
干扰条件下可检索数字版权管理环境敏感数据的加密方法
2022-08-29 10:59付吉菊
上海电机学院学报 2022年4期
付吉菊
(滁州城市职业学院 管理与信息学院, 安徽 滁州239000)
在当今数据高度共享的时代,数字版权管理(Digital Rights Management,DRM)环境带给人们便利的同时,也存在很多安全隐患。在利益的驱动下,很多不法分子开始盗取个人隐私敏感数据。虽然这是互联网高速发展的一个必然阶段,但是个人敏感数据信息的泄露会给用户带来巨大损失[1-3]。
现阶段的安全保护技术,暂时还不能满足保证互联网敏感数据安全的要求。为此,张玉磊等[4]为了提高网络敏感数据的安全性,提出了一种基于身份密码格式的敏感数据加密保护方案。该方案比传统的方案安全系数更高,在进行互联网访问过程中,通过密钥派生函数进行信息访问,跳过密钥传递过程。这种混合加密的方式,比传统的格式保留加密方案具有更高的安全性能,并证明了该方案具有更高的身份伪装技术,对于网络非法访问具有更好的规避性能,但是网络攻击对敏感数据的成功率仍然较高。贾春福等[5]通过对同态加密数据集的研究,提出了一种基于机器学习的互联网数据加密方案。首先,对互联网敏感数据进行预处理,保证其可以满足同态加密数据的基本要求。然后,构建互联网同态加密数据集,并通过互联网协议实现排序和加密上传等功能。最后,获得加密的结果。为了保证在同态加密过程中互联网终端不会获取敏感数据,利用加密算法使服务器终端无法对密文进行访问操作。结果表明,该方案对于敏感数据加密安全性较高,但是鲁棒性较差。
基于以上研究背景,本文提出了一种在干扰条件下针对可检索DRM 环境敏感数据的加密方法。通过设置加密约束条件,计算DRM 环境敏感数据值占比,设计了检索DRM 环境敏感数据的加密算法,从而优化攻击成功率和信息损失率,保证敏感数据的安全性。
1 可检索DRM 环境敏感数据的加密方法
1.1 相关理论基础
对DRM 环境敏感数据进行检索的过程中,存在链路加密过程的病毒侵害、节点加密过程的外在因素干扰、对称加密过程的密码计算方式复杂、非对称加密过程的身份验证困难等4个方面的安全性影响因子。这些因子是杂乱无章的,且权值不一。因此,首先要对互联网敏感数据按照顺序存储,然后结合关键词出现的概率[6],计算出敏感数据的偏移量,其检索的核心设计步骤如下:
步骤1将DRM 环境敏感数据q i进行文档转换,转换后敏感数据的数据层次表示为

式中:f为敏感数据的语义状态;b f为敏感数据语义状态的映射集;s f为敏感数据参数集的映射集合;K为敏感数据占正常文档数据的比例。
步骤2进行文档转换后,对当前的敏感数据进行分类处理,首先中文和英文要分开处理[7],然后构建检索格式,其计算公式为
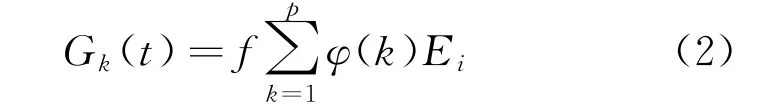
式中:φ(k)为在文档中存在k种敏感数据的概率;E i为敏感数据中文和英文之间的分隔函数。
步骤3根据上述构建的DRM 环境敏感数据检索格式,构建敏感数据检索的序列,表示为

式中:ϑ(t,b)为DRM 环境敏感数据在检索过程中的时间序列为敏感数据检索的时间间隔。
步骤4以DRM 环境敏感数据的检索序列为基础,构建DRM 环境敏感数据集,表示为

由于DRM 环境敏感数据具有独立唯一的安全检索办法,所以可根据不同的敏感数据检索关键词,检索到相关的敏感数据,完成DRM 环境敏感数据的检索。
1.2 设定加密约束条件
在设定可检索DRM 环境敏感数据的加密约束条件时,首先要根据干扰环境下的转换因素,对互联网敏感数据所处的位置进行排序[8];然后对已排序好的互联网敏感数据进行分类,保证每一个互联网敏感数据的阈值不低于设定值,并对加密条件进行约束。具体步骤如下:
步骤1DRM 环境敏感数据在可检索加密过程中,为了准确地描述敏感数据,将单位设置为度、分、秒,再对DRM 环境敏感数据Si进行描述,通过度、分、秒代表描述的原始数值,得到下式:

式中:B、C、D分别表示度、分、秒。
步骤2把排列好的DRM 环境敏感数据进行分类,假设原始空间的敏感数据为v,那么将v划分成v i={R1,R2,…,R n},保证其满足任何两个数据类的划分。
步骤3假设DRM 环境敏感数据R n的划分函数为SPlit(R n),那么划分函数的作用是将R n划分为2个类别[9],保证最终每个类别的数值都不低于初始设定的阈值。设定线性划分的期望值为v j(v j∈R n),则通过下式进行计算:

式中:(v s-v i)为DRM 环境检索过程中的范畴参数;i为需要加密的敏感数据方位向量;s为敏感数据的数据值。
步骤4为了对划分后的DRM 环境敏感数据进行实时加密,并保证加密后的敏感数据与原始数据一样[10],假设加密函数为Δ(q),敏感数据密文空间F={f1,f2,…,f m}在H={h1,h2,…,h m}的明文空间上提取,同时敏感数据划分的类别满足
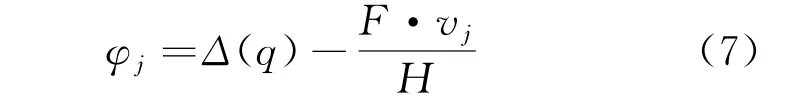
假设通过φfj对可检索敏感数据进行加密,那么得到约束式为
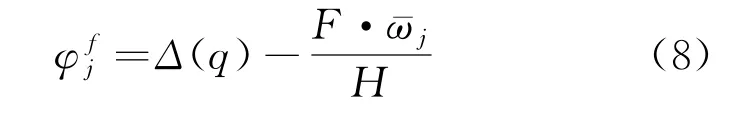
式中:¯ωj为加密后的可检索敏感数据线性划分期望值。
步骤5通过v i对敏感数据类别φj进行描述,进行检索加密的密文为

步骤6令ϑ(y)表示加密函数的计算,则平衡式ϑ(y)的分布可表示为
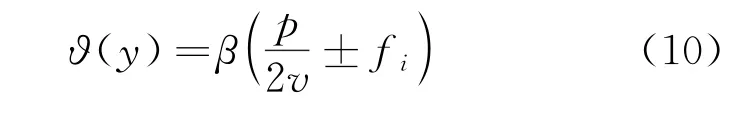
按照上述步骤进行加密约束条件的设定,降低了互联网敏感数据被入侵的危险。
1.3 干扰条件下的加密算法
若最终每个类别的数值皆低于初始设定的阈值,则表明存在干扰条件。为了降低DRM 环境敏感数据信息的损失,通过码元同步找到正交频分复用技术(Orthogonal Frequency D ivision Multiplexing,OFDM)码元的起始位置后,进行OFDM 信号的解调,将时域数据变换到频域。将DRM 环境敏感数据集M中的所有元组进行聚类划分,得到聚类集B。在聚类集B中任意选取2个聚类中心C1和C2进行合并[11-12],生成新的聚类集C,C的质心向量计算公式为
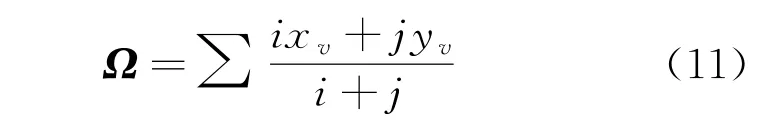
式中:Ω为可检索DRM 环境敏感数据加密的向量值;ix v为敏感数据的元组标识;jy v为敏感数据加密的字符值。
假设u代表C1中敏感数据的任一幅值,则u与聚类中心的距离为
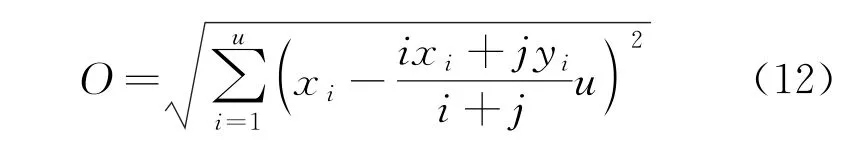
式中:ix i为C1中的i个敏感数据元组中的可检索加密符值,字符值越多,敏感数据的属性越复杂,需要加密的数据量越大,敏感数据元组越大;jy i为C2中第j个元组中的可检索加密元组标识。
将C1和C2进行合并,得到聚类C的可检索加密信息为
L(C1,C2)=L(C1)+L(C2) (13)
式中:L(C1)为C1中i个敏感数据元组所产生的可检索加密信息值;L(C2)为C2中j个敏感数据被检索加密的数值,假设可检索加密敏感数据集C由j个敏感数据元组构成,则敏感数据的属性具有不同的取值[13]。
计算可检索加密的DRM 环境敏感数据值占比为
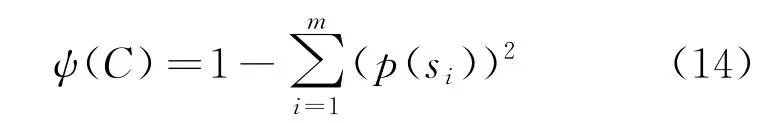
式中:p(s i)表示可检索加密敏感数据集C中的敏感数据占比。
因为OFDM 系统对载波频偏非常敏感,所以经过频率校正后,频率误差应小于0.01倍子载波间隔。假设2个聚类中心C1和C2由敏感数据元组c1和c2构成,得到复杂度为ψ(C1)和ψ(C2)的增益比例为
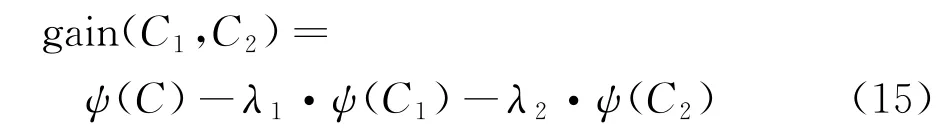
式中:λ1、λ2分别为2次功率调节的系数。
为了在干扰条件下对可检索DRM 环境敏感数据的加密可以满足上述条件,对不同的聚类合并[14],对可检索加密指数进行定义
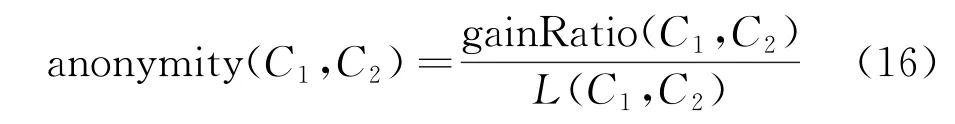
从上述公式中可知,敏感数据的增益值越小,在干扰条件下,DRM 环境敏感数据信息的损失越大,而经过聚类中心合并与优化后,增益值增加,可检索加密指数越大[15]。由此完成检索DRM 环境敏感数据的加密算法的设计,实现了可检索DRM环境敏感数据的加密。
2 仿真实验分析
为了验证干扰条件下可检索DRM 环境敏感数据的加密方法在实际应用中的性能,设计仿真实验。
2.1 测试环境
采用DRM 系统作为测试平台,平台界面如图1所示。

图1 测试平台界面
实验测试过程中,选择Windows 7操作系统,敏感数据可检索加密算法通过Java进行检索实现。利用时间导频信息找到DRM 系统的传输帧起始码元;应用OFDM 调制方式和高级音频编码技术(Advanced Audio Coding Plus,AACPlus),获得数模同播的匹配方案;将模拟信号与数字信号同时以同一载波频率输出;使用正交调制器将低频的基带信号调制为适合在信道中传输的信号,利用频率导频信息计算并校正频率偏差。
2.2 实验数据
以某一公司DRM 环境中存放员工敏感数据的数据库作为实验测试对象。数据库包含2 000份员工敏感数据样本,本文随机选择100份作为测试样本,其余1 900份作为训练样本。表1给出了测试样本中的部分数据。
表1 实验数据样本
在表1的样本数据中,员工的姓名、邮箱、电话以及月工资等均属于敏感数据,整合所有敏感数据,计算其统计学p值为0.2,说明具有统计学意义。以此类数据为实验样本,对其进行加密处理。
2.3 设置评价指标
实验测试分安全性测试和鲁棒性测试两部分进行,先利用入侵软件模拟网络攻击行为,对该公司DRM 环境中的敏感数据进行攻击。
利用攻击成功率衡量敏感数据可检索加密方法的安全性计算公式为

式中:Cz为存放敏感数据的数据库中的总数据量;Cp为破解成功后得到的敏感数据量。
在鲁棒性测试中,利用敏感数据遭受攻击时的信息损失率作为评价指标,计算公式为
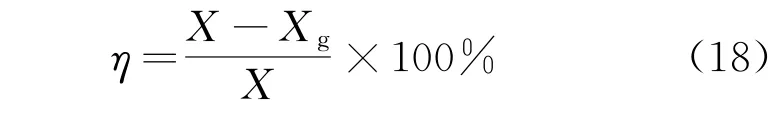
式中:X为敏感信息遭受攻击之前的信息量;Xg为敏感信息遭受攻击之后的信息量。
2.4 安全性测试
在噪声干扰下和滤波干扰下,采用文中方法对DRM 环境敏感数据进行加密,利用DRM 系统给出了攻击成功率测试结果,如图2所示。
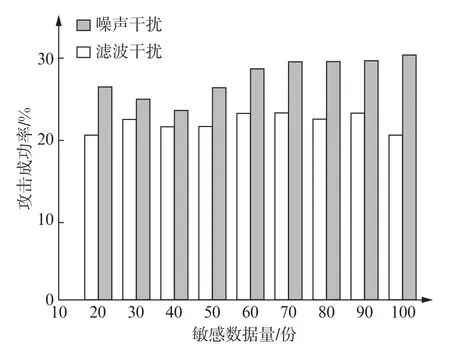
图2 攻击成功率测试结果
图2显示,当DRM 环境敏感数据遭受攻击后,滤波干扰的攻击成功率始终低于噪声干扰。无论是在噪声干扰下还是滤波干扰下,攻击加密后敏感数据的成功率都在30%以下,可以保证敏感数据的安全性。
2.5 鲁棒性测试
当DRM 环境敏感数据遭受攻击之后,测试了敏感数据经过文中方法加密后的信息损失率,结果如图3所示。
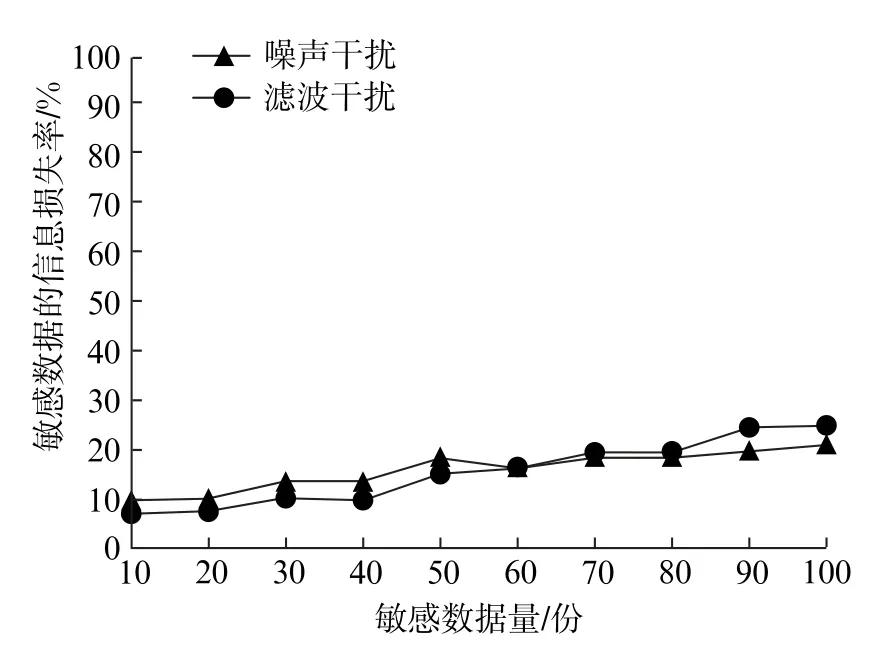
图3 敏感数据的信息损失率测试结果
根据图3的结果可知,在DRM 环境中,遭受攻击的敏感数据经过文中方法的加密之后,敏感数据的信息会损失一部分。当敏感数据量低于60份时,噪声干扰下的信息损失率高于滤波干扰下的信息损失率。当敏感数据量大于60份时,滤波干扰下的信息损失率高于噪声干扰下的信息损失率。在两种干扰条件下,敏感数据的信息损失率都在允许的范围内,说明文中方法在敏感数据可检索加密中具有鲁棒性。
3 结 语
本文提出了干扰条件下可检索DRM 环境敏感数据的加密方法,经过实验测试发现,该方法在加密DRM 环境中的敏感数据时,可以保证敏感数据的安全性,并提高敏感数据加密的鲁棒性。但是本文的研究还存在很多不足,在今后的研究中,希望可以引入同态加密算法,以提高敏感数据可检索加密的安全性。
猜你喜欢
有色冶金节能(2022年1期)2022-03-11
今日农业(2021年1期)2021-11-26
中国种业(2021年7期)2021-08-02
电脑报(2021年14期)2021-06-28
科技经济导刊(2021年1期)2021-01-18
计算机与生活(2020年8期)2020-08-12
网络安全和信息化(2020年6期)2020-06-20
数字通信世界(2020年3期)2020-01-02
软件学报(2019年11期)2019-12-11
计算机与生活(2019年5期)2019-07-18
