
基于FPGA的卷积神经网络加速优化方法
2022-08-22 15:38林朋雨
计算机仿真 2022年7期
林朋雨,郭 杰*
(1. 西安电子科技大学综合业务网理论及关键技术国家重点实验室,陕西 西安 710071;2. 西安电子科技大学通信工程学院,陕西 西安 710071)
1 引言
卷积神经网络是一种多层感知器,对图像的倾斜、比例缩放和平移等形式的变形具有较高的适应度[1]。卷积神经网络的结构与生物神经网络结构相似,但降低了权值的数量和网络模型的复杂度[2]。在卷积神经网络中图像可以直接作为输入,解决了传统识别算法中数据重建和特征提取过程中复杂度高的问题[3]。卷积神经网络结构近年来被广泛地应用在图像搜索、视频监视、模式识别和机器视觉等领域中[4]。在上述背景下对卷积神经网络进行加速优化具有重要意义。
谢斌红[5]等人提出基于流合并与剪枝的网络加速优化方法,该方法减去模型内部每层中存在的冗余参数,将重要的层与非重要的层在模型结构上进行流合并,通过重新训练实现卷积神经网络的加速优化,该方法没有构建卷积神经网络的前向传播模型,导致资源在卷积神经网络中浪费严重,存在资源消耗率高的问题。方程[6]等人提出基于GPU的网络加速优化方法,该方法在GPU运行过程中通过直接系数卷积算法进行加速,处理稀疏数据,用稠密向量和稀疏向量的内积运算代替卷积运算,在GPU平台中实现卷积神经网络的加速优化,该方法没有分析卷积神经网络的前向传播结构,导致卷积神经网络中的冗余数据较多,存在网络计算量大的问题。
FPGA具有开发周期短、灵活可配、计算资源丰富的特点,为了解决上述方法中存在的问题,提出基于FPGA的卷积神经网络加速优化方法。
2 卷积神经网络前向传播结构分析
基于FPGA的卷积神经网络加速优化方法构建卷积神经网络前向传播模型,利用传播模型分析卷积神经网络前向传播结构,包括卷积层、池化层、激活函数和填充,为卷积神经网络的加速优化提供相关依据。
1)卷积层
卷积核和卷积层的输入在图像处理中一般情况下都是三维的[7]。可以通过多个二维的k×k卷积核与多幅二维的输入特征图相乘累加得到二维输出特征图。针对输入特征图对应的卷积,多组不同的三维卷积核可以得到对应的二维输出特征图OUTj
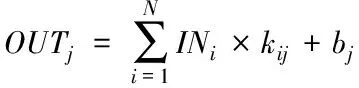
(1)
式中,OUTj代表的是第j个输出特征图;kij代表的是输出特征图对应的卷积核;INi代表的是第i个输入特征图;bj代表的是输入特征图对应的偏置。
输入图像与输出图像之间存在的尺寸,以输入特征图的高H为例,符合下述公式
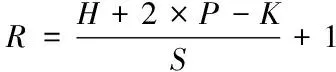
(2)
式中,R代表的是输出特征图对应的高;S代表的是卷积框滑动步长;P代表的是填充单位。
通过M组k×k×N卷积核之间的乘累加计算,针对N幅H×L尺寸的输入特征图,可以得到M个二维输出特征图,尺寸为R×C。卷积核的数量与输出特征图的数量相同,通道数通常可以用N的数量进行表示,通常情况下卷积核与特征图的通道数都是相同的[8]。
2)池化层
池化属于卷积操作,也被称为下采样。经过卷积层运算后,卷积神经网络中特征图数量不断增加,直接将其输入网络的下一层中会导致计算量过大的问题,为了解决上述问题[9]。基于FPGA的卷积神经网络加速优化方法池化处理输入数据,降低图片对应的分辨率,将分辨率较低的图像输入卷积神经网络中,降低了卷积神经网络的复杂度。
输入尺寸与输出尺寸之间符合下式
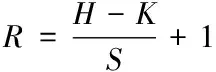
(3)
式中,S代表的是池化框对应的移动步长;K代表的是池化框对应的尺寸。
3)激活函数
在隐藏层中激活函数占据重要地位,输入和输出在卷积计算过程中属于线性加权的线性关系[10],常用的激活函数如下:
Sigmod 函数的表达式如下
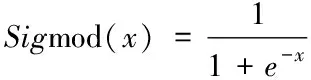
(4)
与Sigmod 函数类似,tanh 函数对卷积计算结果进行了压缩处理,tanh 函数的表达式如下
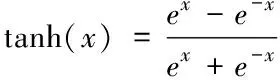
(5)
ReLU函数计算速度较快,在计算过程中不存在复杂的指数计算,ReLU函数表达式较为简单
ReLU(x)=max(0,x)
(6)
4)填充
填充按照行或列对称的形式将零元素增加到特征图的边界中。
3 基于FPGA的卷积神经网络加速优化
基于FPGA的卷积神经网络加速优化方法根据卷积神经网络前向传播结构利用FPGA对卷积神经网络进行加速优化。FPGA的计算框架如图1所示。
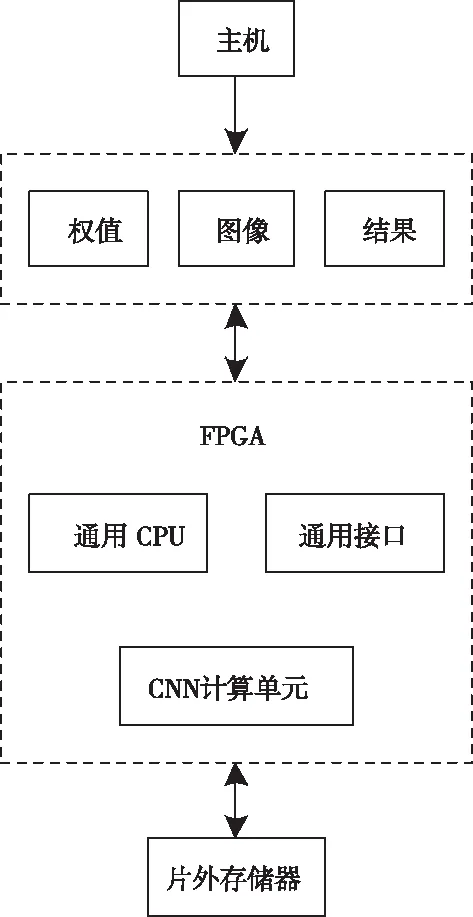
图1 FPGA加速器整体框架
3.1 卷积层并行加速可行性分析
运算方式在每个卷积窗口中都是相同的,第m个通道在卷积输出特征图中满足下式
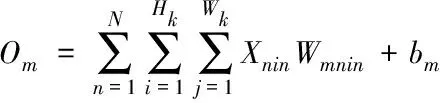
(7)
式中,m∈[1,M],在该卷积窗口中存在M个输出值O1,O2,…,OM。
在上式的基础上,令
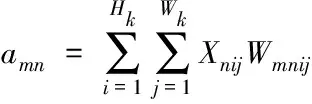
(8)
可将式(7)转变为下式
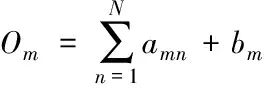
(9)
基于FPGA的卷积神经网络加速优化方法通过以下两种方法对M个输出值O1,O2,…,OM进行计算:
1)首先对参数am1,am2,…,amN进行计算,根据计算结果进行求和运算,将参数bm与求和结果相加,获得Om,令m在区间[1,M]内取值,集合获得M个输出值O1,O2,…,OM。
2)由式(9)可知
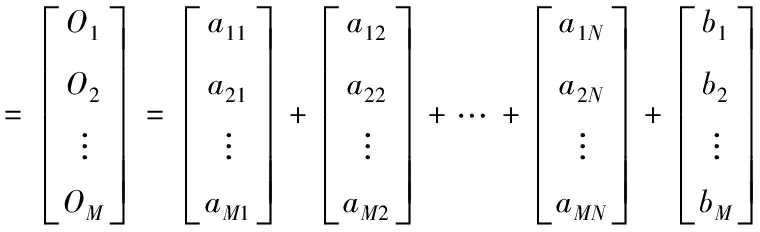
(10)
1级(轻度静脉炎):一种炎症症状或体征(不包括条索状硬化或脓液流出);2级(中度静脉炎):出现两种炎症症状或体征(不包括条索状硬化或脓液流出);3级(重度静脉炎):出现条索状硬化和/或脓液流出和/或更多炎症症状或体征)。

(11)
式中,参数n在区间[1,N]内取值。
通过上述分析可知,可并行计算在卷积神经网络的卷积层中存在三个部分:
1)并行计算式(8)中的HkWk个乘法,此时卷积核内部中存在并行计算,即卷积内并行。
2)通过式(9)对卷积神经网络中存在的第m个卷积输出Om进行计算时,可以并行计算N个输入通道对应的卷积,利用获取的卷积结果获得对应的卷积输出Om[11],在卷积神经网络中上述过程被称为输入通道并行。
3)输出通道并行:在卷积神经网络中计算输出在卷积层对应的第n个分量n时,并行计算卷积神经网络中n个输入通道的卷积和M个卷积核中通道的卷积。
3.2 基本模块设计
1)全并行乘法与加法树模块
卷积核在卷积神经网络中通常为正方形,设定Wk=Hk=K为卷积核在卷积神经网络中的大小,y代表的是卷积神经网络的卷积输出,其计算公式如下
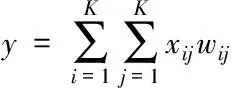
(12)
基于FPGA的卷积神经网络加速优化方法设计的加法树需要g2(η)个寄存器,f2(η)个加法器,时钟周期为h2(η)
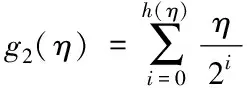
(13)
f2(η)=η-1
(14)
h2(η)=[log2η]
(15)
乘法-加法树模块在FPGA加速器中的运行过程如下:
①在缓存区中输入卷积核权重矩阵和特征图矩阵,分别称为权重缓存和输入缓存。
②在权重缓存和输入缓存中获取数据,利用乘法器对K2个乘法进行并行计算,获得中间结果。
③构建加法树,将中间结果输入加法树中,获得乘法-加法模块的最终输出结果。
2)高效窗口缓存模块
在卷积层进行相关计算时,生成的卷积窗口数量较多,G为生成的窗口数量,其计算公式如下
G=HW
(16)
设通道矩阵在输入特征图中的形状为[H,W],令

(17)
将矩阵x的第i行第j列元素的下标表示为j+(i-1)W,则矩阵x可转变为下述形式
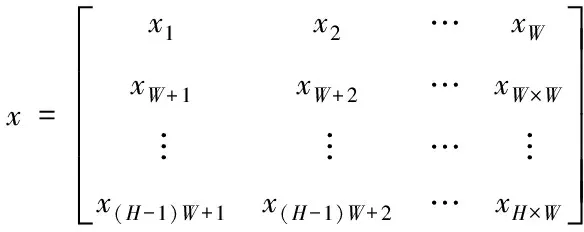
(18)
如果利用硬件并行所有卷积窗口,计算资源会被消耗的太多。为了降低资源消耗,基于FPGA的卷积神经网络加速优化方法利用流水线的方法对卷积窗口进行操作,减少计算资源和存储资源。通过两个2维寄存器组建窗口缓存模块,分别是移位寄存器和窗口缓存器[12]。
3.3 通道并行卷积层加速设计
结合上述并行部分,基于FPGA的卷积神经网络加速优化方法设计卷积层并行加速方案实现卷积神经网络的加速优化。
设Xi代表的是第i个通道在输入特征图矩阵X中的某个卷积窗口;Wmni描述的是第n个通道在第m个卷积核中对应的权重矩阵,此时卷积神经网络中的输入为
amn=Xn·Wmn
(19)
通过上述运算实现卷积神经网络的加速优化。
4 实验结果与分析
为了验证所提方法的有效性,需要在xilinx公司ISE硬件开发的平台中对所提方法进行测试,测试所用的软件开发工具为visual studio 2013,CPU为Core i5 2500K四核处理器,基准主频为3.3GHz。将资源消耗率作为测试指标,分别采用文献[5]方法、文献[6]方法作为实验对比方法,与基于FPGA的卷积神经网络加速优化方法共同测试资源消耗率,得到对比结果如图2所示。

图2 不同方法的资源消耗率
由图2中的数据可知,采用所提方法对卷积神经网络进行加速优化处理时,卷积神经网络中的资源消耗率控制在30%以内;采用文献[5]方法加速优化卷积神经网络时,资源消耗率高达60%;采用文献[6]方法加速优化卷积神经网络时,资源消耗率高达70%,对比所提方法、文献[5]方法和文献[6]方法的测试结果可知,虽然经3种方法优化后的卷积神经网络资源消耗率都随着运行时间的增加而增加,但所提方法的资源消耗率远远低于文献[5]方法和文献[6]方法的资源消耗率,因为所提方法的为了减少资源在卷积神经网络中的消耗,根据建立的卷积神经网络前向传播模型利用流水线方法对卷积神经网络中存在的窗口进行相关操作,减少了卷积神经网络运行所需的计算资源和存储资源,降低了所提方法的资源消耗率。
将网络计算量作为测试指标,进一步对所提方法、文献[5]方法和文献[6]方法进行测试,网络计算量越低表明卷积神经网络的加速优化效果越好,不同方法的测试结果如图3所示。
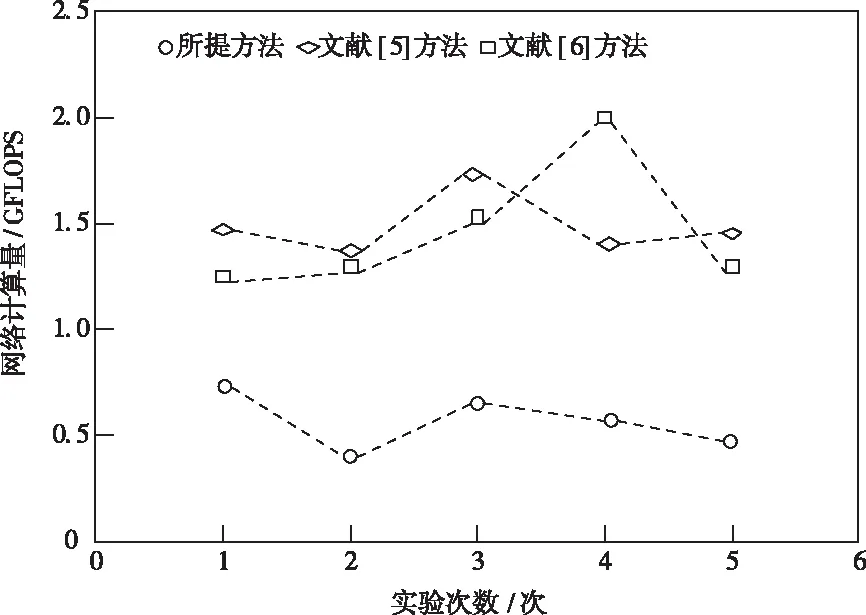
图3 不同方法的网络计算量
分析图3可知,在多次实验中所提方法优化后的卷积神经网络的计算量均在1.0GFLOPS以下,文献[5]方法优化后的卷积神经网络的计算量在第4次实验过程中高达1.7GFLOPS,文献[6]方法优化后的卷积神经网络的计算量在第3次实验过程中高达2.0GFLOPS,对比所提方法、文献[5]方法和文献[6]方法的卷积神经网络计算量可知,所提方法获得的网络计算量最少,网络计算量越少表明方法的加速优化效果越好,因为所提方法对卷积神经网络前向传播结构进行了分析,并根据分析结果在通道并行卷积层加速设计中通过全并行乘法-加法树模块进行相关运算,减少了卷积神经网络的计算量,提高了卷积神经网络的整体运行效率,验证了所提方法的整体有效性。
5 结束语
在深度学习领域中,卷积神经网络是人工智能发展和研究的热点,成为一个重要领域,卷积神经网络具有识别精度好和复杂度低的优点,在图片搜索、机器视觉、语音识别和图像识别等应用中得到了广泛的应用。网络模型的计算量随着类型不同的卷积神经网络模型的出现不断加大,且一些高实时性要求的场合利用现有的CPU无法满足,因此需要对卷积神经网络进行加速优化处理。当前卷积神经网络加速优化方法存在资源消耗率高和网络计算量大的问题,提出基于FPGA的卷积神经网络加速优化方法,在卷积神经网络前向传播模型的基础上利用重构性、灵活性高的FPGA对卷积神经网络进行优化加速,降低了资源在卷积神经网络中的消耗率,减少了卷积神经网络的计算量,为卷积神经网络在众多领域的发展提供了保障。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
舰船科学技术(2022年11期)2022-07-15
中国教育信息化·高教职教(2022年4期)2022-05-13
计算技术与自动化(2022年1期)2022-04-15
煤气与热力(2022年2期)2022-03-09
速读·下旬(2021年11期)2021-10-12
上海师范大学学报·自然科学版(2019年5期)2019-12-13
大东方(2019年12期)2019-10-20
软件(2017年6期)2017-09-23
科学与财富(2017年22期)2017-09-10
