
非接触式三维重建技术综述
2022-09-30 04:24刘志海代振锐田绍鲁刘飞熠
科学技术与工程 2022年23期
刘志海 , 代振锐 , 田绍鲁 , 刘飞熠
(1.山东科技大学交通学院, 青岛 266590; 2.山东科技大学机械电子工程学院, 青岛 266590)
在计算机视觉和图像处理等技术的快速发展下,非接触式三维重建在三维重建领域成为重要研究内容。非接触式三维重建是指通过光、声和电磁学等信号源接触物体表面[1],并使用相应设备对目标物体进行图像采集,然后使用计算机对获取的二维图像信息进行分析处理,再通过三维重建的相关理论知识获得物体的三维信息。与利用测量工具和目标物体表面接触进而完成三维重建的接触式三维重建技术相比,非接触式三维重建具有重建速度快、效率高等优点,且不易受物体的几何形状影响。广泛应用于人工智能、自动驾驶、机器人视觉、医学、虚拟和增强现实等领域[2-6]。
根据发射信号源所使用的传感器是否主动向物体照射光源分为主动式、被动式[7-8]两种方法。主动式三维重建通过向目标物体发射信号并分析返回的信号,计算信号源与目标物体表面的相对位置进而完成目标物体表面的三维重建。被动式三维重建通过单个或多个相机采集目标物体的图像,利用图像分析获得目标物体表面的三维数据,进而完成物体的三维重建。
现主要对主动式三维重建的飞行时间法、基于三角测距的结构光重建、光栅重建和被动式三维重建的单目视觉、双目视觉、多目视觉重建和基于深度学习的三维重建进行分析总结。
1 主动式三维重建
主动式三维重建是一种主动测量环境深度从而重建出物体三维模型的技术。该技术使用传感器主动地向物体表面发射信号源,然后依靠解析返回的信号,计算信号源与目标物体表面的相对位置获取物体的三维信息。根据方法原理,主动式三维重建主要分为基于激光测距和基于结构光重建。现主要分析基于激光测距的飞行时间法、基于相位差的光栅重建和基于三角测距原理的结构光三维重建[9-12]。
1.1 飞行时间法
飞行时间法(time of flight,TOF)通过向目标发送光脉冲信号,然后依据传感器接收到光脉冲信号反射后的时间差来计算与目标的距离,工作原理如图1所示。TOF根据测量传播时间方式的不同可以分为直接测量法和间接测量法[13],根据光源发射器调制光脉冲方法的不同可以分为脉冲调制法和连续波调制法[14]。TOF主要采用主动红外调制光源,可以在无光的环境中工作,不需要进行图像处理分析,速度较快,同时还具有稳定性高、集成度高等优点,但是容易受环境光的影响。
随着微电子、微光学和微技术的不断发展,20世纪90年代初,首次将基于TOF测量技术与特殊功能的传感器结合在一起,生成出了第一代TOF相机[15-16]。目前,生产TOF相机的厂商主要有Psychemedics(PMD)公司、MESA Imaging AG公司和微软公司等。TOF相机的误差会影响TOF三维重建的准确性,TOF相机的误差主要分为相机本身不可避免的系统误差和外界环境引起的非系统误差。
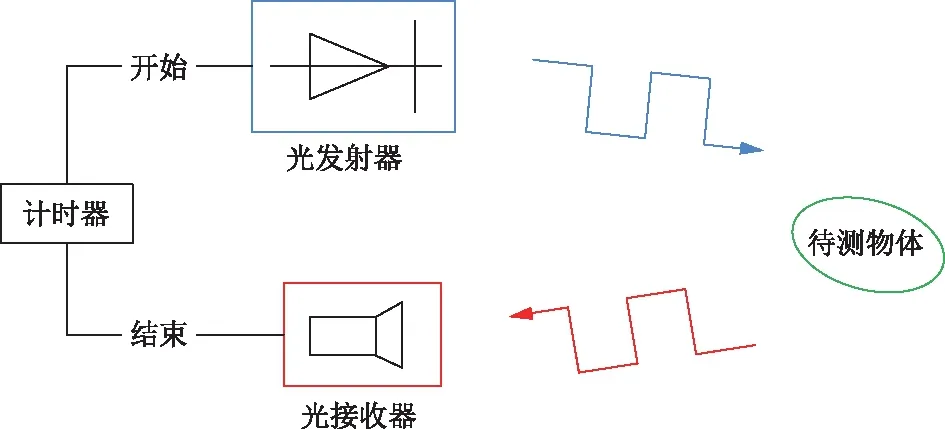
图1 飞行时间法原理图Fig.1 Schematic diagram of TOF method
1.2 结构光三维重建
结构光法三维重建示意图如图2所示,通过投影仪将特定的结构光图案投射到目标物体上,由相机拍摄目标物体的二维图像,再通过图像处理和视觉模型求出目标物体的三维信息[23]。其基本原理是三角测量原理,通过计算投影仪与相机之间的位置关系和畸变条纹来获取物体的三维信息。这种方法容易受光照影响,适合室内环境,而且随着检测距离的增加,重建精度也会变差。结构光常用的结构形式有单投影仪-单相机、单投影仪-双相机[24]、单投影仪-双相机、多投影仪-单相机[25]、多投影仪-单相机[26]等。根据技术原理可以分为三角测距的结构光重建和基于相位的光栅重建。
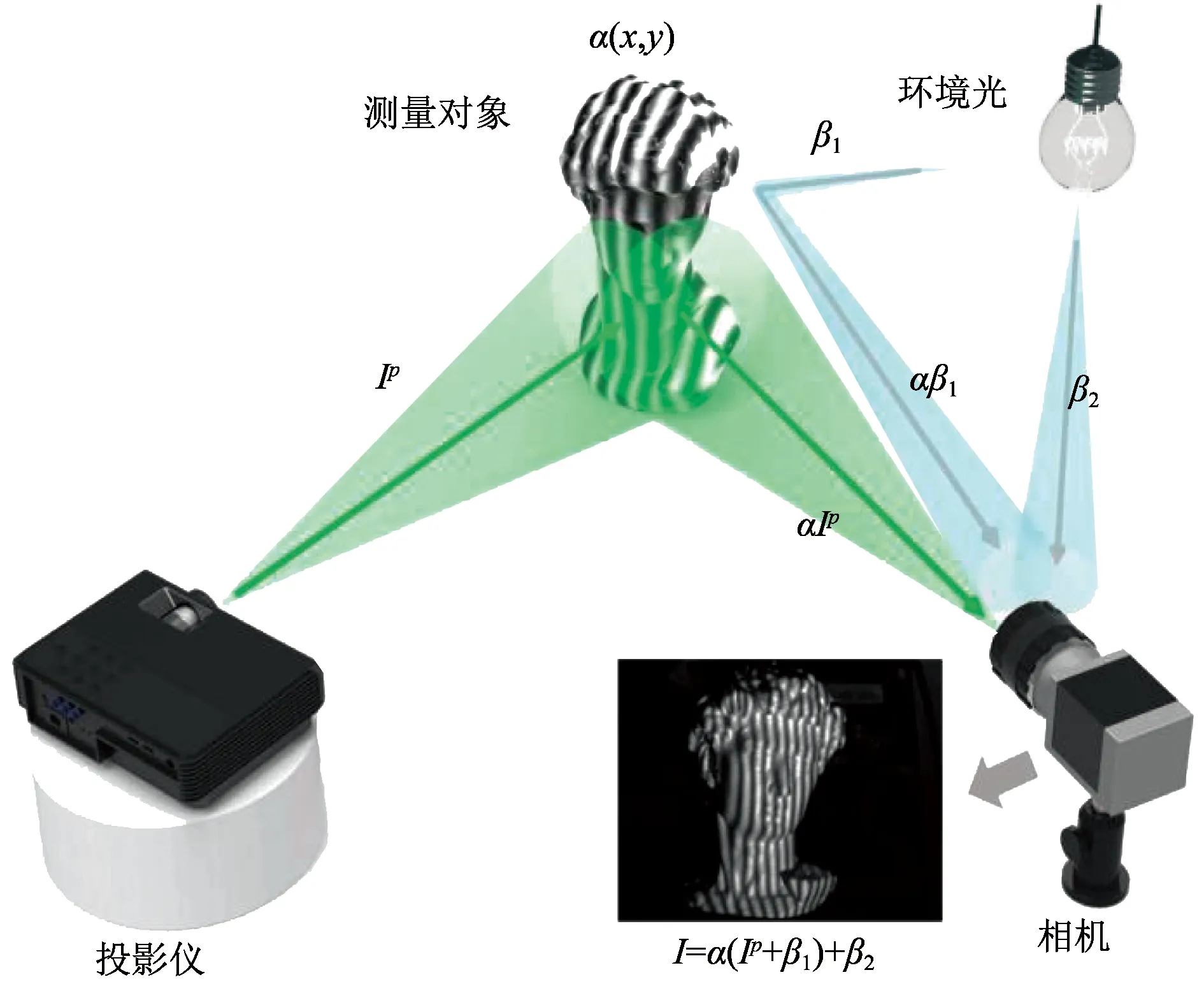
I表示条纹图像;Ip表示p点的条纹图像;α表示被测物体的反射率; α(x, y)表示被测物体(x, y)点的反射率;β表示环境光 图2 结构光示意图[27]Fig.2 Schematic diagram of structured light[27]
1.2.1 基于三角测距的结构光重建
基于三角测距的结构光重建通过计算投影仪发射的光源、相机和光源在目标物体上的投影点构成的三角关系来获得目标物体的三维信息。该方法重建结果比较稳定可靠,但是重建范围较小。根据光信号发射器的投影模式不同,结构光法可以分为点式结构光、线式结构光、面式结构光。
点式结构光使用光信号发射器发射一束光线投射到目标物体上,在目标物体上形成一个光点,然后相机拍摄目标物体得到二维图像信息,再根据三角测量原理计算光点的深度。将光信号发射器沿竖直和水平方向对待测物体进行逐点扫描就可以得到该物体整个表面的深度信息。点式结构光只是对一个点进行处理,算法简单、计算速度较快,适用于小范围三维重建。但是这种方法是逐点进行测量,效率较低。
线式结构光与点式结构光原理相同,不同的是线结构光使用线形光源。光信号发射器将线形激光投射到目标物体表面,使用相机拍摄带有线形激光的图像,根据三角测量原理对线式结构光发射器和相机的位置进行计算,从而得到投射线位置的三维信息。与点式结构光相比,线式结构光得到的三维信息更为丰富且测量效率较高。
面式结构光也称为编码结构光,其原理是利用投影仪将编码图案投射到目标物体上,然后使用相机拍摄目标物体得到带有编码图案的物体表面图像,再根据解码方法和三角测量原理计算得到目标物体的三维信息。根据编码方式的不同可以分为空间编码和时间编码,空间编码只有一种投射方式,时间编码有两种及以上的投射方式。投射图案的编码方式是影响三维重建精度和效率的重要因素。面结构光与点式、线式结构光重建相比效率较高,重建速度较快,适合较小物体的三维重建,如人脸重建。
潘硕等[28]提出了一种基于多线结构光的深孔类零件表面三维重建方法,使用多线结构光图像测量系统获取零件内表面的结构光图像,并结合深孔零件的特征,建立基于柱坐标系下的远心镜头成像模型,测量的精度误差满足实际要求。曾凯等[29]提出了基于线结构光的弯道类工件三维重建方法,使用标定好的线结构光三维重建平台获取工件的点云数据,该方法具有较高的重建精度,能够满足工业实时检测的要求。陈荣等[30]提出了一种基于空间编码结构光的稠密重建方法,使用红色的正弦光栅条纹和蓝色伪随机点组成的编码模式,并利用零均值归一化互相关进行匹配,该方法不需要对投影仪进行标定和颜色校正且只需要一个图像完成三维重建,在保证三维重建精度的前提下提高了速度。Gunatilake等[31]提出了一种利用履带式机器人实现管道三维重建的解决方案,利用结构红外激光环形投影仪和RGB相机,并使用了立体映射、光线投射和RGB深度映射等图像算法对管道的三维轮廓进行了重建,该方案的使用性能和精度得到了保障,但是需要机器人的定位要求较高。Montusiewicz等[32]利用结构光技术的三维扫描仪通过数字化的方式展示了历史服装的三维模型,推动了服装文化的记录和传播,探讨了利用三维模型和信息技术在数字资源空间中推广文化遗产的途径。
1.2.2 基于相位的光栅重建
基于相位的光栅重建通过分析目标物体表面条纹图像包含的深度信息的相位变化,然后根据相位和物体深度的关系获得目标物体表面的深度信息,该方法的原理也是三角测量,但核心是相位的计算。光栅重建测量的范围较大、精度较高、速度较快。使用光栅条纹投影进行三维重建的方法较为广泛,常用的方法主要有傅里叶变换轮廓术和相位测量形貌轮廓术等。
傅里叶变换轮廓(fourier transform profilometry,FTP)术由Takeda等[33]提出,基于傅里叶变换,利用计算机对带有光栅条纹的目标物体表面的图像在空间域进行傅里叶变换、滤波和傅里叶反变换,获取光栅条纹在物体表面的相位分布,进而获得目标物体表面的三维信息。傅里叶变换轮廓术使用一副图像就可以获得目标物体的三维信息,重建速度较快,可以进行实时重建,但是物体表面的反射系数对其影响较大,重建精度不高。
相位测量轮廓(phase measurement profilometry,PMP)术利用投影仪投射多幅具有特殊相移差的条纹图像到目标物体,然后通过三角函数法计算每个像素的相位值,进而获得目标物体的深度信息。该方法需要多幅图像才能获得物体表面的深度信息,重建速度相比于FTP较慢,但可以弥补FTP的缺点,而且具备重建精度高、范围较广等优点,因此广泛应用于工业测量领域[34]。
Lü等[35]提出了一种基于极限学习机网络的相位差-三维坐标映射模型,该模型以标定板的圆心数据为样本库,通过分析样本的网络输出误差确定隐层神经元的数量,利用极限学习机网络分别对训练样本和测试样本的输出进行预测,满足了三维测量中高精度、高效率的要求。刘飞等[36]提出了改进的三频三步相移结构光三维重建方法,该方法将最高频率的3张图像应用三步相移算法得到精度最高的包裹相位,计算出背景光强和调制光强并代入剩余条纹图中得到其包裹相位,最后进行相位展开得到展开相位进而完成三维重建,解决了传统方法主要投影多编码图像和效率低的问题。薛峰等[37]分析了实际工作环境和物理模型对三维重建的影响,针对因亮度饱和而导致重建缺失和精度低的问题,提出了一种相位融合和多频外差算法相结合的方法。邓仕超等[38]分析了传统的三频外差产生相位跳变误差的原因,使用误差范围约束,并利用公式回带和多频外差算法展开相位信息,降低了解包裹过程中的相位误差跳变,使得三维重建结果的表面较光滑且细节清晰。
2 被动式三维重建
被动式[39-40]三维重建没有主动获取环境深度图的能力,只能通过相机采集图像,然后利用多视图几何原理对图像进行分析处理,从而获取物体的三维信息。根据相机数量的多少,被动式三维重建主要分为单目视觉、双目视觉和多目视觉的三维重建方法。
2.1 单目视觉
单目视觉只使用一个摄像头作为图像采集设备,使用的图像可以是单张或者序列图像,主要是通过提取图像中的亮度、纹理、轮廓、特征点等信息来估计图像的深度信息,具有低成本、操作简单等优点。单张图像很难包含物体所有的三维结构信息,因此使用单张图像实现三维重建的难度较大。下面对明暗恢复形状法、光度立体视觉法、纹理恢复形状、轮廓恢复形状、焦点恢复形状和运动恢复结构单目视觉三维重建方法进行阐述。
2.1.1 明暗恢复形状法
Minsky[41]于1970年提出明暗恢复形状(shape from shading,SFS)法,也称为明暗度法。该方法需要已知光源方向,并假设物体表面为朗伯反射模型和成像几何关系为正交投影,根据单幅图像各点对应的亮度值代入预先设计的色度模型中,结合表面可微分性、曲率约束和光滑度约束等,求解各点深度信息。SFS方法只需要一幅图像就可以进行三维重建,运行时间短,但是幅单张图像中获得的信息较少,重建的效果不理想且光照对其影响较大,不适合在室外进行三维重建。
明暗恢复形状法经过多年的发展,主要有最小化方法、演化方法、局部分析法、线性化方法等[42]。最小化方法在全局范围内将图像与反射图的亮度的差值能量最小化。演化方法通过迭代方法从图像中的特征点开始推演出物体表面的三维信息。局部分析法假设已知物体的表面形状,通过求解其与反射图的方程组进而求出物体表面的三维信息。线性化方法是通过Taylor级数将SFS反射函数转换成不同阶次未知量的线性和[43]。Fan等[44]基于Cook-Torrance 双向反射分布函数建立了SFS模型,该模型建立在相机的笛卡尔坐标系上,具有任意光源位置,通过图像实验证明了该算法具有良好的鲁棒性。李健等[45]利用深度相机融合SFS光照约束实现了物体的三维重建,在深度信息的基础上加入了光照约束来优化深度值,重建出的三维模型细节更清晰,精度更高,但受深度相机的制约仅适用于室内重建。
2.1.2 光度立体视觉法
Woodham[46]提出了光度立体视觉(photometric stereo,PS)法,根据光源方向和图像明暗之间的关系求解物体表面的三维信息。其工作原理是在相机位置及周围场景不变的情况下改变光源方向或者光源颜色,获取目标的多张图像,然后通过联立亮度方程求出物体的表面形状,进而恢复出物体的三维模型。根据光源和相机等因素,光度立体成像系统可分为平行光源或点光源面阵相机成像系统和线形光源线阵相机成像系统[47]。与明暗恢复形状法相比,该方法使用多个光源,获得的三维信息较多,但是对光照比较敏感,不适合室外场景重建。
为解决由理想的朗伯体表面在现实中是有限的带来的缺点,研究者们提出基于非朗伯体表面的光度立体视觉方法。Shen等[48]提出了一种基于核回归的高效光度立体测量方法,该方法将正态估计表述为核回归,并进一步表述为特征分解。通过快速的矩阵计算和适当的正规初始化来加速留过程,提高了计算效率。Quéau等[49]基于对噪声和异常值的精确建模,提出了一种鲁棒变分方法,解决了在不准确的照明存在的光度立体问题。朱可等[50]提出了一种基于光度立体视觉的采用二维平面图像重构三维表面的方法,从显微成像角度建立近场点光源模型,通过PS求解研究对象表面的法向量,最后由Frankot-Coellappa算法获取表面深度信息,实现了机械零部件在无拆卸状态下的磨损表面的三维测量。简振雄等[51]提出了一种进场非朗伯光度立体视觉高亮金属表面纹理的重构方法,利用共位光源下的逆反射模型解耦金属表面法向量,并使用最大值融合策略克服阴影影响,提高了表面纹理重构的准确性。
2.1.3 纹理恢复形状法
纹理恢复形状(shape from texture,SFT)法是根据图像的纹理信息来获取物体的三维信息,然后重建出物体的三维模型。该方法根据单张图像重建出物体三维模型,重建精度和速度比较高,而且对光照和噪声都不敏感。但是它只适用于具有纹理特征的物理,实用性不高。
Massot等[52]基于一种不需要选择最优局部尺度的图像局部频率估计方法,将图像局部分解成小块,从而估计出图像的局部频率变化,用于解决从纹理中恢复形状的问题。Loh等[53]提出了一种从纹理中提取形状的方法,假设表面光滑,对锋面纹理进行估计,正确的估计会导致最一致的表面,并通过一致性约束恢复表面。Forsyth等[54]通过假定纹理元素具有有限数量的固定形状类型,构造了一个最大后验估计的表面系数仅使用单个纹理元素的变形,描述了一个形状从纹理方法。
2.1.4 轮廓恢复形状法
轮廓恢复形状(shape from silhouettes/contours,SFS/SFC)法简称“轮廓法”,主要思想是通过单目相机从不同角度拍摄图像来获取物体的轮廓信息,然后根据轮廓信息恢复物体的三维模型,图像的数量越多,重建结果越精确,会导致计算量增大,降低了重建的速度。轮廓恢复形状法又可以分为体素法、视壳法和锥素法。
Martin等[55]首先提出体素法,这种方法将三维空间离散化为体素,再将前景与背景进行分割,然后将所有能够投影到前景的体素点集合起来就能够重构出物体的三维模型。视壳法[56]是在不同视角拍摄图像,将得到的轮廓图通过椎体反投影到三维空间中形成三维锥壳,反投影得到三维锥壳组成视壳,当拍摄视角足够丰富时,那么就可以将视壳的形状认为是物体的三维形状。锥素法[57]是由视壳法发展而来,即通过对极几何的方法把视壳法的运算转换到二维空间中,使得运算变的简单。
2.1.5 焦点恢复形状法
焦点恢复形状(shape from focus,SFF)法也称为调焦法,是通过分析相机光圈、焦距和图像清晰度之间的关系来恢复物体的深度信息,然后重建出物体的三维模型[58]。由于相机镜头具备光学聚焦原理,物体只有在相机焦距处才会拍摄出比较清晰的图像,然后建立物体到投影中心的距离与图像清晰度之间的关系,进而得到图像的深度信息[59]。
调焦法对光照不敏感,重建精度比较高,但是它与相机光圈和焦距有关,需要不断设置相机光圈和焦距,不能实时重建,对纹理复杂的物体重建效果也不理想。调焦法具体可以分为聚焦(shape from focus,SFF)法和离焦(shape from defocus,SFD)法。聚焦法就是被测物体在相机焦距处,再根据成像公式求解得到被测物体相对于相机的距离[60-61]。离焦法则与聚焦法相反,不需要被测物体在相机焦距处,而是根据离焦模型计算被测物体相对于相机的距离[62]。
2.1.6 运动恢复结构法
运动恢复结构(structure from motion,SFM)法首先从不同视角采集图像,通过图像的纹理信息提取特征点;然后每两幅图像之间进行特征点匹配,并计算特征点间对应关系和相机在三维空间中的相机姿态;再利用三角测量原理将该图像对的相机姿态与其特征点对求解得到三维坐标,从而生成三维点云,并用光束法平差对三维点云进行优化处理;当采集到新图像时,在已处理的图像中选择一张与新图像进行特征匹配并求解出新图像对应的相机姿态,计算出其对应的三维点云,与之前的三维点云融合,从而得到不同视角下的三维点云。该算法使用多幅图像来获取目标物体的三维信息,使得重建结果比较精确,但是也会导致计算量较大,重建速度较慢。SFM常用的方法有增量式SFM、全局式SFM和混合式SFM等。
增量式SFM[63]是目前应用最广泛的运动恢复结构法,重建流程如图3所示。一般先使用尺度不变特征变换算子对每张图像进行特征点检测,并进行特征点匹配。再使用随机抽样一致算法和八点法估计出基础矩阵,然后使用三角化对匹配的特征点进行操作,得到其对应的三维点云信息,通过捆绑调整不断地优化场景结构。由于在求位姿与三维点时会有大量噪声干扰,且计算结果会发生漂移,通过添加光束平差(bundle adjustment,BA)算法进行优化处理。全局式SFM[64]将所有图像添加到场景中,计算所有的相机姿态,然后进行三角化处理。全局式SFM仅采用一次光束法平差优化,大大提高了重建速度,且精度较高,但是对大规模场景进行重建时,重建的效果并不理想。混合式SFM[65]是将上述两种方法进行融合,使用全局式SFM估计相机旋转矩阵,增量式SFM估计相机中心位置坐标,然后进行局部捆绑调整。
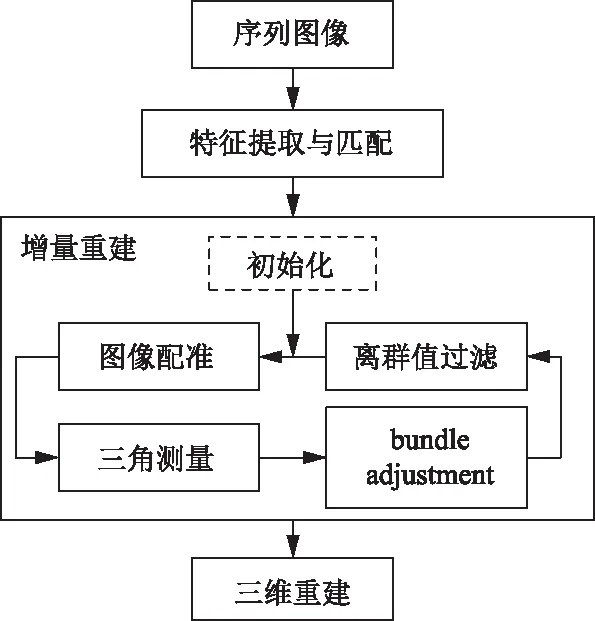
图3 增量式SFM重建流程图Fig.3 Flow chart of incremental SFM reconstruction
陈辉等[66]利用运动恢复结构法实现了对叶片体积的测量,使用智能手机采集叶片图像,通过SFM获取其点云数据,采用模糊C均值聚类算法提取单个叶片,重建出叶片的网格并通过网格法计算叶片的体积,可以满足多种不规则叶片体积计算的要求。汪侃等[67]提出一种邻图配对式SFM重建拓扑结构,该结构首先以首张图像相机坐标系下的点云作为主点云,然后使用抗噪声的尺度迭代最近点法配准点云,最后规定世界坐标系实现点云尺度信息的恢复。梁秀英等[68]基于运动恢复结构实现了玉米植株的三维重建,并通过欧式聚类和圆柱拟合等算法提取了单株、茎秆和叶片等的点云数据,为玉米植株表型的研究提供了测量方法。
2.2 双目视觉
双目视觉通过双目相机拍摄目标物体的左右两幅图像,然后搜索两幅图像中匹配的像素,并计算其匹配像素的位置差,将这个差值设置在图像的灰度范围内,构成两幅图像匹配像素的位置差的图像,称作视差图像。获取视差图像之后,根据三角测量原理,计算视差图像的每个像素点的三维空间坐标,得到目标的三维点云。之后使用多边形网格剖分算法或自由曲面拟合算法,对目标表面进行三维重建,最终得到目标的三维空间信息。双目视觉计算过程主要包含四个步骤:相机标定、图像校正、立体匹配和三维重建计算[69],如图4所示。
相机标定的目的是在将二维图像信息转化为三维空间信息的过程中获得两个相机的内部物理信息和相机直接的相对位置信息,相机标定的精度会直接影响三维重建的精度。常见的相机标定方法有传统标定方法[70-71]、基于主动视觉的标定方法[72]和相机自标定法[73-74]。
图像校正的目的是将立体匹配的搜索范围从二维降到一维,使两幅图像对应的极线位于同一条扫描线上并与基线平行,在搜索两幅图像对应点时,只要在该点对应的扫描线上搜寻即可,可以使立体匹配得到简化。图像校正的常用方法主要有基于平面和基于外极线的校正方法。
立体匹配是双目视觉三维重建的基础,也是重点难点。立体匹配的目的是在两幅图像中找到相对应的匹配像素点,通过计算像素点位置的差值从而求取深度值。由于三维空间中的环境复杂、物体本身的几何形状和表面材质特性、相机镜头畸变和相机的物理信息以及拍摄时产生的噪声等因素,都会影响立体匹配的精度,而且单个算法也会存在较大的局限性,从而导致三维重建的结果不理想。
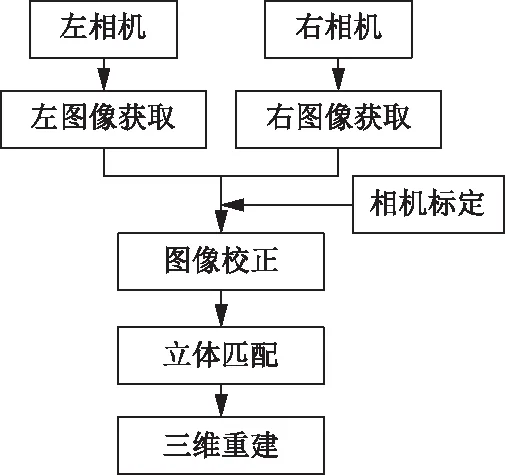
图4 双目视觉三维重建流程图Fig.4 3D reconstruction flow chart of binocular vision
Scharstein等[75]对立体匹配算法进行了总结和评价,将基于两幅视图的立体匹配算法归纳为匹配代价计算(matching cost calculation)、匹配代价聚合(matching cost aggregation)、视差计算及优化(disparity computation and optimization)和视差细化求精(disparity refinement)四个步骤。
经过相机标定、图像校正和立体匹配之后获得视差图像,再根据三角测量原理和相机基线等信息计算图像的深度信息,进而可以求解得到目标物体的三维信息。双目视觉三维重建方法比较成熟,应用广泛,但是运算量比较大。立体匹配的准确性决定了三维重建的精度,可以通过优化立体匹配算法来提高三维重建的效果。
丁苏楠[76]对基于自适应支持权重的立体匹配方法进行了优化,提高了遮挡区域的匹配度,并使用双目视觉系统实现了工件的精准定位,依靠视差图恢复出工件的三维信息,实现了工件的准确抓取功能。Huang等[77]提出了一种基于双目视觉的输电线路走廊自定位和故障检测方法,针对参数间强耦合的问题,提出了基于重构结果误差的校正方法,并使用最小二乘拟合插值对基于半全局立体匹配算法获得的视差图进行优化,基于此,建立了障碍物到电缆检测机器人的距离估计模型,该模型具有极高的距离估计精度和鲁棒性。Wei等[78]将双目三维重建遥控应用到遥控挖掘机上,使用基于绝对差和进行图像匹配,根据赢家通吃策略求得视差,完成工作场景的三维重建,使得遥控挖掘机在危险工况下完成工作,保障了操作人的人身安全。
2.3 多目视觉
多目视觉与双目视觉三维重建的基础理论基本相似,不同是多目视觉采用了三台相机或更多相机,其原理如图5所示。多目视觉利用多台相机从不同视角采集图像,通过更大的视野减少测量盲区,还可以降低双目视觉中误匹配的影响。但是由多张图像导致的大数据会使计算量增大、消耗时间长,不能满足实时性要求,而且容易受光照影响。多目视觉广泛应用在机器人视觉、自主驾驶等领域[79-80]。

Pj表示被测物体的被测点;Pj,k-1、Pj,k、Pj,k+1表示相机1、相机2、 相机3成像平面上被测点形成的特征点 图5 多目视觉原理图[81]Fig.5 Schematic diagram of multi-ocular vision[81]
Xu等[82]利用工业内窥镜和多相机三维重建开发了一种实时三维测量系统,首先使用工业内窥镜捕捉原始负荷表面的图像,然后设计了一种多特征的深度关键帧分类器用于提取深度信息,最后,提出多相机阵列的炉料表面三维重建方法来实时获取高炉炉料表面的三位形状。钱志敏[83]将单目相机与双目相机组合成多目相机应用于六自由度机器人上,使用单目相机初步获取目标物体的空间位置,双目相机实现目标物体的精确定位,机器人收到位置信息之后驱动机械臂进行准确抓取。Tang等[84]提出了基于四目立体视觉系统的再生骨料钢管混凝土柱的表面变形跟踪测量,采用自动标定和动态表面动态测量结合的方法,建立了四目视觉坐标与点云匹配相结合的数学模型,实现了三维变形曲面的重建。
点云对齐是多目视觉三维重建的重点和难点,点云配准的作用是将不同视角下获得的点云数据拼接到同一坐标系下,从而获得完整的三维模型。点云配准主要分为初步配准和精细配准。初步配准是使相同的之间更好的融合在一起,同时避免精细匹配陷入局部最优解[85-86]。点云初步配准是通过点云特征匹配来实现,Lowe[87]利用二维尺度不变特征转换算法实现了点云特征的提取,用于实现实物物体或场景的不同视图之间的可靠匹配。Sipiran[88]基于Harris算子提出了三维目标兴趣点检测方法(Harris 3D),实现了对目标物体特征点的提取。点云精细配准是将两个点云的相对位置更加精确,使得点云的衔接性更好。Besl等[89]首先提出迭代最近点算法(iterative closest point,ICP),通过计算每个点的最近的点进而确定他们之间的关系,不仅提高了点云配准的精度,且为点云配准提供了理论基础。Chen等[90]提出了一种基于学习和变换不变特征(transform-invariant features-registration,TIE-Reg)的点云配准方法,充分利用了点云的变换不变性,对刚性变换具有很强的鲁棒性。Han等[91]将分层搜索方案与基于八叉树的ICP算法结合,提出了基于粗糙初始变换误差的大规模三维环境模型的快速精细匹配方法,对初始变换误差不敏感,通过启发式逃逸决策解决局部最小问题。
多目视觉三维重建从多个视角获取目标物体的三维信息,与单目视觉三维重建中的运动恢复结构法类似,方法简单,通过多个视角的三维信息融合在一起,重建出三维模型,重建的效果较好,但是设备结构复杂,不适用于实时重建。可以通过优化点云对齐算法提高三维重建的效果。
3 基于深度学习的三维重建
Ciresan等[92]发表了卷积神经网络(convolutional neural networks, CNN)在计算机视觉领域的研究成果,深度学习在计算机视觉领域开始流行起来。由于CNN[93]在图像处理方面具有明显的优势,它可以直接将图像作为网络的输入,避免了传统图像处理算法中特征提取和数据重构的复杂过程。相比于上述文章提到的三维重建方法,基于深度学习的三维重建方法发展较晚,但是该方法发展迅速,继而深度学习在三维重建研究上取得了较大的进展。深度学习是在设计好网络的结构和代价函数之后,自己根据数据集提供的输入与结果来调整参数。根据三维重建模型的表示方式主要分为基于深度图、点云、体素和网格四种构建方法。
深度图用灰度图表示,每个像素表示相机到物体的距离,灰度越深距离越近。Eigen等[94]提出一种用单张图像使用神经网络恢复深度图的方法,该方法将神经网络分为全局估计和局部估计,并使用一个尺度不变的损失函数进行回归。Nguyen等[95]提出了一种基于结构光和深度卷积神经网络集成的三维重建技术,该技术使用端到端人工神经网络将由散斑图案组成的多个灰度图像转换成3D深度图,通过多个特征映射来重建三维形状,该方法提高了重建精度并且由较好的鲁棒性。
体素的定义类似二维图像中像素的概念,具备真实的三维数据,该方法一般通过编码器-解码器方式进行三维重建。Choy等[96]提出使用3D-R2N2 (3D recurrent reconstruction neural network)网络结构完成物体二维图形到空间三维结构的映射,建立基于体素的单视图或多视图三维模型。3D-R2N2网络可以在纹理信息较弱的情况下完成三维重建,但是会出现部分模型断裂失真现象。Huang等[97]提出了一种高效的基于超体素的卷积神经网络,该网络可以高效融合在线三维重建过程中多视角二维特征和投影在超体素上的三维特征,实现了二维-三维联合学习和三维语义预测。
点云是坐标系下一系列点的数据集,每个点都包含三维坐标、色彩等信息。点云数据的特征是无序切不规则,需要对其进行规则化处理。Fan等[98]首次提出利用深度学习方法对物体进行基于点云的三维重建。Chen等[99-100]提出一种Point-MVSNet方法对物体的点云进行处理,将二维纹理信息与三维深度信息融合,提高了三维重建精度;2020年又提出VA-Point-MVSNet基于点的多视点立体视觉深度框架,该方法首先生成粗糙的深度图并将其转换为点云,然后通过估计当前迭代深度与地面真实深度之间的残差来迭代细化点云。该方法准确性高,计算效率高还具有较强的灵活性。
网格就是多边形网格,包含了三维模型的点、边和面等信息。与前三种方法相比,基于网格的表示方法具有形状细节丰富的特点,而且相邻点间有连接关系。Wang等[101]首先输入一张RGB图像,利用卷积神经网络提取图像特征,然后使用图卷积网络构建三维网格结构,再对三维网格进行变形,直到接近物体的三维结构并输出其三维模型。Kim等[102]提出了一种用于相机坐标系的单镜头三维多人形状重建的基于端到端学习的模型,该模型使用一种网格样式表示,在每个网格单元中预测研究对象和边界框的信息,以单次射击的方式执行人三维形状的重建。Jeong等[103]提出了一个以2D人体姿态来估计3D人体网格的网络,并使用基于循环结构的弱监督学习方法来训练此网络,该方法降低了地面真实三维数据的获取难度,实现了有效的三维人体网格重建性能。
基于深度学习的三维重建方法近些年发展迅速,应用比较广泛。但是该方法使用的数据集较少,数据集的增加会使得学习的能力更强;点云和网格的表示形式是不规范的,不能较好地直接应用到深度学习中。
4 结论和展望
根据三维重建的技术原理,对非接触式三维重建技术进行了介绍,分析了各种方法的优缺点和适用范围。
飞行时间法不对图像进行分析,重建速度较快,可以实现实时重建。但是容易受外界光照的影响。目前主要是利用TOF相机进行三维重建,可以通过降低误差来提高三维重建的精度。
点式结构光算法简单、重建速度快,但是该方法通过逐点计算目标物体表面的深度信息,重建的效率较低,适用于小范围三维重建。
线式结构光使用线性光源,与点式结构光相比,重建效率较高。适用于小范围三维重建。
面式结构光适用于小范围三维重建,投射图案的编码方式是影响三维重建精度和效率的重要因素,可以通过改善编码方式来体改重建的精度。
傅里叶变换轮廓术可以通过一副图像获取三维信息,重建速度快且能够实现实时重建,重建的范围较大,但是物体表面的反射系数对其影响较大,重建精度不高。
相位测量轮廓术使用多幅图像进行三维重建,获得的三维信息较为丰富,重建范围较广可以用于工业测量领域。
明暗恢复形状法可以根据单幅图像获得目标物体的三维信息,重建速度较快,但是该方法对光照较为敏感,不适用于室外环境。
光度立体视觉法使用多个光源采集多幅图像,获得的三维数据比较丰富,但是在现实中,目标物体表面比较复杂,其重建的准确性依赖于反射模型。同时对光照较为敏感,不适用于室外重建。
纹理恢复形状法通过纹理信息来获得目标物体的三维信息,对外界光源和噪声不敏感,但是对弱纹理或者无纹理的物体重建效果不好。
轮廓恢复形状法的方法原理较为简单,只通过图像的轮廓获取目标物体的三维信息,图像的数量与重建的精度成正比,但是会增加计算量,降低重建速度。
焦点恢复形状法对外界光源不敏感,与图像的清晰度和相机的光圈、焦距有关,需要设置相机的参数使得拍摄图像的清晰度更好。
运动恢复结构法使用单目相机从多个视角采集图像进行三维重建,方法简单,获得三维数据较多,重建结果比较精确。但是会导致计算量增大,三维重建速度较慢。同时点云配准也是该方法的难点,可以从点云配准入手提高三维重建的准确性。
双目视觉三维重建适用范围较广,方法比较成熟,最关键的步骤是立体匹配,其结果的准确性决定了三维重建的精度,通过改进立体匹配可以提高重建的效果。
多目视觉三维重建得到目标物体的多视角三维信息,通过点云对齐获得物体的整体三维信息,方法简单且重建的精度较高,但是多目视觉三维重建需要处理多张图像,导致运算复杂,重建速度较慢。可以通过改善点云对齐的方式提高两相同点云的配准,进而提高三维重建的精度。
上述方法可以归结为传统三维重建技术,光照和噪声均会对降低研究对象的三维重建准确度,它们的重建效果在很大程度上依赖于图像的内容和质量,以及精确校准的相机,并且有的方法需要添加先验条件,这也制约了三维重建技术的发展。
基于深度学习的三维重建技术的成功很大程度上取决于训练数据的可用性,但是图像和三维数据公开数据集的估摸较小,并且真实场景数据集中包含的二维图像和三维模型数量太少,难以利用深度学习的优势进行训练。
基于深度学习的三维重建技术可以克服制约传统三维重建技术发展的瓶颈,因此未来的研究方向可以通过将传统三维重建和基于深度学习的三维重建融合进行开展。目前大部分三维重建技术针对的是静态物体或者是小规模物体,对于动态物体和大规模场景等的重建问题无法较好地实现,这也是未来的研究热点。
猜你喜欢
北京航空航天大学学报(2021年6期)2021-07-20
小学阅读指南·低年级版(2020年11期)2020-11-16
科技资讯(2016年25期)2016-12-27
中国文化遗产(2016年5期)2016-12-14
电脑知识与技术(2016年20期)2016-08-19
杂文选刊(2015年12期)2016-01-12
少儿科学周刊·儿童版(2015年2期)2015-07-07
新青年(2015年2期)2015-05-26
科普童话·百科探秘(2015年4期)2015-05-14
意林(2014年17期)2014-09-23
