
基于无限深度神经网络的非平衡大数据集群匿名化调度算法
2022-10-06 04:13张婷
计算技术与自动化 2022年3期
张 婷
(岳阳职业技术学院,湖南 岳阳 414000)
随着科学技术的不断革新及信息化水平的不断增强,21世纪全球步入大数据时代,各领域每日信息量呈数以万亿的规模不断增长,部分海量数据呈现出不平衡特性,表现为各类别数据样本数量存在巨大差别,即某类别数据数量远低于其他类别,此类不平衡大数据在实际生活中较为普遍,在诸多领域均有应用,如疾病诊断、邮件检测、信用卡欺诈识别等。非平衡大数据具有难以捕捉数据分布特征等特性,采用传统方法对非平衡大数据集群信息进行分析,其效果并不理想,如何识别非平衡数据特征,进行正确分析是当下研究的重要课题。利用深度神经网络的学习能力,对非平衡大数据的高级特征进行提取,对于实现非平衡大数据集群信息的正确分析具有重要意义。深度学习的目标是基于大规模的训练数据创建最佳分类面,达到准确学习数据特征的目的,实现数据信息的准确分析。
隐私是个人或企业的私密性信息,无论对个人或是企业都至关重要,隐私泄露将严重影响人们的正常生活及企业的持续发展,因此,对于非平衡大数据集群而言,采取有效措施保护非平衡大数据,防止信息泄露是需重点关注的问题。通过对原始数据信息进行匿名化处理,将信息中的敏感信息掩盖,使攻击者无法精准识别隐私内容是实现非平衡大数据保护的有效手段。由于非平衡大数据集群中各节点服务器性能存在差异性,资源大小也千差万别,根据资源数量协调各节点的资源调度性能,确保非平衡大数据集群的负载均衡,是实现集群高效调度的重要途径。
李叶飞等针对Hadoop大数据系统中任务执行效率低的问题,设计了可根据累计工作量能随意在高、低权重队列间转换的任务调度器,实现系统数据的协调调度,使系统的任务执行效率有所提升,由于该方法未考虑数据不平衡对分类效果的影响,导致该方法的错分类率较高;张译天等基于大数据流式计算框架Heron下任务间通信开销不同的问题,提出构建流分类模型,依据数据流大小实现数据分类,并将相关的高频数据流视为一个调派任务,用节点内通信更替原节点间通信,实现任务的高效调度,最大化节省通信开销,但该方法容易遭受网络攻击,数据存在安全性问题。
基于非平衡大数据存在的分类及数据安全问题,本文提出基于无限深度神经网络的非平衡大数据集群匿名化调度算法,以提升非平衡大数据集群数据调度的高效性、准确性、安全性。
1 非平衡大数据集群匿名化调度算法
1.1 非平衡大数据集群匿名化调度结构设计
非平衡大数据集群匿名化调度结构如图1所示。
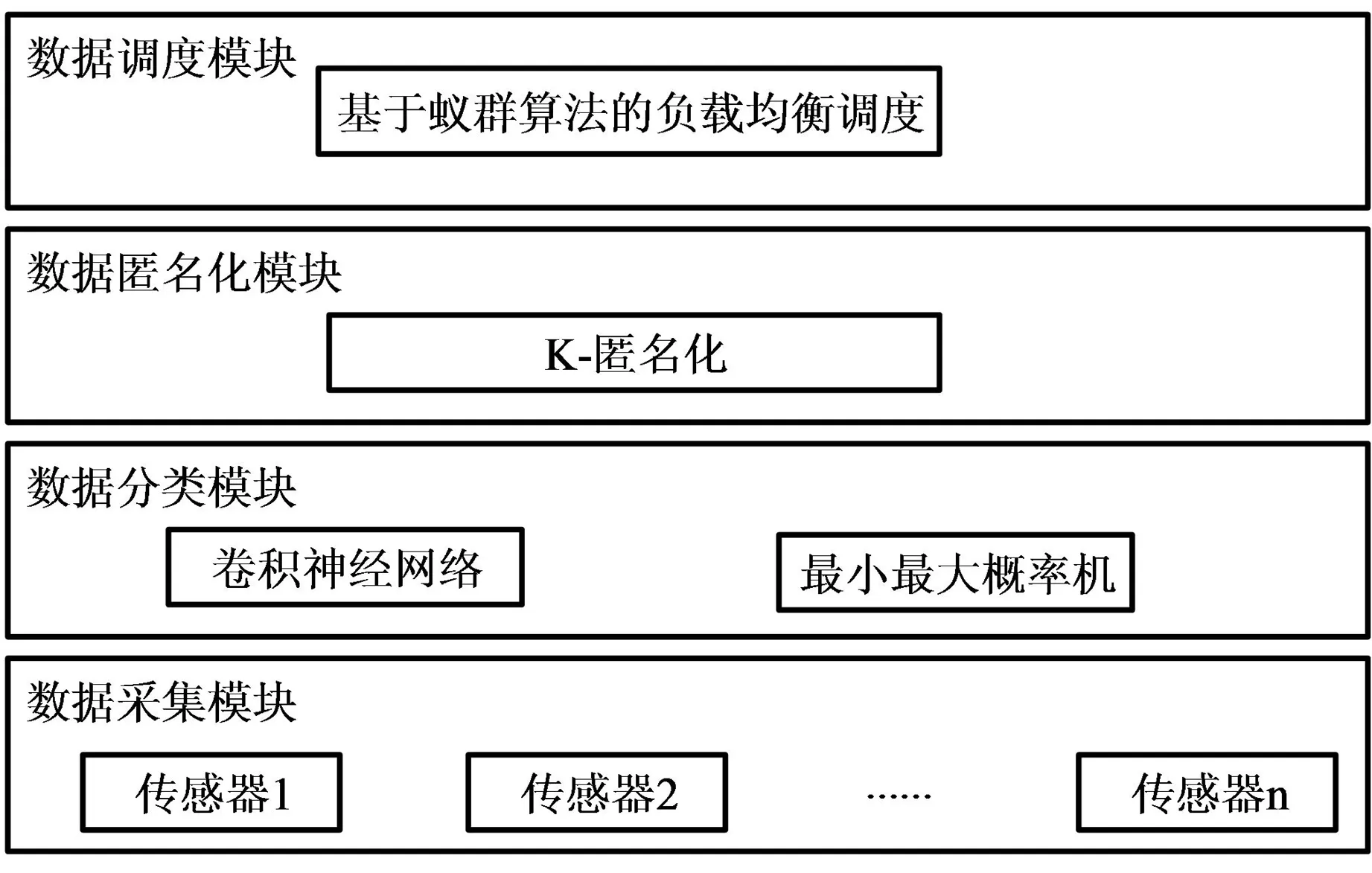
图1 非平衡大数据集群匿名化调度结构
(1)数据采集模块。利用传感器采集各节点服务器的非平衡大数据,构建非平衡大数据集群。
(2)数据分类模块。利用最小最大概率机可最大化降低极大错分类概率的特性,将之与卷积神经网络(CNN)相结合,通过卷积神经网络提取非平衡大数据的特征,以端对端形式对非平衡数据进行训练,构建出强大的分类器,实现非平衡数据分类。
(3)数据匿名化处理模块。通过K-匿名化方法实现非平衡大数据匿名化处理。
(4)数据调度模块。采用基于蚁群算法的非平衡大数据集群均衡调度方法实现集群数据的调度。
1.2 基于深度最小最大概率机的非平衡数据集群分类
由于卷积神经网络容易遭受小干扰攻击,本文的数据分类模块通过引入最小最大概率机改善其抗攻击性,以适应非平衡大数据集群的所属环境。最小最大概率机(Minmax Probability Machine,MPM)可在极恶劣条件下降低极大错分类概率,使其概率为极小值,在卷积神经网络的共同作用下,以端对端形式对非平衡数据进行训练,构建出强大的分类器,实现非平衡数据集群分类,即为深度最小最大概率机(Deep Minimax Probability Machine,DeepMPM)。DeepMPM的优势是可充分利用CNN的特征提取能力,经多层卷积、池化后,与多层全连接相连,将其传输至MPM,以MPM作为强大的分类器替换softmax,DeepMPM模型结构如图2所示。
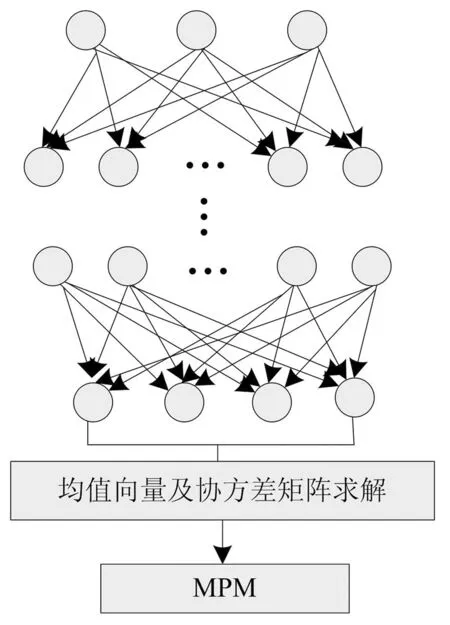
图2 DeepMPM模型结构
、为原始非平衡数据,MPM是基于原始数据求解其均值及协方差矩阵,实现非平衡数据的优化,而DeepMPM方法中,则是先利用CNN对非平衡数据的高级特征进行提取,在提取特征基础上再通过MPM实现分类。对于神经网络,其非线性映射可表示为(),其中该网络参数为。、为原始非平衡数据的所属类别,通过神经网络提取的非平衡数据的高级特征表示为(,)、(,),通过下式可实现原始非平衡数据优化的参数估计:
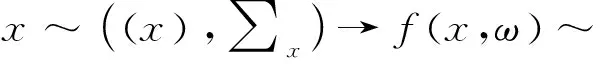
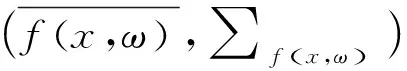
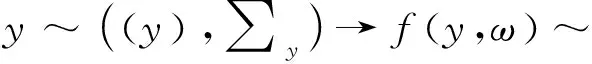
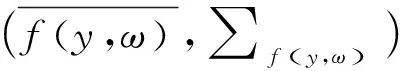
(1)
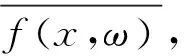
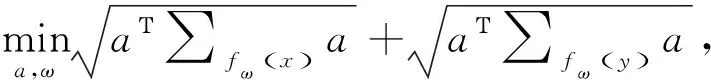
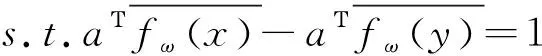
(2)
式中,为分类超平面参数,为分类超平面。为达到DeepMPM的端对端训练目标,利用拉格朗日乘子法转换式(2),目标函数可描述为:
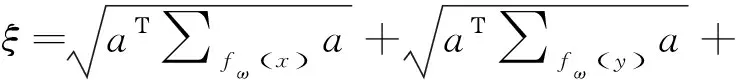
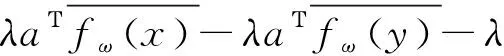
(3)
式(3)利用梯度回传法并以端对端形式对、寻优,表示拉格朗日系数,的梯度可利用链式法进行求解,可描述为:
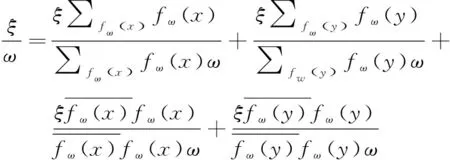
(4)
在深度神经网络的反向传播过程中,通过梯度下降法求解最佳、,获得的梯度。
设、为获得的最佳参数,由此分类面的求解公式可描述为:
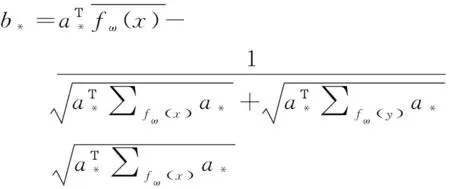
(5)
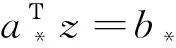
1.3 基于K-匿名化的非平衡大数据匿名化方法
数据匿名化模块采用基于K-匿名化的非平衡大数据匿名化方法,实现非平衡大数据匿名化处理。由于采用深度最小最大概率机法对非平衡大数据进行分类处理,各类别通常由个属性组构成,各等价类内数据相似度需呈现最大化特点,类间数据则需保持其差异性的最大化,再利用等价类的类质心更新全部属性组,以达到非平衡大数据的匿名化处理。
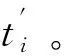
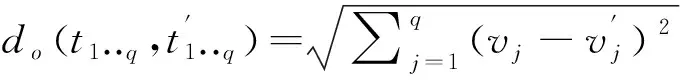
(6)
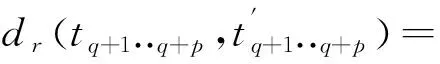
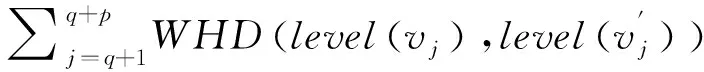
(7)
式中:在第属性的泛化层中层的标号表示为(),表示第属性的泛化层映射。对于混合型数据,其距离则通过对、加权平均方式进行求解,可用下式描述:
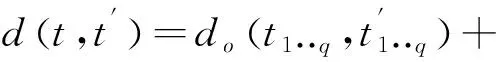
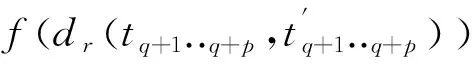
(8)
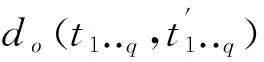
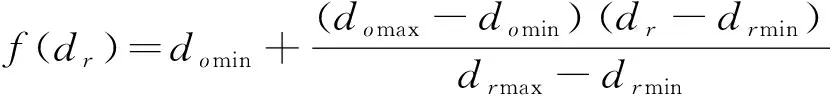
(9)
式中:的取值范围可通过()进行映射,转换到区间[min,max],从而防止将埋没。
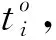
={,,…,}=
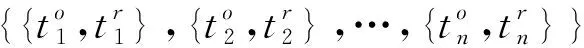
(10)
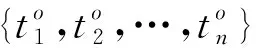
()={,}
(11)
1.4 基于蚁群算法的非平衡大数据集群负载均衡调度算法
蚁群算法可根据非平衡大数据集群节点数及各节点的任务处理能力,对信息素矩阵进行动态更新,筛选出最佳任务调派方式,实现非平衡大数据集群的动态调度,因此,数据调度模块通过基于蚁群算法的负载均衡调度方法实现非平衡数据集群调度,调度步骤如下:
第一步:算法的初始设置。
针对非平衡大数据集群的全部节点,获得其参数的初始值,并对各节点当下所执行任务的处理速度进行求解,求解公式表示为:
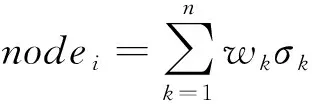
(12)
式中:对于非平衡大数据集群中节点服务器,第个参数的权重表示为,该参数值表示为,节点全部参数的加权总和即为该节点的任务调派性能。
(1)待执行任务均存储于负载均衡器的缓冲池中,从中调取需执行的任务,并确定任务长度。
(2)在步骤(1)(2)的基础上对各任务调派方式下的执行时间进行计算。
(3)对蚁群信息素矩阵进行初始设置,将其设置为1。
(4)任务调派概率矩阵初始设置,令初始值设为1。
第二步:通过不断迭代获得最优结果。
(1)产生蚂蚁,数量为,各蚂蚁需对全部任务进行调派,依据任务调派概率矩阵,对执行任务节点进行求解,通过path矩阵实现调派方式的控制。该矩阵描述为:
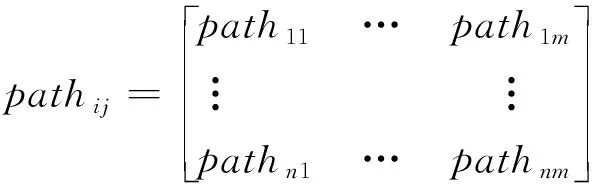
(13)
式中:由节点调派的任务表示为,该矩阵取值为0或1,当其值为0时,表示任务不由节点调派,当其值为1时,则表示节点调派任务。
(2)各蚂蚁执行完任务调派任务后,获取其任务调派时间,搜索任务执行时间最小的调派方式,以之作为局部最佳搜索结果。
(3)调整信息素矩阵。该矩阵用下式描述:
(+1)=·()+Δ()
(14)
式中:()表示时间点节点调派任务的信息素浓度,迭代过程中信息素逐渐减弱,减弱系数为。迭代次后信息素浓度的增长量表示为Δ()。
(4)调整任务调派概率矩阵。该矩阵用下式表达:
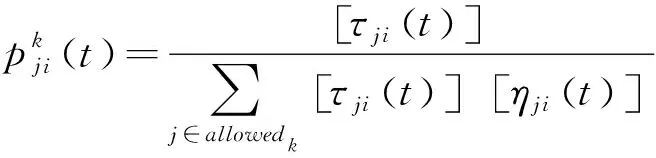
(15)
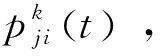
(5)再次调取任务继续迭代。
2 实验分析
以某企业的非平衡大数据集群的大数据信息为研究对象,创建数据集,数据集中包含6类信息共6000个,其中选取5000个样本作为训练集,1000个样本作为测试集。首先将数据集中6类数据转换成二分类问题,即以一对多方式将各类数据均分成2类,从而转换为6个二分类的处理。
利用训练集数据分别对本文的DeepMPM及CNN模型进行训练,分析两模型的正(少数样本)、负类(多数样本)的分类精度,实验结果如表1所示。
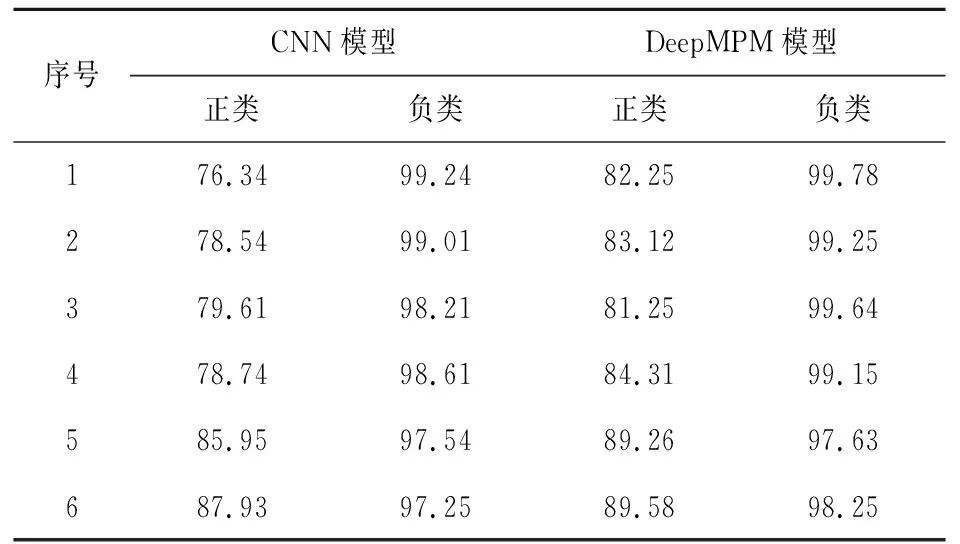
表1 CNN、DeepMPM模型的正、负类分类准确度对比
分析表1可知,采用DeepMPM模型对非平衡大数据集的测试样本数据进行分类,正、负类分类准确度均高于CNN模型,这是因为本算法通过卷积神经网络的端对端方式训练非平衡大数据,利用CNN的特征提取能力并以MPM作为强大分类器实现非平衡数据分类,使得分类准确度获得提升,分类效果显著。
在非平衡大数据实现准确分类的基础上,通过与文献[5]的基于累计工作量的数据调度算法、文献[6]的基于Heron的流分类任务调度算法对比,分析不同元组数量下的信息损失及信息泄密风险情况,验证本文算法的匿名化处理性能,实验结果分别如图3、图4所示。
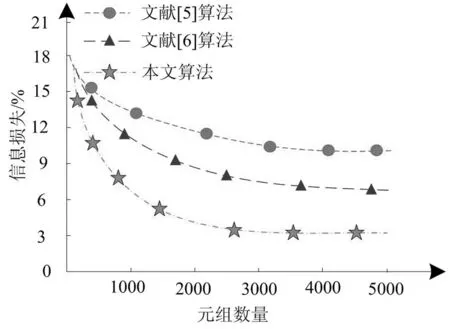
图3 各算法的信息损失对比
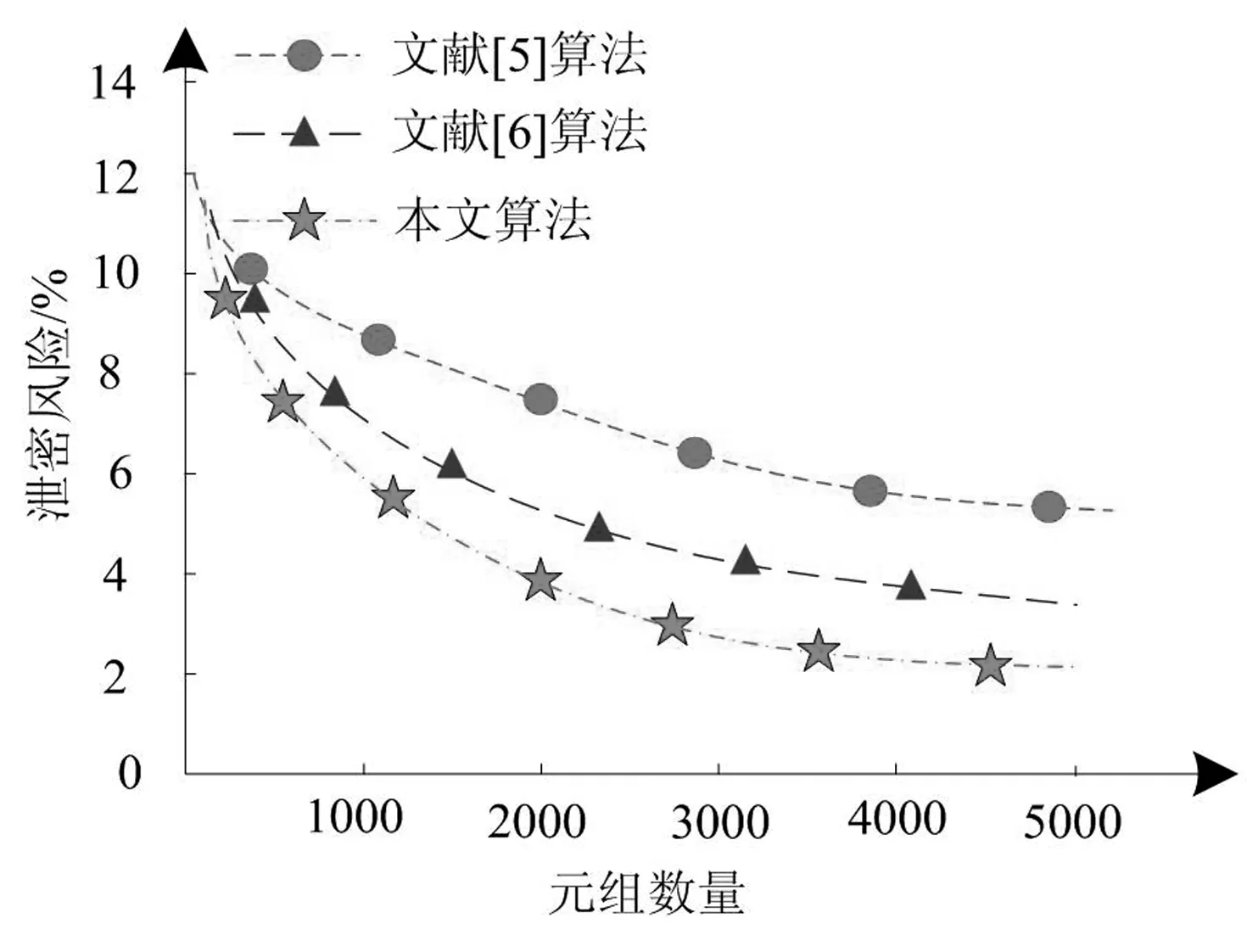
图4 各算法的泄密风险分析
分析图3可知,随着元组数量的不断增长,三种算法的信息损失呈逐渐下降趋势,降低幅度各不相同,文献[5]算法降幅最小、其次为文献[6]算法,本文算法的下降趋势最大,当元组数量达到5000时,信息损失只有6%左右。实验结果表明,采用本文算法进行非平衡大数据的匿名化处理可有效降低非平衡大数据的信息损失率。取得优势结果的原因在于本文算法应用K-匿名化算法匿名化处理分类后的数据信息,可使各等价类内数据具有最高相似度,类间数据呈现最大差异性,提高了数据匿名化效果。
分析图4,随着元组数量的不断增多,三种算法的泄密风险均呈递减趋势变化,文献[5]算法的泄密性较高,其次为文献[6]算法,本文算法泄密性小,当元组数量达到5000时,泄密风险只有2%左右,原因在于元组数量的增多使得等价类内相似数据大幅增长,提取原始大数据高级特征,以最小和最大概率机作为分类器,实现非平衡大数据的分类,大大降低了非平衡数据的攻击概率,确保数据的安全性。
分别与文献[5]算法、文献[6]算法对比,分析三种算法对不同任务量的非平衡大数据进行调度时,非平衡大数据集群的负载均衡,实验结果如图5所示。
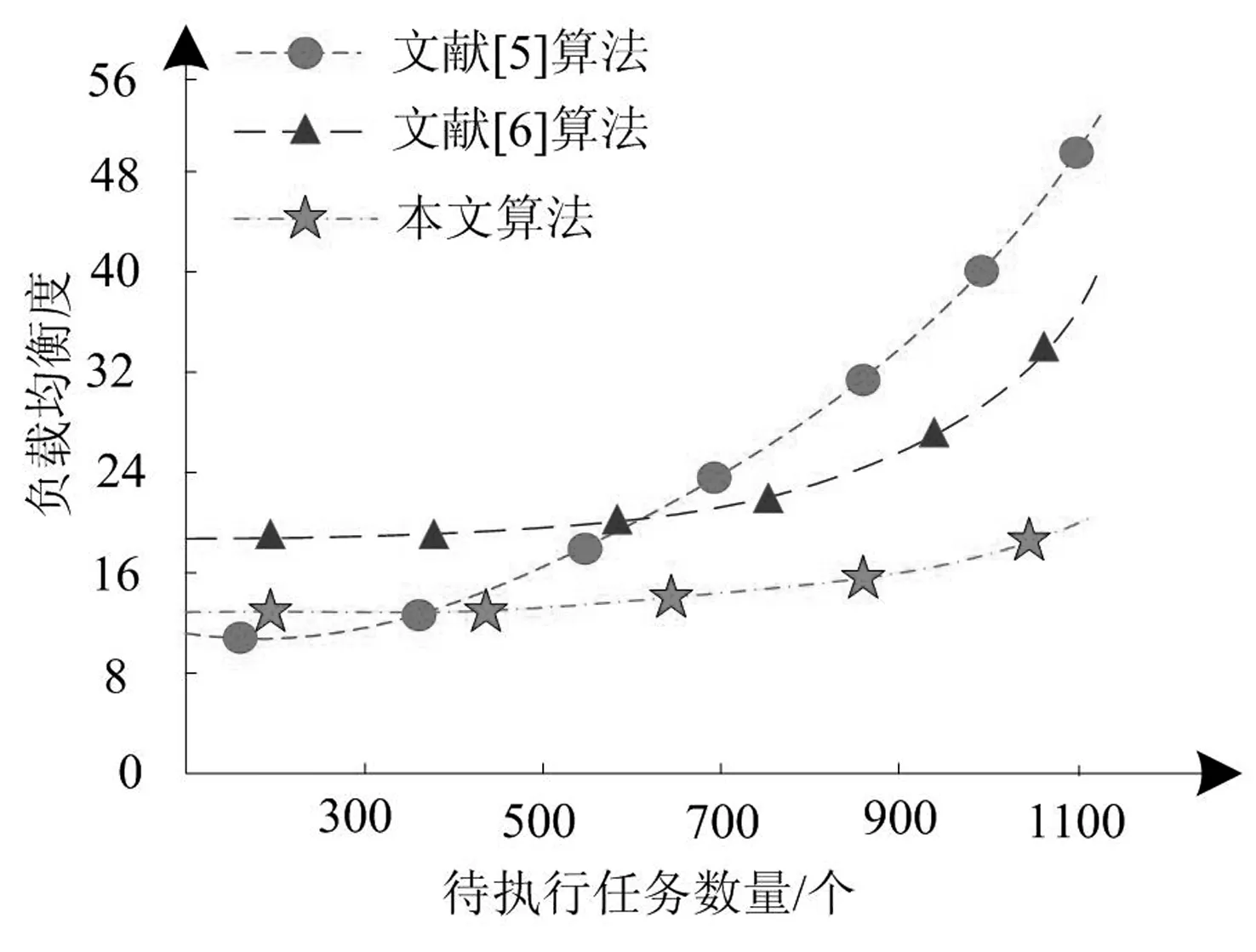
图5 三种算法的负载均衡分析
分析图5,随着待执行任务数量的不断增大,三种算法调度后非平衡大数据集群的负载均衡度指标均呈不断上升趋势,但上升幅度大不相同,文献[5]算法的负载均衡指标增长幅度最大,当处理任务达到1100个时,该指标达到50以上;文献[6]算法明显优于文献[5]算法,当处理任务数低于700个时具有较好的调度性能,由于该算法更加侧重于对优势节点的调度,未实现空闲节点的有效利用,当任务数大于700个时,反映出该算法的调度劣势;本文算法的调度性能明显优于文献算法,任务数增长至1100个,该算法调度后非平衡大数据集群的负载均衡度指标仍处于较低水平。实验结果表明,本文算法能实现优势节点与空闲节点间任务的均衡分配,提升了集群任务的调度能力,集群调度效果突出。这是因为本设计的数据调度模块中采用了基于蚁群算法的负载均衡调度方法,进行非平衡大数据集群各节点、任务的实时调度,提高了调度能力。
3 结 论
以非平衡大数据集为研究对象,验证提出的基于无限深度神经网络的非平衡大数据集群匿名化调度算法的有效性。通过对比分析CNN、DeepMPM模型的正、负类分类准确度,验证本算法的分类效果;通过对比分析本算法与文献[5]算法、文献[6]算法的信息损失、泄密风险指标,验证本算法的匿名化效果;通过对比分析负载均衡度指标,验证本算法的非平衡大数据集群的调度性能。实验结果表明:利用CNN的特征提取能力并以MPM作为强大分类器,提升非平衡大数据的分类准确度;本算法可降低非平衡大数据的信息损失率、泄密风险,并可充分调度优势节点与空闲节点实现任务的均衡分配,提升了集群任务的调度能力,集群调度效果突出。
猜你喜欢
农业工程学报(2022年11期)2022-08-22
南方农业·下旬(2022年4期)2022-05-24
中国教育信息化·高教职教(2022年4期)2022-05-13
计算技术与自动化(2022年1期)2022-04-15
电子乐园·上旬刊(2022年5期)2022-04-09
煤气与热力(2022年2期)2022-03-09
科学与财富(2021年35期)2021-05-10
软件(2017年6期)2017-09-23
知识就是力量(2017年2期)2017-01-21
