
结合实体标签的中文嵌套命名实体识别*
2022-08-26 09:39潘丽君陈艳平黄瑞章秦永彬
计算机与数字工程 2022年7期
潘丽君 陈艳平 黄瑞章 秦永彬
(1.贵州大学计算机科学与技术学院 贵阳 550025)(2.贵州大学贵州省公共大数据重点实验室 贵阳 550025)
1 引言
命名实体识别(Named Entity Recognition,NER)是信息抽取中的一项重要任务,其目的是识别出文本中的命名实体并进行分类。命名实体包括人名、地名、组织名等,它在关系抽取,语法解析,知识问答等自然语言处理(NLP)系统中具有重要的作用。然而,命名实体(NE)存在主观性、复杂性、多变性等特点,且命名实体在句子中的上下文特征稀疏,使得命名实体识别一直是NLP中一个重要且有挑战性的研究课题[1]。
与英语NER 相比,中文NER 更具有挑战性。第一,中文文本没有关于NE的词型特征,如首字母大写等。第二,中文NE高度依赖上下文,几乎每个汉字和词语都可以用来构建NE,且同一个词在不同的上下文中有不同含义。例如“文献是朝阳区区长”中,“文献”是人名实体,而大多数情况下,“文献”不是NE。第三,同一个词语可以指代不同的实体类别。如“阿里”在“拳王阿里是个传奇”中是人名实体,在“西藏阿里美不胜收”中是位置实体,在“杭州阿里吸引了很多人才”中是组织实体。第四,中文文本中没有分隔符(如空格)来分隔单词,使得识别实体边界更加困难。例如,句子“习近平常与特朗普通电话”可以分词为“习近/平常/与/特朗/普通/电话”,其中“特朗”被预测为人名实体,而事实上“习近平”及“特朗普”都是人名实体[2]。
在早期的研究工作中,通常将NER 视为序列标记问题,即为每个标记单元分配一个标签,用以表示每个标记单元在命名实体中的角色,如实体开始(“B”),实体中部(“I”)和非实体(“O”)等。由于自然语言具有复杂的语义结构,嵌套实体无处不在。近几年,NER领域提出了很多针对嵌套实体结构的模型。一些工作通过修改序列模型以支持使嵌套命名实体识别。传统算法使用的浅层序列标注模型存在严重的特征稀疏问题,深度学习算法虽然能解决上述问题,但序列标注模型只能识别扁平结构的命名实体,无法识别句子中互相重叠的嵌套实体,因此基于深度学习的序列模型在嵌套命名实体识别中性能较低[3]。
为解决上述问题,嵌套命名实体识别领域提出了基于跨度(Span)的算法,即将实体识别视为一个跨度分类任务,首先产生一定数量的跨度种子,再输入分类器中进行识别。相对于序列标注算法,基于Span 的模型在识别性能上体现出较大优势。但是目前基于Span 的大部分模型都存在无法有效利用句子的全局信息的问题,如Chen 等[4]。提出的NNBA 模型。该模型生成跨度种子后,将句子分为三个语境:跨度种子左边语境,跨度种子语境,跨度种子右边语境,再分别仍进三个LSTM 模块学习,拼接三个输出结果后进行分类。因而损失了大量的跨度区域上下文语义信息,导致了检测性能不高。
针对上述问题,本文提出了结合实体标签的嵌套命名实体识别模型。首先用传统的枚举算法生成跨度种子(候选实体),为了减少计算量提高效率,设置最大的枚举长度为7,然后将跨度区域的边界信息作为实体标签嵌入原句中,作为分类器输入。实体标签明显标识出跨度种子在句子中的位置信息,模型除了学习到跨度种子的局部信息外,还能学习到跨度种子和上下文的语义信息,更好地帮助模型理解语义。模型把候选实体筛选的问题转化为句子分类问题,简化识别难度,提升了性能。
2 相关工作
序列模型是NE 识别的常用算法,包括条件随机场(CRF),隐马尔可夫模型(HMM)和长短期记忆网络(LSTM)等。序列模型假设输入的结构是扁平的,难以识别嵌套NE。为了解决嵌套结构问题,研究者提出分层策略、级联策略和结构化标记策略。Zhou 和Zhang 等使用HMM 识别最外层实体,然后对内层实体采用基于规则的算法进行识别。Settles 和McDonald 等[5]提出了结构化多分类模型,该模型基于CRF,但不能识别类型相同的嵌套实体。当算法基于序列模型时,嵌套实体通常有多个标签,这加大了识别难度。Tang 等[6]提出用不同标记区分实体的独有和共享部分,并使用基于支持向量机(SVM)的判别算法,对输出进行解析后,结合基于规则的识别算法对齐已识别的嵌套实体。浅层序列标注模型存在严重的特征稀疏问题,不能有效获取上下文依赖信息,导致识别性能低下[3]。
将嵌套结构转换为平坦表示是嵌套NE识别的另一种算法。Lu 和Roth[7]首先提出了使用超图表示法来识别嵌套命名实体。他们的模型可以有效地捕获无限长的嵌套命名实体。Wang 等[8]提出了一个分段的超图表示来捕获特征和交互,将嵌套命名实体转换为树结构,再采用堆栈LSTM 模型识别嵌套NE。Katiyar 和Cardie[9]采用递归神经网络对有向超图表示进行编码。在基于解析的模型中,首先将句子解析为依赖树,再通过对解析树的节点进行分类来识别NE。Jie 等[10]构建了一个可以获取依赖树全局信息来有效支撑最外层实体的识别的模型。
基于Span 的模型也被广泛用于嵌套命名实体识别中。该框架首先收集一定跨度的候选实体,然后由分类器进一步评估。例如,Xu 和Jiang[11]以及Sohrab 和Miwa[12]详尽地枚举了一定长度内所有可能的NE 候选。Xu 和Jiang 将句子被分为三个部分:候选实体左边语境、NE候选语和候选实体右边语境,每个部分被编码成一个固定大小的表示,再拼接为一个整体进行分类。在Sohrab 和Miwa 的工作中,NE候选词通过连接起始词、结束词和内部词来表示。Xia 等[13]设计了一个区域网络来生成NE候选,然后使用分类网络进行评估。Chen等[4]提出NNBA 模型,该模型首先检测实体边界(开始及结束边界),再采用前向匹配的算法组合实体边界得到候选实体,然后通过分类器对NE 候选进行识别和分类。事实证明基于Span 的算法针对多层嵌套实体是有效的。
目前提出了许多多目标或端到端框架来支持嵌套命名实体识别任务。Ju 等[14]提出了一种神经分层模型,该模型通过层叠级联平面模型识别嵌套实体。Lin等[15]使用头部驱动短语结构进行嵌套NE识别。在基于BERT 的模型中,Fisher 和Vlachos[16]提出了一种合并和标记算法来组合单词和预测嵌套实体。Shibuya 和Hovy[17]采用了一种序列模型,从最外层到内部迭代提取嵌套实体。Straková等[18]将嵌套NE 识别转化为序列问题。Wang 等[19]将一个句子映射到金字塔层中,其中嵌套的NE 被识别为句子的金字塔输出。Li等[20]将嵌套的NE识别描述为一项机器阅读理解任务。
越来越多的研究者尝试用迁移学习解决嵌套命名实体识别问题,但基于span的方法在性能上仍具有竞争性优势。然而,目前基于span的模型在对跨度种子进行分类时,主要采取两种方法:1)直接识别跨度种子;2)将句子分为三个部分,分别学习后拼接进行识别。这两种方法都会丢失大量跨度种子和上下文之间的结构语义信息,导致性能不佳。
3 模型方法
模型总体框架如图1 所示。结合实体标签的嵌套命名实体识别模型可分为两部分:实体标签插入和候选实体筛选。在实体标签插入中,采用传统的枚举法产生跨度种子(候选实体),并根据跨度种子的位置信息在原句子中插入表示实体边界的标签,以标识不同的候选实体。在候选实体筛选中,搭建了传统的深度神经网络模型,把带实体标签的句子作为输入,对整个句子进行分类。
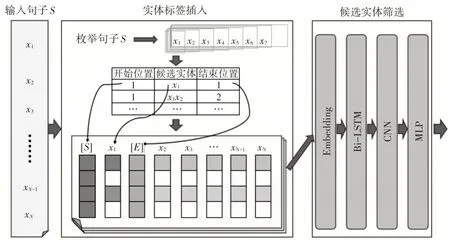
图1 模型总体框架
3.1 实体标签插入
令S=[x1,x2,…,xN](orx1:N)表示一个句子,其中xk∈S表示一个汉字。Cij=xi:j(1 ≤i≤j≤N)用于表示句子中可能的命名实体(跨度种子或候选实体),xi和xj是Cij的开始和结束边界。
目前基于Span 的框架中,有两种方法对候选实体进行分类。一种是将Cij作为分类器输入,直接对其进行分类。该方法没有使用候选实体在句子中的上下文特征,容易导致特征稀疏的问题。第二种是将句子S分为三个部分:候选实体左边(x1:i-1),候选实体(Cij),候选实体右边(xj+1:N)。然后分别作为神经网络模型的输入,通过神经网络提取各部分的特征后再拼接为一个向量进行分类。该方法能利用候选实体上下文特征,但各个部分单独提取特征丢失了候选实体与上下文之间的语义依赖。
为了充分学习候选实体与上下文全局语义信息,可以将整个句子作为模型输入。然而,一个句子通常包含多个实体。所有实体共享相同的上下文特征。如果没有关于候选实体的线索,模型就无法判断当前需要识别的候选实体。为了解决这一问题,我们在句子中候选实体的两边插入实体标签,然后将句子输入神经网络模型中学习,从而获取句子中相当于实体边界的语义依赖特征。
在插入实体标签之前,要先获取实体标签的插入位置。我们采用枚举法获取位置信息和生成跨度种子。为减少计算复杂度,设置最大的枚举长度为7。并用两个特殊标记“[S]”和“[E]”表示实体标签,以指示跨度种子在句子中的开始和结束位置,标签在神经网络中的表示是唯一的。带实体标签的句子称为NE 实例。句子植入实体标签后,NE实例̂可以表示为
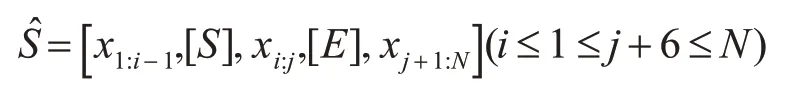
实体标签有三个特点:1)实体标签成对出现;2)一个NE 实例只包含一对实体标签;3)如果一个句子有K个NE 候选,它就对应有K个NE 实例。将Ŝ输入神经网络,对候选实体xi:j(1 ≤i≤j≤N)进行分类,模型可以根据标签位置判断不同候选实体,并学习出整个句子相对于实体边界“[S]”和“[E]”的语义依赖特征,从而提升识别的性能。
在实体识别中,通过对插入实体标签的句子进行分类具有三个优点。首先,它对候选实体相对于整个句子的语义和结构信息进行编码;其次,实体标签是基于插入的候选实体开始及结束标识,它独立于候选实体的文本表达;最后,筛选候选实体对象时,候选实体的结构嵌入在表示中。
3.2 候选实体筛选
本文采用传统神经网络构建候选实体筛选分类器。此步骤的输入是带有实体标签的句子,即所有的NE实例。通过对插入实体标签的句子进行识别,本文将嵌套命名实体识别的问题转化为句子分类任务,降低了模型学习难度,获得了更好的识别性能。
分类器主要分为嵌入层、RNN层、卷积层、MLP层。模型使用BERT[21]做词嵌入,将句子映射到768 维向量中。对于给定的具有n 个字符的句子,将中第Ewi 表个示字词符嵌xi入的查词找嵌表入,表句示子为中的词=通Ew过(x查i)。找其表转换为分布式单词表示形式。查找表从外部信息中学习得到,它对词语的语义信息进行编码。
RNN 层使用LSTM 模型。LSTM 是一种特殊的RNN 模型,它通过设计的门结构选择性地存储上下文信息,克服了在长序列中引起的梯度消失和爆炸的问题。双向递归神经网络层(Bi-LSTM)用于捕获单词间的前向和后向依赖关系。Bi-LSTM 的向前和向后隐藏状态的输出被连接为表示Bi-LSTM 的正向和反向输出,最终获得表示式为等式,其中[;]表示串联。基于获得的词嵌入表示…,n)},我们使用Bi-LSTM 模型提取句子的语义信息。Bi-LSTM的隐藏状态可以表示为式(1):
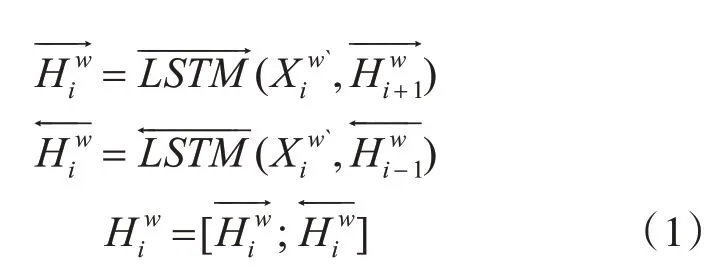
其中和表示Bi-LSTM 层的第i 个向前和向后隐藏状态。我们将句子中每个字符的共享特征提取为。RNN 层将768 维向量映射到256 维(128×2)。
模型在Bi-LSTM 后接入TextCNN。TextCNN能够有效获取到句子局部特征,并筛选出句子最明显特征。在TextCNN 中,我们使用使用滤波器Wf ϵRh×m对输入进行卷积运算:
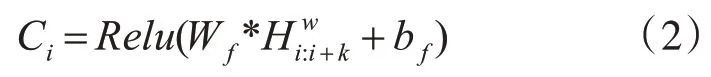
其中是从Bi-LSTM 输出的子序列信息,符号*是带偏置bf的卷积的点积运算,Relu是非线性激活函数。我们使用[2,3,4,5] 4 个不同的滤波器执行卷积运算,每种滤波器设置64 个,并将结果特征表示为Ci。然后,计算最大池化层作为Ci的元素方式最大值以表示这部分输出,输出结果为256维向量:
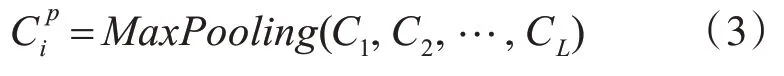
在经过以上步骤,输出一个表示高阶抽象特征的向量,再扔进MLP 层中,MLP 包含两个密集层,用于提供全局调节。MLP 的密集层将输入分别从256 映射到64,从64 映射到2(实体检测)或8(实体识别)。为避免过拟合问题,Dropout 分别设置为0.9、0.5。最后使用softmax 进行规格化,获得类别分数:

4 实验及结果分析
本文使用ACE2005 中文语料库来评估CEL 模型,包含了从新闻通讯社,广播和博客收集到的633个文档,其中定义7种实体类型——VEH(交通工具)、LOC(地名)、WEA(交通工具)、GPE(地理政治实体)、PER(人名或)、ORG(组织名)、FAC(基础设施)。该语料库标注了15264 个实体和33932 个实体提及,其中嵌套命名实体的比例为45.27%[3]。
语料库按6∶2∶2 的比例生成训练集,验证集和测试集,并采用准确率、召回率、F1 值来衡量模型性能。在所有表格中,“Total”是识别7 个实体类型的结果,“Det”是实体检测的结果,不区分实体的类型。
本文设计了三组实验评估CEL 模型。实验均在ACE2005 中文数据集上进行,且采用相同划分方案、外部资源和评价标准。
4.1 CEL在ACE2005中文数据集上的性能
为了实现CEL模型,设定输入句子最大长度为110。设置CEL 模型的学习率,Epochs 和Batch Size分别为0.00002、6、64。结果如表1所示。
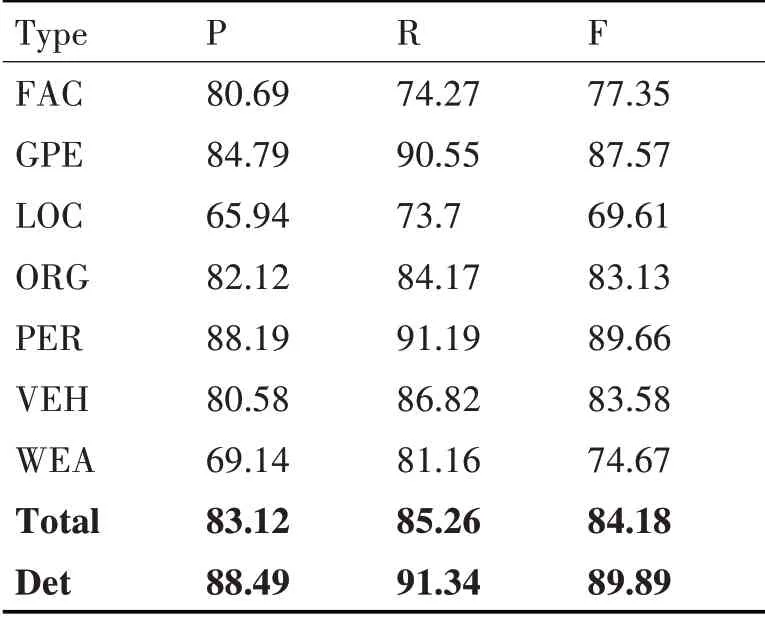
表1 CEL在ACE2005中文数据集的性能
表1的实验结果证明,CEL模型多分类F1值达到84.18%,二分类达到89.89%,召回率比正确率高出两个百分点,这是由于枚举法可以获取到很大一部分的正确实体(在中文中命名实体长度大于7 的占少数),提高了实体的召回率,加上对枚举算法的长度限制,大幅度减少了负例对性能的影响。虽然限制长度有效减少了负例影响,但枚举法产生的负例还是远远多于正例,因此,模型还有很大的改进空间,尤其是对枚举算法的改进。
4.2 实体标签的影响
在四种不同模型(CEL、Bi-LSTM、TextCNN、Transformer)中,进行带实体标签“[S]”、“[E]”和不带实体标签的实验。其中,Bi-LSTM、TextCNN、Transformer 将Word2Vector 作为词嵌入,学习率、Epochs、Batch_size、优化器分别为0.001、10、256、rmsprop。
实验的二分类结果如表2 所示,可以明显看到实体标签对不同模型的性能都有很大影响。在句子中没有实体标签的情况下,每一种模型的性能都在60%左右。句子嵌入实体标签后,四种模型的学习能力也大不相同。在相同的数据和参数设置下,Bi-LSTM的学习能力最强,源于Bi-LSTM能够获取到长距离的语义信息。在使用BERT 作词嵌入后,CEL 模型的学习能力明显增强,比其他模型高出6个百分点。实验证明嵌入实体标签对嵌套命名实体识别有很大提高。
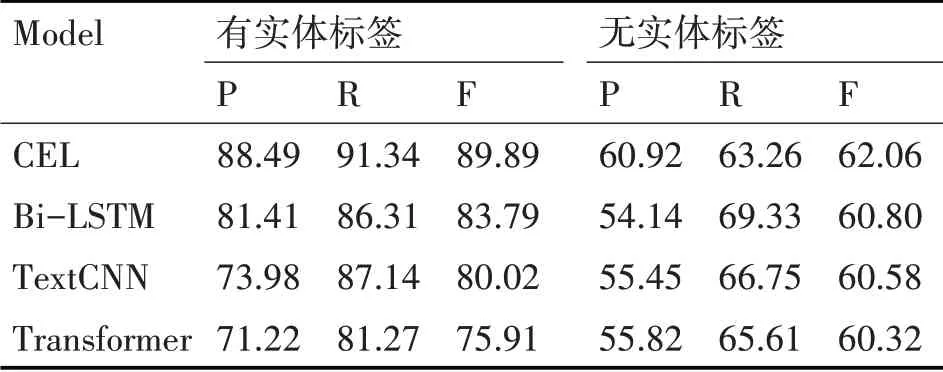
表2 实体标签性能影响
4.3 对比实验
为了更好地评估CEL 模型,进行了两种NE 识别方法的比较实验:序列模型和嵌套模型。CEL性能如表1 所示。本文实现了两个传统的序列模型来识别嵌套的NEs。因为序列模型需要扁平的标签序列,当嵌套的NEs 出现时,只能识别最内层或最外层的NEs,即对应于最内层模型或最外层模型。提及的实体总数为33932,包含24731 个最外层和25766个最内层实体提及。
结果如表3 所示,召回率根据总的实体提及次数进行调整。结果表明,无论是最内层还是最外层的策略都会受到嵌套的NEs 导致的低召回率的影响。在序列模型实验中,LSTM-BERT 性能大大提高,但是,忽略嵌套问题会成为任务的瓶颈,在性能上仍有很大的改进空间。

表3 序列模型性能
与嵌套模型的比较中,选取三种先进的嵌套算法进行比较:Alex 等讨论的级联模型(Cascading 模型)和分层模型(Layering 模型)以及NNBA 模型[4]。三者都使用与CEL 模型相同的数据和参数设置。实验结果如表4所示。

表4 嵌套模型性能对比
在Cascading-Out 模型中,每种实体类型均由独立BERT-Bi-LSTM-CRF模型识别。如果嵌套的命名实体具有相同类型,它只识别最外层实体。由于每个实体类型都可以由独立的序列模型识别,不能有效使用带注释的数据,导致实体类型“VEH”和“WEA”的性能非常低。Layering-Out 模型实现了两个独立的BERT-BiLSTM-CRF 模型,以识别最外层和最内层实体,其中外层提及是可取的,然后再收集内层的实体提及。该模型较Cascading-Out模型有明显提升,多分类和二分类分别提升六个、八个百分点。NNBA 模型[4]使用Bi-LSTM-CRF 识别出实体的开始及结束边界,再使用贪心策略匹配边界,最后输入一个Multi-LSTM 模型中进行识别。该模型对实体检测有明显提升,但是对实体识别提升不大,其原因是分类器无法有效利用全局语义信息,导致模型只能高效学习局部候选实体信息。
以上实验结果证明,CEL模型除了在二分类任务中有竞争性的优势外,在多分类任务中比当前最优的模型高出了四个百分点。特别地,在“VEH”这个类别的性能提升非常明显,提升了49%。
5 结语
深度神经网络可以从原始输入中自动提取抽象特征。然而,如果没有关于NE 候选词的实体标签,神经网络就无法学习候选实体和上下文之间的语义依赖关系。本文提出了结合实体标签的嵌套命名实体识别模型,以解决基于span的模型无法有效利用全局语义信息,导致识别性能不高的问题,CEL模型在中文嵌套NE识别任务中取得了有竞争性的成绩,为未来的工作提供了一种可能的解决方案。
猜你喜欢
军事文摘(2022年18期)2022-10-14
建材发展导向(2022年14期)2022-08-19
交通科技与管理(2021年13期)2021-09-10
金桥(2021年5期)2021-07-28
科技创新导报(2021年31期)2021-05-10
华人时刊(2020年21期)2021-01-14
西部交通科技(2021年9期)2021-01-11
东方女性(2018年3期)2018-04-16
电影文学(2017年24期)2017-11-16
金融经济(2017年7期)2017-07-15
