
一种基于机器学习的网络流早期分类方法
2022-09-20 01:41董育宁
南京邮电大学学报(自然科学版) 2022年4期
项 阳,董育宁,魏 昕
(南京邮电大学通信与信息工程学院,江苏 南京 210003)
近年来,随着互联网和多媒体技术的快速发展,网络流量大幅上升。根据Cisco的预测报告[1],到2022年,视频流量将占所有网络流量的82%。因此,网络视频流分类对网络资源管理和多媒体业务的 Quality of Service(QoS)保障具有重要的意义[2]。而流早期分类(Early classification,EC)更适应于当下的高速网络环境,并且可以更好地保障QoS[3]。
网络流分类主要可以分为以下4种方法:基于端口、深度包检测[4]、基于机器学习 (Machine learning, ML)[5]和基于深度学习(Deep learning,DL)[6]的方法。然而,由于新型网络应用层出不穷,加密传输、动态端口号等技术的出现使得前两种方法对流分类的准确率大为降低[7]。而基于ML的方法大多利用基于流和基于包的统计特征[8]就可以完成分类任务;基于DL的方法可以将数据包的有效负载直接输入[9]或是转化成图片输入[10]就可以完成流分类。这两种方法都不需要利用端口号或是加密信息,并且能获得较高的分类精度。
随着ML和DL技术的不断进步[11-12],网络流分类取得了高精度的效果[13-15]。然而,由于网络速率的不断提高,面临的挑战不仅是分类的精度,更要求具有实时性[16]。传统的统计特征需要从持续时间较长的流中提取才能得到较高的精度,而这需要等待流结束或大部分流通过才能计算,滞后了分类时间[17];基于DL方法的计算复杂,需要花费较多的时间才能完成分类[18]。针对这个问题,本文设计了适用于EC的特征,用少量的数据包完成分类,即可获得较高的准确度。同时,在特征选择时还把其计算复杂度作为选择标准之一,旨在减少流处理时间。此外,还提出了一种层级分类方法(Hierarchical classification,HC),可以适用于不同的实时分类场景。
本文方法主要是结合包大小和时序信息提出两种适用于EC的流特征。通过计算复杂度分析和三段式的特征选择(Feature selection,FS)方法降低特征维度,减少特征提取(Feature extraction,FE)的时间。能够在分类过程中先使用少量数据包完成视频/非视频的二分类,之后使用更多的包完成细粒度的应用层面分类,从而完成流早期分类。本文的主要贡献如下:
(1)提出了基于包大小等级的条件频度,将相邻包大小等级和到达顺序结合形成一种新的特征。同时设计了将包大小序列除以时间间隔序列得到一个新的序列,称之为速率序列。这两种特征有利于完成EC任务。在传统统计特征基础上,设计的特征能够有效改善流EC性能。
(2)提出了一种HC方法,先通过到达的少量连续数据包完成对Non-videos/videos的二分类,再根据分类结果使用后续数据包完成更细粒度的分类,从而提高整体的分类准确度。同时,采用流式计算来计算该方法的特征。该方法不但适用于不同的分类场景,也能在一定程度上改善流分类性能。
(3)在2个真实数据集上测试了方法的普适性。相较于已有方法,本文方法在不同流段长度(Segment length,SL)(即数据包个数)上都具有优势。
1 相关工作
1.1 特征提取方法
目前,统计特征和时间序列特征在网络流分类领域使用广泛。例如,Baldini[19]对从流中提取的统计特征归一化后进行时频分析,验证了维格纳-威利分布(Wigner-Ville distribution,WVD)比恒 Q变换(Constant-Q transform,CQT)和连续小波变换(Continuous wavelet transform, CWT)更有效。Areström等[20]提出了一种适用于EC的基于时间序列的多重分形FE方法。该方法创建了一个时间序列用来提取两组多重分形特征,分别是Holder指数和Huasdorff指数,经过主成分分析(Principal component analysis,PCA)选择特征后使用支持向量机(Support vector machines,SVM)模型进行分类,实验表明对于20 s流的准确度可达95.8%。Perna等[21]提出了一种基于决策树模型的实时分类方法,通过从原始序列产生4种序列分别提取统计特征,完成对1 s数据包序列的分类,准确率可以达到97%。上述方法都需要使用不少于1 s长度的数据包序列进行分类,但随着网络速率的提高,需要使用更少的数据包,才能满足实时早期分类。针对这一问题,Shi等[22]提出了 SpBiSeq方法,分别提取出上下行有效负载序列和双向有效负载序列作为特征输入,在使用10个数据包时,准确率为88.9%。本文提出的特征结合了统计特征和包的时序信息,可以更好地改善EC的分类准确性。
1.2 特征选择方法
FS能够有效降低特征维度,减少模型训练的复杂度,也能在一定程度上改善流分类的性能[23]。现有的FS方法,主要分为过滤式、嵌入式和封装式3种。例如,Aouedi等[24]对基于决策树的各种模型与FS方法在准确率、训练和分类时间方面进行了对比分析,得出通过递归特征消除可以识别出有效的特征从而提高机器学习模型准确性。同时,基于时间序列的FS方法研究也取得了一定的成果。如,Pasyuk等[25]介绍了序列FS方法,如序列向后选择、序列向前选择等,验证了序列前向选择和前向浮点选择更适合于网络流媒体分类。但现有FS方法都是以分类准确度为优先进行选择,没有考虑到各个特征的时间消耗。在高速率网络下,FE的时间消耗会影响到分类的实时性。因此,本文对特征进行了时间复杂度分析,选择复杂度小的特征作为初始特征集合,之后进行筛选,有效减少了FE时间。
2 本文方法
图1给出了本文所提的HC方法框图。为了提高EC准确性,将包大小和数据包时序信息结合起来,提出了条件频度和速率序列特征,这些特征能够提供更多的有效信息用于流分类。同时为了能够提高分类的速度,结合计算复杂度分析,用过滤式和嵌入式方法进行 FS,减少了 FE和分类器的计算开销。另外,为了适应当下视频流量占多数的网络环境,采用视频/非视频二分类器和视频多分类器以及非视频多分类器进行级联,在流早期阶段就可以完成是否是视频流的判别;如需进行更细的分类,将二分类结果输入到后续分类器中完成细粒度分类。对于不同的分类任务,都通过FS选出合适的特征(图1中不同分类模块中的特征选择)以提高分类的准确性。该方法可以灵活地应用于不同的分类场景。
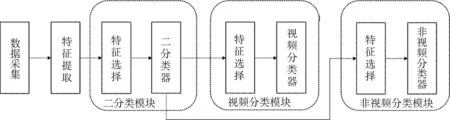
图1 本文HC方法框图
2.1 数据集
2.1.1 南邮数据集
用PC机通过WireShark在南京邮电大学校园网于2019年抓取了6种不同类型的网络应用流数据;在家庭网络环境下于2022年抓取了网络游戏类型的数据,共3 667条,如表1所示。该数据集(本文称为南邮数据集,或ND)包括视频点播、视频通话、视频直播、网页浏览、网络游戏、网络音乐和网络下载。每条流的长度为1 min,包含1 min内的连续数据包。采集的数据包信息为五元组:包到达时间、源地址、目的地址、包大小以及传输协议。

表1 南邮数据集(ND)
2.1.2 ISCX数据集
为了验证本文方法的普适性,还使用了表2所示的ISCX公共数据集[26]进行验证。

表2 ISCX数据集
2.2 特征提取
2.2.1 统计特征
将采集到的数据划分成包大小序列、包到达时间序列、时间戳序列和包差值序列,分别对这4个序列计算如表3所示的17个统计特征,共得到68个特征。

表3 流段(包序列)统计特征
2.2.2 条件频度
将原始的包大小序列分为上行和下行包大小序列,对二者进行等距分箱划分包大小等级,由于上行包相较于下行包数目比较少,所以上行包大小只划分了两个等级,下行包大小划分了5个等级。条件频度为某个方向相邻到达的两个数据包,前包为等级i,后包为等级j的事件发生的次数。
2.2.3 速率序列
不同于传统的统计特征,设计用相同方向的包大小序列除以时间间隔序列得到一个新的序列,称为速率序列,并计算相应的特征,如表3所示。
2.3 特征选择
2.3.1 FE复杂度分析
对于在线分类,需要按极高的线速率进行流分类,这就要求FE尽可能快。为此,进行了FE时间复杂度分析作为初步的FS,排除时间复杂度较高的特征。传统统计特征的时间复杂度如表4所示。同时,由于条件频度的计算只需要遍历一遍包大小序列,所以它的时间复杂度为O(n)。n为包序列的长度。

表4 流段(包序列)统计特征的时间复杂度
通过时间复杂度分析,首先除去时间复杂度大于O(n)的特征;因此,保留下均值、标准差、峰度、偏度、最大值和最小值以及条件频度。同时考虑到计算机在执行复杂的非线性计算时也耗时较长,所以进一步筛除标准差、峰度和偏度。最后,仅留下均值、最大值、最小值以及条件频度。
2.3.2 特征相关性分析
结合过滤式和嵌入式方法,用以下3步实现FS。
(1)特征与标签之间的相关性:通过计算特征与标签之间的皮尔森系数[21],赋予每个特征一个重要性分数。
(2)特征之间的相关性:计算所有特征两两之间的皮尔森系数,当发现两个特征之间的皮尔森系数大于设定的阈值(实验中取0.9)时,删除重要性较小的特征,完成第一次特征选择。
(3)极限树特征选择:通过极限树[21]模型对第二步剩下的特征进行排序。然后根据重要性程度逐个增加特征观察分类性能的变化,直到分类性能变化稳定,获得最优特征子集。由于存在相关性较大的特征组情况,基于树的特征排名是有偏差的,所以第二步删除相关性较大的特征对极限树特征选择至关重要[21]。
2.4 层级分类方法
不同于平坦结构分类(Flat classification,FC),HC先完成视频/非视频的二分类,后续的多分类器完成各自的多分类。同时,针对每一次分类,HC都选择出适合该分类的特征子集,以期达到最佳的分类性能。这样,相对每一个分类任务来说,分类类别数有所减少,准确性会有所提高。同时可以更早地判定是否是视频流,从而启动相应的QoS保证策略(例如,对应的网络带宽分配,QoS路由选择等)[3]。
此外,引入了流式计算方法来计算特征。其优点是对数据包执行管道计算,不需要等所有数据包到达才能计算,加快计算速度。同时,HC后一级不用保存前面的数据包以节省存储空间;均值计算如式(1)所示。
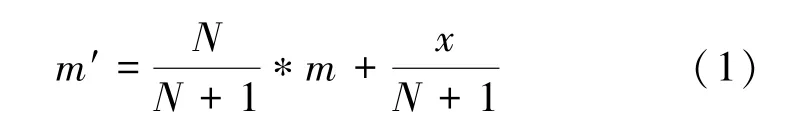
式中:m′表示新的均值,N为当前序列个数减1,x为当前值,m表示之前的均值。相应地,对于最大值和最小值来说只需保存之前的最大、最小值即可,而条件频度只需不断加一即可。因此,HC第二级的特征计算可以复用第一级相同的特征计算结果。同时,通过将二分类、视频多分类和非视频多分类的特征子集求并集,为整个HC的特征集合;那么HC的FE时间就是该并集的计算时间。
3 实验与分析
3.1 评估指标
实验的评估包括分类准确性、时间性能以及内存占用评估。
3.1.1 分类准确性指标
采用总体准确度(A)来量化分类器的性能,如式(2)所示。
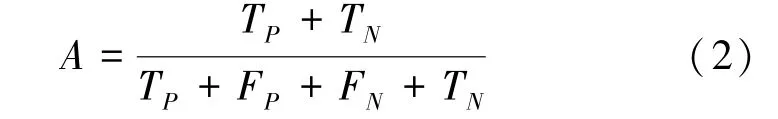
式中:TP和FP分别表示该类被正确分类和被误分类的样本数;FN和TN分别表示其他类被误分类和被正确分类的样本数。
3.1.2 计算性能指标
计算性能主要分为两个部分,一方面是特征提取的计算性能(Feature extraction performance,FEP),表现为每秒能够提取特征的样本数;另一方面是分类器的计算性能(Classification performance,CP),表现为分类器每秒可以识别的样本数。最后,将FEP和CP整体考虑,得到总体的计算性能(Total performance, TP)。
3.1.3 模型的内存占用指标
分类模型的内存使用(Model memory usage,MMU)主要依赖于所选择的模型、特征维度和超参数的设置,本文用python中pikcle包的dump函数保存的模型大小来反映模型的内存消耗。
3.2 实验参数设置
分类器采用 RF,树的数量设为 150,min_samples_leaf(MSL)为1。采用10折交叉验证评估分类性能。 与文献[20],[21]和[22]方法进行分类性能比较。所有实验分别在硬件配置为Intel i5-4500H CPU@3.4 GHz,8 GB内存2 GB显存的笔记本电脑(机器 1,或 M1)、Intel i5-8400U CPU@2.80 GHz(机器2,或M2)和8 GB内存的台式电脑完成,操作系统都为Windows10 64位。
3.3 不同FE方法FC的性能对比
将本文方法与文献方法分别在ND和ISCX数据集上设置 SL 为 5、10、20、50、100、200 进行实验,结果如图2至图5所示。
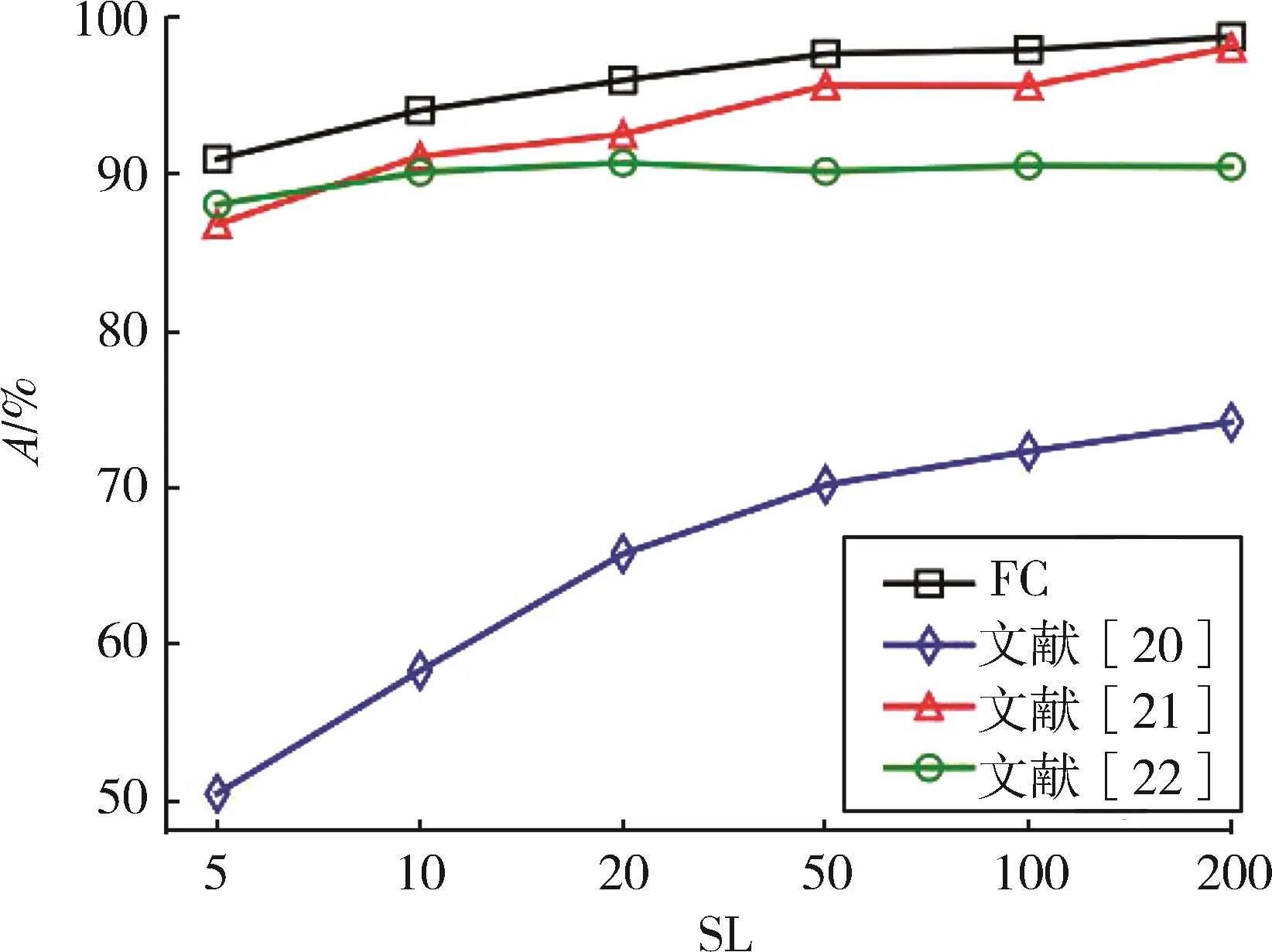
图2 ND不同SL各方法的A对比
从图2可知,本文方法在不同SL情况下都要优于其他3种方法。可能的原因是文献[22]直接将上、下行和双向有效载荷的序列简单地作为特征输入,忽略了包与包之间的联系;文献[20]从包序列离散成时间序列提取分形特征,这需要大量的数据包才能得到较好的分类性能,因此不适用于短数据包序列的早期流分类;文献[21]仅使用传统的统计特征,在包数目增多时可以达到较好的分类效果,但在包个数低于20时,由于无法获得稳定的统计特征,导致分类性能变差;本方法使用了少量统计特征,新特征条件频度反映了相邻包之间的联系,以及速率序列反映了流速率的信息,这些信息在数据包个数较少时可以改善分类性能,适用于早期流分类。
图3展示了4种方法不同SL的FEP、CP和TP对比。在FEP方面,本方法要优于其他3种方法,说明根据时间复杂度筛选特征可以改善FEP;在CP方面,由于使用相同的分类器,各方法的CP差距不明显;在TP方面,本文方法优于其他3种方法。4种方法的性能瓶颈也有所不同,本文方法和文献[22]的瓶颈在于 CP,而文献[20]和[21]在于 FEP。同时,不同的硬件配置也有影响。

图3 ND不同SL各方法的FEP、CP和TP对比
从图4和图5可知,本文方法在ISCX数据集上的分类准确性和时间性能同样优于其他3种方法。说明本方法具有一定的普适性。

图4 ISCX不同SL各方法的FEP、CP和TP对比
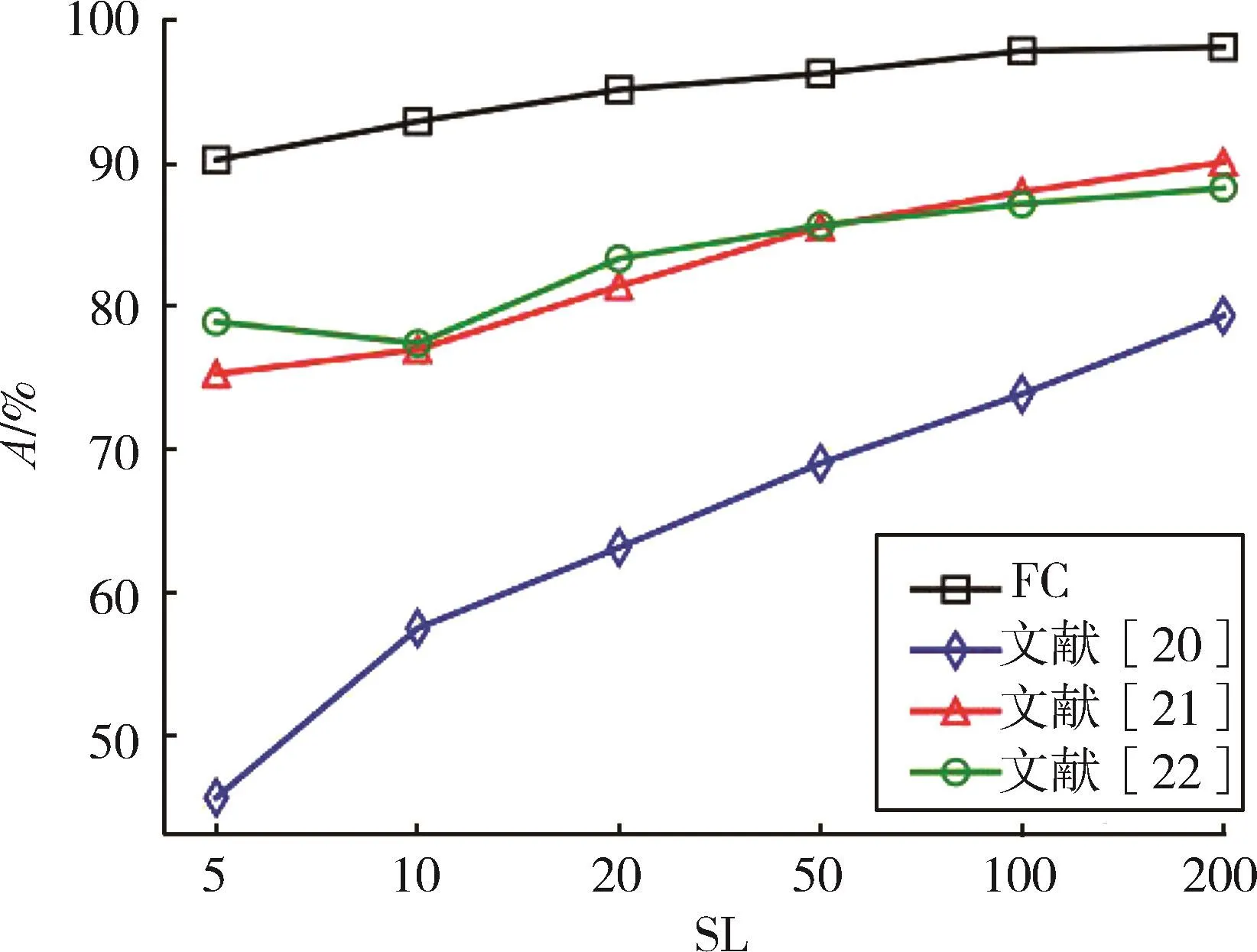
图5 ISCX不同SL各方法的A对比
3.4 HC与FC性能对比
为了验证HC方法的有效性,使用前5个数据包进行视频/非视频的二分类(BC-5),接着使用完整的10个数据包对流进行视频(VC-10)或非视频(NVC-10)分类。然后将两次分类的A相乘,即为整体的分类准确率。由于采用流式方法计算特征,并且BC、VC和NVC均使用相同的特征,所以HC只需要计算10个包的FEP即可。HC分类时间为BC加上VC或NVC分类时间。分别使用ND和ISCX进行实验,结果如表5和表6所示。
根据表5的结果,HC-10的A比 FC-10高约1.68个百分点,BC-5的A比FC-10高;同时VC-10和NVC-10的准确度都比较高;说明分类器在处理类别较少的分类任务时具有优势,而HC通过将视频分类任务和非视频分类任务进行分治处理利用了这种优势,从而提高了整体的准确度。在FEP上,HC-10比FC-10低约50%,原因是HC-10选择的特征数目比FC-10多。在CP上,HC-10也比FC-10低约50%,原因是HC需要进行两次流识别。虽然HC-10的TP下降,但它能够提升分类的准确性,而且能灵活配置于不同的应用场景。在MMU方面,HC-10比FC-10更省内存空间。可能的原因是随机森林在处理类别少的任务时,不需要分裂出太多的叶子数和节点数就可以完成分类任务,所以BC-5、VC-10和NVC-10的模型内存都比FC-10要少,导致HC-10总体内存占用要优于FC-10。
在表6中,HC的分类准确度比FC高1.7个百分点,但同样TP下降约50%,并且HC的MMU也低于FC。这说明HC方法在不同数据集上同样适用。

表5 ND SL=10的 HC 和 FC 的 A、FEP、CP、TP 和 MMU 比较(M1/M2)
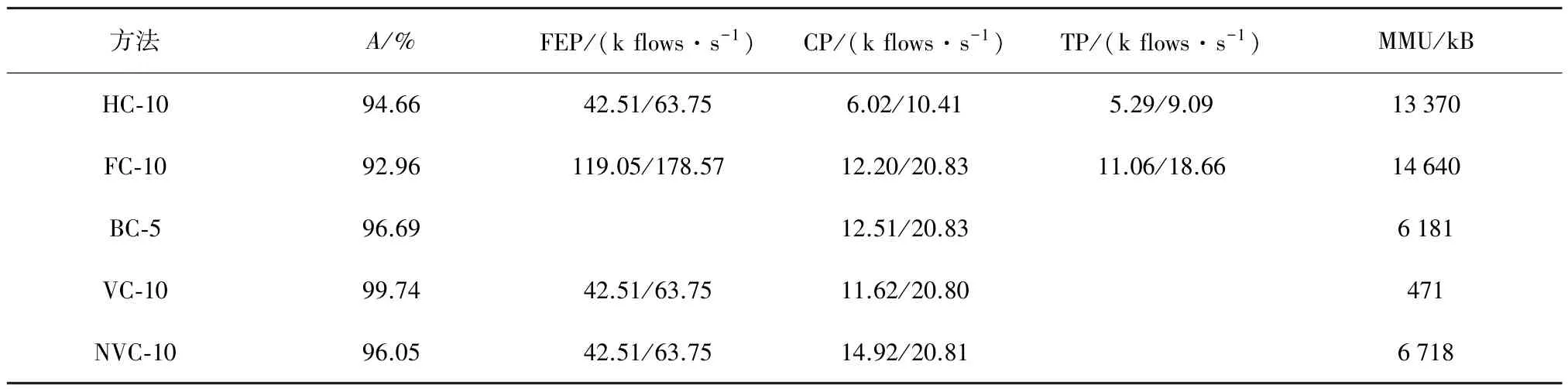
表6 ISCX SL=10的 HC和 FC 的 A、FEP、CP、TP和 MMU 比较(M1/M2)
3.5 内存消耗的讨论
在ND上选择SL=10的情况,设置MSL为1、10、30、50 和 100,对比不同方法的A、CP 和 MMU。实验结果如图6所示。
根据图6可以看出,随着MSL的增大,模型使用的内存减少,但A会下降。这是由于当MSL增大时,随机森林中树的深度也在变小,而随机森林模型的空间复杂度与树的深度有关[18]。本文方法所需内存空间在MSL为1和10时明显少于文献[20]和[22],与文献[21]相差不多;当 MSL 增大为 30、50和100时,4种方法占用的内存相差不大。
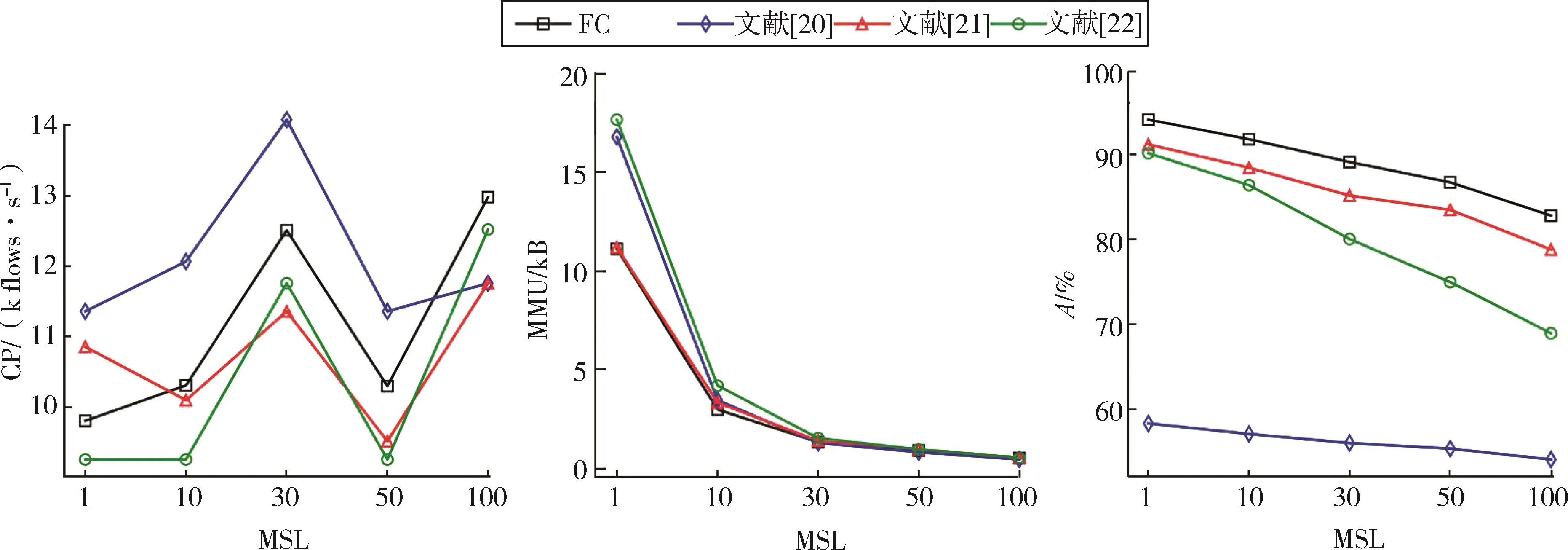
图6 ND SL=10不同MSL各方法的CP、MMU以及A对比(M1)
4 结束语
本文提出了两种对早期流分类较为有效的特征及一种层级分类方法。首先根据少量的数据包进行视频/非视频的二分类,再通过后续分类器进行更细粒度的分类,同时采用时间复杂度分析进行FS。在两个真实网络数据集上进行了方法验证。结果表明,在数据包个数为 5、10、20、50、100 和 200 情况下,分类准确率都大于90%。与文献方法相比,这两种特征不但在FE时间和分类准确性上都有优势,而且通过HC可以进一步提升分类的准确性。此外,还讨论了不同超参数下,模型的内存占用、分类时间和准确性的变化。实验结果表明,本文方法能够提升EC的准确性,降低FE时间,适用于实时网络流分类。
在后续的工作中,将探索通过数据清洗进一步提高分类准确性;同时考虑降低提取特征的维度,继续减少FE时间开销。
猜你喜欢
电子产品世界(2022年4期)2022-04-21
计算机与数字工程(2022年3期)2022-04-07
密码学报(2021年4期)2021-09-14
计算机系统应用(2021年2期)2021-02-23
成都信息工程大学学报(2021年6期)2021-02-12
民用飞机设计与研究(2020年4期)2021-01-21
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
电子技术与软件工程(2019年18期)2019-11-18
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
物联网技术(2018年8期)2018-12-06
