
基于注意力机制和有效分解卷积的实时分割算法
2022-09-25 08:42唐伟伟熊俊臣
计算机应用 2022年9期
文 凯,唐伟伟*,熊俊臣
(1.重庆邮电大学通信与信息工程学院,重庆 400065;2.重庆邮电大学通信新技术应用研究中心,重庆 400065)
0 引言
语义分割作为计算机视觉重要任务之一,目标是为图像中每个像素分配一个唯一的类标签,可视为像素级的分类任务,与图像分类和目标检测任务不同,语义分割融合了两者的特点,兼有识别和定位的功能,最终输出具有语义标注的预测图像。深度学习之前,大多采用传统的分割算法,如基于阈值的分割、基于边缘的分割和基于区域的分割等,这些算法不仅费时费力,而且分割性能不佳。随着深度学习在计算机视觉领域的应用,基于深度学习的语义分割算法在性能上已有很大突破,现阶段分割算法层出不穷,大部分高精度算法模型基于全卷积网络(Fully Convolutional Network,FCN)[1],但都专注于提高准确度,如用于图像分割的深度卷积编解码架构SegNet(deep convolutional encoder-decoder architecture for image Segmentation)[2]、金字塔场景解析网络(Pyramid Scene Parsing Network,PSPNet)[3]和用于高分辨率图像分割的多路径精细网络(multi-path Refinement Networks for high-resolution semantic segmentation,RefineNet)[4]等。高精度算法模型普遍参数量巨大、计算复杂、内存占用非常高,无法满足实际需求。近年来,语义分割广泛应用于无人驾驶、医疗影像和视觉增强等实际领域,而真实场景要求具有较低的计算成本和内存占用,这对分割算法的实时性和准确性提出了新的挑战,如何在快速识别和定位图像中目标事物的同时保持较高的准确度成为解决该问题的关键。当前实时语义分割算法不是牺牲精度换取较高推理速度,就是在提高精度的同时增大计算成本和内存占用,进而降低了推理速度,无法兼顾两者。
为解决上述问题,本文基于轻量级非对称残差卷积构建了一种单路径浅层算法——基于注意力机制和有效分解卷积的实时分割算法(Real-time semantic segmentation Network based on Attention mechanism and Effective Factorized convolution,AEFNet),通过减少下采样次数和空洞卷积分别用于提取细节信息和增大算法感受野,从而增强算法捕捉上下文信息的能力,并结合全局上下文注意力模块补充编码过程中折损的细节信息,另外,利用轻量级残差模块减少计算成本,提高实时性,进而提高整个算法分割性能。本文主要工作有以下几点:
1)基于分解卷积构建轻量化分解卷积模块(Factorized Convolution Module,FCM),能有效捕捉多尺度特征信息和更好保存空间细节信息,进一步减少算法参数和降低内存占用同时保证分割精度。
2)提出了全局上下文注意力模块(Global Context Attention Module,GCAM),充分提取全局信息和细化每个阶段特征,进一步补充上下文信息,并能有效增强算法模型的学习能力。
3)构建了一种新型的浅层实时分割算法,整合了轻量级残差模块和全局上下文注意力模块,提高了分割性能。
1 相关工作
1.1 实时语义分割
现阶段实时分割算法主要通过裁剪或限定图像大小降低计算复杂度或通过分解卷积提高实时性,但裁剪可能会带来细节信息的丢失,因此目前更多使用分解卷积建立轻量级算法模型;另外空洞卷积和注意力机制对精准识别和定位图像中的目标也非常重要。当前实时分割算法提出了多种解决方案用于实时语义分割的深度神经网络架构(deep neural network architecture for real-time semantic segmentation,ENet)[5]中,通过裁剪算法模型通道数减少了大量的运算和降低了内存占用。用于图像分割的轻量级卷积网络(novel Lightweight ConvNet for semantic Segmentation,LiteSeg)[6]中,使用深度空洞空间金字塔池化模块(Dense Atrous Spatial Pyramid Pooling,DASPP)对分割性能有一定的提升。深度非对称瓶颈网络(Depth-wise Asymmetric Bottleneck Network,DABNet)[7]中,通过堆叠深度非对称模块(Depth-wise Asymmetric Bottleneck,DAB)构建浅层网路,进一步提升分割性能。增强非对称卷积网络(Enhanced Asymmetric Convolution Network,EACNet)[8]中运用一种双路径浅层算法模型,分别提取细节信息和上下文信息,并阶段性融合,有效地提高了分割精度和推理速度。
1.2 分解卷积
分解卷积的出现很大程度上为解决实时性提供了范式,如用于移动视觉应用的高效神经网络(Efficient convolutional neural Networks for Mobile vision applications,MobileNets)[9]中的深度可分离卷积和高效残差分解卷积网络(Efficient Residual Factorized ConvNet,ERFNet)[10]中的一维非瓶颈结构(Non-bottleneck-1D),都能有效减少大量的计算和降低内存占用的同时保持较高的精度,为建立轻量级算法模型提供了思路。而在实现轻量化模型的同时会损失空间细节信息,因此如何构建有效的分割模块对提高分割性能有着重要的作用。

1.3 感受野
感受野对提高分割性能的重要性已在大量文献中得以证明,增大感受野通常有使用大的卷积核、池化操作和空洞卷积等操作。大卷积核加重了算法的计算负担,不利于实时性;池化操作使得图像尺寸不断缩小而造成空间细节信息丢失;而空洞卷积可在不增加卷积核参数前提下同时增大感受野,有利于提取图像的空间细节信息。目前大多算法采用空洞卷积,如深度卷积网络(Deep Convolutional network,Deeplab)[11]提出的空洞空间金字塔池化(Atrous Spatial Pyramid Pooling,ASPP)模块和高效空间金字塔网络(Efficient Spatial Pyramid Network,ESPNet)[12]中引入的高效空间金字塔(Efficient Spatial Pyramid,ESP)模块,都能有效捕捉多尺度感受野,增强算法的表达能力。本文与上述算法不同,采用堆叠方式逐步增大感受野且利于提取细节信息。
1.4 注意力机制
注意力机制更关注一些关键的特征,并通过权重标识,使得算法能够学习图片中重要的特征。双路径分割网络(Bilateral Segmentation Network,BiSeNet)[13]中提出了注意力细化模块(Attention Refinement Module,ARM)细化每个阶段的特征,能够容易地整合全局上下文信息;双重注意力网络(Dual Attention Network for scene segmentation,DANet)[14]中,提出通过整合局部信息和全局信息来捕捉上下文信息,再由注意力机制获得特征表达;Hu 等[15]在快速注意力分割网络(real-time semantic segmentation Network with Fast Attention,FANet)中引入了快速注意力机制,实现了在精度和推理速度上的双赢;RGB-D 室内语义分割的三流自注意力网络(Three-stream Self-attention Network for RGB-D indoor semantic segmentation,TSNet)[16]引入自注意力机制,并通过交叉模式蒸馏流细化深度流和RGB 流的中间特征图,进而提高分割性能;来自廉价操作的多功能网络(More features from cheap operations network,GhostNet)[17]提出轻量级Ghost模块,在小特征图基础上使用更为廉价的卷积操作,生成一系列特征图,进一步减少计算量。与以上算法不同,本文引入注意力机制旨在解决编码过程中上下文信息不足的问题,提高模型的泛化能力。
2 模型设计
2.1 分解卷积模块
由上文所述可知,本文认为一些算法模块设计不利于提取空间细节信息,如ESPNet[12]的ESP 模块,模块内使用多个空洞卷积会造成一些细节信息丢失,同时加重计算负担,因此本文结合深度可分离卷积和非对称残差卷积进行模块设计。深度可分离卷积包括深度卷积和逐点卷积两个过程,其中深度卷积可在每个通道独立地进行卷积运算;而逐点卷积则是利用1×1 卷积进行特征加权,生成新的特征图。
近年来为了建立轻量级模型,涌现出非瓶颈结构(Nonbottleneck)(如图1(a))、瓶颈结构(bottleneck)(如图1(b))和一维非瓶颈结构(Non-bottleneck-1D)(如图1(c))等轻量级残差结构。非瓶颈结构随着算法模型的加深,由于固定的核尺寸导致没有足够的感受野,因此性能会随之下降;瓶颈结构随着卷积层数的增多,还会出现退化问题;一维非瓶颈结构不仅能加快训练速度,并能有效解决在大而密集的特征层的分割问题,保持算法的学习能力和较高的精度。基于以上研究,本文构建分解卷积模块(FCM)特征提取单元,其利用原始的一维非瓶颈结构将3×1 和1×3 卷积分别修改为深度可分离卷积和带孔深度可分离卷积,并引入残差连接增强算法学习能力和使用PRelu 激活函数和批归一化操作增加算法的非线性表达能力,如图1(d)所示,图中,“DConv”为深度可分离卷积,“DDConv”为带孔深度可分离卷积,r为空洞率,“SUM”为元素加法操作。
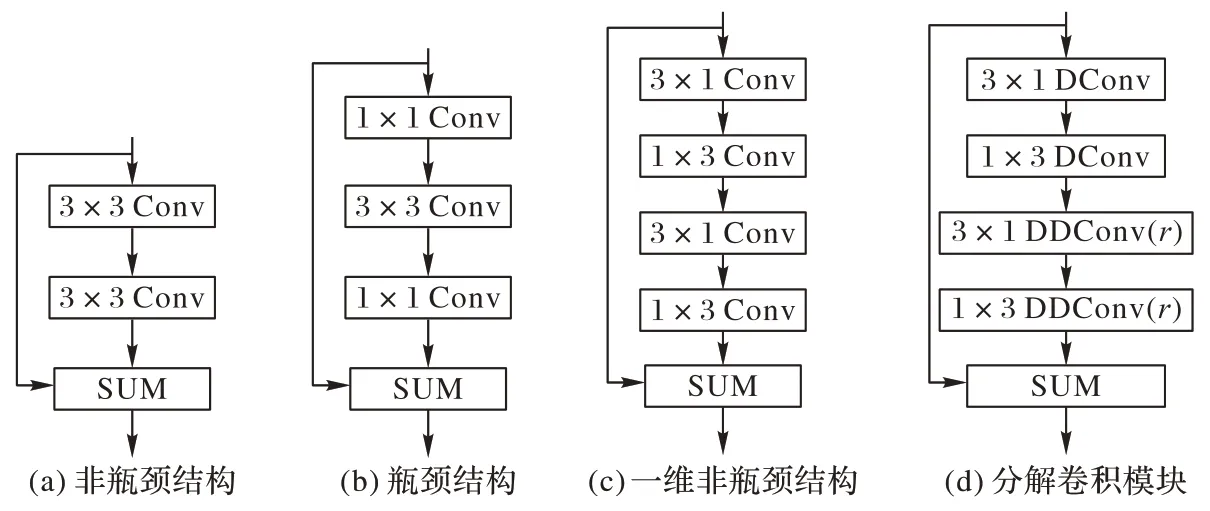
图1 轻量级残差模块Fig.1 Lightweight residual module
由1.2 节可知,在一维非瓶颈结构中,Dk×Dk被分解为Dk× 1 和1 ×Dk,其深度可分离卷积的计算量为2×(M×其与正常卷积之比就为2×,由此可见深度可分离卷积和一维非瓶颈结构的结合可进一步减少计算量。修改后的模块通过大空洞率以提取具有复杂的全局特征,而小空洞率更能关注简单的局部特征,相较于固定大小卷积核,分解卷积模块(FCM)更能有效提取上下文信息和细节信息,不仅弥补了固定大小感受野的缺陷而且不会出现退化问题;另外与一维非瓶颈结构比较,FCM 参数量更少,且特征提取能力更强,更能体现实时性,在加快算法训练的同时提高了模块的兼容性。
2.2 全局上下文注意力模块
本文认为造成浅层算法模型分割性能不佳的一部分原因是卷积过程中上下文信息的不足,忽略了类别之间的边缘特征。注意力细化模块(ARM)如图2(a)所示,对输入依次进行平均池化、逐点卷积、批归一化和sigmoid 映射处理后得到全局特征权重值,再与输入特征相乘最终获得加权后的特征,该过程充分考虑全局特征和细节特征,在计算量少的情况下获得与深层卷积过程对应的上下文信息,极大地提高了模型的分割能力。因此基于注意力细化模块,本文提出全局上下文注意力模块(Global Context Attention Module,GCAM),如图2(b)所示,更进一步对每个阶段特征细化,弥补编码过程中欠缺的上下文信息,进而提高算法的分割性能,并能有效克服背景信息的干扰。该模块以初始化特征块作为输入,由注意力细化模块分别对平均池化和最大池化后的特征进行通道加权,重新调整特征权重,得到与其大小对应的权重图,再由元素加法操作进行特征融合,以极少的计算量便可获得更加丰富的全局上下文信息,最后利用3×3 卷积进一步增强特征的表达能力。由于浅层的特点导致算法缺乏足够的上下文信息,虽然ARM 能够细化特征,但终究难以解决该问题,添加池化操作后的模块更有利于增强全局特征提取,由ARM 细化输出并融合特征,加强了信息间的交流,并与编码各阶段融合指导特征分类预测,最终提高分割性能。
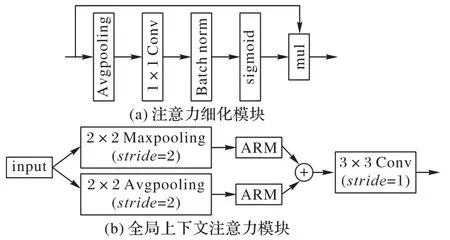
图2 注意力细化模块和全局上下文注意力模块Fig.2 Attention refinement module and global context attention module
2.3 整体算法模型
为提高推理速度的同时保证精度,本文构建一个新型的轻量级实时分割算法——基于注意力机制和有效分解卷积的实时分割算法(Real-time semantic segmentation algorithm based on Attention mechanism and Effective Factorized convolution,AEFNet)。算法框架如图3 所示。
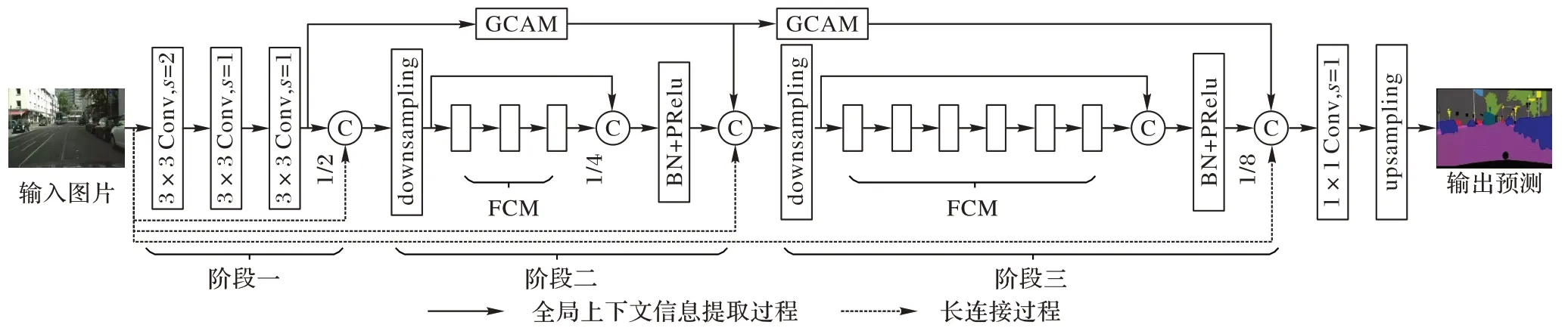
图3 AEFNet框架Fig.3 Framework of AEFNet
现阶段一些算法通过连续下采样操作和堆叠大量卷积层(100 层以上)构建深层卷积网络模型,以获得足够丰富的语义信息和足够大的感受野;然而网络层数越深,下采样次数越多,空间细节信息丢失越严重,不利于恢复图像。本文采用3 次下采样得到1/8 分辨率的特征图,通过构建有效模块,发挥其在少量卷积层上的强大特征提取能力,建立与深层卷积算法同样有着丰富的语义信息和大感受野的浅层算法模型。在第一阶段,首先输入图像执行3 个连续的3×3 卷积得到初始化特征块,使用较少的参数训练获得与7×7 卷积同等大小的感受野,使算法具有更好的学习能力。
由步长为2 的3×3 卷积和2×2 最大池化组成的下采样器(如图4 所示)下采样得到1/4 和1/8 图像分辨率后,为充分获取局部特征信息和全局特征信息,进一步增大感受野,建立深度卷积模型,阶段二堆叠3 个空洞率为2 的FCM,阶段三堆叠6 个空洞率分别为4、4、8、8、16、16 的FCM,不同空洞率的有效性将在实验部分进行验证分析。为充分提取空间细节信息,本文在整个堆叠模块引入残差连接,再由批归一化和PRelu 激活函数处理后作为整体输出。为进一步细化特征,本文采用GCAM(如图3 中上方实线所示)和长连接(如图3中下方虚线所示)捕捉全局特征信息,并与相应阶段输出进行连接。最后分类器对阶段三的输出进行预测,由双线性插值恢复图像分辨率。由于非线性层在bottleneck 中使用会对算法性能造成一定影响,因此本文在最后1×1 卷积不再使用激活函数。
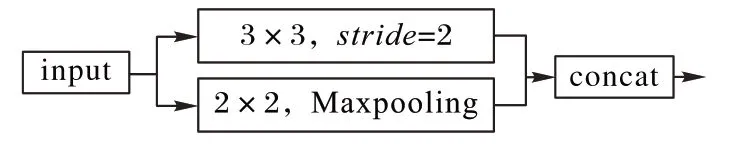
图4 下采样器Fig.4 Downsampler
3 实验结果与分析
3.1 数据集
本文采用cityscapes 和camvid 两种自动驾驶常用数据集对模型进行验证。cityscapes 是城市街景数据集,该数据集含19 个类别,包括5 000 张精细标注图片,其中训练集为2 975 张图片,验证集为500 张图片,测试集为1 525 张图片,每张图片分辨率为1 024×2 048,另外还有20 000 张粗标注的图片,在本实验中仅使用精细标注图片。camvid 为另一个用于自动驾驶的图片数据集,该数据集包含11 个类别,共有701 张图片,其中训练集为367 张图片,验证集为101 张图片,测试集为233 张图片,每张图片分辨率为720×960。
3.2 实验设置
本实验在pytorch 平台使用单个GTX 2080Ti GPU 进行实验。AEFNet 训练时采用批次为8,动量为0.9,权重为0.000 1 的小批次随机梯度下降法对模型进行优化,训练期间使用“ploy”学习策略(如式(1))动态调整学习率,初始学习率为0.045,最大epoch 为1 000。数据预处理过程中使用了数据增强策略,如:随机水平翻转、随机裁剪和均值衰减,随机裁剪值为{0.75,1.0,1.25,1.5,1.75,2.0}。本实验将cityscapes 数据集经随机裁剪后分辨率为512×1 024 作为算法的输入。另外,本文没有采用任何形式的预训练策略,算法模型从头开始训练。
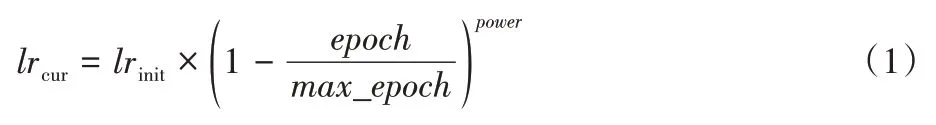
其中:lrcur为当前学习率,lrinit为初始学习率,epoch为迭代次数,max_epoch为最大迭代次数,power控制曲线形状,通常设置为0.9。
3.3 评价指标
本实验中所有的精度结果均采用平均交并比(mean Intersection Over Union,mIOU)进行评价,推理速度采用帧速率(Frames Per Second,FPS)进行评价。
平均交并比(mIOU)计算真实值和预测值两个集合的交集和并集之比,是分割任务中评价精度的常用指标,其计算公式如式(2):
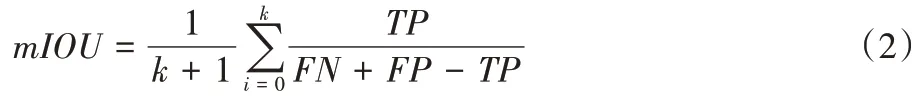
其中:k为类别数量,TP(True Positive)表示预测为真正数量,FN(False Negative)表示预测为假负数量,FP(False Positive)表示预测为假正数量。
帧速率(FPS)指图形处理器每秒钟能够刷新几次,FPS 越高,则动作显示越流畅,实时性相对就越高。因此,实时分割任务常用FPS 评价算法推理速度,其计算公式如式(3):

其中:N为图片数量,Tj为算法处理第j张图片时所需要的时间。
3.4 消融实验
为探索多尺度感受野对算法分割性能的影响,本文针对阶段三设置3 组不同空洞率的对比实验,空洞率分别为3、3、7、7、13、13,4、4、4、4、4、4 和4、4、8、8、16、16,实验结果如表1 所示,由于固定空洞率大小限制了感受野大小,导致大尺度特征的信息提取不完整,而空洞率为3、3、7、7、13、13时,对“大而密”的特征图的信息提取依然缺乏足够的感受野。本文采用空洞率为4、4、8、8、16、16 的FCM 能获取更多丰富的细节信息和更大的感受野,其分割精度高于其余两组约1 个百分点,推理速度基本持平,具有更强的泛化能力。
另一方面,为探究解码器结构对算法模型的影响,本文采用了ERFNet[10]的解码器结构进行实验。实验结果如表1所示,解码器结构在AEFNet 基础上精度提高了0.3 个百分点,在性能上的提升并没有明显的作用,反而由于解码器结构带来的额外计算成本,大大限制算法的推理速度,因此解码器结构在本文模型中不必要。
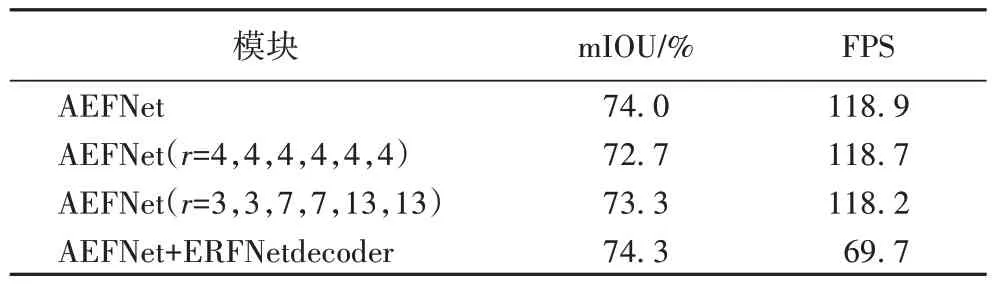
表1 空洞率和解码器对算法性能的影响Tab.1 Influence of dilated rate and decoder on algorithm performance
结合多尺度语义信息在一定程度上提高了分割性能,但一些边缘特征分割模糊,引入注意力模块可细化每个编码阶段。为探索GCAM 对算法性能的影响,本文设计了4 组对比实验。实验结果如表2 所示,当使用最大池化代替平均池化时,精度提高了0.4 个百分点;当全部使用池化操作时,比全部不使用时精度提高了1.4 个百分点,且比单个使用的精度都要高,但推理速度少于不使用池化操作时约7 FPS,但这不影响算法的实时性,其他组别的推理速度与本文所提算法基本一致,而本文更注重算法分割精度,由此看来使用两种池化更有利于性能的提升。部分实验结果如图5 所示。
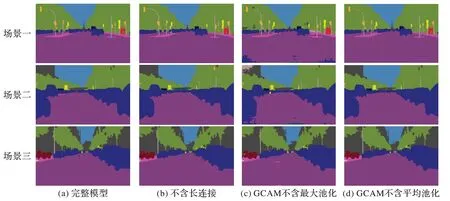
图5 部分实验结果Fig.5 Part experimental results

表2 GCAM对算法性能的影响Tab.2 Influence of GCAM on algorithm performance
在GCAM 的基础上,本实验采用长连接进一步特征细化并弥补下采样丢失的细节信息。为探索长连接对算法性能的影响,本实验采用控制变量法逐步实验。实验结果如表3所示,精度与AEFNet 相比,长连接缺失会导致算法分割精度略有下降,但都在1 个百分点以内,虽然在推理速度上也有所影响,但与AEFNet 基本保持不变,因此在保证实时性的前提下,本文算法有着较好的性能。部分实验结果如图5所示。
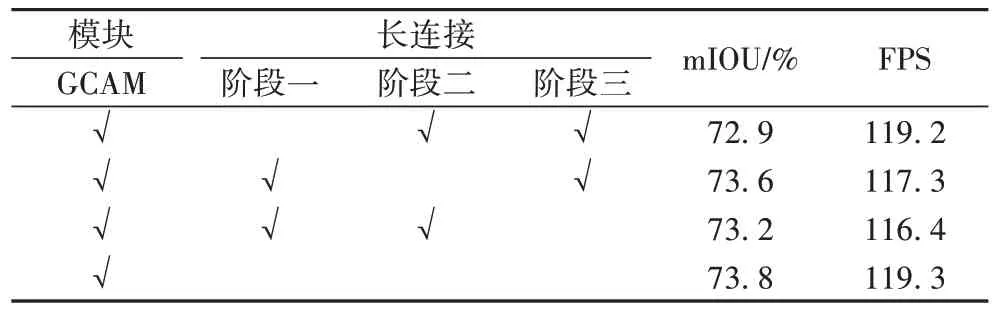
表3 长连接对算法性能的影响Tab.3 Influence of long connection on algorithm performance
从图5 可以看出:本文以图5(a)为基准进行对比,研究算法在不同情况下的实际效果;图5(b)由于拥有GCAM,算法对全局信息提取较为准确,并接近于完整模型,对道路、车和建筑物等分割准确,但对远处目标和一些混合性的物体出现分割错误,如路旁的自行车有分类错误和远处的教堂分割不全,这可能是由于没有足够的信息,没能及时补充相应的细节;图5(c)中相较于完整模型缺少最大池化,从效果图可以看出对性能影响较大,对道路、树木等相对较大目标分割存在瑕疵,效果图中出现斑点,但图中物体间界限分明,边缘特征清晰可见,表明虽然缺少最大池化,但GCAM 依然能够有效捕捉全局上下文信息,指导正确的预测分类;而在图5(d)中,由于最大池化的作用,使得算法对目标更加关注,边缘特征更加明显,较完整模型来讲,两者分割最为接近,行人、汽车和树木等都能准确地识别,但对于小目标依然存在分类错误和丢失的情况,特别是远处的细小目标,如远处的塔就分割不完整。总体上,细小目标和远处部分目标的分割不全或丢失的问题普遍存在,致使算法分割效果不佳,而金字塔特征提取算法能有效解决该问题。
3.5 在速度和精度上的比较
本文使用cityscapes 测试集对算法模型进行验证,并和目前优秀的算法模型进行对比分析,包括金字塔场景解析网络(PSPNet)[3]、用于图像分割的深度卷积编解码架构(SegNet)[2]、用于实时语义分割的深度神经网络架构(ENet)[5]、高效空间金字塔网络(ESPNet)[12]、高效残差分解卷积网络(ERFNet)[10]、图像级联网络(Image Cascade Network,ICNet)[18]、注意力引导的轻量级网络(Attention-Guided Lightweight Network,AGLNet)[19]、深度非对称瓶颈网络(DABNet)[7]、高效对称网络(Efficient Symmetric Network,ESNet)[20]、深度特征聚合网络(Deep Feature Aggregation Network,DFANet)[21]、非局部高效实时算法(Light-weighted Network with efficient Reduced non-local operation,LRNNet)[22]、增强非对称卷积网络(EACNet)[8]。实验结果如表4 所示,本文提出的AEFNet拥有1.59MB的参数,相较于ENet[5]和ESPNet[12]的参数量0.36MB,这两种算法参数占有明显优势,但从精度和推理速度上看,ENet 和ESPNet 在精度上与AEFNet 相差约14 个百分点,而在推理速度上ESPNet 低于AEFNet 约7 FPS,由此看来,AEFNet 性能表现较好。相较于EACNet,本文提出AEFNet 精度比其略低0.2 个百分点,但在推理速度上,AEFNet 则表现较为出色,达到了118.9 FPS,高于上述所有算法。由此可见,本文提出的AEFNet 在精度和推理速度上取得较好的平衡,能够在保证精度较高的同时提高推理速度。
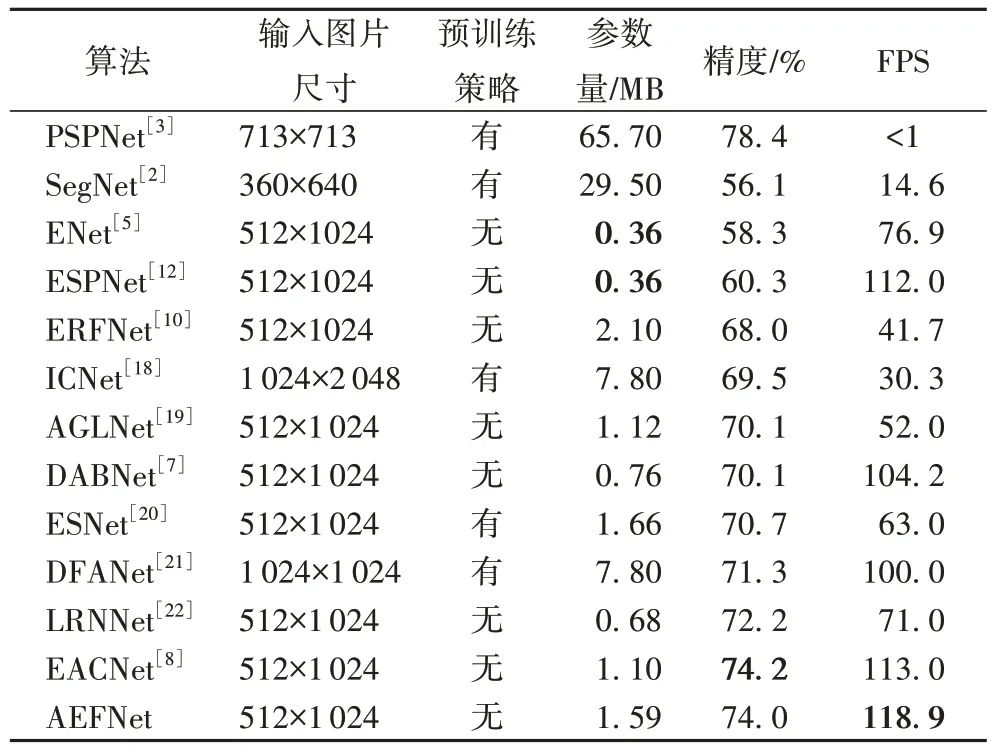
表4 不同算法在cityscapes测试集上精度与推理速度的对比Tab.4 Precision and interference speed comparation of different algorithms on cityscapes test set
相较于一些优秀的算法框架,本文构建的算法模型在具体类别上的精度也表现出优越性。如表5 展示了每类分割精度值,并且大多数类别分割精度都优于其他算法,特别在人行道、栅栏和交通标志等分割精度大幅度上升,表明本文提出的算法对类别的一些重要特征(如边缘特征等)的识别更加精细,而在植物、天空和大车等方面分割效果不佳,可能是多种细小目标与其混合所致,但总体性能本文模型更优,表中:类mIOU 表示表示19 个小类类精度的平均值,类别mIOU 表示7 个大类精度的平均值。
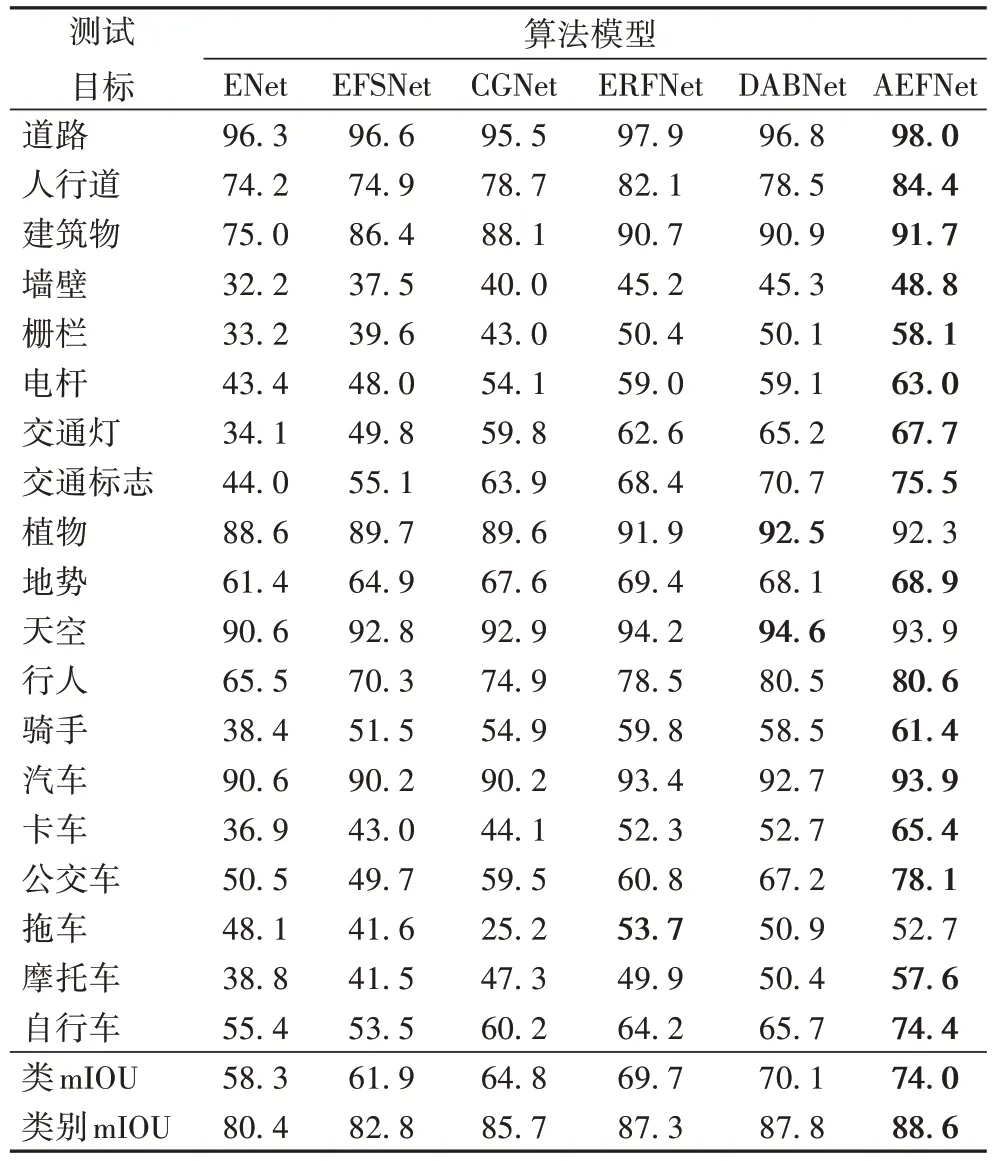
表5 AEFNet在cityscapes测试集上的每类IOU及与其他算法的比较 单位:%Tab.5 Each class IOU of AEFNet and other algorithms on cityscapes test set unit:%
为进一步分析,本文在cityscapes 验证集上的分割结果进行了分割可视化,并选取具有代表性的算法进行比较相比。实验结果如图6 所示,对于建筑、马路和汽车等简单场景的分割,AEFNet 更接近标签图,类别之间的界限分割效果比较明显,细化了边缘特征的分割,如图6 第一个场景中的建筑物分割较为准确。由于远处道路场景细节复杂,细小的目标和多种目标混合区域的分割出现分割不全的情况,如图6 最后一个场景中单车上的小孩出现错误分类,其原因可能是空洞卷积过程中造成的细节丢失或注意力模块对小目标关注度欠缺。
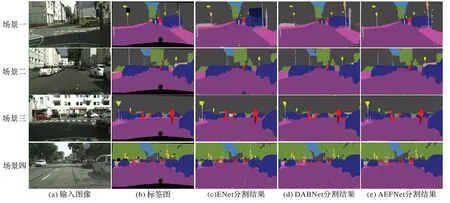
图6 不同算法在cityscapes验证集上的分割可视化结果Fig.6 Visualized segmentation results of different algorithms on cityscapes verification set
3.6 在camvid数据集上的验证
本文在另一个用于自动驾驶的数据集camvid 上进行实验,图片经随机裁剪后输入为360×480,训练参数设置与在cityscapes 数据集上基本保持一致,初始学习率重新设置为0.001,并新增了高效密集对称卷积网络(Efficient Dense modules of Asymmetric convolution Network,EDANet)[25]进行对比。实验结果如表6 所示,本文提出的AEFNet 在camvid测试集上能够达到67.6%的精度,推理速度为123.6 FPS。AEFNet 的精度低于DFANet 3.7 个百分点,但推理速度取得了较大的提升,提高23.6 FPS。推理速度上EDANet[25]高于AEFNet 约40 FPS,但精度略低于本文所提算法1.2 个百分点。由此可见,AEFNet 也能在camvid 数据集上获得良好的性能。

表6 不同算法在camvid测试集上的性能对比Tab.6 Performance comparation of different algorithms on camvid test set
4 结语
为满足实时性要求,本文运用了轻量级非对称残差模块和注意力机制构建了浅层算法,该算法为减少计算成本和内存占用,利用深度可分离卷积和非对称卷积构建轻量级的FCM,为获取全局重要信息,细化每个阶段,利用GCAM 用于提高算法分割性能。为验证算法模型的有效性,AEFNet 在cityscapes 和camvid 数据集上进行了实验。实验结果表明,该算法能够在精度和推理速度之间取得较好的平衡,相较于其他算法而言,本文所提出的算法表现出了良好的性能。
在可视化结果中,本文所提算法依然存在细小目标分割不完整或丢失、部分边缘特征界限略有不清晰的情况,针对以上问题,设计有效的金字塔特征提取算法和更为精细的注意力模块加深对小目标的提取和关注将是今后研究的重点。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
小雪花·成长指南(2022年1期)2022-04-09
上海师范大学学报·自然科学版(2019年5期)2019-12-13
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
中国新通信(2017年9期)2017-05-27
电子技术与软件工程(2016年24期)2017-02-23
第二课堂(课外活动版)(2016年2期)2016-10-21
职业·中旬(2009年12期)2009-06-01
