
基于消息中间件与GRU 的分布式日志异常检测*
2022-08-26 09:39贾雪磊
计算机与数字工程 2022年7期
贾雪磊 方 巍 张 文
(1.南京信息工程大学计算机与软件学院 南京 210044)
(2.中国气象科学研究院灾害天气国家重点实验室 北京 100081)
(3.南京信大气象科学技术研究院有限公司 南京 210044)
1 引言
分布式的服务日志有着两个特点,首先日志的数据量是海量的,大规模的系统每小时打印日志约50Gb(约1.2 亿~2 亿行)的量级[1];另外分布式系统产生的日志都是分散在不同的服务器目录下。由于日志数据是海量且分散的,因此对整个分布式系统的日志进行分析与异常检测会比单机系统复杂很多。所以就需要有一种高效的日志采集和分析方法来帮助完成对日志的分析工作,从日志中发现异常来避免系统异常而造成的严重后果。
近年来,有许多的科研团队对日志异常检测展开了相关研究工作,并且取得了很丰硕的成果。早在2004年Mike Chen[2]等学者提出了使用决策树的方法对HDFS 日志进行的错误检测。Yinglung Liang[3]团队使用SVM(Support Vector Machines,支持向量机)对IBM BlueGene/L的日志数据进行一个异常处理。文献[4]提出了使用RNN(Recurrent Neural Network,循环神经网络)对系统日志进行异常检测。Qingwei[5]团队提出了一个LogCluster的方法对服务系统进行一个日志错误识别。最近几年深度学习飞速发展,许多研究日志异常的团队将目光转向了深度学习领域,其中Feifei Li[6]团队提出了一种基于LSTM[7](Long Short-Term Memory,长短期记忆网络)的日志异常检测模型DeepLog,这个模型通过学习大量的正常日志数据,从中学习日志规则,当检测到新来的日志数据偏离了正常的日志规则,则认定这条日志是一条异常日志。
常见的日志异常检测的方法可以归纳为三个步骤[8]:1)日志采集和预处理;2)日志解析;3)异常检测。整个日志异常检测的流程图见图1所示。
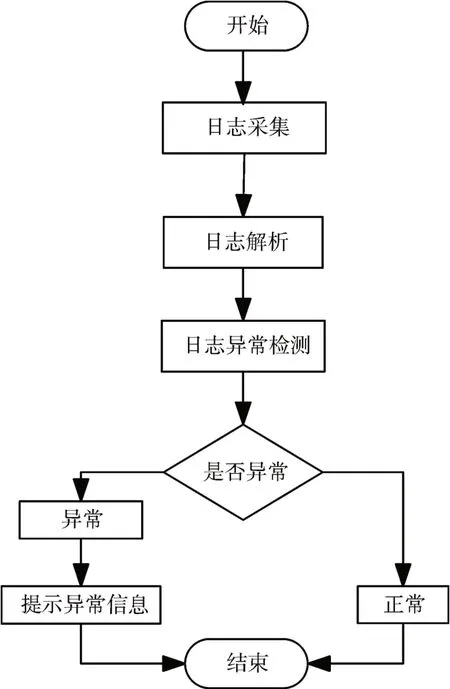
图1 常见日志检测的流程图
本文针对目前分布式系统中日志异常研究存在的一些问题提出了如下的三点研究创新。
1)在日志采集前加入预处理操作。先进行预处理的好处是在一定程度上减少网络传输的数据量,提高整个异常检测的效率。
2)使用分布式的消息中间件进行日志的采集与传输。分布式消息中间件可以很好地应对高频率的大数据的需求。
3)在日志异常检测阶段,本文提出了基于GRU[9]深度网络的日志异常检测方法,相比文献[6]提出的基于LSTM 的检测方法,GRU 结构更为简单,所需训练样本较少,具有轻量级与易实现的特点。
2 分布式日志异常检测方法的设计
2.1 基于消息中间件的日志过滤与收集
本文针对的是分布式系统的日志异常检测问题,因此日志数据的高效收集是重点任务之一,也是进行日志异常检测之前必不可少的环节。
由于日志的数据量十分庞大,因此需要先进行一个日志预处理,将日志数据中对日志异常检测没有帮助的信息进行剔除,在一定程度上减少了需要进行网络传输的数据量,提高整个异常检测的效率。Filebeat 是一个轻量级的传送器,可以用来对指定的日志文件或位置进行日志的收集,通过使用配置参数exclude_lines 可以对收集的日志先进行一个过滤。Filebeat 配置的输出是Kafka,Kafka 是一种高吞吐量的分布式发布订阅消息系统,具有高吞吐量、低延迟、持久性、高并发等特点,十分适合对实时的日志进行一个大数据量的传输。对不同机器的日志按不同Topic 进行传输,使得日志流数据不会产生混合变成“脏数据”[10]。日志流按照Topic发布的架构图见图2。
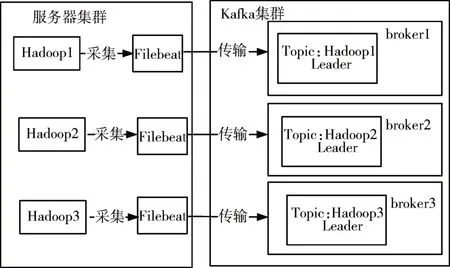
图2 日志流按照Topic发布架构图
本文所采用的分布式集群中有三个主机,主机名为Hadoop1、Hadoop2、Hadoop3,对应机器中的Filebeat将收集到的日志分别推送到本主机名命名的Topic中。这样设计的很好地避免日志被随意混合,形成“脏数据”。
最后使用Logstash 对Kafka 集群中的日志数据进行消费读取与保存。Logstash是一个开源数据收集引擎,具有实时流水线功能,将日志规范化后输出到指定位置进行保存。总体的分布式日志预处理与收集的算法流程图如图3所示。
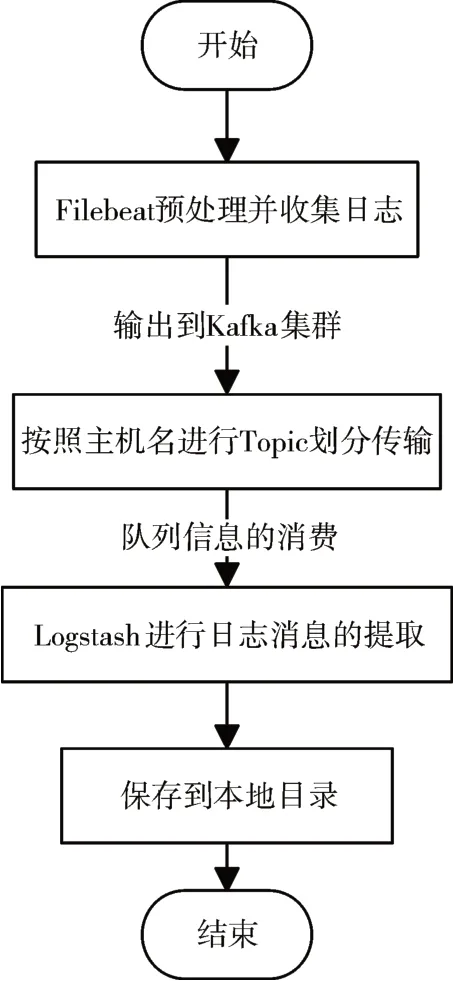
图3 日志过滤与收集的算法流程图
在本阶段主要使用了三种消息中间件进行日志的预处理、传输、接收与保存,且满足大数据传输所需的高吞吐量,低延迟以及高可用等。
2.2 基于GRU的日志异常检测方法
本文对日志异常检测部分使用的方法是基于GRU 的深度学习检测模型,对于日志异常检测主要分为日志数据向量化处理,异常检测模型的训练和日志异常检测三个部分。文本数据向矩阵向量化 转 换 的 方 法 有word2vec[11](word to vector),TF-IDF[12],one-hot[13]等。word2vec 可以通过浅层的神经网络结构训练一个权重矩阵如式(1)所示,来将独热编码所得的高维数稀疏矩阵如式(2)所示,转化为低维数的稠密向量矩阵如式(3)所示。Mikolov 在文献[11]中指出一个优化的单机版本一天可训练上千亿词。可见word2vec 的效率是很高的。

另外word2vec 可以将相似度高的词语通过在向量空间对应词向量的距离体现出来[14]。所以本文使用word2vec对日志序列进行词向量的构建,并作为GRU神经网络的输入。
GRU 与LSTM 都为循环神经网络的变种,单个GRU 网络的结构见图4。GRU 升级了门限结构,将LSTM 里面的输入门、遗忘门整合成一个更新门Zt,用Rt门替换了LSTM的输入门,因此GRU网络中的门的个数由LSTM中的3变成了2,有效地减少了总体参数的数量,缩短了训练时间。Zt主要是用来对新输入信息的过往数据进行归纳,Rt主要是决定前一步骤中状态信息输入模型的概率。
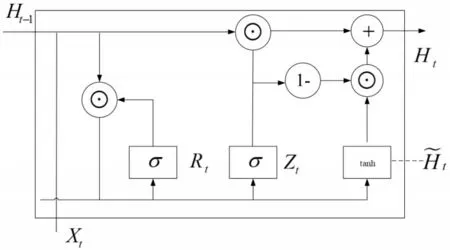
图4 单个GRU网络结构图

式(6)中为上一个单元的隐藏层状态,输入为Xt,重置门Rt,更新门Zt,候选隐状态H͂t,重置门Rt决定了如何将新的输入信息与前面的记忆相结合,更新门Zt定义了前面记忆保存到当前时间步的量。如果本文将重置门Rt设置为1,更新门设置为0,那么本文将获得标准RNN 模型。根据式(7)可以看出当前状态的隐状态的输出取决于当前的输入与之前的隐藏层的输入。所以最后的输入是依赖当前的输入向量与之前的输入,可以很好地处理日志上下文之间的关系,可以合理地对日志序列向量进行一个异常检测训练与检测。
基于GRU 的日志异常检测方法的总体流程图以见图5。通过以上对基于GRU 的日志异常检测方法的阐述以及图5 所表达的流程可知,在本阶段主要对日志数据进行向量化处理,GRU 网络对日志序列进行分类预测的训练,网络的输出再经过Softmax[15]分类器进行异常分类。
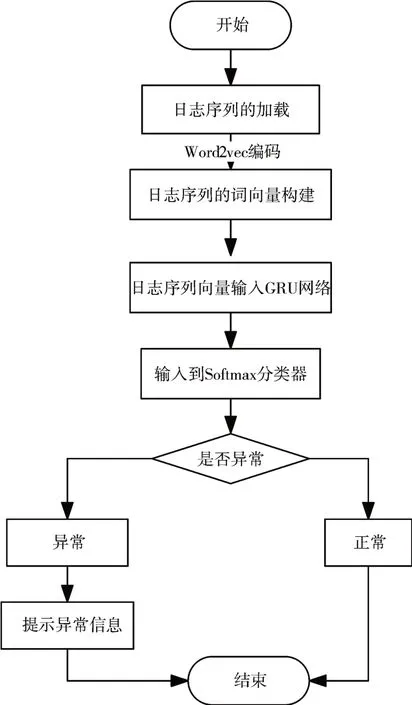
图5 基于GRU的日志异常检测算法流程图
3 分布式日志异常检测方法的实现
本文在实验环节使用三台Centos 服务器组成Hadoop 分布式集群作为实验基础,利用Filebeat 与Kafka 对集群中HDFS(Hadoop Distributed File System)日志进行预处理与收集,收集之后的日志经过Logstash整理过滤生成待编码日志。分布式集群和模型训练与测试的机器配置信息见表1。

表1 硬件与软件环境配置表
3.1 分布式日志预处理与收集
日志收集与解析的实验部分所采用的分布式服务系统为3 个Hadoop 节点集群,主要是对HDFS所产生的日志文件进行一个异常分析。使用Filebeat对日志的变化进行监控,并将新日志数据发送到libbeat,libbeat 将聚集事件,并将聚集的数据发送到Filebeat 配置的输出接口。本文所使用的是Kafka 作为Filebeat的输出。Kafka 中采用点对点的消息队列模式,防止日志重复消费,造成网络资源的浪费,同时根据不同的机器发布相对应的主题,实现不同机器日志的单独收集。
最后Logstash 进行日志的消费输出到对应的日志文件中进行保存。Filebeat 与Logstash 的配置文件信息如下。
filebeat.inputs:
-type:log
enabled:true
paths:
-/var/log/*。log
output.kafka:
enabled:true hosts:[“192.168.10.10:9092”,“192.168.10.11:9092”,“192.168.10.12:9092”]
topic:hadoop100
input{
kafka{
bootstrap_servers=> [ “192.168.10.10: 9092,192.168.10.11:9092,192.168.10.12:9092”]
topics=>[“hadoop100”]
group_id=>“filebeat-logstash”
}}
output{
file{
path=>“/tmp/logstash.output”
}}
在Filebeat的配置中path用来指定要监控的日志目录,通配符*表示监控所有后缀名为.log的日志文件,output 指定为Kafka 输出。Logstash 配置信息中再对输入进行指定,就可以进行日志消息的抓取,最后再统一输出到保存目录即可。
3.2 日志编码与异常检测
根据所设计的异常检测算法,本文实现了基于GRU 的深度学习检测模型,其模型结构见图6。针对本文所使用的基于GRU 的深度学习检测模型,实验使用PyTorch来对模型的网络结构进行搭建以及实现。主要的模型与训练参数见表2。

图6 基于GRU的日志异常检测框架图
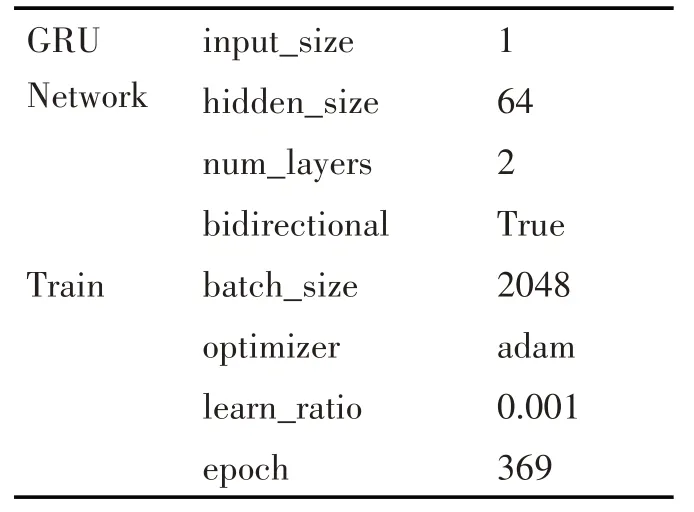
表2 模型与训练参数
4 实验结果分析
本文异常检测的网络模型的训练数据集是亚马逊公开的11,175,629条HDFS日志,数据集的分类标签已由亚马逊的分布式系统专家标记是否为异常日志。
实验采用准确率(Precision)、召回率(Recall)以及综合评价指标(F1-Measure)来评价模型的检测效果,公式见式(8)~(10)。其中TP 正类判定为正类,FP 负类判定为正类,FN 正类判定为负类,TN负类判定为负类。

实验也分别使用近年来主流的一些方法进行日志异常预测,比如LSTM[6]、Invariants Mining[16]以及PCA[17]。通过对比发现本文所使用的模型在综合评价指标方面比其他三种方法的检测精度有显著优势。最后的实验结果对比图见图7,具体的实验结果数据见表3,*标表示本文使用的方法。
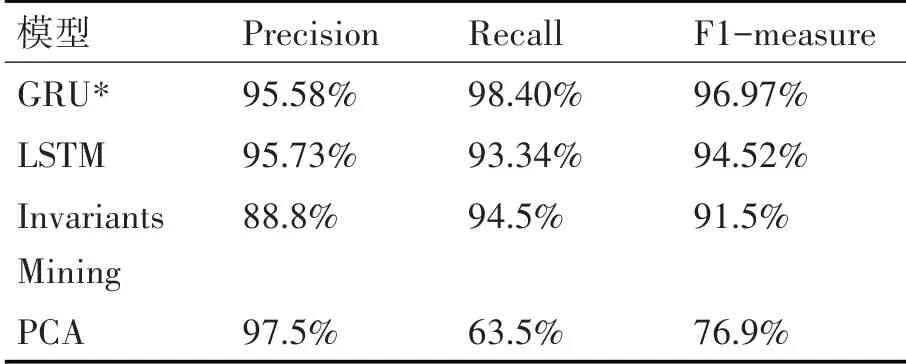
表3 实验结果对比

图7 实验结果对比
通过实验结果得知GRU 在F1-measure 的标准下效果最好,这也验证了本文所使用的检测模型是正确的。
5 结语
本文提出了一种基于消息中间件与GRU 的异常检测方法高效地对分布式系统中产生的日志进行采集与异常识别,极大地帮助运维人员了解系统的异常情况。在日志产生阶段开始对日志进行一个预处理与采集,根据分布式集群中机器名划分Topic,防止日志造成混淆,最后将日志保存到本地的文件系统中。在日志收集与解析之后就需要对日志进行一个异常识别。本文使用word2vec 进行词向量的构建[18],word2vec 输出的向量矩阵输入GRU 网络,经由两层GRU 单元组成的GRU 网络得到其输出,随后将其输入到全连接层经过Softmax分类器,得到的结果分为正常和不正常两种情况,实现了日志的异常情况的检测。通过对比同为循环神经网络的LSTM 以及其他基于机器学习的检测方法,最后根据实验数据对比可以看出,本文所使用的GRU 模型的效果更好。接下来的工作是尝试适应不同的分布式系统以及考虑在检测模型中加入注意力机制等,对Spark,Flink[19]等系统的日志进行异常分析,提高本文方法的普适性。
猜你喜欢
化工进展(2022年8期)2022-08-29
农业工程学报(2022年8期)2022-08-08
健康体检与管理(2022年4期)2022-05-13
化工进展(2022年3期)2022-04-12
华人时刊(2021年13期)2021-11-27
科学与财富(2021年35期)2021-05-10
诗选刊(2020年12期)2020-12-03
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
思维与智慧·上半月(2018年10期)2018-11-30
思维与智慧·上半月(2018年9期)2018-09-22
