
云南红豆杉单木生物量模型选择与树冠调控
2022-10-04 03:19欧建德欧家琳吴昊宇康永武
西北林学院学报 2022年5期
欧建德,欧家琳,吴昊宇,康永武
(1.明溪县林业局,福建 三明 365200;2.福建理工学校,福建 福州 350000;3.福州理工学院,福州 连江 350506;4.沙县林业局,福建 三明 365500)
森林生物量是森林生态系统中最基础的数量特征[1],单木生物量模型是估算森林生物量的基础[2],一直是森林生物量研究的热点内容。变量类型选取[3-6]关系生物量模型预测精度。树冠结构综合反映着生境、生长阶段、密度、竞争等环境因子,改变植物光合作用、同化能力[7-8],影响生物量积累,目前尚未见基于树冠结构的单木生物量模型的报道。导入总体树冠结构特征因子,构建反映树冠结构的单木生物量模型,提高模型拟合、预测精度显得十分必要。
云南红豆杉(Taxusyunnanensis)的10-DAB(紫杉醇半合成前体10-脱乙酰巴卡亭Ⅲ)累积含量高[9],当前研究多关注遗传规律[10-11]、培育[12-13]、采收季节[14-15]等,未见其单木生物量模型和树冠结构调控的研究报道。冠幅、冠形率和树冠率是树冠结构的二维指标体系[7,16-18],亦是调控树冠结构的指标性状。为此,以福建省明溪县3年生云南红豆杉林为对象,选择4种变量类型生物量模型,并导入总体树冠结构(冠幅、冠形率、树冠率)变量,逐步回归拟合模型,优选单木各器官(枝叶、茎干、地上部分)和全株生物量模型;比较导入总体树冠结构前后模型的拟合、预测效果,明确并验证树冠结构调控技术,以期为云南红豆杉原料林经营提供技术与理论支持。
1 研究区概况
研究地为福建省西北部的明溪县(26 °8′-26°39′N、117°4′-118°47′E),主要以低山丘陵地貌为主,地处武夷山脉南面,气候属中亚热带海洋性季风气候,年均温18.1 ℃,年均降水量1 786 mm,5-6月最多,年均蒸发量1 364 mm,年均日照时数1 750.7 h,无霜期283 d,年均相对湿度81%[19]。供试材料取自明溪县王桥的3年生云南红豆杉原料林,株行距25 cm×25 cm,林分郁闭度0.7,平均地径1.2 cm,平均树高97 cm。海拔300 m,平均坡度5°左右,山地红壤,立地肥沃。
2 材料与方法
2.1 性状测定与数据整理
2019年12月在原料林内,随机布设宽1 m、长1 m的8个样方,逐株标志并测量云南红豆杉地径、树高、枝下高、东西和南北冠幅等,分别精确至0.1、1.0、1.0 cm和1.0 cm,共计128株植株;采用全挖法,挖取样带内全部植株,带回实验室,测定枝叶生物量、茎干生物量、根系生物量。生物量测定按参考文献[20]的方法执行,样木基本情况见表1。
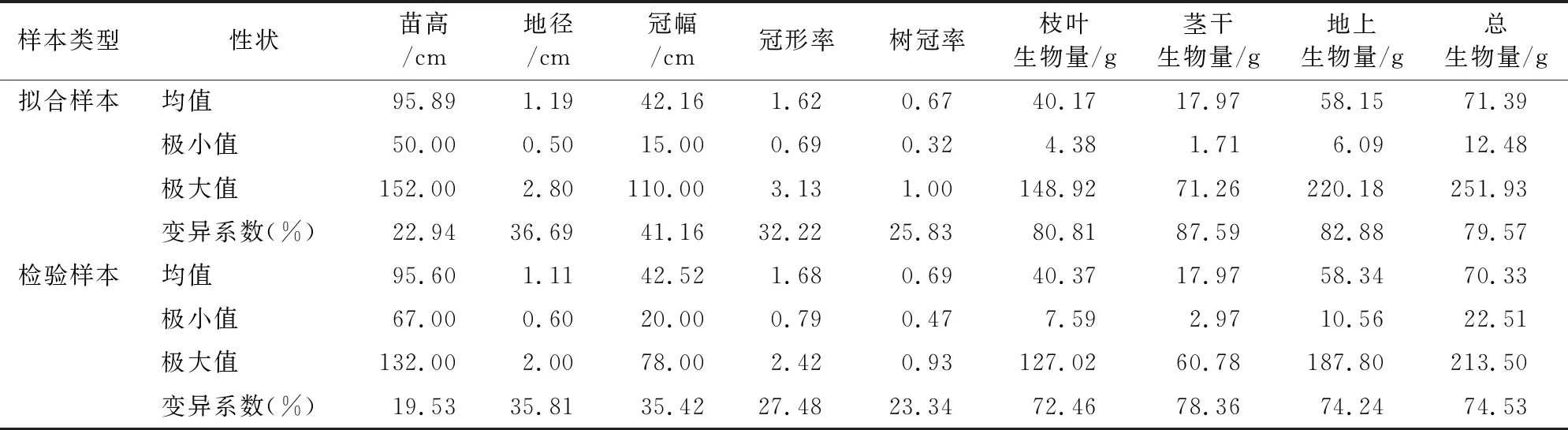
表1 样本基本情况
树冠结构特征及生物量按以下公式计算
冠长(CL)=树高-枝下高[21-22]
(1)
冠幅(CW)=(东西冠幅+南北冠幅)/2[21-22]
(2)
冠形率(CSR)=冠长/冠幅[21-22]
(3)
树冠率(CR)=冠长/树高[21-22]
(4)
地上生物量=枝叶生物量+茎干生物量
(5)
总生物量=地上生物量+根系生物量
(6)
2.2 生物量数学模型的拟合与优选
地径、树高、冠幅均匀分布,按照典型抽样的方法抽取,选择80%(103棵)红豆杉样本数据作为建模数据。D、H,D2,DH,D2H是生物量模型常用的变量类型[3-6],为此采用4种变量类型生物量模型(表2),逐步回归拟合模型[1,23],根据模型判定系数R2以及SSE大小,选出最优模型。

表2 生物量模型
2.3 模型检验
采用独立样本检验评价模型预测水平和精度,即以剩余的20%(25棵)红豆杉样本数据作为检验数据,计算出检验数据的生物量预测值后[1,23],对预测值与实测值进行配对样本t检验[1,23];计算平均偏差(ME)、平均绝对偏差(MAE)、平均相对偏差(MPE)、平均相对偏差绝对值(MAPE)等系列偏差指标,估算预测模型精度(P)。评价模型预测能力[1,24-27];偏差检验与模型预测精度估算按参考文献[24-26]的方法。
2.4 树冠结构调控技术与验证
在逐步回归拟合最优生物量模型过程中,确定率先进入模型的树冠结构特征为主导因子;根据主导因子系数的正负,确定调控方向,明确树冠结构调控技术(调控重点与方向)。
采用独立样本验证树冠结构调控技术,即计算出独立样本的主导因子均值,以是否符合调控方向划分为树冠调控与对照2个类型,采用t检验法验证调控技术效果与可靠性。
2.5 数据处理
采用Excel 2003软件进行数据预处理与统计;采用SPSS 21.0软件中逐步回归方法拟合数学模型,配对样本t检验方法检验预测值、实测值间差异。
3 结果与分析
3.1 云南红豆杉单木生物量模型的拟合与优选
3.1.1 不同变量类型云南红豆杉单木生物量最优模型拟合效果与比较 系列变量类型的红豆杉单木生物量最优模型结果显示(表3),变量类型间(D2H、DH、D2、常规类型(D、H))的枝叶生物量最优模型R2为0.812~0.862、SSE为19 567.537~14 403.703,茎干生物量最优模型的R2为0.818~0.872、SSE在3 145.004~4 460.343,地上生物量最优模型R2为0.815~0.866、SSE为30 900.542~42 613.806,总生物量最优模型的R2为0.831~0.875、SSE为39 924.914~53 458.577,变量类型的模型R2由大到小依次排序均为D2H、DH、D2、常规变量(D、H)类型,变量类型的模型的SSE由大到小依次排序均为常规变量(D、H)、D2、DH、D2H,D2H变量类型的系列模型拟合效果最佳,其次为DH变量,再次为D2变量,最后是常规变量(D、H),表明选择变量类型以提高生物量模型拟合效果是可行和必要的。模型4、8、12、16分别当选云南红豆杉生物量(枝叶、茎干、地上和总生物量)最优模型。
在逐步回归拟合系列生物量最优模型(模型4、8、12、16)的过程,变量D2H率先进入,表明云南红豆杉系列生物量(枝叶、茎干、地上和全株生物量)主要受到干形综合作用(D2H)影响,D2H显著促进系列生物量(系列最优模型的D2H系数分别为0.093、10.048、0.141、0.156)。
3.1.2 云南红豆杉系列单木生物量优化模型预测效果检验与比较 采取独立样本检验方法进行配对t检验、偏差检验和预测精度估算,比较常规变量(D、H)和复合变量(D2、DH、D2H)等类型系列最优模型(R2最大且模型参数均通过t检验)的预测效果(表3)。

表3 云南红豆杉单木生物量最优模型
配对t检验结果显示,无论枝叶、茎干、地上、全株生物量模型,常规变量(D、H)、复合变量(D2H)的最优模型(模型1、4)配对t检验的p值均大于0.05,意味着采用常规变量和复合变量的模型间的实测值、拟合值差异不显著,模型预测效果均较好。
预测精度结果显示,无论枝叶、茎干、地上、全株生物量模型,复合变量(D2H)较常规(D、H)变量模型明显提高预测精度,说明复合变量(D2H)提高了模型预测精度,表明选择变量类型的必要性与可行性。
偏差检验结果显示,2种变量类型的模型ME、MAE、MPE、MAPE表现均较好;无论枝叶、茎干、地上、全株生物量模型,复合变量(D2H)较常规变量模型明显降低了的MAPE、预测精度更高,且MAPE均小于20%,基本满足生产中应用的要求。
综上,选择复合变量(D2H)较常规变量(D、H)提高系列单木生物量模型的预测精度,且均以D2H变量模型表现最佳;WL=-41.382+0.093D2H+0.955CW+15.538CSR,WS=-19.700+10.048D2H+0.433CW+6.773CSR,WA=-66.082+0.141D2H+1.388CW+22.311CSR,WT=-66.082+0.141D2H+1.388CW+22.311CSR等系列生物量模型的MAPE均小于20%,基本满足生产应用中精度要求。
3.2 导入树冠结构特征前后单木生物量最优模型的比较
鉴于前文D2H变量类型的系列单木生物量模型表现最好。为此,以D2H变量类型生物量模型为例,比较导入树冠结构特征前后(导入前后)对模型拟合及预测效果,结果见表4、表5。
3.2.1 导入树冠结构特征前后单木生物量最优模型的拟合效果与比较 导入树冠结构特征后(导入后)系列单木生物量模型的拟合过程中,变量D2H率先进入、均通过参数t检验(P<0.01)(表5),变量D2H的系数始终大于0,表明干形综合性状(D2H)是影响作用系列生物量(枝叶、茎干、地上和总生物量)的主导因子,发挥着极显著性正向促进作用。由表4可见,导入后较导入前模型均明显提高调整判定系数R2,且导入后的系列模型的树冠结构特征(CW、CSR)参数均通过参数t检验(P<0.01),意味导入后明显提高模型的拟合效果;树冠结构特征(CW、CSR)显著影响生物量,表明生物量模型中导入树冠结构特征是必要与可行的。系列模型的逐步回归拟合过程中,CW、CSR依次进入,始终未出现CR变量,说明CR单独作用不显著,同时表明影响生物量的主导树冠结构特征为冠幅;导入后的系列生物量最优模型(模型4、8、12、16)中CW系数均大于0,意味着提高生物量的树冠结构调控技术(重点与方向)均为促进冠幅宽大,且冠形狭长有利系列生物量积累(表5中模型4、8、12、16变量CSR系数均>0)。
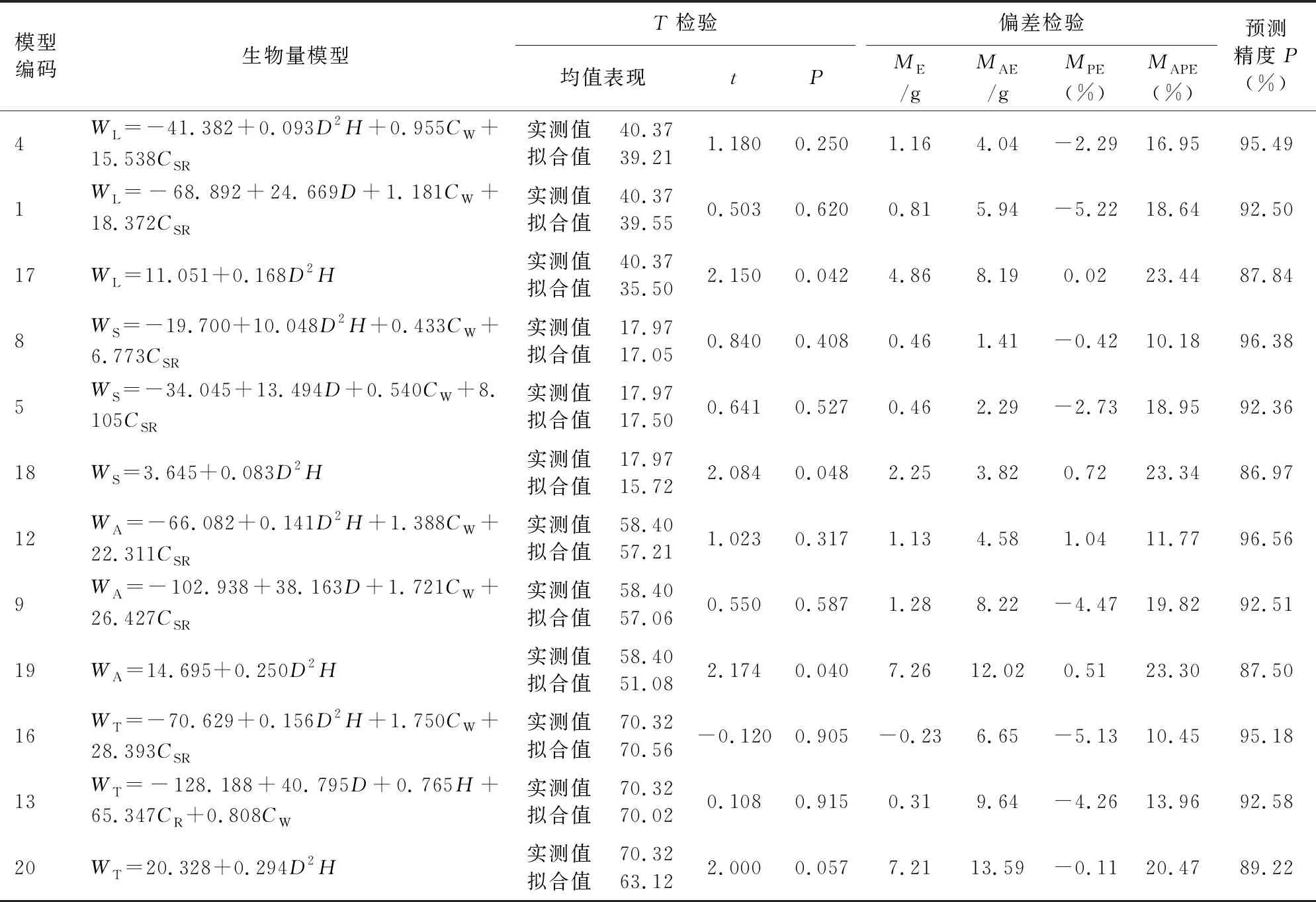
表4 单木云南红豆杉生物量模型检验结果
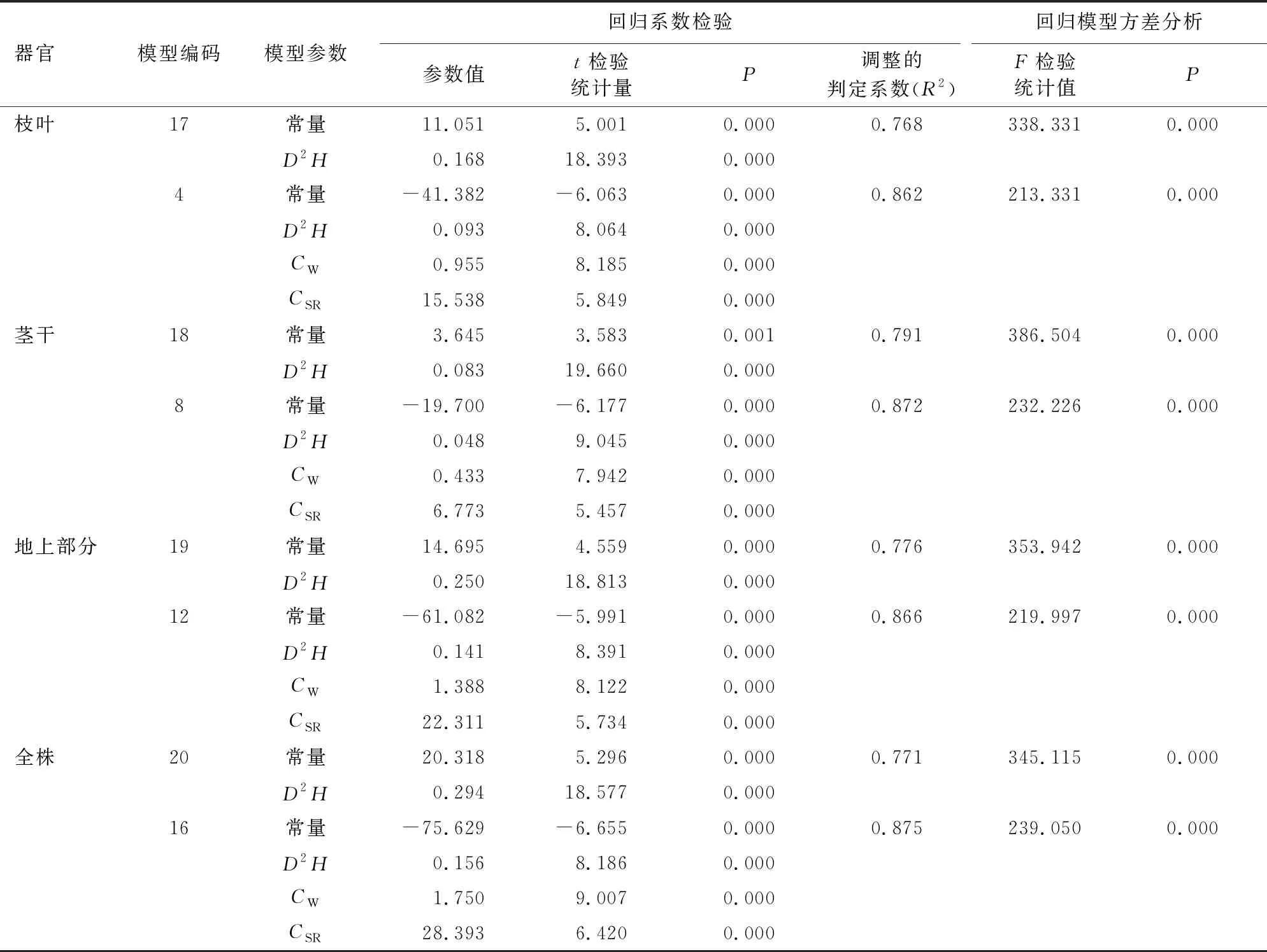
表5 单木枝叶生物量数学模型拟合结果
3.2.2 导入树冠结构特征前后单木生物量最优模型的预测效果与比较 由表4可见,无论枝叶、茎干和地上生物量,导入树冠结构特征后的模型(模型4、8、12)配对t检验的P值均大于0.05,模型实测值、拟合值差异不显著,预测效果均较好;导入前的模型(模型17、18、19)配对t检验的P值均小于0.05,模型实测值、拟合值差异显著,预测效果欠佳。导入前后全株生物量模型(模型20、16)配对t检验的P值分别为0.057、0.905,均大于0.05,意味着导入前后模型20、16的实测值、拟合值差异不显著、总体预测效果较好;但模型16的P=0.905,远大于模型20的0.057,导入后的整体预测效果更好。
由表4可以看出,无论枝叶、茎干、地上、全株生物量模型,导入后较导入前明显提高模型预测精度,表明在红豆杉生物量模型中导入树冠结构特征的必要与可行性。
无论枝叶、茎干、地上、全株生物量模型,导入后较导入前模型在ME、MAE、MPE、MAPE有着更好的表现,且导入后模型MAPE均小于20%,基本满足生产中应用的要求。
综上,导入树冠结构特征可明显提高模型的预测效果与精度,对于云南红豆杉单木生物量模型中是必要和可行的。
3.3 模型的应用与树冠结构调控技术验证
系列生物量最优模型(模型4、8、12、16)中的CW、CSR的系数均>0,CW、CSR显著促进枝叶生物量积累,冠幅宽大、冠形狭长是枝叶生物量的理想树冠结构;逐步回归拟合系列生物量优化模型过程中,率先进入的树冠结构因子是CW,表明CW是影响系列生物量的主导树冠结构因子,促进系列生物量的树冠结构调控技术是促进冠幅宽大。
经计算独立样本平均冠幅为42.52 cm,为此按冠幅大于42.52 cm的13个样本归类为树冠调控处理,将冠幅小于42.52 cm的12个样本归类为对照处理,分析系列生物量差异性结果。由表6可见,树冠调控处理的枝叶、茎干、地上和全株生物量显著大于对照处理,树冠结构调控技术显著促进云南红豆杉枝叶、茎干、地上和全株生物量,说明树冠结构调控技术的可行性和有效性。

表6 云南红豆杉树冠结构调控技术验证
4 结论与讨论
自变量类型显著影响模型拟合与预测效果,选择自变量类型以优化云南红豆杉单木生物量模型是必要和可行的。导入树冠结构特征因子明显提高了单木生物量模型的拟合效果与预测精度,是必要的。树冠结构显著影响云南红豆杉单木生物量,促进系列生物量的树冠结构调控重点与方向是促进冠幅宽大。系列最优单木生物量模型的决定系数均不小于0.862,预测精度均不小于95.18%,MAPE均不大于16.95%,可在生产中应用。
选择变量类型可提高云南红豆杉单木生物量模型拟合与预测效果,与前人研究结论一致[3-6];采用D2H变量类型的系列云南红豆杉单木生物量模型拟合效果最佳,与前人结论是一致的[3-5]。云南红豆杉系列单木生物量(枝叶、茎干、地上和全株生物量)主要受到干形综合作用(D2H)影响,提高原料林生物量(产量)首先是提高D2H指标,建议在云南红豆杉林培育过程,首先采用良种壮苗、幼林抚育以促进D2H指标。
仅从变量类型层面优化云南红豆杉单木生物量模型是不够的,导入树冠结构特征变量是必要的,亦验证了含有树冠结构变量的单木生物量预测精度表现好的研究结论[28-29]。与前人采用逐步回归的方法优化预测模型[3-5,20,30-31]过程,模型的拟合精度随自变量增加而不断提升的趋势[29]结论相互验证。亦有研究结论认为冠长、冠幅等树冠结构因子自变量与马尾松(Pinusmassoniana)树冠、树枝、叶花果等生物量相关关系不明显[32];造成这种结论差异原因,与树种、培育模式与年龄不同有关,验证了树种间生物量模型自变量选取上明显不同[28]的结论。
树冠结构显著影响云南红豆杉原料林单木生物量,原料林中树冠既是枝叶生产器官,又是光合作用的同化器官,其结构改变了利用地上空间能力、影响同化能力与生产力所致;与树冠结构影响同化能力、地上空间利用能力[7-8]和林木生产力[7-8,33]的研究结论相互验证。云南红豆杉原料林理想树冠结构:首先是冠幅宽大、其次为狭长的冠形;促进原料林生物量(产量)的树冠结构调控重点与方向是促进冠幅宽大。建议在原料林培育模式中,宜选用冠幅宽大的品种、个体,调适密度以促进冠幅生长。
猜你喜欢
天中学刊(2022年4期)2022-11-08
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
大连民族大学学报(2020年2期)2020-06-16
东方企业家(2020年5期)2020-05-29
山西文学(2019年8期)2019-11-01
文学港(2019年5期)2019-05-24
西江月(2018年5期)2018-06-08
青年文学家(2017年28期)2017-11-28
家庭用药(2017年8期)2017-08-22
高中生学习·高三版(2016年4期)2016-11-19
