
河北省旅游景点知识图谱的构建*
2022-08-26 09:39张宇飞贾东立
计算机与数字工程 2022年7期
张宇飞 李 腾 贾东立
(河北工程大学信息与电气工程学院 邯郸 056000)
1 引言
随着物质生活的不断提高,人们越来越重视精神生活的享受,这使得旅游业越发受到大家的追捧。然而由于景区特点各异,信息量庞大又复杂,而且网络上存在的数据良莠不齐,使游客很难在短时间内得到自己需要的精确信息[1]。鉴于此,有学者提出将知识图谱应用到旅游领域,如徐溥、刘济源[2]等都对旅游领域的知识图谱进行了设计和构建。
河北省内不仅景点数量多(截止2020 年初,含有5A 级景点10 个,4A 级景点约130 个),还有许多像狼牙山、西柏坡等具有良好教育意义的经典红色旅游景区,是名副其实的旅游大省。有学者通过DEMATEL 模型得出了‘旅游管理对旅游的发展作用力最强’的结论[3],但是目前河北省并没有权威完善的智能化旅游管理平台。因此本文选择河北省作为研究对象,构建旅游景点知识图谱,以帮助提高河北省旅游信息的检索效率。
2 景点知识图谱的构建过程
2.1 信息抽取
信息抽取是将需要的知识单元从大量异构的数据源中自动获取的过程[4],对于不同结构的数据需要采用不同的抽取方法。本文选择互动百科、百度百科、携程网和去哪儿网四个网站作为数据来源,对于这类面向web 的半结构化数据通过网络爬虫的方法[5]在数据获取的同时完成信息抽取。
选取21 个河北省内3A 级以上的景点作为研究实体在四个网站中进行搜索:对于两个百科类网站[6],每个词条都会返回一个类似表格的信息盒,信息盒中的内容即是本文需要的并且结构良好的属性及属性值数据;对于两个旅游类网站,通过分析Html 页面布局,找到属性信息存储的标签。然后采用火车采集器作为爬虫工具,根据网页特点确定规则,获取每个景点初始的<实体,属性,属性值>三元组,信息抽取任务完成。
2.2 知识融合
本文的数据来源于四个不同的网站,所以通过信息抽取过程得到的属性和属性值信息在使用时会遇到两个问题[7]:1)景点的同一属性在不同来源中表示不同:比如对于景点的所在地这一属性,在百度百科中的属性名是地理位置,而在去哪儿网中对应的属性名是地址。2)同一属性在不同来源下对应的属性值不同,分为两种情况:一是正误问题,比如对于娲皇宫景点的开放时间,互动百科显示的值是8:00~17:00,携程网显示的是8:00~17:30,而最终的属性值只能是其中正确的那一个;另一种是信息不完整问题,如景点的别称通常会有很多个,但是在一个网站中经常会统计不完全。为了解决以上问题,进行以下知识融合。
2.2.1 属性融合
针对“景点的同一属性在不同来源中表示不同”的问题,通过属性融合技术进行解决。为了使融合结果更加准确,将以下两种方法结合使用。
方法一:使用余弦相似性算法计算相似度[8]。首先将待比较的字符串进行词频统计并表示为向量式,然后通过式(1):
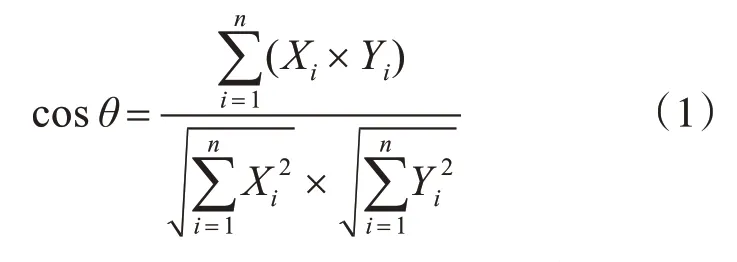
计算余弦值,如果计算结果趋于1,代表两个属性值相似可进行合并,否则不相似两个属性值均保留。实现的核心代码1如下:
核心代码1
def cosc(m,n):
v_a=np.mat(m)
v_b=np.mat(n)
num=float(v_a*v_b.T)
den=np.linalg.norm(v_a)*np.linalg.norm(v_b)
cos=num/den
s=0.5+0.5*cos
return s
方法二:根据属性值判断属性的相似性。在拥有两个相似属性的实体中,如果它们的属性值相同的数量占据大多数,那么认为它们表示的是同一属性,可进行合并。计算式(2)如下[9]:

公式中的分母表示具有该两种属性的实体个数,分子代表两个属性的属性值相同的实体个数。
2.2.2 属性值融合
针对‘同一属性在不同来源下对应的属性值不同’的问题,通过属性值融合技术[10]解决。该问题分为两种情况,所以属性值融合过程[11]分为两个步骤,具体描述如下:
1)根据以上对问题的描述,将本文获取到的所有属性分成两类:
(1)单值属性:即上文中存在正误问题的属性。该类属性的特点是它的候选属性值可以有多个,但是它们有对有错,最后只有一个可以作为最终属性值,文中此类属性有:景点名称、建立时间、门票价格、占地面积、邮编、建议游玩时长、开放时间、海拔高度。
(2)多值属性:即上文中存在信息不完整问题的属性。该类属性的特点是它的候选属性值可以有多个并且它们可能全部都是正确的,因而最终属性值是可以存在多个的,文中此类属性有:景点别称、相关人物、景区看点、联系方式、所获荣誉、相关事件。
2)按照不同类型属性的特点选择合适的方法将属性值进行融合:
(1)对于单值属性,需要从多个候选属性值中融合得到最有效最准确的一个作为最终属性值,因此该问题的重点在于属性值有效性或者准确度的排序,引用可信度来表示上述的有效性或者准确度。通过式(3)计算出多个候选属性值的可信度,将可信度排序,最高的一个作为该属性最终的属性值。式(3)及参数解释如下:

其中,m1至m3为自定义参数,本文中m1=10,m2=7,m3=2。E 代表来源的权重,本文定义来源于百科类网站的属性值权重为4,来源于旅游类网站的属性值权重为3。N 代表该属性值出现的次数。L代表属性值的长度,最短设为1,依次递增。
(2)对于多值属性,只需要将多个正确的候选属性值进行合并然后去重即可融合形成完整的最终属性值。去除重复属性值操作相对简单且方法较多,因为集合中的内容具有不可重复的特点,所以本文利用Python里的集合工具完成此过程。
2.3 本体构建
本体构建属于知识图谱的模式层,它用于在逻辑上表达各概念之间的相互关系[12],本文对旅游本体的构建[13]过程如下,图1 是通过Protégé软件构建的本体模型。

图1 本体模型
1)定义实体类别(Thing)
根据河北省旅游景点的特点,定义了景点、地址、级别、季节四类实体。其中景点下分红色经典景区、自然风光景区和游乐休闲景区三类;地址表示景点所在的地理位置,包括河北省内的11 个城市以及其包含的县区等地址;级别表示景区的星级,此处有3A 级、4A 级和5A 级;季节表示某景点适宜游客游玩的季节,即春季、夏季、秋季和冬季。
2)定义实体关系(Object Property)
根据定义的实体类别,创建了四种实体间的语义关系:位于——表示景点与地址之间的关系,即景点位于某地址;属于——表示景点与级别之间的关系,即景点属于几星级;包含——表示大地点与小地点之间的含有关系;适宜——表示景点与季节的之间的关系,即景点适宜游玩的季节。
3)定义实体属性(Data Property)
将经过知识处理后的景点属性信息进行描述,定义了景点的名称、别称、联系方式、建立时间、占地面积、海拔高度、开放时间、邮编、门票、所获荣誉、相关事件、著名人物、景区看点、地位、游玩时常15个属性。
2.4 知识存储
目前存在RDF 和Neo4j 两种较完善的知识图谱存储方法。其中RDF 存储是通过三元组方式实现对数据的存储。而Neo4j图数据库存储是通过节点和边组成图的形式对数据进行存储[14]。相比而言,Neo4j图数据库在数据操作方面更加的灵活,在数据展示方面更加的直观,且其存储速度不会随着数据的增加而降低[15]。因此本文选择Neo4j 图数据库作为知识存储工具,采用Cypher语言对旅游信息的存储命令[16]如下:
1)创建实体部分代码
create(娲皇宫:自然风光景区{名称:‘娲皇宫’,建立时间:‘北齐时期’,占地面积:‘76 万平方米’,开放时间:‘8:00-17:00’,门票:‘70元’})
create(邯郸市:地点{名称:‘邯郸市’})
2)创建关系部分代码
create(娲皇宫)-[:属于]->(AAAAA级)
create(娲皇宫)-[:位于]->(涉县)
3 景点知识图谱的构建结果
通过以上处理步骤,将选取的21 个景点实例以及它们之间的逻辑关系构建完成的知识图谱结果如图2 所示,这些节点通过代表实体间关系的边进行连接最终形成完整的图谱。

图2 景点图谱
图3 展示的是对景点“娲皇宫”进行查询得到的结果,除了景点自身的名称、别称、占地面积、开放时间等属性信息外,关于景点位于地址、适宜游玩的季节和景点属于的星级也是一目了然。
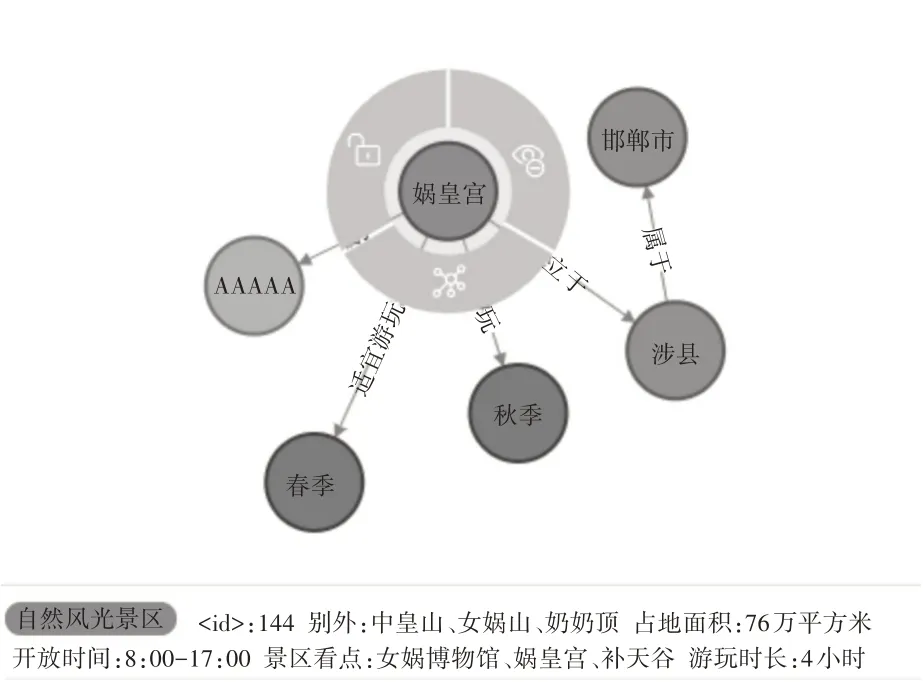
图3 景点信息查询
4 结语
本文以河北省内21 个3A 级以上的景点为例,在数据爬虫过程中实现了景点信息抽取,通过属性融合和属性值融合对景点知识进行了加工,又使用Protégé本体编辑软件构建了河北省旅游本体,最终将结构化旅游知识存储到Neo4j图数据库中完成了河北省旅游景点知识图谱的构建。未来的工作将继续从河北省现状出发,使该景点图谱规模更大、功能更完善,实现知识图谱在旅游领域更广泛的应用。
猜你喜欢
军事文摘(2022年16期)2022-08-24
舰船科学技术(2022年11期)2022-07-15
齐鲁艺苑(2022年1期)2022-04-19
哈哈画报(2021年10期)2021-02-28
中国新闻周刊(2020年38期)2020-11-02
意林·全彩Color(2018年7期)2018-08-13
新城乡(2018年6期)2018-07-09
Coco薇(2015年11期)2015-11-09
股市动态分析(2015年12期)2015-09-10
图书与情报(2013年1期)2013-11-16
