
一种负载预测感知的虚拟机合并与迁移策略
2022-10-10 09:25刘秋菊
计算机应用与软件 2022年9期
陈 平 李 攀 刘秋菊
1(济源职业技术学院 河南 济源 459000) 2(郑州工程技术学院 河南 郑州 450044)
0 引 言
云数据中心利用虚拟化技术可以在物理服务器上部署多个不同性能的虚拟机,以提高整体的资源利用率[1]。虚拟化的一个主要优势是在数据中心内可以进行动态的虚拟机合并来降低能耗,通过将虚拟机合并到更少数量的物理主机上,并将闲置主机转换为睡眠模式以提升能效。动态的虚拟机合并实现了运行时虚拟机在不同主机间的在线迁移[2],尤其在主机处于较低负载或超载状态下时,迁移将具有诸多好处。因此,通过迁移操作会使得数据中心内的资源管理更加灵活。然而,虚拟机在线迁移对于运行在虚拟机上的应用任务的性能具有负面影响[3]。由于在云服务提供者与其用户间提供相应的服务质量是至关重要的,所以动态虚拟机合并应该着重考虑优化虚拟机迁移次数。此时的服务质量需求通常以服务等级协议SLA来描述,根据吞吐量或服务的响应时间上的性能表现来定义。
动态虚拟机合并可以形式化为装箱模型,是NP问题。由于装箱问题仅能在给定物品下最小化箱子数量,直接应用于虚拟机合并中拥有一定局限性[4]。很多算法也以装箱思路求解过虚拟机合并问题。然而,这会产生过多的非必要虚拟机迁移,增加SLA违例风险。比较已有工作最小化主机利用数量,本文将设计一种启发式算法同步最小化虚拟机迁移次数和SLA违例。本文算法进行动态虚拟机合并主要由两个阶段组成:1) 尝试将负载最低主机上的所有虚拟机迁移至负载最大主机上;2) 从当前超载或预测在近期会变为超载的主机上迁移出部分虚拟机以防止可能的SLA违例。同时,本文算法可以根据当前和未来的资源请求将迁移虚拟机分配至合适主机上。为了预测负载,本文设计使用了线性回归LR和K最近邻回归KNNR模型预测方法,对未来资源利用率进行预测。为了训练和测试预测模型,本文通过运行云环境中的多种现实负载生成历史数据集,并通过实验验证了本文算法的有效性。
1 相关工作
相关研究中,文献[5]提出了动态的服务迁移机制,在给定负载状态和降低SLA违例的条件下可以降低物理能力的使用量,算法利用了装箱启发式方法和时序预测技术最小化主机利用量,但并没有考虑新部署中的虚拟机迁移次数。文献[6]利用蚁群系统寻找最优解,同步考虑了休眠主机量和迁移次数。文献[7]为了避免性能下降,设置门限值防止主机CPU达到100%占用率,将CPU占用率限定在门限值之内。然而,静态的门限值设置无法处理动态的云负载环境,此时主机上运行的负载类型是多样的。因此,门限值应该针对不同的负载类型作出相应改变,并允许有效的任务合并。文献[8]根据历史数据的静态分析设置了自适应的上下限值,而文献[9]则根据数据中心内不同的应用类型,以最大化资源利用率和负载均衡为目标,提出了新的虚拟机部署算法。
虚拟机合并问题可以形式化为装箱问题,装箱问题即是将若干物品装入有限数量的箱子内,并最小化箱子数量。每台虚拟机可视为一个物品,每台主机即为一个箱子。由于装箱问题的NP难属性,有效求解方法为启发式方法。如:首次适应算法FF将物品放入可容纳该物品的第一个箱子中;最佳适应算法BF将物品放入空间最合适的箱子中。此外,FF和BF算法可进一步改进为降序首次适应算法FFD和降序最佳适应算法BFD。然而,经典的装箱方法并不能直接应用于虚拟机合并问题。原因在于:1) 虚拟机和主机拥有多个维度资源,如CPU、内存和网络带宽。若考虑CPU和内存资源的约束,虚拟机合并问题就是典型的二维装箱问题。2) 虚拟机合并问题可修正为可变箱子(主机)大小的装箱问题,不同于经典的等同能力箱子的装箱问题。3) 经典装箱方法仅最小化箱子数量,即单目标优化。而本文考虑的目标包括虚拟机迁移次数和SLA违例问题。文献[10]设计了BFD的改进算法,可以节省部分能耗。文献[11]利用FFD的改进算法在功耗和迁移代价间取得均衡。文献[12]利用改进的FF和BF算法在未考虑性能下降的情况下最小化主机利用量。然而,以上算法多是单一目标的优化,没有在能效和服务性能上作出综合的考量。
本文提出一种融合了负载预测机制的虚拟机合并算法UP-VMC,与已有研究相比具有以下几点优势:1) 算法可以得到能效和SLA违例间的最优均衡解,实现动态的虚拟机合并;2) 为了降低虚拟机迁移量,算法可以根据当前和未来的资源需求分配迁移虚拟机至目标主机;3) 为了降低SLA违例,算法选择从当前超载主机或最近未来会变为超载的主机上迁移部分虚拟机,避免无用虚拟机迁移;4) 算法利用线性回归与K最近邻回归方法对负载进行预测,可以基于历史数据预测主机和虚拟机的CPU占用率,实现了前瞻性的虚拟机合并。
2 系统模型
假设一个云数据中心由m台异构物理主机构成,表示为P={p1,p2,…,pm}。每台主机拥有D类资源,如CPU、内存、网络带宽和存储能力。多个虚拟机可以通过虚拟机监视器部署在一台主机上。初始情况下,虚拟机通过传统装箱方法降序最佳适应算法进行部署。在任意给定的时间,用户可发送虚拟机请求,表示为V={v1,v2,…,vn},需要部署至主机上。由于虚拟机和主机请求的资源占用随着时间发生变化,初始部署时,需要利用周期性的虚拟机合并算法对虚拟机部署进行优化。本文提出的UP-VMC算法即可根据负载变化对虚拟机部署作出优化。图1是虚拟机合并的系统模型,由两类代理构成:1) 在主机上全分布的本地代理(Local Agents,LAs);2) 在主节点上的全局代理(Global Agent,GA)。执行过程如下:

图1 系统模型
1) 每个LA周期性监测主机上所有虚拟机的当前资源利用率,然后利用回归预测模型预测虚拟机的未来资源利用率。本文引入线性回归和K最近邻回归进行预测。
2) GA收集本地代理信息,获得虚拟机的当前和未来资源利用率情况。
3) 利用UP-VMC算法,GA生成全局最优迁移计划,并将其发送虚拟机监视器执行虚拟机迁移。该指令决定了源主机上的哪些虚拟机需要迁移至对应目标主机。
4) 接收GA指令后,虚拟机监视器VMM执行实际虚拟机迁移。
每台主机p拥有d维资源能力向量,Cp={Cp,1,Cp,2,…,Cp,d},Cp,d表示主机p的第d维资源能力。每个维度对应一类物理资源,如CPU、内存、网络带宽和磁盘存储。根据现实负载的资源维度需求,设置|D|=2,考虑二维虚拟机合并问题,并将CPU和内存考虑为主要资源类型。主机p已使用的能力向量表示为Up={Up,1,Up,2,…,Up,d},其中,Up,d表示主机p的资源d的已使用能力。若三个虚拟机部署在同一台主机上,则该主机已使用的CPU能力为三个虚拟机的CPU占用之和。虚拟机v的总能力向量表示为Cv={Cv,1,Cv,2,…,Cv,d},其中,Cv,d表示虚拟机v在d维资源上的能力。Uv={Uv,1,Uv,2,…,Uv,d}表示虚拟机v已使用的资源能力。由于动态负载条件下虚拟机的资源利用会随时间发生变化,虚拟机部署需要通过UP-VMC算法进行周期性优化。表1给出相关符号说明。

表1 参数说明
3 算法的详细设计
UP-VMC算法的执行过程如算法1所示。UP-VMC算法通过两个阶段进行虚拟机合并优化。
算法1UP-VMC算法
1. setM1=NULL
2. forpso∈[Pover,Pover′] do
3. sortVMsonpsoandVmin ascending order ofUv,mem
4. forv∈Vmdo
5. if (pso∈Pover)‖(pso∈Pover′) then
6. forpde∈P-[Pover,Pover′] do
7. if (Upde+Uv≤T×Cpde) and (PUpde+PUv≤T×Cpde)
8.M1←M1∪{(pso,v,pde)}
9. updateUpsoandUpde
10. break
11. if (pso∈Pover)‖(pso∈Pover′) then
12. switch on the dormantPMp
13. else break
14. setM2=NULL
15. sortPactivein descending ofLoadp
16. fori=|Pactive| to 1 do
17.pso←Pactive[i]
18.Vm←sortVMsonpso,Vpin descending order ofLoadv
19. forv∈Vmdo
20.success←false
21. forpde∈Pactive-psodo
22. if (Upde+Uv≤T×Cpde) and (PUpde+PUv≤T×Cpde)
23.M2←M2∪{(pso,v,pde)
24. updateUpsoandUpde
25.success←true
26. break
27. ifsuccess=false then
28.M2←null
29. recoverUpsoandUpde
30. else switchpsoto the sleep mode
31.M←M1∪M2
32. returnM
第一阶段。UP-VMC算法该阶段的目标是从超载和预测超载主机迁移虚拟机以最小化SLA违例。若至少有一类资源(CPU或内存)超过总能力,则主机被视为超载主机集合Pover中的成员。若至少一个预测利用率高于可用资源能力,则该主机被视为超载主机集合Pover′中的成员。UP-VMC算法首先从Pover中迁移部分虚拟机,直到没有超载主机为止。然后,从Pover′中迁移虚拟机以确保在短期内不会出现SLA违例。
为了预测资源利用率,利用两种回归模型进行预测:线性回归模型LR和K最近邻回归模型KNNR。预测模型可以估算主机和虚拟机的CPU和内存的资源利用。UP-VMC算法在动态的负载条件下主要关注短期的负载预测。LR主机利用历史资源利用率数据并将其估算为线性函数,该函数给出了当前与未来资源利用率的关系,表示为:
PUpde=α+βUpde
(1)
式中:PUpde和Upde分别表示主机p的预测和当前已使用能力向量;α和β表示回归因子,分别用于描述Y轴截距和线性斜率。估算回归因子的常用方法是最小方差法,该方法估算最优的直线拟合为观察输出值与预测输出值间的距离最小化。因此,回归因子可通过以下公式进行估算:
(2)
α=y′-βx′
(3)
式中:x′代表x1,x2,…,xn的均值;y′代表y1,y2,…,yn的均值。
利用类似的方法,虚拟机资源利用也可以通过线性函数预测,表示为当前已使用的能力向量Uv和预测使用的能力向量PUv之间的线性关系式,为:
PUv=α+βUv
(4)
KNNR利用数据集的局部均值对资源利用做出预测。局部数据量定义为与新的样本最近的k个样本。最优k值(邻居数量)可以通过留一交叉验证法确定,取值范围为样本数以内。留一交叉验证法通过每个可能k值的平方冗余之和估算预测准确性;然后,选择冗余最小的最优k值作为K最近邻回归的k值。
UP-VMC从超载或预测超载主机迁移虚拟机时,将根据以下三种策略进行迁移虚拟机选择:最小迁移时间策略MMT、最大负载策略MaxL和最小负载策略MinL。
第二阶段。该阶段算法将尽可能消除最低载主机,降低活跃主机数量以节省能耗。算法的目标是迁移最低载主机上所有虚拟机至最高载主机并释放低载主机节省能耗。UP-VMC算法可确保部署迁移虚拟机后目标主机在短期内不会变为超载主机。选择目标主机时,算法将依次负载从高到低顺序选择,直到虚拟机完成迁移。若低载主机上存在至少一个虚拟机无法迁移,则所有均不迁移。是否能够实现虚拟机迁移,需要考虑不同维度资源的约束。定义主机p的负载为每个资源维度d的资源利用率Rp,d之和,表示为:
(5)
式中:Rp,d表示资源利用Up,d与资源能力Cp,d之比。Rp,d计算为:
Rp,d=Up,d/Cp,d
(6)
为了决定低载主机上迁移的虚拟机,算法按虚拟机负载对其作降序排列,因此,第一个选择迁移的虚拟机即为负载最高的虚拟机。虚拟机v的负载定义为:
(7)
式中:Rv,d表示虚拟机v在d维资源上的请求Uv,d与虚拟机的d维资源总能耗Cv,d之比。Rv,d计算如下:
Rv,d=Uv,d/Cv,d
(8)
为了寻找部署迁移虚拟机的目标主机,引入两种约束避免SLA违例和无用迁移。第一个约束:若主机当前拥有足够资源容纳迁移虚拟机,则允许虚拟机v迁移至目标主机pde。当主机利用率接近100%时,即会产生SLA违例风险。因此,需要设置阈值T限制虚拟机的资源请求量。因此,第一个能力约束为:
Upde+Uv≤T×Cpde
(9)
式中:Cpde表示目标主机pde的总能力向量;Upde表示pde的已使用能力向量;Uv表示虚拟机v已使用能力向量。
第二个约束确保在虚拟机迁移后目标主机不会变为短期超载主机,因此,此时UP-VMC算法同时考虑了主机pde和虚拟机v的未来资源能力需求。第二个预测能力约束为:
PUpde+PUv≤T×Cpde
(10)
式中:PUpde表示主机pde的预测使用能力向量;PUv表示虚拟机v的预测使用能力向量。
UP-VMC算法的目标是通过实现前文所述两个步骤得到一个最终的虚拟机迁移计划。在第一阶段中,即步骤2-步骤13,步骤2遍历超载主机集合Pover和预测超载主机集合Pover′,其目标是从这两个集合中迁移出虚拟机以避免更多的SLA违例。为了实现这一目标,算法首先选择迁移时间最小的虚拟机进行迁移。由于主机间的网络带宽为1 Gbit/s,根据虚拟机请求的内存利用即可计算出迁移时间。因此,算法以请求内存利用的降序对所有虚拟机进行排序,然后开始虚拟机迁移,即步骤3-步骤4。若源主机仍为超载或预测超载集合中的成员,则再次利用虚拟机迁移选择策略从该主机选择迁移虚拟机,即步骤5,重复该过程直到该主机在当前和未来均不是超载主机为止。然后,算法根据提出的两个约束选择重分配虚拟机v的目标主机(步骤6-步骤7)。最后,新的虚拟机部署被添加为迁移计划M1中的成员,即步骤8。迁移计划设置为三元组(pso;v;pde),其中:pso为源主机;v为迁移虚拟机;pde为目标主机。若活跃主机没有足够资源分配虚拟机v,则开启一台休眠主机p,即步骤11-步骤13。
第二个阶段中,即步骤14-步骤30,算法根据负载的降序对活跃主机进行排序。UP-VMC从列表Pactive中的最后一个主机开始,将负载最低的主机考虑为源主机pso,即步骤16-步骤17。然后,算法尝试从主机pso上迁移所有虚拟机以释放pso。为了从pso上选择优先迁移的虚拟机,算法对pso上的所有虚拟机按其负载进行降序排列,即步骤18。为了找到分配迁移虚拟机的目标主机pde,UP-VMC算法从列表Pactive中第一个主机(负载最高主机)开始扫描,即步骤19。若无法部署,继续选择第二台主机尝试。算法选择的目标主机pde需要在当前和短期未来均拥有容纳迁移虚拟机的资源,即步骤20。最后,新的虚拟机部署添加为迁移计划M2中的成员,即步骤23。更新源主机和目标主机的能力以反映迁移后的改变,即步骤24。参数success用于检测从源主机上是否所有虚拟机均被迁移,若有至少一个虚拟机未迁移,则所有虚拟机均不作迁移。因此,若success为false,则算法需要移除迁移计划中的所有三元组并恢复源主机和目标主机的资源能力,即步骤27-步骤29。否则,所有虚拟机迁移后,源主机被转换为休眠模式,即步骤30。UP-VMC算法的输出是迁移计划M,包括两个阶段中的全部迁移三元组,即步骤31-步骤32。
4 实例分析
以一个实例说明UP-VMC算法的实现过程。现在三台异主机P={p1,p2,p3},五台虚拟机部署请求,V={v1,v2,v3,v4,v5}。主机的能力向量分别是为:Cp1={12,18},Cp2={6,8},Cp3={8,12},表明主机p1的CPU能力和内存分别为12 GHz和18 GB。虚拟机的能力向量分别为:Cv1={1,1},Cv2={1,4},Cv3={2,2},Cv4={2,2},Cv5={3,4}。Cv1={1,1}表明虚拟机1的CPU和内存消耗分别为1 GHz和1 GB。假设CPU阈值设置为T=0.8。
UP-VMC算法的第一次迭代中,虚拟机请求的资源占用为:Uv1={0.5,0.7},Uv2={0.5,2},Uv3={0.5,0.5},Uv4={0.5,0.5},Uv5={0.5,0.5}。Uv1={0.5,0.7}表明虚拟机v1请求1 GHz中的0.5 GHz的CPU能力和1 GB内存的0.7 GB。基于初始的虚拟机部署(图2(a)),主机的已使用能力向量为:Up1={1,2.7},Up2={0.5,0.5},Up3={1,1}。如:{0.5,0.7}为虚拟机v1请求的CPU和内存元组,{0.5,2}为虚拟机v2请求的能力。那么,主机p1容纳这两个虚拟机后,其占用则为{1,2.7},即请求向量之和。算法首先利用式(3)计算每个主机的负载为:
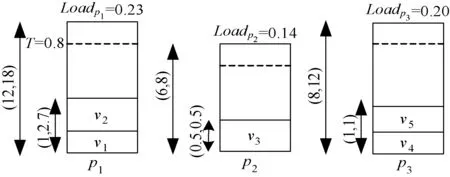
(a) 第一次迭代:v3从p2迁移至p1
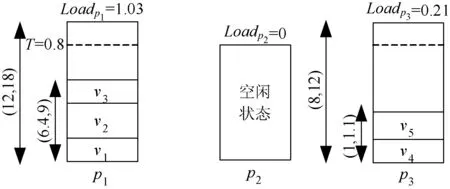
(b) 第二次迭代:v4从p3迁移至p1,然后v5迁移
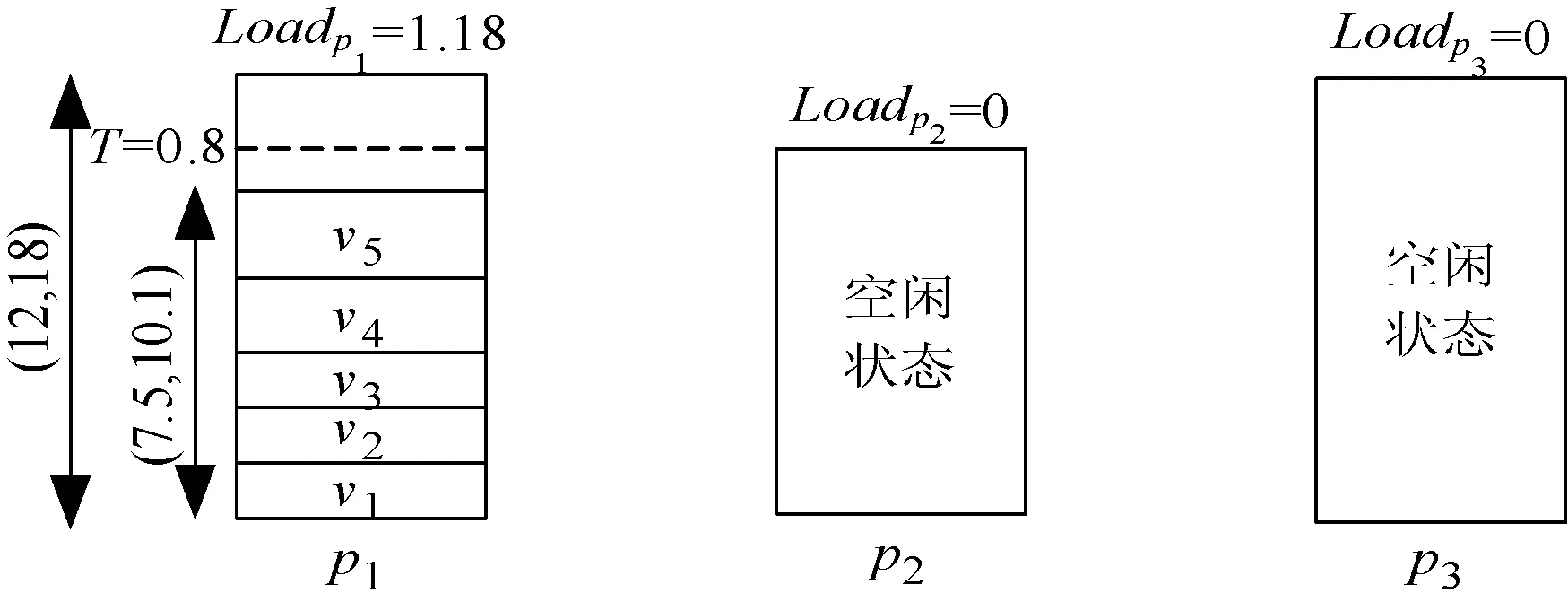
(c) 第三次迭代:不发生迁移图2 实例说明
类似地,p2和p3的负载分别为:Loadp2≈0.14,Loadp3≈0.20。在第一步,UP-VMC算法没有找到任一超载和预测超载主机,由于所有主机的当前和预测利用率均未超过主机能力。在第二步,算法根据当前负载得到主机p2是最低负载主机,为了释放p2,需要迁移虚拟机v3。
为了寻找部署v3的目标主机,UP-VMC算法从负载最大主机p1开始扫描,并确定式(9)和式(10)是否成立。
Up1+Uv3≤T×Cp1={1,2.7}+{0.5,0.5}≤
0.8×{12,18}={1.5,3.2}≤{9.6,14.4}
PUp1+PUv3≤T×Cp1={1.2,2.5}+{0.8,1.3}≤
0.8×{12,18}={2,3.8}≤{9.6,14.4}
由于主机p1在所有资源维度上均拥有足够的能力部署虚拟机v3,式(9)条件满足。同时,如果主机p1的预测能力向量为{1.2,2.5},虚拟机v3的预测需求能力向量为{0.8,1.3},则式(10)条件满足。
由于两个条件均满足,虚拟机v3可从主机p2迁移至p1。由于p2未部署任一虚拟机,p2可转换为休眠状态节省能耗 。
在第二次迭代中,算法未执行第一步,由于活跃主机p1和p3不是超载或预测超载主机。在第二步中,假设虚拟机的当前资源需求为:Uv1={1.4,3},Uv2={2,2},Uv3={3,4},Uv4={0.5,0.5},Uv5={0.5,0.6}。根据当前的虚拟机部署,如图2(b)所示,主机已使用能力向量为:Up1={6.4,9},Up2={0,0},Up3={1,1.1}。活跃主机的负载为:Loadp1≈1.03,Loadp3≈0.21。由于主机p3负载小于p1,若p1可容纳v4和v5,则可将p3转换为休眠。UP-VMC算法首先从p3上迁移一个拥有最大负载的虚拟机。虚拟机负载由式(7)计算。
由于v4比v5负载高,UP-VMC算法尝试将v4迁移至p1。p1需要在当前和未来均有足够资源能力容纳该虚拟机。在PUp1={1,2.5}和PUv4={0.5,0.6}情况下,式(9)和式(10)成立,则p1为目标主机。
Up1+Uv4≤T×Cp1={6.4,9}+{0.5,0.5}≤
0.8×{12,18}={6.9,9.5}≤{9.6,14.4}
PUp1+PUv4≤T×Cp1={1,2.5}+{0.5,0.6}≤
0.8×{12,18}={1.5,3.1}≤{9.6,14.4}
因此,v4可迁移至p1,由于主机在当前和未来均拥有足够资源能力。然后,算法检测p1是否有足够资源容纳v5,且假设PUv5={0.7,0.5}:
Up1+Uv5≤T×Cp1={6.4,9}+{0.5,0.6}≤
0.8×{12,18}={6.9,9.6}≤{9.6,14.4}
PUp1+PUv5≤T×Cp1={1,2.5}+{0.7,0.5}≤
0.8×{12,18}={1.7,3}≤{9.6,14.4}
由于v5可迁移至p1,迁移后p3可转换为休眠。最后,主机利用量从3减至1。同时,资源需求量增加,两个休眠主机可以再次开启。
5 性能评估
5.1 实验环境搭建
为了测试算法性能,在CloudSim平台[13]中进行仿真实验,构建由M台异构主机构成的数据中心,M大小由负载类型决定,如表2所示,选取PlanetLab[14]和Google[15]两类负载类型。每种负载类型中,一半主机为HP ProLiant ML110 G4服务器,单核1 860 MIPS,一半主机为HP ProLiant ML110 G5服务器,单核2 660 MIPS。每台主机拥有两个核心,4 GB内存和1 GB/s带宽。虚拟机实例的CPU和内存属性参考Amazon EC2在平台中设置,即:High-CPU中等实例(2 500 MIPS,0.85 GB),越大实例(2 000 MIPS,3.75 GB),小型实例(1 000 MIPS,1.7 GB),微型实例(500 MIPS,613 MB)。
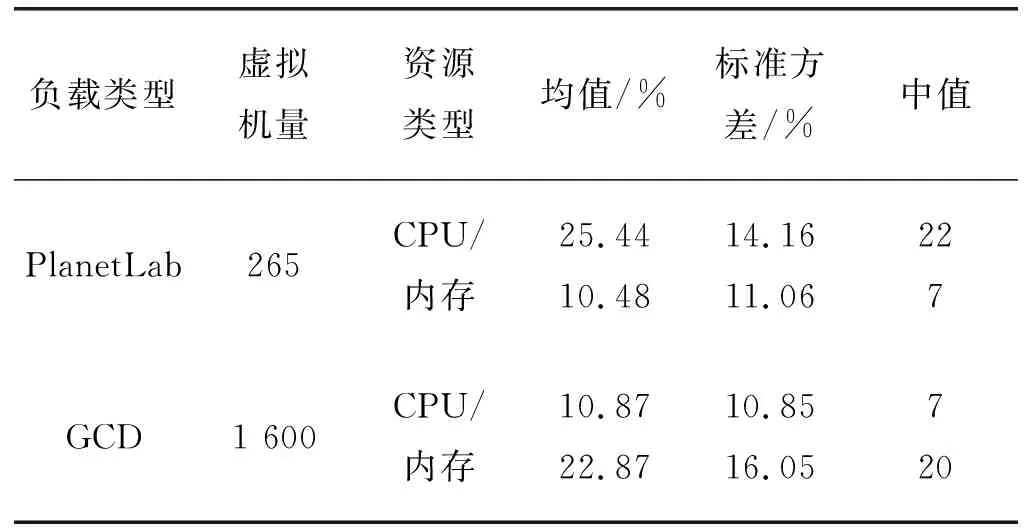
表2 负载流特征
5.2 评估指标
1) SLA违例SLAV指标。SLAV是一种独立的负载指标,用于评估虚拟机部署中SLA的交付情况。SLAV包括主机超载导致的SLA违例SLAVO和由于迁移导致的SLA违例SLAVM。对于云环境中的虚拟机合并问题而言,两种SLA违例具有同等的重要性,因此,综合的SLA违例指标可考虑为两个参数的乘积,表示为:
SLAV=SLAVO×SLAVM
(11)
式中:SLAVO表示活跃主机经历CPU利用率100%所占的时间比例。
(12)
式中:M表示主机数量;Tsi表示主机i经历的CPU利用率100%(导致SLA违例)的总时间;Tai表示主机i活跃状态的总时间。
SLAVM表示由迁移导致的虚拟机性能下降,度量为:
(13)
式中:N表示虚拟机数量;Cdj表示由于迁移导致的虚拟机j性能下降的估算;Crj表示整个周期中虚拟机j的总CPU请求量。
2) 能耗指标。该指标表示数据中心中物理主机执行负载消耗的总体能耗。主机能耗取决于CPU、内存、存储及网络带宽的利用率。研究表明,相比其他资源类型,CPU消耗了最多能源。因此,简化能耗模型后,主机能耗可表示为其CPU利用率的关系式。实验中依据SPECpower试验床中现实的功耗数据。表3给出了在不同的负载条件下两类主机HP G4和HP G5的功耗情况,可以看出,低载主机转换为休眠后可降低能耗。
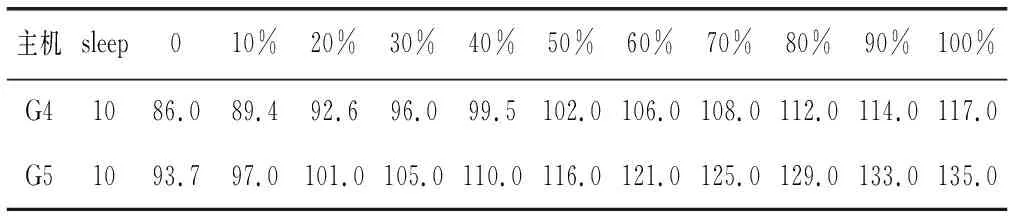
表3 不同负载条件下主机的功耗 单位:W
3) 虚拟机迁移量。在线虚拟机迁移涉及在源主机上的CPU处理、源和目标主机间的链路带宽、迁移时的服务停机、迁移时间等多重代价,因此,虚拟机合并过程中需要最小化虚拟机迁移量。
5.3 比较基准
将以下启发式算法与本文的虚拟机合并算法UP-VMC进行对比分析:
1) 改进降序最佳适应算法MBFD。该算法利用一个阈值限定目标主机的CPU利用率进行分配虚拟机迁移。若虚拟机和主机的总的已使用能力未超过主机的总能力阈值,则算法将虚拟机v分配至负载最高的主机pde,即式(9)。
比较UP-VMC,MBFD算法未使用预测模型,仅从超载主机上迁移虚拟机以避免SLA违例。因此,该算法可以通过释放主机节省能耗。
2) 改进降序首次适应算法MFFD。该算法将迁移虚拟机分配至满足资源需求且不超过CPU能力向量约束的第一台主机上,即式(10)。
同时,该算法通过迁移超载主机上的虚拟机最小化SLA违例,也执行了UP-VMC的第二阶段,基于当前资源需求最小化了活跃主机量。
3) 主机利用率预测的虚拟机合并算法PUP-VMC。该算法运行机制与本文算法UP-VMC类似,但仅考虑了目标主机的未来资源利用率进行虚拟机分配。因此,算法分配虚拟机v至目标主机pde,若主机pde的预测能力和虚拟机v的请求能力向量不超过主机总能力向量阈值,即:
PUpde+Uv≤T×Cpde
(14)
4) 虚拟机利用率预测的虚拟机合并算法VUP-VMC。该算法运行机制与本文算法UP-VMC类似,但仅考虑了虚拟机的未来资源利用率进行虚拟机分配。虚拟机v可分配至目标主机pde,若主机已使用能力向量与虚拟机的预测需求能力向量不超过主机的总的能力向量阈值,即:
Upde+PUv≤T×Cpde
(15)
5) 贪婪虚拟机合并算法G-VMC。该算法从最低载主机上尝试迁移出所有虚拟机至最高载主机上,并释放最低载主机。为了消除不必要的迁移,该算法只要出现一个虚拟机无法迁移,则所有虚拟机均不迁移。
6) 蚁群优化虚拟机合并算法ACS-VMC。一种元启发式装箱算法,利用蚁群觅食过程得到虚拟机迁移计划,降低能耗和SLA违例风险。
5.4 虚拟机迁移选择机制
引入三种典型的虚拟机迁移选择机制观察UP-VMC算法的性能:
1) 最小迁移时间算法MMT。该算法选择迁移的是具有最小迁移时间的虚拟机。迁移时间定义为虚拟机的内存除以源/主机间的网络带宽。
2) 最大负载算法MaxL。该算法选择迁移的虚拟机具有最大的负载Loadv。
3) 最小负载算法MinL。该算法选择迁移的虚拟机具有最小的负载Loadv。
5.5 结果分析
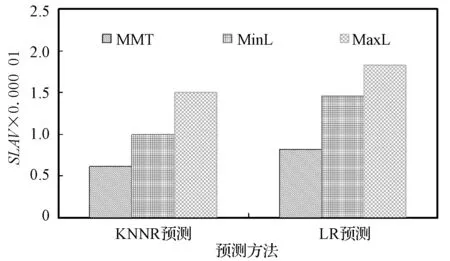
实验1观察虚拟机迁移选择策略对于性能的影响,结果如图3和图4所示。当利用MMT进行虚拟机迁移选择时,UP-VMC算法可以降低能耗、SLA违例、虚拟机迁移量。此外,利用K最近邻回归作为负载预测模型时,UP-VMC算法也可以更好地降低三个性能指标值,显然K最近邻回归比线性回归可以更准确地对主机和虚拟机的资源利用做出预测。
(a) SLA违例情况

(b) 能耗情况

(c) 虚拟机迁移量图3 PlanetLab负载流的性能结果-UP-VMC采用不同的虚拟机迁移选择机制和不同的负载预测模型

(a) SLA违例情况
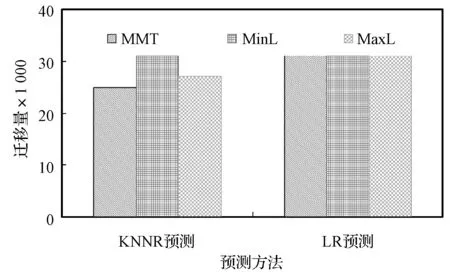
(c) 虚拟机迁移量图4 GCD负载流的性能结果-UP-VMC采用不同的虚拟机迁移选择机制和不同的负载预测模型
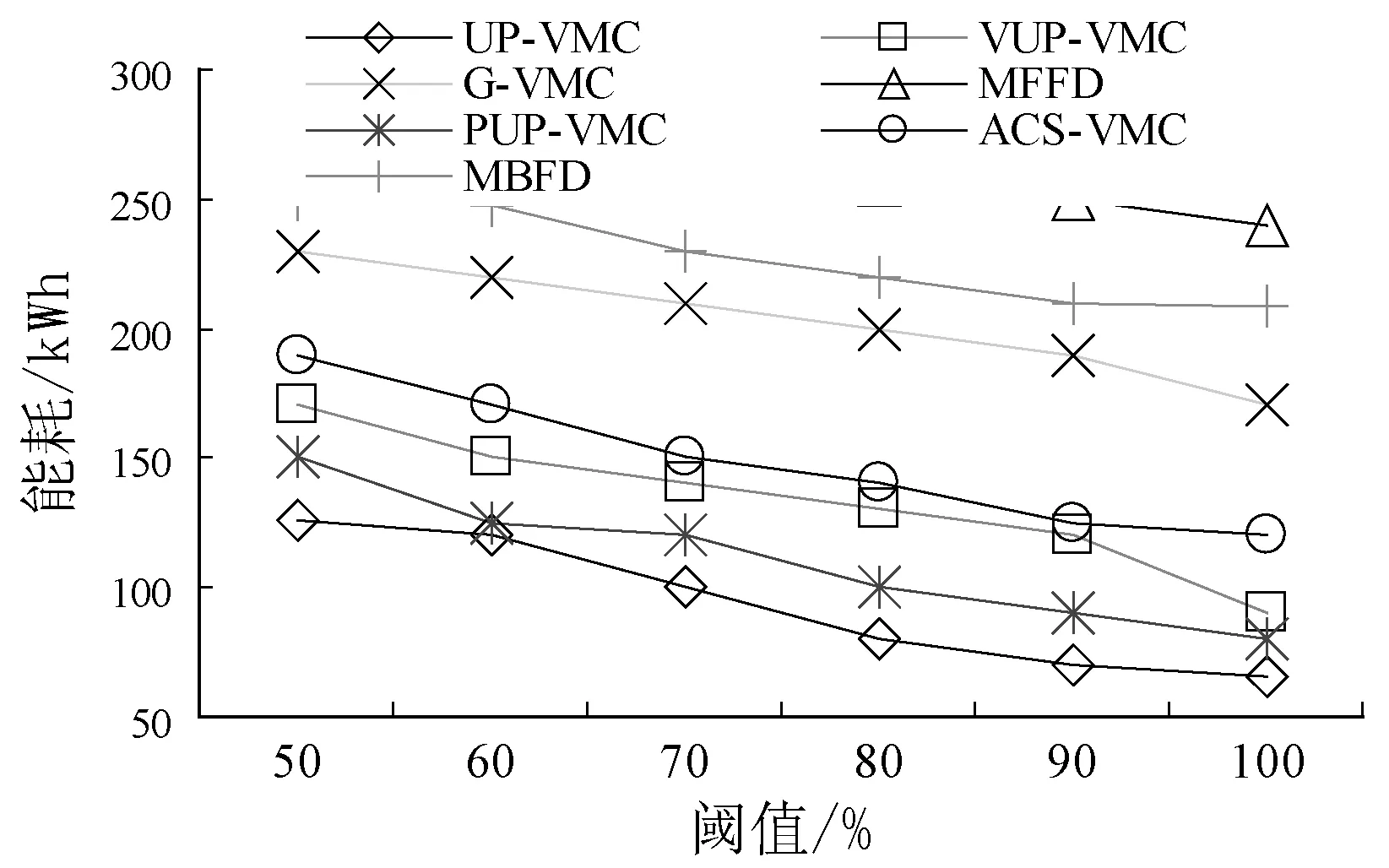
实验2观察与基准算法的对比结果。先以PlanetLab负载流进行测试。由于越高的CPU利用阈值将导致越高的性能下降和越多的迁移,而低阈值又会增加能耗,因此需要选取合适阈值大小。实验中在50%~100%范围内改变阈值取值观察性能指标值的影响。图5(a)显示了七种算法的SLA违例情况。显然,UP-VMC算法对比其他算法可以更有效地降低SLA违例,这是由于该算法根据设计的预测模型在将虚拟机迁移至目标主机时不会导致该主机变为短期内的超载主机。此外,UP-VMC算法可以从当前超载和预测超载主机上迁移虚拟机以避免SLA违例。图5(b)显示,UP-VMC算法较MFFD可以节省约71%的能耗,原因在于本文算法可以将虚拟机装箱至高负载主机,最小化了活跃主机的数量。图5(c)显示了虚拟机合并过程中的虚拟机迁移量。由于资源利用的预测,本文算法有效降低了虚拟机迁移量,且优于基准算法。

(a) SLA违例情况
(b) 能耗情况

(c) 虚拟机迁移量图5 PlanetLab负载流的性能结果
以GCD负载流同样进行了一次仿真实验,仿真过程中,每个虚拟机随机分配一个负载流。图6(a)显示UP-VMC算法比基准算法大大降低了SLA违例,这是由于UP-VMC能够通过主机和虚拟机的负载预测以及虚拟机迁移不会导致目标主机变为超载主机的方式有效避免了SLA违例。图6(b)显示,UP-VMC拥有最多的能耗节省,这是由于UP-VMC通过装箱虚拟机至更少的主机释放了低载主机,节省了能耗。同时,由图6(c),UP-VMC也得到了最少的虚拟机迁移量,这利于本文算法可以根据当前和未来的资源占用分配迁移虚拟机,降低了无用虚拟机迁移。

(a) SLA违例情况
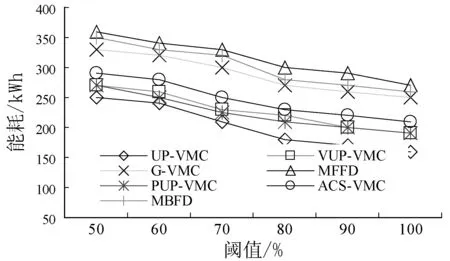
(b) 能耗情况

(c) 虚拟机迁移量图6 GCD负载流的性能结果
综合实验结果分析,负载的动态变化会直接影响虚拟 机迁移过程。当负载量急剧增加时,虚拟机迁移量也会相应增加,由于在确定的资源能力状态下,必须通过虚拟机迁移才能满足更大的负载需求。在此过程中,资源利用阈值也会影响虚拟机迁移,阈值的增加也会导致迁移量的增加,这是因为此时在相同条件下资源可容纳的负载会增多,可允许的迁移也会增加。但是,在虚拟机和主机两端进行了资源利用预测可以明显降低虚拟机迁移量,避免动态负载条件下的不必要迁移。当负载量比较平稳或较小时,虚拟机迁移频率也会较小,因为已有资源能力可以满足负载需求,无须进行虚拟机迁移。
综合图5和图6可以发现,阈值的增加会导致能耗的降低,但迁移量和SLA违例会有所增加。因此,在实际环境中,应该综合考虑性能优化目标来设置合适的阈值。
6 结 语
本文提出一种预测感知的虚拟机合并算法。算法将虚拟机合并形式化为多目标向量装箱问题。为了将虚拟机合并至最小数量的活跃主机上,算法利用回归模型同步考虑了主机上的当前负载和未来负载,使得虚拟机迁移过程中在目标主机选择上可以避免主机在虚拟机迁移后变为超载主机,增加SLA违例风险。通过两类负载类型的仿真测试,证明了本文算法不仅可以降低数据中心能耗,还可以同步降低SLA违例和虚拟机迁移量。进一步的研究可集中考虑资源维度更多的虚拟机合并和迁移问题。除了关键的CPU资源和内存之外,网络资源占用和链路拥塞也是虚拟机合并过程中可能需要考虑的问题,尤其针对通信密集型应用负载类型而言,可能导致通信链路的拥塞,此时若仅考虑CPU和内存资源两个维度,可能导致最终的虚拟机合并与迁移出现超时问题。
猜你喜欢
煤气与热力(2022年4期)2022-05-23
煤气与热力(2022年4期)2022-05-23
新高考·高一数学(2022年3期)2022-04-28
浙江人大(2022年1期)2022-02-19
环球时报(2020-02-19)2020-02-19
知识就是力量(2019年7期)2019-07-01
电脑知识与技术(2016年19期)2016-08-18
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
