
基于DCNN深度特征融合和MMRVM的遥感场景分类
2022-10-10 09:34卢湖川杨晓敏陈炳才雷印杰
计算机应用与软件 2022年9期
王 倩 宁 芊,* 卢湖川 杨晓敏 陈炳才 雷印杰
1(四川大学电子信息学院 四川 成都 610065) 2(新疆师范大学物理与电子工程学院 新疆 乌鲁木齐 830054) 3(大连理工大学信息与通信工程学院 辽宁 大连 116024)
0 引 言
遥感[1]是一种基于航拍技术的新型技术与科学。通过遥感技术,人们可以从遥远的高空得到想要获取位置的地表信息,它的快速发展为地表信息的累积、以遥感信息为基础的研究和遥感场景数据集的创建等方面作出了巨大贡献,被广泛运用于环境保护、地质调查和测量、土地利用和土地覆盖的确定、矿产勘探等社会规划中[2]。在遥感场景图像(RSI)分类研究中,特征提取与处理以及分类器的选择都是场景正确分类的关键前提。
现阶段特征表示方式及处理方式包括多种,如低层特征、中层特征、深度特征。在低层特征中,包含尺度不变特征变换特征(SIFT)[3-4]、方向梯度直方图特征(HOG)[5]、GIST特征和Gabor特征[6]等;中层特征一般是通过对低层特征进行统计计算或者编码得到的,比较热门的方法是词袋模型(BOW)[7]。在近期,许多以BOW为基础的研究方式涌出,例如视觉词袋模型(BOVW)[7-8]。徐培罡等[9]提出用多重分割关联子特征的特征研究方法对低层特征进行特征融合,再使用BOVW对融合特征进行处理,但是低层特征的图像描述能力弱,并且特征提取与处理的过程繁琐,最终的分类效果也较差。中、低层特征提取及处理对研究人员的经验要求很高,耗时更多,最终的分类效果也不会有很大的提升。
深度学习的出现为特征提取提供了一种新思路。例如,Liu等[2]采用两种深度卷积神经网络(DCNN)模型中提取的卷积特征经过特征融合后再形成最终的全局特征,但是通过人工处理形成的全局特征与计算机直接提取的深度全局特征在描述能力上具有一定的差距,因此最终的分类效果不是很好。Gong等[8]以卷积神经网络深度特征和词袋模型为基础,提出卷积特征包(BoCF)的新语义描述,以提高特征描述能力,分别使用两种DCNN的卷积层特征用于分类器训练,但是单模型提取的特征,描述能力有限,因此最终分类效果不佳。孟庆祥等[10]提出改进DCNN模型,通过正则化、dropout等手段避免过拟合现象,但是由于深度网络结构复杂、参数众多、精度提高不大的情况导致训练缓慢。此外,在分类问题中,分类器的选择与设计也是很重要的,例如文献[2]中采用的是线性SVM,文献[8]中采用的是一对多SVM。但是常规SVM在多类分类问题中,效果并不是特别理想。
由此可见,虽然现阶段基于深度特征在遥感场景分类领域都有大量的成功应用,但是也存在一些问题。一方面,深度特征的特征描述能力对比于低中层特征提高很多,但是单模型的深度卷积特征通过特征处理形成的全局特征或者直接提取的深度特征描述能力依然不是很好;另一方面,使用卷积神经网络(CNN)训练分类模型,在小样本数据集上的训练很容易导致过拟合,而在大数据集上的训练时间长,对硬件设备要求也较高。此外,SVM大多是通过单核函数映射,在类别较少的数据集上分类效果好,但是随着类别的增多,效果也会变差。因此,基于以上考虑,以提高遥感场景分类能力为最终目的,本文从特征描述能力与分类器的分类能力两方面进行改进。先将从两种DCNN预训练模型VGGNet-16和ResNet-50中提取的深度全局特征进行特征融合,以扩充单模型特征描述能力;基于与SVM原理相似的相关向量机,设计并构建MMRVM分类器,并运用于遥感场景分类领域中进行训练及分类以提高最后的分类效果。实验证明,特征融合结合MMRVM(Fusion MMRVM,F-MMRVM)对UCM数据集进行遥感场景分类效果较好,构建LSV数据集,并在LSV大场景图像上进行场景级分类中的应用表现良好。
1 原理介绍及方法描述
1.1 MMRVM模型介绍
随着分类任务的加重以及数据类别的增多,主要针对二分类任务的RVM不再能满足分类需求,所以Psorakis等[11]针对多分类任务再结合RVM提出MMRVM。与RVM相同,MMRVM是基于贝叶斯框架训练学习,由多项后验似然函数实现多类及概念输出[12]。

(1)
加入回归目标Y∈RN×C和权重W∈RN×C,得到最后的噪声模型为:
(2)
式中:ync为回归目标函数;wc为权重。
为了将回归目标转换成存在类别,引入了多项概率连接函数tn=i,yni>ynj,j≠i,再结合文献[11],得到最终的多项概率似然函数如下:
(3)
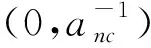
1.2 MMRVM模型学习
使用快速type-II最大似然函数进行参数的更新。根据log边缘函数推导得到:
C=I+KA-1KT
(4)
C可分解为:
(5)
在C分解式中,C-i代表删除了第i个样本后的C值,表达式如下:
(6)
log边缘函数可再次被分解为:
L(α)=L(α-i)+l(αi)
(7)

(8)
(9)
结合文献[11-12]在训练模型的过程中,最大后验值被更新为:
(10)
(11)
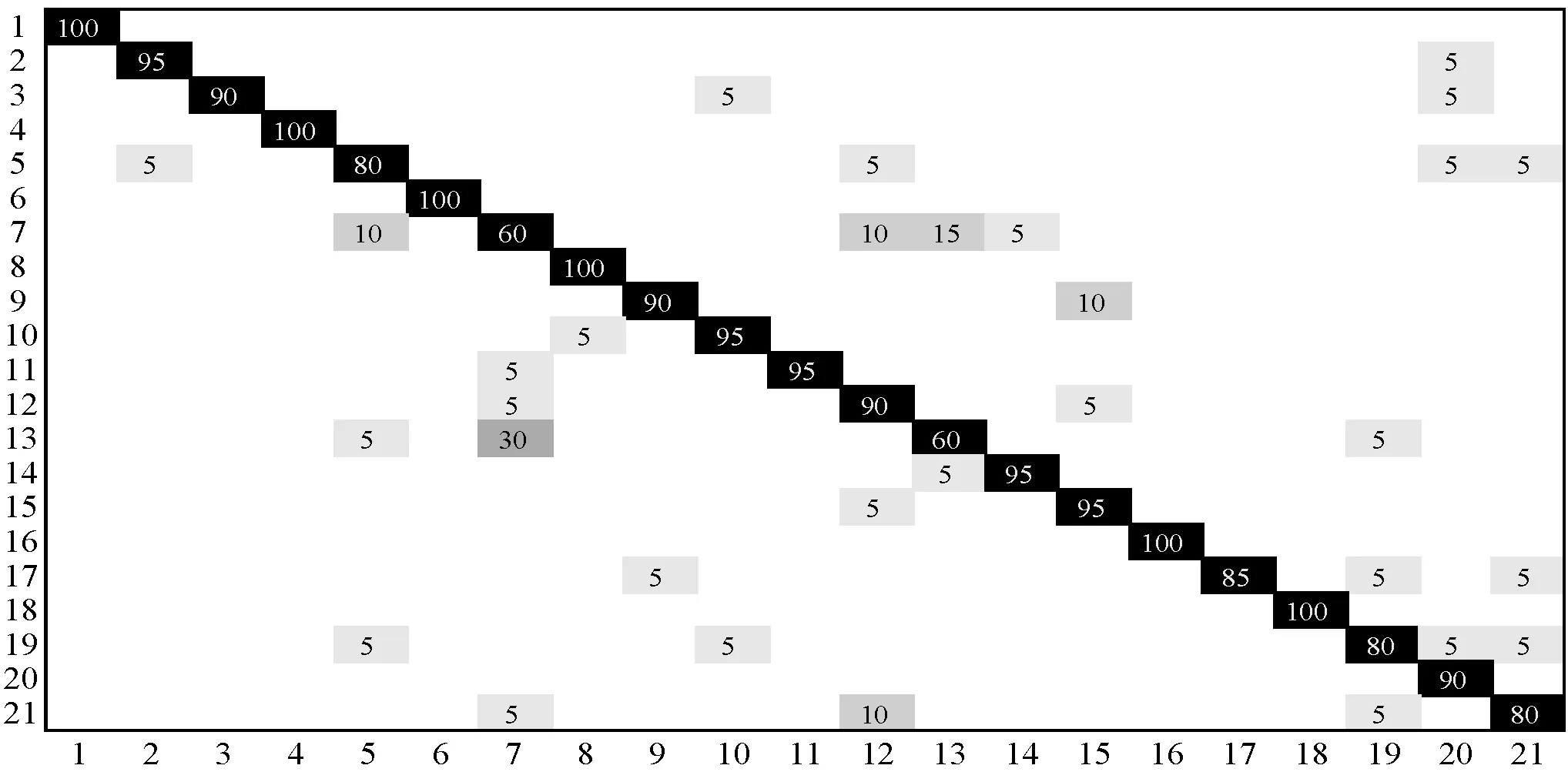
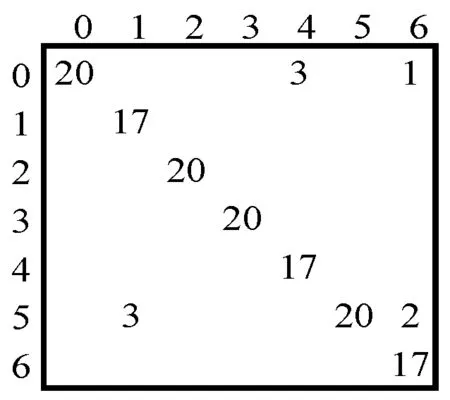
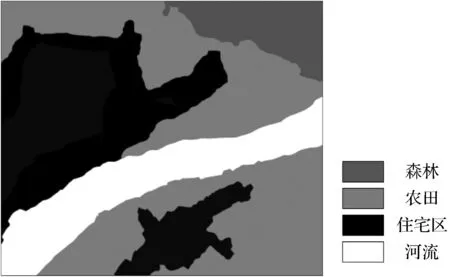
式中:K*∈RN×M;A*∈RM×M;M< 再根据式(4)得到后验分布为: (12) ∀c≠i 先验参数的后验分布如下: P(A|W)∝P(W|A)P(A|v)∝ (13) Yosinski等[13]通过对CNN模型每一层特征的特征迁移性进行研究,发现从第一层网络提取的特征就是低层特征,与最终的分类结果关联性很小,但是最后一层的特征却起到关键性作用。此外,训练一个新的、高精度的深度卷积神经网络需要依赖于一个很大的数据集且对硬件设备要求高、耗时长,而预训练CNN模型的学习卷积核对于数据的依赖性比较低,所以在本文的研究中,将由大型数据训练过的DCNN模型作为特征提取器,以提取图像特征。单独的DCNN模型中提取的深度特征虽然已经包含了大部分图像的语义特征,但是由于dropout等算法,会造成部分特征丢失。此外,在多分类任务中,分类器的选择错误会导致分类效果大打折扣,所以本文提出将两种DCNN模型VGGNet-16和ResNet-50中提取的深度特征进行特征融合,以弥补丢失特征,进一步提高特征描述能力,结合MMRVM分类器原理,设计多核相关向量机,以提高分类器的分类能力。基于上述考虑,提出如图1所示方法,以提高图像场景分类效果。 图1 实验原理 图1中主要分为两大部分。第一部分是特征处理,包括特征提取、特征融合和特征降维。首先使用在ImageNet数据集上训练过的VGGNet-16和ResNet-50模型作为特征提取器,用于全局特征的提取。遥感图像在两种DCNN中经过卷积操作以及全连接层的映射后,分别得到最终的全局特征,1×1 000的一维特征向量,分别记为: FeatureV=[v1,v2,…,vn] FeatureR=[r1,r2,…,rm] 根据深度学习理论方式的融合原理得到最终的融合结果如式(14)所示。 FeatureVR=[FeatureV,FeatureR]= [v1,v2,…,vn,r1,r2,…,rm] (14) 由于融合后的特征维度加倍,且总是有重复冗余特征,所以经过特征降维操作以轻减特征冗余度,提升模型训练效率。 图1中第二部分为分类器的设计,对于支持向量机分类器,核函数的选择是重中之重,而与支持向量机类似的MMRVM分类器,其核函数的选择也是非常重要的。本文基于三种核函数,线性核函数(式(15))、高斯核函数(式(16))和多项式核函数(式(17))进行研究,根据单核函数的结果差异,选择效果最好的两种核函数组合在一起,构造效果优良的分类器,再使用训练集进行模型训练。 k(x,x′)=xx′ (15) (16) 式中:δ为函数的宽度参数。 k(x,x′)=(xx′+1)d (17) 基于数据源的迁移是从原有的大型数据集中,挑选出部分与目标数据分布相近的数据与目标数据集进行混合,以扩充训练集的样本数量。相近分布的数据混合在一起训练,能够促使训练效果更加优化,得到分类精度高的分类模型。由于本文构建的LSV数据集样本少,直接用于模型训练会导致过拟合现象发生,致使识别率低,因此引入基于数据源的迁移学习以实现最终的LSV遥感场景分类应用。 数据集UCM全称为UC Merced Land Use[3],摘自美国地质调查局国家地图城市地区图像集中的大型图像,囊括了全国各个城镇地区的遥感场景图像。该数据集总共有2 100幅遥感场景图像,总共21类,每一类包含100幅图像,每幅图像大小为256×256像素。基于软件LSV(Local Space View),通过获取成都周边遥感图像,制作小样本数据集,包含农田、密集住宅区、停车场、马路、河流、森林、稀疏住宅区七种类别。所有图像的像素都为256×256的RGB图像,每一类包含30幅。在UCM数据集中,80%作为训练集,剩余的作为测试集。在LSV数据集中,采用数据源迁移学习的方式,选取LSV数据集每类中10幅图像与UCM中该类的90幅图像进行混合,形成每类100幅的训练集,LSV数据集中每类的20幅图像作为测试集。 图2展示的是场景图像A,使用LSV软件采集得到。该场景位于东经103.985°、北纬30.417°,采集高度为3 000 m,主要场景包括农田、河流、密集住宅区、稀疏住宅区和森林五类遥感场景,图像的像素大小为1 792×1 536。采用像素滑动窗口来进行场景遍历实现最终的场景级分类,其中像素窗口大小分设为五种:1 024×1 024、768×768、512×512、256×256和128×128。滑动步长设置为128像素。 图2 场景图像A 实验的硬件环境为Intel i7-6700 3.4 GHz的CPU、16 GB内存和单块NVIDIA GeForce GTX1070 Ti显存6 GB的显卡,操作系统为Ubuntu16.04-Linux操作系统,使用PyCharm编辑器。 表1展示了UCM数据集在不同核函数RVM上的总体分类精度及时间对比。 表1 单核RVM分类器识别精度、时间对比 可以看出,针对单核RVM分类器,当核函数为线性核函数时,识别精度最高,为88.57%,多项式核函数次之,为87.62%,高斯核函数分类效果最差,为86.43%。模型训练时间则都相差很小,大概都在1.15 s左右。由于高斯核函数的耗时更多,且由结果可知在样本量与特征数相差较大的情况下,线性核函数和多项式核函数的效果比高斯核函数分类效果稍好,所以本文选择线性核函数和多项式核函数进行函数组合构成多核MMRVM。 表2所示为单DCNN模型深度特征与融合特征分别结合MMRVM后,得到的最终分类精度及训练时间对比。 表2 不同特征结合MMRVM的识别精度、时间对比 可以看出,F-MMRVM的分类精度达到89.52%,比两种DCNN模型的分类精度分别高出7.6百分点和3.5百分点左右,图3展示了F-MMRVM的分类结果的混淆矩阵。混淆矩阵中各类别分别为:1.飞机;2.海滩;3.农业;4.棒球场;5.建筑物;6.灌木丛;7.密集居住区;8.森林;9.公路;10.高尔夫球场;11.海港;12.十字路口;13.中等密集住宅区;14.拖车住房公园区;15.立交桥;16.停车场;17.网球场;18.河流;19.飞机跑道;20.稀疏住宅区;21.储存槽区。如混淆矩阵所示,第i行第j列中的数字代表着将第i类识别为第j类的概率。可以看出,该算法模型在大部分场景的识别中都能达到很好的分类效果,仅有密集住宅区(类别7)与中等密度住宅区(类别13)的分类效果较差。主要还是归因于两类图像高维特征过于相似,导致最终的场景混淆。 图3 基于F-MMRVM的数据集分类结果混淆矩阵(89.52%) 表3列出了基于UCM数据集的一些现有方法和本文方法的分类准确度,这些现有方法详见文献[2,3,10,14-17]。与现有方法的比较表明,本文方法比文献[2,3, 10,14-17]中的最佳结果提高了2.69百分点。 表3 UCM数据集与现有方法结果对比(Overall Accuracy,OA) 图4展示了F-MMRVM基于LSV与UCM混合数据集对LSV数据集进行分类后得到的分类结果混淆矩阵。标签0-标签6分别代表类别农田、密集住宅区、森林、马路、停车场、河流和稀疏住宅区,总分类精度为93.57%。 图4 LSV数据集分类结果混淆矩阵(93.57%) 根据不同的像素窗口对实验图像A进行局部场景截取,再经过分类模型场景分类后,判别出每个单位像素(128像素)的类别,最后统计出最终的场景级分类结果如图5所示。可以看出,像素滑动窗口大小为1 024×1 024时,仅能分辨出密集居住区、稀疏居住区和河流三种类别,与实际场景图像差别巨大;像素滑动窗口大小为768×768和512×512时,也仅能分辨出密集居住区、稀疏居住区、河流和农田四种类别,虽稍微靠近原始图像,但是依然相差较大;当像素滑动窗口大小为256×256和128×128时,五类场景均被识别出来,而像素滑动窗口大小为128×128时,由于滑动窗口过小,遍历图形的过程中信息被混淆,导致部分森林、稀疏住宅区区域被识别为河流,部分农田区域被识别为森林,使分类效果降低;只有像素滑动窗口大小为256×256时分类效果与实际场景符合。因此,通过此实验可以确定最好的像素滑动窗口大小为256×256。 图5 不同像素滑动窗口场景分类 为消除场景分类窗口效应,进行场景边缘提取后,基于得到的最佳滑动像素窗口256×256,对边缘内部区域再进行类别区分,可得到如图6所示结果。通过对最终结果和实际图像进行场景对比,基本符合原图的场景分布。 图6 边界划分分类结果 本文研究的基础特征为从VGGNet-16和ResNet-50两种预训练模型中提取的遥感图像全局特征,通过特征融合的方式对特征描述能力进行补充。提出构造MMRVM分类器并与特征融合相结合的方式,以验证MMRVM在遥感场景分类领域的有效性;构建LSV,并采用UCM数据集中与LSV数据集类别相同的7类场景数据进行迁移学习,再对LSV数据集进行场景分类,得到最终的分类结果为93.57%;接着根据已得MMRVM训练模型,结合像素窗口滑动的方式对场景图像A进行遍历识别分类,从而实现大场景图像的场景级分类,并确定最优像素滑动窗口为256×256。通过场景边界提取再一次进行场景分类以消除窗口边界效应,获得较为准确的分类结果。今后应该致力于更多场景的分类应用研究。
1.3 方法描述

2 遥感场景分类实验数据集
2.1 数据源迁移学习
2.2 数据集

3 实验分析与方法验证
3.1 实验环境
3.2 UCM数据集的不同核函数RVM分类对比



3.3 小样本LSV数据集迁移学习分类实验

4 结 语
猜你喜欢
计算机时代(2022年9期)2022-11-03
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
红领巾·萌芽(2019年8期)2019-08-27
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
软件导刊(2017年4期)2017-06-20
CHIP新电脑(2016年3期)2016-03-10
少儿科学周刊·少年版(2015年3期)2015-07-07
