
基于Hadoop云平台的空间属性数据挖掘技术研究
2022-09-08 00:38李娟
南京理工大学学报 2022年4期
李 娟
(金陵科技学院 计算机工程学院,江苏 南京 211169)
Hadoop是一种分布式计算框架,它可以向学者提供云计算服务。Hadoop技术的核心包含Hadoop分布式文件系统(Hadoop distributed file system,HDFS)、MapReduce等,利用此分布式集散框架处理海量数据,具有较高的执行能力[1,2]。因此,通过Hadoop构建云平台,可以更好地处理数据。空间属性是地理信息系统(Geographic information system,GIS)中一类重要而特殊的名词,它包含了大量的空间数据、属性数据及其相互关系。相对于一般的关系数据库系统和事务数据库系统,空间属性系统有着丰富而复杂的语义信息,同时也隐藏着大量的冗余数据。在空间属性数据库数据挖掘中,包含位置和拓扑信息等,属性数据包含了空间属性数据库的名称、分类、数值等信息;通常应用在时序特征数据挖掘和非空间型数据挖掘中,对数据进行采集、储藏、管理以及分析等。
由于社会的高速发展,GIS得到迅速更新,如何对应用于GIS的空间数据与属性数据进行挖掘是当前较多学者正在研究的问题。其中,空间数据实质上是空间对象自身的空间定位特征[3,4],而属性数据描述的是空间对象的特征反应,将两者结合,即为空间属性数据,有较多学者对这一数据挖掘过程进行了研究。孙红等[5]研究融合遗传算法和关联规则的数据挖掘技术,申燕萍等[6]研究基于云计算平台的仿生优化聚类数据挖掘技术,但在数据挖掘过程中仍然需要面对数据挖掘速度较慢、无法较为完美地对数据实现去噪等问题,因此本文提出基于Hadoop云平台的空间属性数据挖掘技术,构建Hadoop云平台,在这一平台中实现对空间属性数据的挖掘。
1 空间属性数据挖掘技术
1.1 Hadoop云平台构建
Hadoop是一种较好的数据处理技术框架,它的性能表现稳定,可以将其用作云计算的基础设施。Hadoop云平台是一种分布式的、可在低配置的硬件设备上运行的架构,能够为应用软件提供可靠的界面,具有良好的可扩展性、可靠性和可移植性。在Hadoop框架下利用MapReduce计算模型与HDFS构建实现空间属性数据处理的云平台。具体内容如下所示:
1.1.1 MapReduce原理
MapReduce是于一种可以高效实现空间属性数据处理的分布式编程模型,可通过两部分实现具体工作,分别为Map部分与Reduce部分。用户可设定一个Map函数,通过此函数处理初始数据,处理后得到一组键值对(key/value),之后用户可再次设定一个Reduce函数,通过此函数合并全部具备同样key值的中间结果[7,8]。
利用MapReduce将输入的内容调整为大量各自独立的小任务,并通过Map函数对这些小任务进行处理,获取单个键值对,中间结果会暂存至内存[9]。之后利用Shufle,将Map输出过程调整为Reduce的输入,可利用Hadoop自备的合并器实现Map输出中间结果的首次合并。当初步输出完成后,Reduce对输出结果进行复制,这一复制过程称为Reduce任务的copy过程。Reduce在进行copy时可以存在大量复制线程,所以可通过并行的形式复制Map输出。当全部Map输出均被复制时,Reduce开始进行排序操作,排序的过程实质上是按Map输出的初始顺序完成排列[10],且循环实现排序操作。当排序完成后,Reduce开始合并数据输入Reduce函数。
1.1.2 搭建HDFS
HDFS是Hadoop框架下一种可实现数据分布式保存与管理的并行文件系统。HDFS由大量数据节点DataNode与一个名字节点NameNode构成。在DataNode中,每个文件都会被均匀调整为数量不等的64M数据块,且通过分散的形式保存在不同DataNode上。同时,HDFS还具备数据备份功能,HDFS以默认形式将每个数据块制造出3个副本[11],并依次放置在不同机器中,当用户通过NameNode获取数据位置信息时,可与放置数据块的DataNode进行直接通信[12]。
1.1.3 基于Hadoop云平台的数据挖掘设计
基于上述Hadoop云平台搭建过程,利用分层理论,通过分层形式搭建数据挖掘云平台。在云平台中,从上至下每层都具备调用下层的接口,这使得每层不仅具备独立功能,还可以完善云平台的功能。具体Hadoop云平台的整体结构如图1所示。
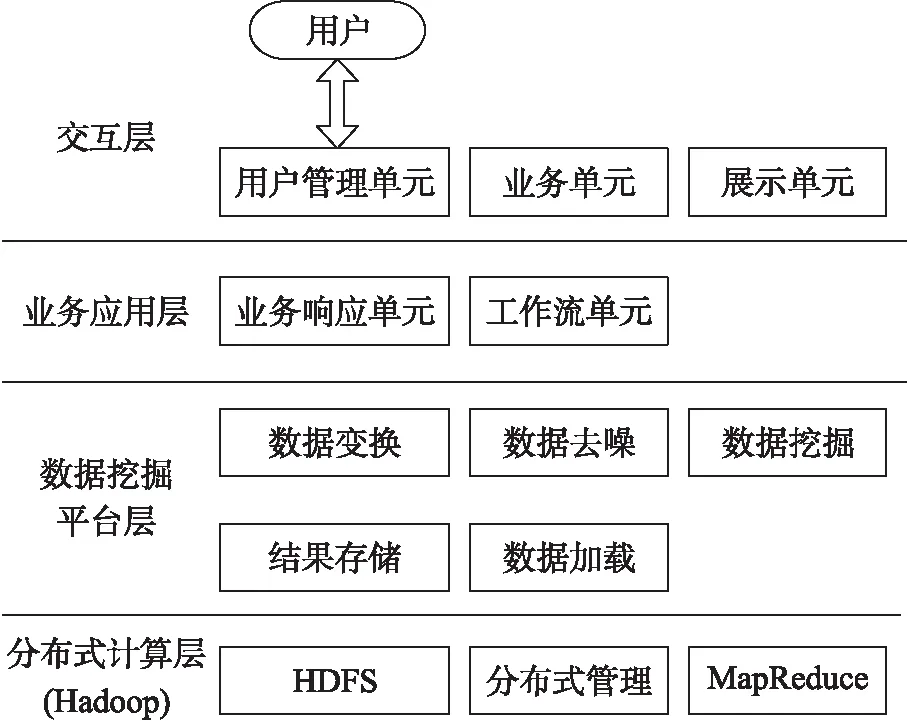
图1 Hadoop云平台的整体结构
(1)交互层。这一层主要提供交互接口。利用图形界面向用户展示平台内容,用户可通过登陆查看与操作。这一层共具备以下单元:
①用户管理单元:此单元可以设置用户权限,并完成用户身份的验证。
②业务单元:用户利用此单元提交需求。
③展示单元:用户可通过此单元查询、存储业务结果,同时平台的执行结果通过此模块反馈至用户。
(2)业务应用层。这一层可调用下层中已完成的各个单元中的业务,并调用数据挖掘层的执行结果。同时,这一层还可以实现对下层执行进度的控制。这一层具备以下单元:
①业务响应单元:通过调用下层单元实现需完成业务的子业务的调用。
②工作流单元:管理与监控业务执行情况,并将监控结果返回至业务响应单元。
(3)数据挖掘平台层。
这一层向业务应用层输送数据挖掘过程中所需单元的执行结果。它属于本文Hadoop云平台的核心层,利用这一层实现空间数据数据挖掘业务,并向下层提交业务结果进行计算,计算完成后,向业务应用层输送挖掘结果。本层具备以下单元:
①数据转换单元:利用此单元实现空间数据与属性数据的统一。
②数据去噪单元:通过快速独立成分分析(Fast independent component analysis,FastICA)算法实现空间属性数据去噪。
③数据挖掘单元:在此单元中利用贝叶斯分类算法实现空间属性数据挖掘。
④结果存储单元:此单元类似于知识库,用于保存挖掘过程中制造出的各种模式。
⑤数据加载单元:此单元对空间数据数据进行注册,并将其保存至云平台的HDFS内。
(4)分布式计算层。利用Hadoop框架完成集群保存与计算。Hadoop完成对云平台的管理并提供了云平台的运行模式。
1.2 空间属性数据变换
在进行数据挖掘之前,由于空间属性数据量纲与类型不同,且数据之间的关系也呈线性与非线性两种状态,因此,需采用数据转换方法对空间属性数据进行一定的预处理[13,14]。即将空间属性数据尽可能调整为正态分布,并统一数据量纲[15]。
在空间属性数据转换过程中,为了不让数据损失,且不增加干扰,通过数学逻辑形式,设定一个全新的空间属性观测值,通过式(1)表示
U=F(R)
(1)
式中:初始观测值由R表示;变换的函数由F表示;U表示新的空间属性观测值。当前较为流行的变换方法有均匀化变换、归一化变换等。为实现空间属性数据量纲的统一,本文采取归一化变换,将全部数据变化限制在0~1之间,即变换后的数据变量最小值为0,最大值为1。
1.3 空间属性数据去噪
1.3.1 基于FastICA算法的空间属性数据去噪
空间属性数据经转换后虽然可以进行数据挖掘,但为进一步提升数据挖掘的精准度,在数据挖掘之前,利用固定点算法即FastICA算法对数据进行去噪。此算法在每次迭代时,通过成批操作来采样数据[16,17],属于并行分布式算法。FastICA算法在使用时依据非高斯性最大化理论,在计算过程中,利用固定点迭代原理,计算出wTq的非高斯最大值(T表示时间),同时利用牛顿迭代算法,以成批操作形式处理观测变量q的若干采样点。FastICA的非高斯型度量函数如下
J(y)∝[E{G(y)}-E{G(v)}]2
(2)
利用式(2)估计独立分量,其中,∝的含义为正比;期望值由E(·)描述;非线性函数由G(·)描述;v与y表示零均值高斯变量,且两者具备相同方差。
为获取第i个独立分量,或计算得到yiwTq的投影位置,利用式(3)将式(2)的计算结果最大化,其理论依据是式(2)非高斯型度量函数是客观存在的规律,同时也是计算的依据,为计算提供了正确的思维方式,保证了计算结果最大化的合理性和可行性,具体公式如下
JG(w)=[E{G(wTq)}-E{G(v)}]2
(3)
式中:m维变量由w表示;其中,q与v具备一致的均值与协方差矩阵的高斯变量,当处理完成后,可将式(3)的最大化过程视为E{G(wTq)}的优化过程。根据Kuhn-Tucher理论,当E{(wTq)2}=‖w‖2=1时,可利用牛顿迭代法对E{G(wTq)}的优化过程采用式(4)计算
(4)
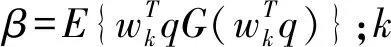
wk+1=wk+1/‖wk+1‖
(5)
同时,将式(4)两边数值与β-E{G′(wTq)}相乘,得出wk+1迭代计算后的结果
(6)
1.3.2 FastICA算法具体操作步骤
步骤1设初始权值矢量w0为随机获取,并设k=0;
步骤2通过式(6)对权值矢量wk+1进行更新;
步骤3对wk+1=wk+1/‖wk+1‖进行归一化处理;
步骤4若|wk+1-wk|>ε,则算法停止收敛,若未实现,则跳转回步骤2继续执行,直至估算出一个独立分量后结束收敛。
若想实现多分量提取,反复执行算法进行分离即可。若要确定每次提取出的分量均不是相似分量,则需在每次完成一个分量提取后,将此分量从观测信号中剔除掉,反复进行剔除操作,即能够提取全部所需独立分量,执行完成后,即可实现原始空间属性数据的去噪处理。
2 空间属性数据挖掘技术
2.1 贝叶斯分类
在大量数据挖掘算法中,贝叶斯分类算法应用较为广泛,且此算法适用于多种类型的数据。贝叶斯分类实质是依据历史训练数据,挖掘出数据性质。通过贝叶斯分类构造出的分类模型,也称为分类器,利用此分类器,可以知道待分类数据属于哪部分[18]。本文利用贝叶斯分类进行空间属性数据的挖掘,将上述去噪后的数据应用于贝叶斯分类过程中,能够有效提升挖掘的精确度。
2.2 贝叶斯定理

P(A|B)P(B)=P(AB)=P(B|A)P(A)
(7)
式(7)的计算过程可以称为概率乘法规则,假设P(B)属于非零状态,当两边同时除以P(B)时,可得式(8)
(8)
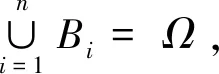
(9)
式(9)即为贝叶斯定理的通常形式。
2.3 极大后验假设与极大似然假设
给定类别集合C,也称为待选假设集合,并设一个假设为c,两者满足c∈C;设标号样本为X;若假设c为可实现假设,则通过P(c)表示,即P(c)为c的先验概率,同时设X的先验概率为P(X);当假设c为可实现时,X发生的概率由P(X|c)表示,利用贝叶斯定理实现对它的计算
(10)
当标号样本X处于已设定的状态时,配合贝叶斯理论,可获取可能性最高的未知假设c∈C,因此可将c表示为极大后验假设,通过CMAP描述极大后验假设,并通过式(11)计算
(11)
通常情况下,假设c与先验概率P(X)不存在关系,因此,可将式(11)调整为式(12)
(12)
当无法得出类别发生概率时,可认定全部类别的先验概率相等,即认定任意的ci,cj∈(i≠j),可实现P(ci)=P(cj)。先验概率不会对可能性最高的假设的计算造成影响,所以,计算出P(X|c)的最大值即可,同时P(X|c)称作极大似然假设,表示为CML,计算过程如式(13)所示
(13)
2.4 朴素贝叶斯分类模型
朴素贝叶斯分类器(Naive bayes classifier,NBC)是当前数据挖掘技术中应用较广的一种分类器。此分类器中,包含变量集U={X,C},其中类变量集为C={c1,c2,…,cm},具备m个取值,属性变量集为X={x1,x2,…,xn},具备n个条件属性,若已设定属性变量之间不存在影响,且各自独立,则可通过式(14)描述朴素贝叶斯分类器
(14)
通过上述过程,即能完成对空间属性数据的挖掘,同时利用朴素贝叶斯分类器,可有效降低网络计算复杂度,由此完成基于Hadoop云平台的空间属性数据挖掘技术研究。
3 试验分析
将本文平台应用至某城市农业区域,对这个区域中的空间属性数据进行试验分析。从农业生产的气象条件来看,在农业生产中,不同地区的气象要素如降雨量、日照时长、温度值等,都会对作物生长产生不同影响,需要采取不同的管理措施。通过不同管理措施,产生如表1所示参数的具体选择。

表1 试验参数设置表
由表1可知,以这5种参数类型为研究对象进行空间属性数据挖掘技术试验分析,根据农业气象要素的分段取值,气温分为特别低、偏低、正常、偏高以及特别高5种;降水量可分为特别大、偏大、正常、偏小以及特别小5种类型。农业生产场景如图2所示,应用基于Hadoop云平台的空间属性数据挖掘技术后,得到的农业生产场景如图3所示。

图2 农业生产场景如图

图3 应用所设计技术后农业生产场景
由图2和图3可知,应用所设计的空间属性数据挖掘技术后,农业生产场景更加有序。根据空间属性数据挖掘技术,从属性数据中挖掘出指导农业生产的有用知识,并将此数据挖掘技术应用在农业种植管理中,能增加经济效益,极大程度地节省成本,成为经济复苏的有力支撑。
分析挖掘节点不断增加的情况下,选取文献[5]融合遗传算法和关联规则的数据挖掘算法和文献[6]基于云计算平台的仿生优化聚类数据挖掘算法作为对照组,与本文算法进行对比。3种算法挖掘时的加速比如图4所示。

图4 数据挖掘技术加速比性能分析
根据图4可知,随着节点数量的上升,本文技术挖掘加速比也随之增加,在节点个数为10时,加速比最大值达到10;而文献[5]算法和文献[6]算法的加速比分别为6.3和5.9,本文技术挖掘加速比与之相比分别提高了3.7和4.1,由此可知本文技术可有效实现空间属性数据的并行挖掘。同时,本文算法挖掘的加速比均保持在4以上,说明利用本文技术挖掘数据时,可有效提升数据挖掘的速度。
选取不同噪声污染比例的数据,分析当测试数据的数量不断增加时,通过本文技术去噪后的峰值信噪比变化情况,结果如图5所示。
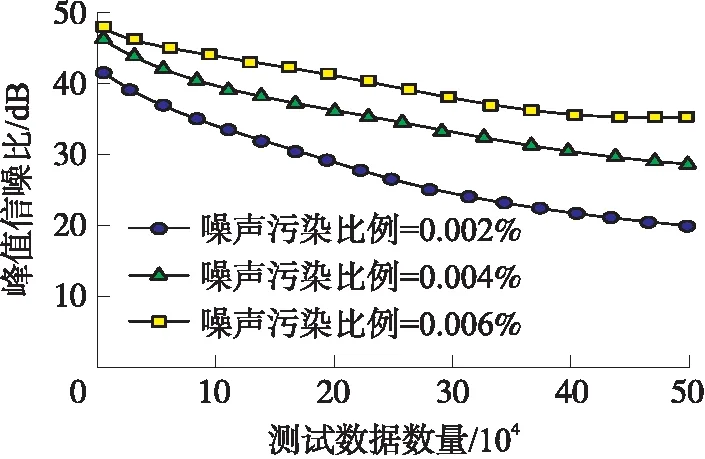
图5 空间属性数据去噪效果
根据图5可知,当测试数据数量不断增加,去噪后空间属性数据的峰值信噪比也有所降低。在不同噪声污染比例下,当噪声污染比例为0.006%时,去噪后的峰值信噪比保持最高,证明本文技术对含噪比例较大数据的去噪效果更显著。虽然在数据数量为50万条时信噪比有所下降,但利用本文技术去噪后峰值信噪比始终保持在20 dB以上,由此可知,本文技术能够较好地实现数据去噪。
选取3组数据集,其中数据集1共有10万条数据,数据集2共有20万条数据,数据集3共有30万条数据,分析在不同时间下对空间属性数据进行去噪时的数据结构相似度,结果如图6所示。

图6 去噪时空间属性数据结构相似度
由图6可知,当时间不断增加,本文技术在对空间属性数据进行处理时的数据结构相似度也有所上升。同时,虽然数据集越大在去噪时的结构相似度越低,但本文技术在去噪时的结构相似度始终保持在0.8以上,因此利用本文技术进行去噪时可有效保障数据的完整。
综上所述,应用所设计的基于Hadoop云平台的空间属性数据挖掘技术后,农业生产场景更加有序,利用本文技术挖掘数据,可有效提升数据挖掘的速度,能够较好地实现数据去噪;当时间不断增加,本文技术在对空间属性数据进行处理时的数据结构相似度也有所上升,进行去噪时可有效保障完整的数据结构。
4 结束语
本文研究基于Hadoop云平台的空间属性数据挖掘技术,通过搭建Hadoop云平台实现对空间属性数据的多角度处理,在平台中设计数据挖掘技术,利用朴素贝叶斯分类器完成空间属性数据的挖掘。朴素贝叶斯分类器能够有效提升挖掘的精确度。利用本文数据挖掘技术,能够较好地实现数据去噪,有效保障数据的完整,挖掘结果较为精准,有效提升数据挖掘的速度,将其应用在农业生产中,能增加经济效益。在后续研究中,可继续优化本文技术,使这一平台可应用至各个领域中,实现多种数据的挖掘。
猜你喜欢
中国现代医生(2022年21期)2022-08-22
消费电子(2022年5期)2022-08-15
阅读与作文(英语初中版)(2019年8期)2019-08-27
智富时代(2018年11期)2018-01-15
智富时代(2018年11期)2018-01-15
科教导刊·电子版(2017年32期)2018-01-09
数学学习与研究(2017年10期)2017-06-22
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
