例如:SUV20211111,表示该条数据于2021年11月11日采集的SUV车型数据,value为过滤后的RDD数据集。
(5)遍历分组后RDD数据集,根据key生成数据文件存储路径,将RDD数据集转为DataFrame数据集,通过控制每个文件数据条数来控制每个文件的大小,最后通过DataFrame的coalesce方法控制此次分组生成的Parquet文件个数。
3.4 基于Spark数据分析优化
基于现有的Parquet格式数据,我们要实现一个统计功能,统计晚高峰期(18时-19时)每一个时段数据上传的条数,通过同比每个时段数据量可分析出集群是否发生过数据延迟问题。现有的样例数据8451条,样例数据如图2和图3所示。

图2 样例数据
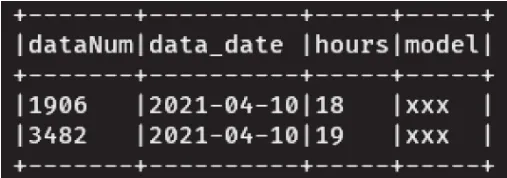
图3 输出结果图
用于统计的代码如下:
(1)初始化 spark 环境


(2)读取Parquet格式文件数据

(3)将DataFrame数据缓存,防止后续多次Action操作导致多次加载DataFrame数据
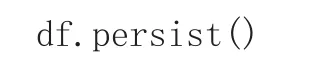
(4)利用列式存储优势,按需选择需要统计的字段

(5)根据条件过滤掉非高峰期时段的数据

(6)统计每个日期每个时间段数据条数

(7)释放缓存的DataFrame
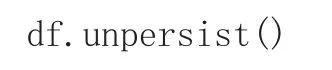
最终输出结果如图3所示。相比传统的按行分析数据,列式存储Parquet可按需筛选字段,极大减少用于读取数据的资源开销,而且可使用近似Sql语法去分析数据,极大减少数据分析的工作量,
4 结束语
本文介绍一种基于Parquet数据格式实现整车大数据存储与计算优化,减少了数据存储成本,同时数据分析速度提升,为企业实现降本增效的根本目的。
猜你喜欢
空军工程大学学报(2021年4期)2021-09-23
现代电子技术(2020年21期)2020-12-07
科学与财富(2017年33期)2017-12-19
电影文学(2017年24期)2017-11-16
金融经济(2017年7期)2017-07-15
数字技术与应用(2017年3期)2017-05-17
电脑知识与技术(2017年6期)2017-04-26
科技与创新(2016年17期)2016-11-04
大众理财顾问(2016年9期)2016-10-11
电脑知识与技术(2014年13期)2014-07-18
