
基于改进YOLOv5和视频图像的车型识别
2022-09-30 04:25王志斌冯雷张少波吴迪赵建东
科学技术与工程 2022年23期
王志斌, 冯雷, 张少波, 吴迪, 赵建东*
(1. 河北雄安京德高速公路有限公司, 保定 071799; 2.北京交通大学交通运输学院, 北京 100044)
有效地识别车辆的身份信息对智慧交通的建设起着至关重要的作用。车牌是车辆的重要标识,是确定车辆身份信息的重要来源,然而在实际应用中由于车牌遮挡、套牌等现象,仅仅通过车牌信息可能无法准确的确定车辆身份,因此快速而又准确识别出车辆的其他特征显得尤为重要。而车型作为车辆的固有属性,很难进行更改,可以弥补车牌识别的不足之处,对车牌识别的结果进行补充。
随着智能交通的发展,大量的交通监控摄像机被布置在路网中,通过道路系统中的监控摄像机,可以获得丰富的道路监控视频,为利用图像处理技术识别车型提供了可能。利用图像处理技术,可以准确的检测出图像中车辆的信息,不需要额外安装设备,不会对路面造成破坏,能够提供直观的车辆图像。根据从图像中提取特征的不同,可以把基于图像的车型识别方法分为两类:基于图像特征描述符和基于深度学习神经网络。
基于图像特征描述符[1-3]的车型识别主要是从图像中提取方向梯度直方图(histogram of oriented gradient, HOG)、尺寸不变特征(scale-invariant feature transform, SIFT)、加速鲁棒特征(speed up robust features, SUFT)等特征,构建车型特征集,利用支持向量机(support vector machine, SVM)、贝叶斯等分类器完成车型的分类。但是该方法需要根据图像的特点选择恰当的特征描述符和分类器组合来达到较好的效果,并且识别准确率不高,检测效率低。而基于深度学习的车型识别利用卷积神经网络自动提取图像的特征,达到远超传统算法的精度,具有明显的优势,因此得到了广泛的应用。桑军等[4]提出基于Faster-RCNN[5]目标检测模型与ZF、VGG-16以及ResNet-101 3种卷积神经网络分别结合的策略,三种组合在数据集上展现了很好的泛化能力。由于该方法对候选框进行了预分类,虽然车型识别的精度有所提升,但是检测速度较慢。石磊等[6]在Caffe深度学习框架下提出了一种基于MexNet结构的网络模型,对车型的图像进行训练,并与传统CNN(convolutional neural network)算法进行比较,MexNet结构的识别准确率较高,但模型相对复杂,实用性不是很强。陈立潮等[7]提出了一种改进的AlexNet网络模型,融合嵌入了循环神经网络,对池化方式结合研究对象进行了自定义,并对参数的更新进行了合理的组合,提高了网络的泛化能力。但其存在模型参数量过大、运行时内存占用高的问题。李晓琳等[8]基于前端Cortex-M开发板内嵌的CMSIS-NN(cortex microcontroller software interface standard neural network)库搭建车型识别模型,利用CMSIS-DSP(cortex microcontroller software interface standard digital signal processor)加快检测车型速度,检测精度达到94.6%,但是该方法将车型识别作为分类任务研究,容易受到背景信息的影响,精度有待提升,泛化能力较差;郭融等[9]利用改进深度可分离卷积(single shot multibox detector,SSD)算法用于车型研究。引入反残差模块来解决通道数少、特征压缩导致的准确率下降的问题。实验证明在BIT-Vehicle数据集上准确率达到96.12%,检测速度提高至0.075 s/f。
综上,为了提高车型识别的精度和速度,满足交通场景下的使用需求。现使用YOLOv5目标检测模型进行车型识别。针对数据集中各车型类别不均衡的现象,使用多种图像处理方法均衡车型数量;为了提高YOLOv5车型识别精度,使用RFB(receptive field block)模块增大感受野,捕捉输入图像的全局特征;另外,引入SimAM注意力机制,提高模型的特征提取能力。改进后的YOLOv5模型在检测速度和检测精度上达到较好平衡,能适用交通场景下车型识别检测,达到高精度实时检测要求。
1 YOLOv5模型
1.1 网络结构
2020年6月YOLOv5模型在github上发布,它并不仅仅是一个网络模型,而是具有不同深度和宽度的4个模型。模型深度和宽度的增加会带来识别性能的提升,但是同样也会消耗大量的计算资源,使得识别速度降低。考虑到检测对象是道路上行驶的车辆,对实时性要求较高,因此采用深度和宽度最小的YOLOv5s(下文统一称为“YOLOv5”)模型作为基础网络进行优化,完成车型识别任务。
YOLOv5网络结构主要包括主干特征提取网络(Backbone)、加强特征融合部分[FPN(feature pyramid network)+PAN(path aggregation network)]的检测层(Head)部分。
主干特征提取网络由CSPDarknet53构成,如图1中红色虚线部分所示,其主要组成BottleneckCSP[10]结构,在YOLOv5网络中改进为C3结构,去掉主分支的bottleneck后的卷积层,并把融合后的BatchNorm层和激活层LeakyReLU去掉,减少计算参数,提高了计算效率。改进前后的结构如图2所示,图2中的conv2d是普通的卷积层,BatchNorm层是批归一化层,CONV层是由conv2d、BatchNorm以及激活函数层构成。另外YOLOv5提出了一个结构Focus模块,通过对输入特征图切片操作,达到快速下采样,提高深层语义信息的特点。
加强特征融合部分主要由特征金字塔网络(feature pyramid network,FPN)[11]结构和路径聚合网络[12](path aggregation network,PAN)结构组成,如图1中黄色虚线所示,通过FPN结构融合不同尺度的特征信息,将浅层细节信息和深层语义信息进行融合,避免深层次特征提取,导致小目标信息丢失。PAN自下向上结构与FPN自上向下的结构进行配合,通过横向连接,实现不同尺度融合。
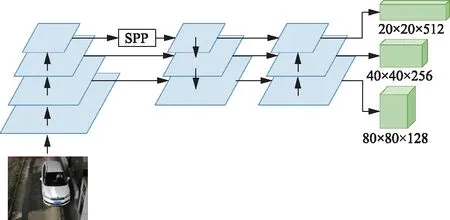
图1 YOLOv5网络结构图Fig.1 YOLOv5 network structure diagram
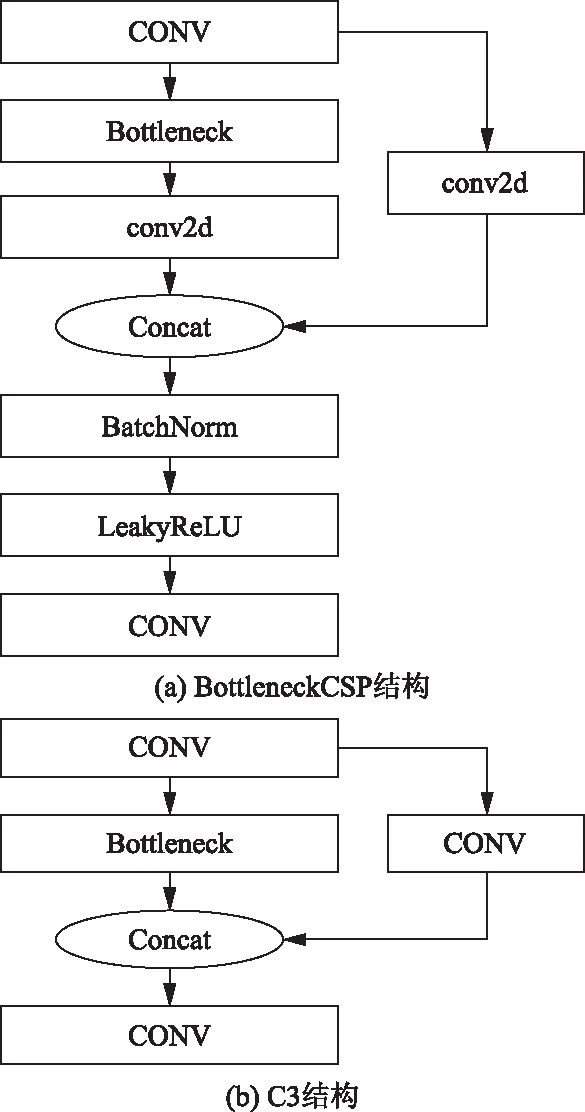
图2 改进结构Fig.2 Improved structure
检测层利用特征融合部分输出的三个大小不同特征图,以输入640×640的尺寸图片为例最终输出20×20、40×40、80×80的特征图,完成对大中小三种目标的检测。
1.2 损失函数
YOLOv5中的损失函数为
(1)
式(1)中:N为检测层的个数,YOLOv5中为3层;Bi为第i个检测层分配到先验框的目标个数;Si×Si为第i个检测层所对应得特征图被分割成的网格数;Lbox为边界框损失;Lobj为目标物体损失;Lcls为分类损失,λ1、λ2、λ3分别为上述3种损失对应的权重。
CIoU损失计算如公式为
(2)
式(2)中:b、bgt分别为预测框和标签框;wgt、hgt、w、h分别为标签框的宽、高和预测框的宽、高;ρ为两个矩形框中心的距离;α为权重系数。
Lobj和Lcls计算公式为
(1-yi)lg[1-σ(xi)]}
(3)
2 YOLOv5基准网络车型识别模型
2.1 数据集
采用BIT-Vehicle[13]数据集作为车型识别的训练集。该数据集是在不同的时间和地点利用两个不同视角的道路监控摄像头拍摄,共包含了9 850张车辆图片。将车辆分为6种:大巴车(BUS)、小型客车(Microbus)、小型货车(Minivan)、轿车(Sedan)、运动实用性汽车(sport utility vehicle,SUV)、卡车(Truck)。图3为不同车辆类型的示意图。上述6类车型涵盖了道路上所有的车辆,能够有效的判断道路上的车辆信息。该数据集图片信息丰富,不同的车辆尺度、各种颜色车辆、不同的拍摄视角以及光照条件的图片。
为了增加训练模型的泛化能力,提高在实际应用中的鲁棒性,利用高速公路收费站拍摄的视频图像数据对原始车型识别数据集进行扩充。同时原数据集中各类车型图片的数量存在不均衡的现象,其中Sedan和Bus、Minivan数量差距高达5 000多张,各类别数量的不均衡容易导致不同类别物体检测精度出现差异,训练后的模型预测结果更加偏向于数量较多的类别。因此需要对数据集进行预处理,利用图像翻转变换、添加高斯噪声、色彩变化,增加原有数据集中数量较少的车型,使得各种车型图片数量均衡,将扩充后的数据集命名为BIT-Vehicle-Extend,各部分扩充细节如表1所示。
2.2 实验环境
本文模型训练在windows10 64位操作系统中进行,编程语言为python和pytorch框架进行模型训练,实验所使用的GPU配置为Nvidia GTX1080ti。训练样本的batch size为16,训练共迭代200个epoch。
2.3 评价指标
目标检测任务要找检测物体在图像中的位置,以及该物体的类别属性,因此衡量目标检测模型性能的指标除了分类任务中用到的准确率和loss曲线外,还包括全类平均精度(mean average precision,mAP)、召回率(recall)、精确度(precision)等指标。
精确度(precision):表示检测为正样本并且分类正确的数量与检测为正样本总数的比值;召回率(recall):表示检测为正样本并且分类正确的数量与实际正样本数的比值,计算公式分别为
(4)

(5)
式中:TP(true positives)表示被检测为正确的正样本;TN(true negative)表示被检测为正确的负样本;FP(false positive)表示被检测为错误的正样本;FN(false negative)表示被检测为错误的负样本。
AP值:正样本和负样本依据设置的IOU(intersection over union)值进行划分,通过置信度的大小,确定模型是否分类正确,通过不同的置信度可以计算出不同的召回率和精确度,以召回率为横轴,精确度为纵轴,绘制曲线,曲线与坐标轴所围成的面积就是平均精度(average precision, AP)。AP值常用来描述模型性能的好坏。
mAP值:对所有类别(在本文中指的是车型的种类)的AP值进行求平均,mAP越大代表模型整体检测精度高。在实际模型评价中常采用mAP0.5和mAP0.5:0.95两个指标,VOC数据集使用的mAP0.5,将IOU的大小设置为0.5,即当IOU大于0.5时,判断为正样本。随着模型性能的不断增加COCO数据集使用更为严苛和准确的的mAP0.5:0.95作为评价指标,将IOU阈值从0.5取到0.95,步长为0.05,然后求平均。后者更有一定的合理性,检测标准更为严苛,在一般情况下小于前者。
3 改进的YOLOv5车型识别模型
3.1 增大感受野
在卷积神经网络中,感受野是指输出特征图上每个像素点在输入特征图像映射区域大小,也就是说经过卷积运算后,每个像素点对应得感受野就是在上一个特征图上与卷积核进行卷积运算得区域,可以理解为神经元所看到得区域大小。
感受野对应的区域越大表示接触到原始图像的范围也就越大,更容易发现全局特征。但是为了增大感受野而增加卷积核大小,会导致模型参数增加;或者通过池化层的方式进行下采样缩小特征图,增大感受野,但是这样会丢失特征信息。而空洞卷积可以增大网络的感受野范围,让每一次卷积都包含较大范围的信息,通过设置膨胀率(rate)大小,来控制感受野范围。
RFB[14]模块模拟人类视觉的感受和偏心度,借鉴Inception[15]网络构建形式,结合空洞卷积的思想设计了RFB模块,它的内部结构主要是由多个卷积不同膨胀率rate的卷积层构成,本文所用的RFB模型的结构如图4所示。将RFB模块添加到YOLOv5的特征提取网络中,提高模型对于车辆全局特征的提取,找出相似出行之间的不同之处。
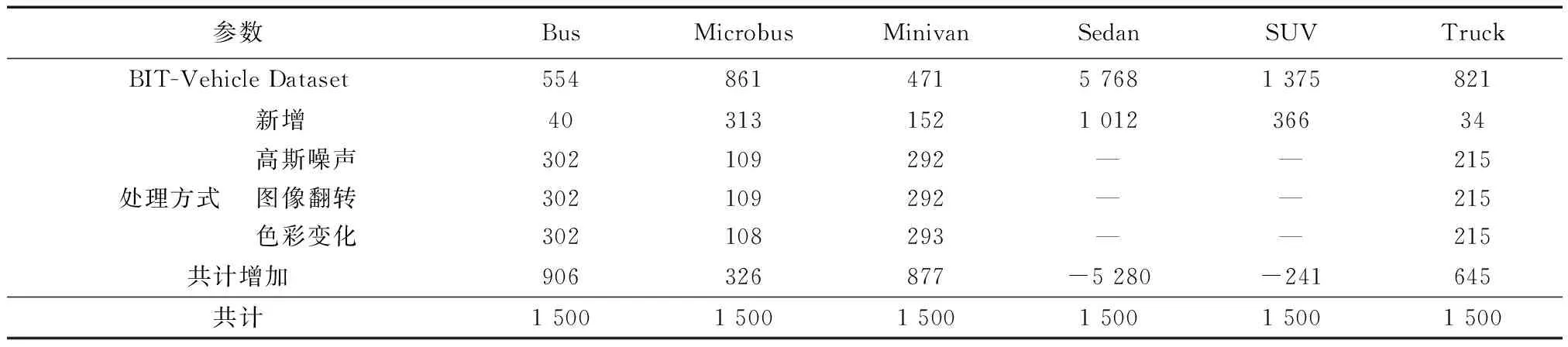
表1 BIT-Vehicle-Extend数据集Table 1 BIT-Vehicle-Extend dataset

图4 RFB模块示意图Fig.4 schematic diagram of RFB module
3.2 添加注意力机制
注意力机制的本质就是用计算机来模拟人的视觉系统,模仿人观察事物的方式,将注意力聚集在某一局部信息上,在图像处理上就是特别关注图像中的某一部分区域。由于受到距离、外界环境因素等的影响,视频图像可能清晰度不高,一些重要特征容易被忽视,采用注意力机制可以帮助神经网络更好的关注到图像的细节特征。
目前一些已有注意力模块SE[16]模块、CBAM[17]模块等已被证明可以有效的增加网络的特征提取能力,然而这些模型都会在一定程度上给网络模型引入新的参数,使模型变得更复杂。而文献[18]提出了一种简单有效的注意力模块SimAM,不同于现有的通道或者空域注意力模块,该模块不需要额外的参数便可以推导出3D注意力权值。将SimAM模块添加到Bottleneck中,形成Bottleneck_SimAM模块,增强模型的特征提取能力。Bottleneck_SimAM模块结构如图5所示。

图5 bottleneck_SimAM结构Fig.5 bottleneck_ Simam structure
4 实验分析
通过表2可知,YOLOv5在检测速度和检测精度上均优于Faster-RCNN[4]、YOLOv4[19]。改进后的网络,训练100个epoch后mAP0.5和mAP0.5:0.95比原始网络分别高0.9%和1.7%,因此改后的网络更快达到收敛。训练200个epoch后,最终改进后的网络mAP0.5相比于原始模型提高了0.7%,mAP0.5:0.95提高了1.5%。通过实验发现评价指标mAP0.5:0.95得到了更好的提升,主要原因在于原网络自身具有较高的检测性能,在面对较为宽松的评价指标时,有较好的表现,达到了较高的准确率。当选择严格的指标后,改进后的网络展现出比原始网络更好的性能,即改进后的网络预测框与真实框的重合程度更高,检测性能更好。
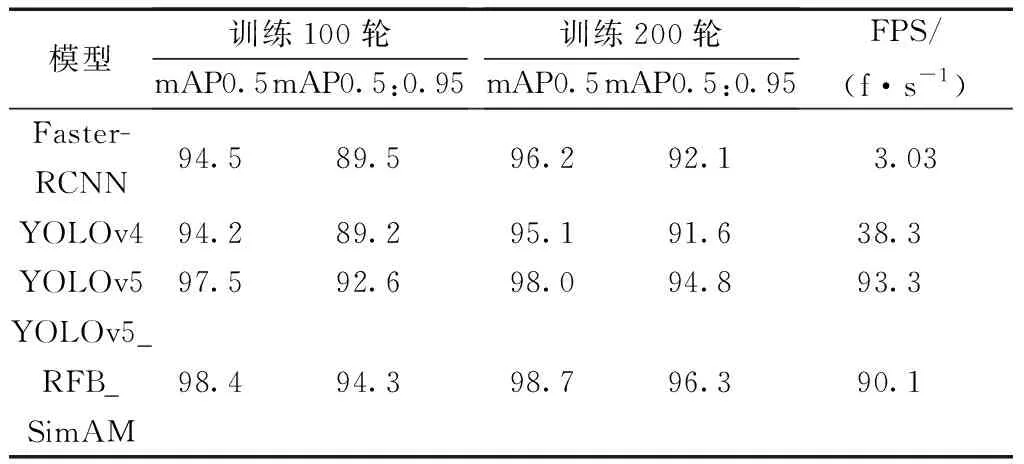
表2 实验结果对比Table 2 Comparison of experimental results
5 结论
为了车型识别任务检测速度和检测精度,选择YOLOv5模型作为基础模型完成车型识别任务,并提出改进措施,具体工作与结论如下。
(1)为了提高模型的鲁棒性。利用高速公路收费站监控视频图像数据扩充数据集,并通过图像反转、色域变化以及添加高斯噪声等图像处理技术对各车型数量进行均衡化,构建BIT-Vehicle-Extend数据集。
(2)在网络结构方面使用为了提高车型识别的精度,添加RFB模块用于增加网络感受野,有助于模型捕捉全局特征;其次将无参数的SimAM注意力机制添加Bottleneck模块中,在不增加参数的情况下,提高网络的特征提取能力。
(3)改进后的YOLOv5模型,mAP0.5和mAP0.5:0.95达到了98.7%和96.3%,远超Faster-RCNN和YOLOv4模型。相比于原始网络模型,mAP0.5和mAP0.5:0.95分别提高了0.7%和1.5%。改进后的模型检测速度达到90 f/s,能够高精度地实时检测车型信息,满足车型识别检测需求。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
机械工业标准化与质量(2022年8期)2022-10-09
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
车迷(2022年1期)2022-03-29
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
汽车与驾驶维修(汽车版)(2020年5期)2020-07-24
中国计算机报(2019年46期)2019-01-13
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
