
基于融合文本主题模型的学者兴趣挖掘研究
2022-09-07 12:52夏骄雄
计算机时代 2022年9期
陈 锋,夏骄雄,2,3
(1.上海理工大学光电信息与计算机工程学院,上海 200093;2.上海大学计算机工程与科学学院;3.上海市教育科学研究院)
0 引言
兴趣标签作为对科研学者兴趣偏好的集中表达,也逐渐成了学者画像中的“标配”。但随着科学技术的迅猛发展,学术论文、期刊等学术数据呈高速增长趋势,人们越来越难以从海量的学术大数据中抽取出精确的学者兴趣标签,于是如何在有限的时间内从大量文本中提取兴趣标签成为学术大数据信息挖掘的一项重要任务。
传统的学者兴趣标签抽取研究中,循环神经网络常常需要面对在训练中出现的梯度消失或梯度爆炸的问题,还有在文本大数据中处理分类问题的时候,文本数据具有非结构化、稀疏性特征,经常导致分类效果不理想。为解决上述问题,本文利用加权投票法融合 Latent Dirichlet Allocation 和改进的Doc2vec算法得到一种新的结合主题向量和文档向量表示的融合模型,从而有效地提升兴趣标签标注的精准度。
1 相关研究
以往的研究主要是通过用户对网页的浏览内容和浏览时的操作行为进行用户的兴趣发现。而后社交网络兴起,周娜等学者提出将兴趣挖掘的工作建立在无监督的主题概率模型上,从学者自身发表的论文著作的文本信息中挖掘兴趣标签。本文的主要目的在于利用学术数据构建精准的学者标签。兴趣标签构建研究采用LDA 与Doc2Vec两种不同的表示方法,其中文本属性分类模块使用预训练的无监督的Doc2Vec 段落向量模型,其将原始文本转化为向量形式,并利用双向长短记忆循环神经网络(BiLSTM)和带有注意力机制的聚合方式生成文本对各兴趣标签进行表示,然后依据学者和兴趣标签之间的余弦相似度,将相似度最高的五个标签作为学者的兴趣标签,而LDA 利用无监督的主题概率模型进行兴趣标签的分类,将每个人的文本内容合并成一个文本文档,再使用LDA算法捕捉隐藏的主题信息。从而得到作者-主题分布,最后依据加权投票法融合以上两种方法得到的标签结果作为学者最终的研究兴趣标签。
2 整体框架
本文所提出基于融合文本主题模型的学者兴趣挖掘研究的整体框架由四部分组成:基于LDA 主题模型的标签表示、基于Doc2Vec 文本模型的标签表示、学者与兴趣标签相似度计算和结果方法集成。整体结构如图1所示。
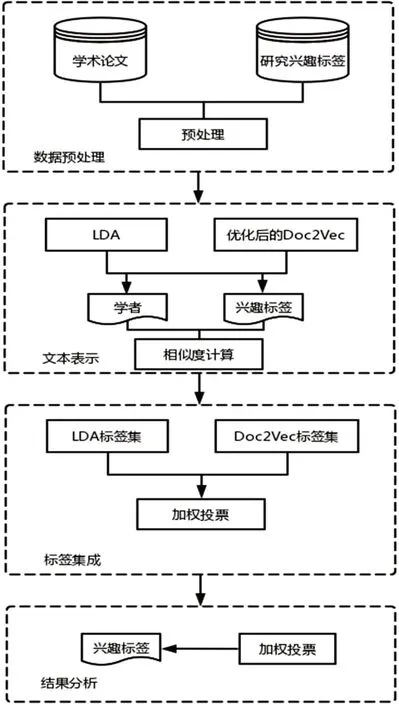
图1 文本主题模型兴趣抽取思路
2.1 基于LDA主题模型的标签表示
本文采用了LDA 主题模型,可以在语义上计算文本内容的相关性,实现文本特征的降维,具体的文本语义特征提取如下所述。
LDA 是一种基于主题的空间模型,它能够通过给定文档集中每个文档的主题,将其以概率分布的形式展现,即文档可以转换为基于主题的值,每篇文档由一组没有相互顺序关系的单词组成,文档中每个单词都依赖于主题而生成。LDA的图模型结构如图2所示。
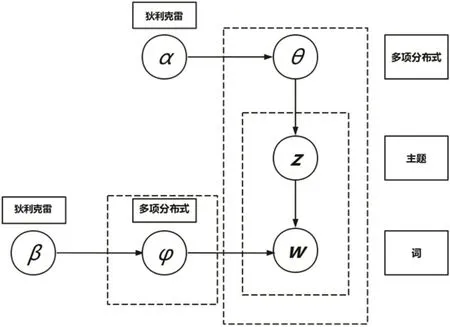
图2 文档主题生成模型结构
2.2 基于Doc2Vec文本模型的标签表示
本文将学者和研究兴趣标签表示成多种词向量形式。Word2Vec 可以提供每个单词的数字表示,并且能够捕获上述关系。
Doc2Vec 是基于Word2Vec 的段落向量模型,Mikolov等人在2013年提出了基于词向量文本表示工具Word2vec 模型,虽然Word2Vec 词向量模型能够基于分布式假说理论高质量得抽取词语的语义信息,但此模型忽视了文本间的语序数据,为了改善此问题,Doc2Vec 模型在谷歌工程师Quoc Le 和Tomoas Mikolov 的努力下逐渐崭露头角。他们添加了用来标记文档的id 的向量作为记录文档的唯一标识,每当模型训练完成的时候,可以同时得到文档和单词的向量表示。本文Doc2vec模型采用了Distributed Memory(DM)隐藏层技术模型,它就像一个记忆体,记住当前上下文缺少的内容。单词向量表示单词的概念,而文档向量表示文档的概念。
2.3 学者与兴趣标签相似度计算
在学术文本语义相似度计算实验中,根据先验知识,学者与研究兴趣标签越相似,表明该标签越能代表学者的研究方向。计算文本相似度是本文的关键理论技术之一,相似程度可以通过考察这些承载文本关键信息的概念词集合之间的相似程度衡量。
本文使用向量余弦值来度量学者和研究兴趣标签之间的相似度。我们可以用不同向量的夹角余弦值来表示它们的差异。这个余弦值通常被称为“余弦距离”。定义兴趣标签向量空间与学者之间的关联关系,需要定义语义相似度如公式(1)所示,其中,X 和Y分别为向量空间中学者向量形式和研究兴趣标签的向量形式,CosSim(X,Y)是两个行向量的余弦相似度,定义如公式⑴。
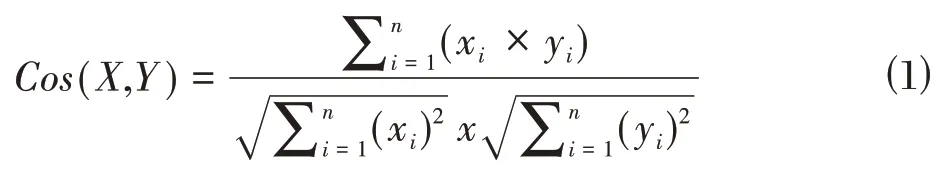
提取文本特征后,可以将学者和兴趣标签向量代入余弦值计算公式,可以得到两者之间的余弦距离。
2.4 结果方法集成
集成机器学习模型是一种常见的提升模型能力的机器学习范式,它可以避免陷入糟糕的局部最优。采用单个学习器可能对泛化的效果不明显,结合多个学习器可以减少这一风险,当集成学习方法正确组合两种或两种以上能解决相同问题的方法后,它将能更有效地提高整体精度。
本文得到的改进的Doc2Vec 模块和LDA 主题模块分别得出了兴趣标签结果,根据文献[12]可知,采用集成方法(Ensemble Method)聚合两个模块的兴趣标签评分可以得到比任意一个模块更好的分类准确率得分。
LDA 主题模块和改进的Doc2Vec 模块分别会为数据集中的学者生成兴趣标签评分。首先计算两个子模块的分类准确率,再将其各自的准确率作为融合权重,将各自的分类评分加权聚合为最终的评分结果,其得分是分类得到的兴趣标签集与给定的兴趣标签完全相同的比例,公式如下:
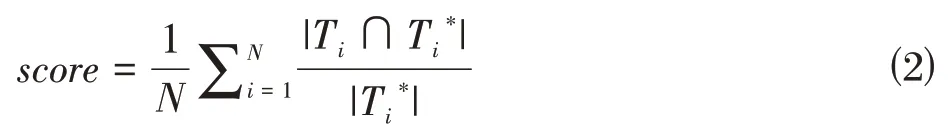
其中,N 为数据集中学者个数,T 为分类得到的学者兴趣标签集,T*为给定的兴趣标签集。
投票法,学习法和平均法是常见的集成学习采用的结合策略。投票法(voting) 常用于分类问题,它以单个分类模型的分类结果为基础,以少数服从多数的原则确定模型预测的类别标签。本文采用的集成方法为投票加权聚合,具体方法如图3所示。
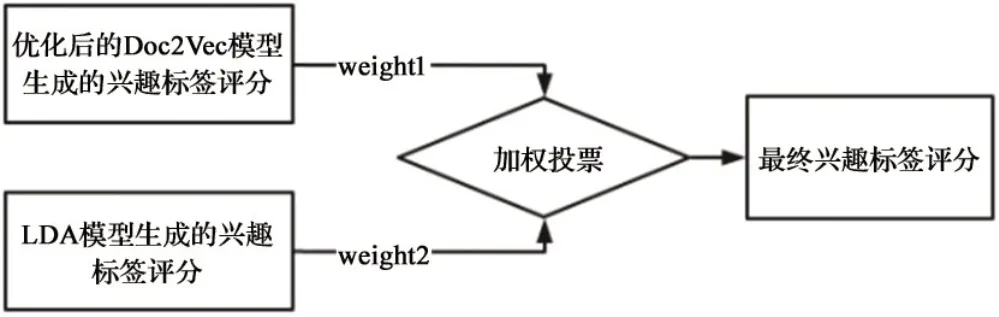
图3 加权投票示意图
得到两个子模块的分类准确率得分后,使用如下公式计算两个模块的权重:

其中,score 表示子模块的准确率得分,weight 表示子模块的权重。利用两个模块的加权各自的兴趣标签评分,公式如下:
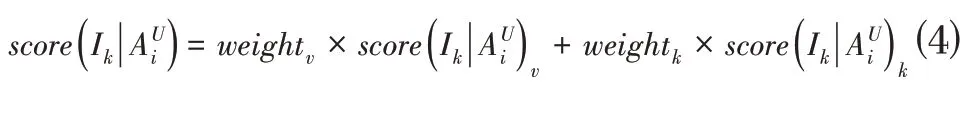
3 实验结果与分析
接下来将按照实验的操作流程介绍数据集、数据预处理、兴趣标签及学者的表示与相似度计算、模型集成步骤。
3.1 数据集
本文实验所用的数据集来源于人工智能和大数据竞赛平台Biendata 提供的“2017 开放学术精准画像大赛”论文基本信息数据集,包含3081998篇发表时间在1936~2016 年间计算机领域内的论文基本信息数据、15367 名学者的姓名、作者的三个兴趣标签,以及大小为1098的标签空间。
3.2 数据预处理
获得学者论文数据之后不能够马上进行处理,本实验首先对数据集进行文本预处理。将文本拆分为句子,将句子拆分为词语,将句子拆分为单词,再删除所有的停用词,把所有单词变换为小写单词并删除标点符号,删除在语料库中出现少于三个字符的单词。最后将过去时态和未来时态的动词都改为现在时态。
3.3 兴趣标签及学者的表示与相似度计算
⑴LDA
在LDA 中,超参数a设置为0.1,pass设置为20,以保证收敛。首先,为每一位学者汇总各自发表的论文,并将每篇论文题目进行连接,形成一个文本文档用来表示学者,然后汇总每一个兴趣标签所对应的学者,连接所对应学者发表的论文题目,形成一个文本文档,用来表示兴趣标签;其次,对这两类文档进行文本预处理,预处理后对这两类文档使用LDA 模型进行了表示,即对学者和兴趣标签都进行了表示,主题数从10 和50 开始试验,再从主题数为100 开始以100 为步长递增的方式进行表示实验对比。如图4所示。
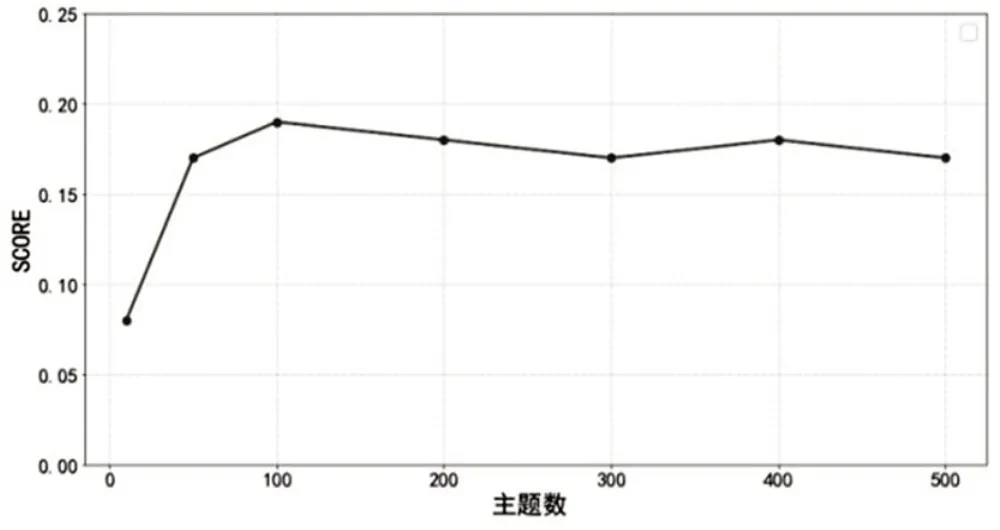
图4 使用不同主题数下展现的评分效果
基于前文提到的科研学者与兴趣标签向量空间相似度方法计算余弦相似度,排名前五的兴趣标签保存为对应的学者感兴趣或主要研究的方向。从图4可以看出,主题数为10时,标注效果较差,此时得到的标注得分为0.088,但随着主题数增加,通过试验分析可以明显发现主题数参数为100的时候达到了区间内的最大值0.197。当主题数继续增加时评分趋于稳定,标注得分为0.15 到0.2 之间。由此我们初步得出结论:主题数参数设置为100 的时候能够更好有效得对主题进行标注。
⑵Doc2Vec
接下来使用基于Doc2Vec 方法的向量空间模型对兴趣标签与科研学者进行向量空间的表示,基于前文提到的科研学者与兴趣标签向量空间相似度方法计算余弦相似度,得到了不同词向量特征数下的兴趣标签标注效果,如图5所示。
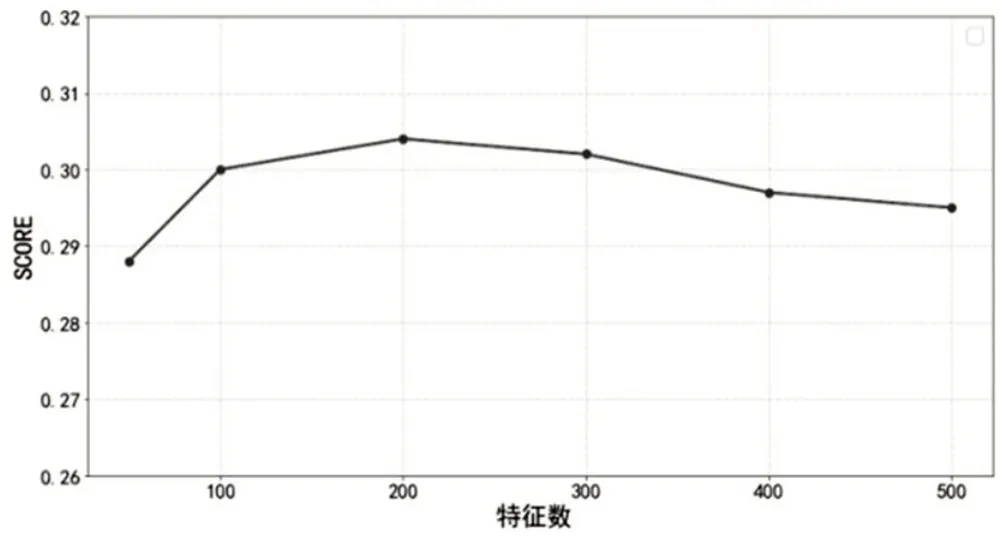
图5 使用不同特征维度下展现的评分效果
从图5 可以看出,词向量特征维度数量从50 开始增加时,再从特征数为100 开始以100 为步长递增的方式进行实验的对比,当维度增加到200维时,兴趣标签标注得分为0.304,此时的标注效果最好,当维度从200 维继续增加时效果逐渐下降。通过对比训练,可以得出当词向量维度为200 时,取得的兴趣标签标注效果最好。
3.4 模型集成
为了得到精准的兴趣标签表示,本文也展开了集成方法的试验,加权投票法作为本次的集成策略。图6展示了不同模型得到的效果评分。
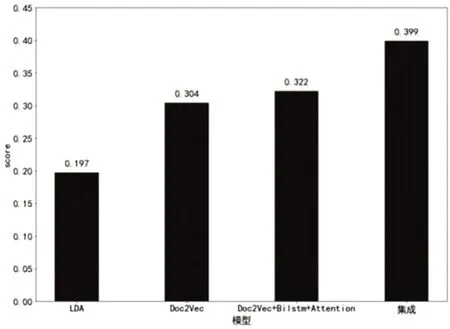
图6 不同模型在数据集的表现
从图6可以看出,LDA、Doc2Vec、改进的Doc2Vec模型和集成模型的评价分别为0.197,0.304,0.322,0.399。因为实验数据的主题差异性比较弱,所以LDA兴趣标签抽取模型较差效果,只有0.197。Doc2Vec 模型是基于句子维度的空间向量表达,因不涉及主题的相关差异性,所以不受到独立领域数据集的限制,更适合处理本文使用的数据集,达到了0.304 的评分。改进的Doc2Vec模型在此基础上利用BiLSTM 模型和Attention 机制,由前后向的LSTM 捕获文本数据文本中的上下文信息,能够很好的处理双向数据的序列信息,Attention抓住文本数据集的重点,因此双向长端记忆神经网络的优化,而再采用了注意力机制加权文本中不同位置的信息,能更好地加强兴趣标签表示效果,改进后的模型提升了0.018 的评分。使用投票加权模型集成的方式有利于LDA 与改进的Doc2Vec模型发挥各自的标签抽取能力,集成模型相较于基础模型有了较大的改善,达到了0.399的评分。
4 结束语
本文通过多源的计算机科学学界的学术论文信息进行学术兴趣标签的抽取研究。我们采用几种不同的文本表示方法,包括LDA、Doc2Vec 和改进后Doc2Vec,对学者和兴趣标签进行表示,其中LDA 尝试在多种不同的主题数进行对比试验,得出区间最优的主题数参数,Doc2Vec 也根据模型在不同维度间的抽取表现得到了区间最优维度参数,接着使用加权投票的策略进行模型的集成得到更优的集成模型,最后利用学者和兴趣标签之间的相似性,即通过科研学者与兴趣标签集合的余弦相似度计算法为每位学者抽取出其最匹配的兴趣标签,通过对比不同建模方法和集成方法下的标注效果,本文发现集成LDA 与改进的Doc2Vec模型能获得更好的兴趣标签标注效果。
猜你喜欢
客联(2022年3期)2022-05-31
管子学刊(2022年2期)2022-05-10
中北大学学报(自然科学版)(2022年2期)2022-05-05
管子学刊(2022年1期)2022-02-17
中国新闻周刊(2021年26期)2021-07-27
中学数学杂志(高中版)(2016年6期)2017-03-01
信息安全研究(2016年4期)2016-12-01
影视与戏剧评论(2016年0期)2016-11-23
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27
职业技术(2015年8期)2016-01-05
