
数据挖掘技术应用下基于决策树模型的油水井生产异常状况管理
2022-09-23 09:25李婧璇
中国管理信息化 2022年14期
李婧璇
(中国石油大港油田信息中心,天津 300280)
0 引言
随着信息化的发展,石油勘探开发中逐渐大规模应用计算机网络、智能控制和数据挖掘等新兴技术来实现高效管理。然而,当前数字化系统存在信息共享性差、数据综合应用率低、报警准确率低等问题。对此,不少石油企业以数字油田为基础逐渐向智能油田建设方向发展。其智能决策控制中心通过分析大数据,实时进行资源合理调配、异常状况判断和生产风险预警,从而实现油田资产的智能化开发和管理。油水井生产异常状况诊断和管理系统是智能油田建设的一项具体应用,主要针对注采井组进行动态分析。注采井组是以注水井为中心,联系周围的油井和水井共同构成的油田开发基本单元。该系统可以实现井组实时诊断检测、提出相应管理措施、跟踪进度等功能。
数据挖掘指的是从已有数据库大体量、有损坏且具体含义模糊的实际数据中进行抽取、转换、分析以及模块化处理,发现其中具有潜在价值的可归纳信息的过程。数据挖掘过程中需要保证数据统计的有效性及准确性。决策树作为一种预测模型,代表的是对象属性与对象值之间的映射关系。决策树模型算法简单,仿真结果准确率高,易于理解和使用,常用于生产故障预测和目标追踪检测等。本研究以数据挖掘技术中的决策树模型来构建系统的核心诊断算法。基于井组生产中的实时数据,工作人员可以通过决策树模型对生产异常状况作出判断和管理,还可以对历史数据进行分析,设置保护设定值,对各类生产异常相关的指标进行预警监测。模型性能优异,分类精确度高,能够保障生产稳定安全,为油水井生产异常状况管理提供参考。
1 油水井生产异常状况诊断模型的构建
1.1 CART 决策树
油水井生产异常状况诊断模型属于分类模型,决策树算法挖掘出的分类规则准确性高且易于理解,算法运算速度快。因此,本文选择使用分类回归树(Classification and Regression Tree,CART)决策树对油水井生产数据进行分析,初步建立生产异常状况诊断模型。CART 决策树由根节点、中间节点和叶节点构成,通过计算基尼系数增益来确定分割点,采用二元分割法对数据进行分类,最终形成分类二叉树。相较于其他决策树,CART 决策树在分析大规模样本时不用进行大量的排序运算和对数运算,运算效率更高。
随机变量x 对应i 种状态下的概率为p,p,…,p,使用基尼指数(Gini index)来选择最佳的节点划分特征。基尼指数代表属性分类的不确定性,值越小,代表不确定性越低。两点分布的随机变量x 的基尼指数为:
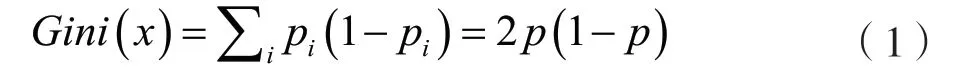
式(1)中,Gini 代表基尼指数,p代表样本属于i 类别的概率,1-p代表样本错误分类的概率。
对于训练数据集A,假设有j 个类别,而C代表第j 类样本的子集,|A|为A 的大小,|C|为C的大小,则集合A 的基尼指数为:

假设数据集A 被特征L 划分,若L 是离散型,则由L 的某个可能值l 将A 划分为A、A:

若L 为连续型,则可以得到Gini(A,L):
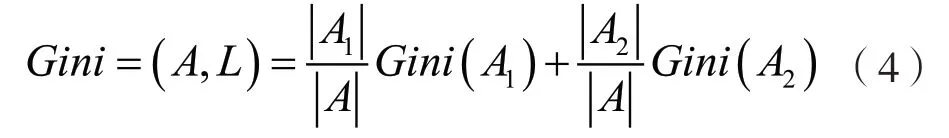
A、A表示数据集A 被特征属性L 的最佳分割点分割后的两部分,|A|、|A|分别表示A、A中样本的个数。Gini(A,L)取值越大,样本数据集被标签划分的不确定性就越高,因此,对于CART 决策树,可以选择Gini(A,L)的最小值作为最佳分割点。
1.2 基于提升方法优化的CART 决策树
本文引入提升算法提升决策树分类精度,在初步构建完成CART 决策树后改变样本权重,构建新的训练集得到一系列弱分类二叉树{T,T,T,…,T},将其进行加性组合,最终得到一个更加稳定高效的强分类二叉树F。
第n 个弱分类器的误差率E为:

式(5)中,W表示第n 个弱分类器、第m 个样本的权重;T(m)表示数据集A 的第m 个样本经弱分类器T分类后得到的值;y表示样本真实值;I 为指示函数,取值为0 或1;N 为样本集A 的样本个数。当预测值T(m)=真实值y时为0,当预测值T(m)≠真实值y时为1。
分类器加性组合系数α为:

权重W为:

规范因子Z为:
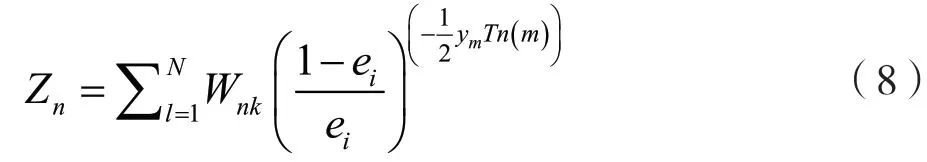
最终的强分类器函数表达式为:

F对数据集的误分类次数达到最低值时,新的弱分类器即停止构建。
1.3 原始数据来源及预处理
本文所使用的原始数据来源于某油田注采井组施工现场各底层传感器采集的生产动态资料,具体包括产能资料、压力资料、水淹状况资料、原油和水的物性资料以及井下作业资料等。
将原始数据按照生产时间保存日志文件,通过编程进行解析。对解析后得到的数据中重复、缺失和有明显错误的数据分别采取合并、临近数值补全和直接舍弃的措施进行初步处理。从不同时间段随机抽取2020—2021 年生产正常时的数据4 500 组,等概率抽取2020—2021 年生产异常时的数据3 500 组共同组成数据集A。将数据集中的正常数据和异常数据进行随机混合,将其中的5 000 组数据作为训练集,剩下的3 000 组数据作为测试集。利用CART 决策树模型对训练集进行训练。
2 模型实验结果
油水井生产异常状况可以细化为决策树深度为9的二叉树,且在输入因素中,电网波动、电潜泵控制柜故障、地层压力、含水变化、原油相对密度黏度和施工单位规模这6 个因素集中在决策树中的前3 层,表明这些因素对油水井生产影响较大。为了进一步清晰地展示油水井生产异常状况的具体分类预测情况,本文根据决策树细化了生产异常因素分类规则及其样本分布,部分样本数量较多的分类情况如表1 所示。
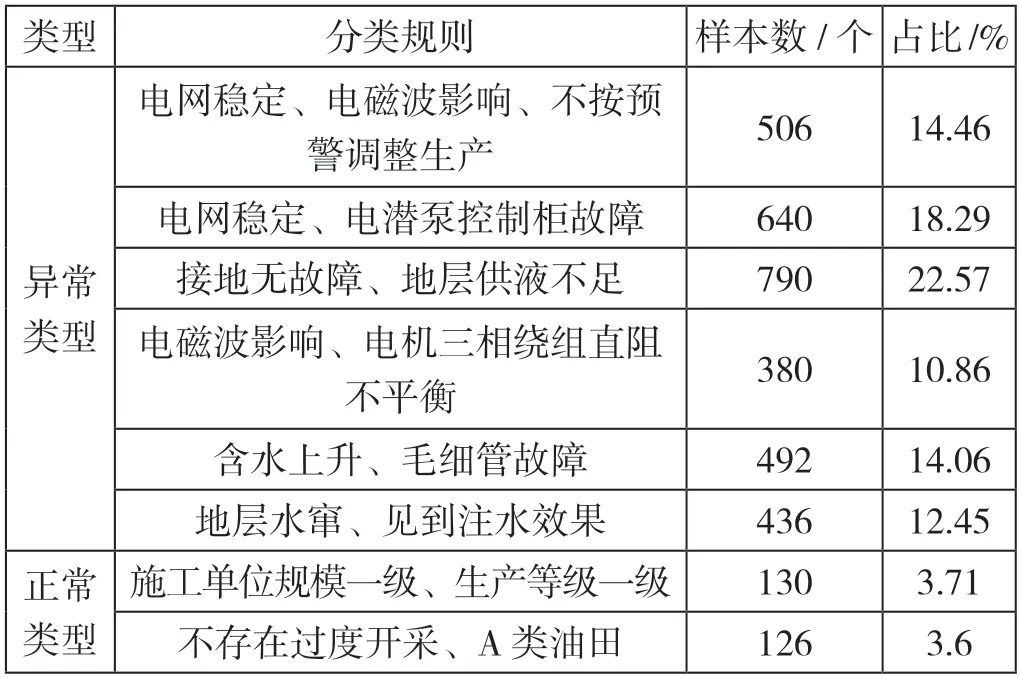
表1 部分油水井生产异常状况的分类规则及样本分布情况
学习率是机器学习中重要的超参数,合适的学习率能够使模型在一定时间内收敛到局部最小值,达到最优性能。根据实验结果,本文绘制了强分类器分类精确度与学习率关系曲线以及受试者工作特征曲线(Receiver Operating Characteristic Curve,ROC 曲线),具体如图1 所示。

图1 强分类器ROC 曲线及精确度与学习率关系曲线
理论上,学习率的取值也会影响强分类器分类精度,但在实际测试中,学习率变化对分类精度的影响较小。图1 中可以看出在学习率为[0,0.1]时,分类器处于欠拟合状态;学习率大于0.1 后,分类精度逐渐增高后降低;当学习率取0.8 时精度最大,为87%,此时ROC 曲线如图1 所示。ROC 曲线中越靠近图1 左上角,模型预测结果越准确,曲线下面积(Area Under Curve,AUC)约为0.90,表明该模型性能优异。
3 结语
对油水井生产异常状况进行诊断和管理能够有效稳定原油产量,保障生产工人的生命财产安全。模型仿真形成的决策树可以对生产异常状况输入因素进行分类,直观显示出影响油水井生产的不同因素及其比重。模型学习率变化对分类精度的影响较小,ROC 曲线下面积基本大于0.90,表明模型性能优异,可为油水井生产异常状况管理提供参考。但是,模型仅对生产异常状况进行了初步分类,对于油水井生产异常情况的管理依然需要人工操作,还需针对异常管理进行智能化改进。
猜你喜欢
今日农业(2021年7期)2021-11-27
小学生学习指导(低年级)(2020年3期)2020-06-02
成都信息工程大学学报(2019年3期)2019-09-25
华人时刊(2018年17期)2018-12-07
电子制作(2018年16期)2018-09-26
电子测试(2018年1期)2018-04-18
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
作文周刊·小学一年级版(2016年1期)2016-08-12
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
