
高光谱影像奇异谱特征提取和分类方法
2022-10-13 09:13赵莹莹潘兆杰付航张爱竹姚延娟孙根云
遥感信息 2022年4期
赵莹莹,潘兆杰,付航,张爱竹,姚延娟,孙根云
(1.长沙市规划勘测设计研究院,长沙 410007;(2.海洋国家实验室 海洋矿产资源评价与探测技术功能实验室,山东 青岛 266071;(3.中国石油大学(华东)海洋与空间信息学院,山东 青岛 266580;(4.生态环境部卫星环境应用中心 国家环境保护卫星遥感重点实验室,北京 100094)
0 引言
高光谱图像(hyperspectral image,HSI)包含数百个甚至上千个连续的光谱波段,可以有效地识别不同材料的细微变化。高光谱影像被广泛应用于目标识别[1]、环境管理[2]和矿产测绘[3]等领域,其中,地物分类是当前的一个研究热点[4]。然而,HSI分类还存在较多的问题,如“同物异谱、同谱异物”现象,巨大的维度造成分类中的“Hughes现象”,这给影像的解译带来了挑战。因此,对HSI数据进行有效的特征提取是必要的[5]。
特征提取可以将高维数据投影到低维空间,保留原始数据基本结构信息的同时降低数据的维数。近些年来,研究人员提出了一系列特征提取方法,如广泛应用的主成分分析(principal component analysis,PCA)[6]和线性判别分析(linear discriminant analysis,LDA)[7],一些基于流形学习的方法被提出,如局部保持投影(locality preserving projection,LPP)[8]、局部线性嵌入(locally linear embedding,LLE)[9]等,这些方法可以更好地挖掘高维数据中潜在的低维流形结构。考虑到上述方法均为无监督方法,分类性能有限,研究人员进一步提出监督的特征提取方法,如局部Fisher判别分析(local Fisher discriminant analysis,LFDA)[10],其主要思路是最大化类间分离的同时保留类内精细复杂的局部结构,有效提高了分类精度。
然而,上述特征提取方法主要作用于光谱域,仍然受到“同物异谱、同谱异物”的影响。高光谱影像包含的地物空间特征对点状误分类的现象具有潜在的帮助。为此,研究人员提出了一系列联合光谱-空间的分类方法,这些方法可大致分为两类:基于机器学习的方法和基于深度学习的方法[11]。基于机器学习的方法主要包括特征提取和分类器两个阶段,特征提取是通过一种或融合几种不同的处理技术来共同挖掘影像的光谱-空间特征,并利用高效的分类器获得分类结果。基于深度学习的方法主要利用多个非线性网络,分层提取HSI的抽象特征和鉴别特征,近些年来逐渐成为研究的主流[12-16]。然而,深度学习方法存在样本需求量大、计算耗时昂贵、难以解释模型内的动态变化等[17]问题。机器学习方法侧重于特征提取方式和分类器的选取,通常结构比较简单、参数少,仍然是提高分类精度的重要突破。因此,本文主要关注基于机器学习的方法。
在基于机器学习的分类方法方面,研究人员提出了一系列高效的光谱-空间特征提取算法。如Zabalza等[18]将二维奇异谱分析(two-dimensional singular spectrum analysis,2DSSA)用于高光谱逐波段的特征提取,该方法通过分离不同的空间信息成分,来获取单波段的主要空间上下文特征。Kang等[19]提出一种结合平均降维和本征图像分解的特征提取方式,可以有效去除影像中的无用信息,如阴影和图像噪声,提高了影像的分类精度。Li等[20]结合分段主成分分析(segmented PCA)和高斯金字塔,提出了一种高效的多尺度空间融合分类框架,取得了优异的分类效果。
然而,这些光谱-空间特征提取方法大多数作用于规则形状或固定大小的空间区域,忽略了影像地物形状和尺度的复杂性,即用于空间特征提取的区域与图像的空间结构不匹配[21]。图像超像素分割能够获取不同大小和形状的图像局部均质区域,在一定程度上可以解决上述问题[22]。
为了充分挖掘高光谱影像丰富的地物尺度特征,本文提出了一种结合超像素和2DSSA的空间特征提取方法即超像素2DSSA(S2DSSA),将2DSSA的作用域从整幅图像变换到超像素区域,可以自适应地挖掘不同形状地物的空间上下文特征,能够提高类内光谱的一致性并增强类间差异。为了进一步挖掘影像的光谱非线性结构,本文将提出的S2DSSA与LFDA相结合,在空间特征的基础上提取光谱流形特征,进一步提升类间相似性,提高地物的区分性。选取支持向量机(support vector machine,SVM)对得到的光谱-空间特征进行分类,将本文的处理流程记为S2DSSA-LFDA-SVM方法。
1 提出的方法
本文提出的S2DSSA-LFDA-SVM方法主要包含4个步骤:1)对原始的HSI进行PCA分解,在得到的第一主成分图上进行熵率分割(ERS)[23],得到分割图;2)分割图引导2DSSA对每个波段的超像素区域进行特征提取,得到空间特征;3)LFDA作用于空间特征的光谱域,得到降维后的光谱-空间特征;4)SVM对光谱-空间特征进行分类。具体过程如图1所示。
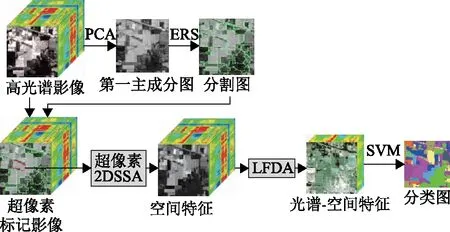
图1 提出的S2DSSA-LFDA-SVM方法的框架流程
1.1 基于ERS的超像素分割
熵率分割(entropy rate segmentation,ERS)是一种基于图论的分割方法,在图像处理中得到广泛应用[24]。具体来讲,ERS首先将PCA第一主成分图像映射为一个图G=(V,E),其中V是图的顶点,E是图的边缘集合。在某一超像素数量下,选择子边缘集A使得图G恰好包含S个离散的子图,其中每个子图代表一个超像素。然后,使用构造的熵率项函数H(·)和平衡项函数B(·)得到目标函数,通过最优化目标函数来获得S个超像素,目标函数如式(1)所示。
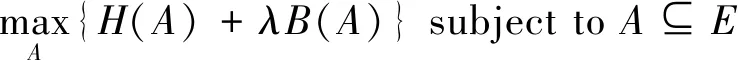
(1)
式中:λ≥0是平衡项函数的权重调节参数。上式的优化问题一般通过贪心算法求解[25]。最后,通过基于稀疏表示的距离度量为每个超像素指定一个公共标签。
1.2 超像素2DSSA(S2DSSA)
S2DSSA作用于单个波段的每个超像素区域。对于某一超像素区域,首先为其构建一个规则的作用区,即根据超像素的行数和列数,结合邻域像素来补充超像素区域,如图2所示。

图2 S2DSSA的处理方式
然后,对于每个规则的超像素区域,使用2DSSA对其进行特征提取,它旨在提取最大特征值分量所反映的空间信息。对于尺寸为Nx×Ny的规则超像素区域,定义一个大小为L=l×l(l∈min[Nx/2,Ny/2])的二维嵌入窗口。该窗口从图像的左上角滑动到右下角,不同位置处窗口内所有像素按列拉伸为向量Vi,j∈L×1,将其作为轨迹矩阵P的列向量,可得式(2)。
P=(V1,1,V1,2,…,V1,Ny-Ly+1,V2,1,…,VNx-lx+1,Ny-ly+1)∈RL×(Nx-lx+1)(Ny-ly+1)
(2)
计算协方差矩阵PPT的特征值和相应的特征向量,轨迹矩阵可以写成式(3)。

(3)
式中:Ui和Vi分别为轨迹矩阵的左奇异向量和右奇异向量。选择P1成分作为P的近似值,通过两步对角平均处理操作,可将矩阵P1再次转换为Nx×Ny大小的规则区域。
经过每个超像素区域的2DSSA特征提取后,将原始超像素位置处的像素提取出来,作为特征提取后的超像素,如图2所示。相比于原始超像素,该特征超像素有较好的区域均匀性,并且消除了噪声的影像。
1.3 基于LFDA的光谱特征提取
局部Fisher 判别分析(LFDA)用于空间特征的光谱流形结构降维,其基本思想是最大化类间分离的同时保留类内精细复杂的局部结构。假设xi∈B×1表示输入空间特征的单个光谱向量,B为高光谱数据的维度,首先计算样本xi和xj的相似度矩阵,如式(4)所示。
(4)
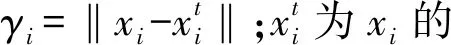
(5)
(6)
式中:Wlb和Wlw为用来保留数据局部信息的加权矩阵。它们的第(i,j)个元素可表示为式(7)、式(8)。
(7)
(8)
最后,通过计算局部Fisher 比率的最优值得到投影变换矩阵WLFDA,可表示为式(9)。
(9)

1.4 基于SVM的分类
特征提取后,使用SVM分类器进行基于像素的HSI分类,主要是因为SVM对数据的维数问题有较高的鲁棒性,核函数选取RBF核函数。
2 实验及结果分析
2.1 实验数据及设置
实验主要使用了两个包含地面真值图的经典数据集,Indian pines和Pavia centre数据,其详细信息如下。
Indian pines数据:由机载可见光/红外成像光谱仪(AVIRIS)获取的高光谱影像,空间分辨率为20 m,光谱范围为400~2 500 nm,包含145像素×145像素的图像尺寸和200个波段。
Pavia centre数据:由反射光学系统成像光谱仪(ROSIS-03)传感器获取的数据集,光谱覆盖范围从0.43~0.86 μm。该数据集包含103个波段,空间分辨率为1.3 m,使用了510像素×490像素大小的子场景,共有9个土地覆盖类。
SVM分类器算法在LIBSVM library库[26]中通过使用高斯RBF核函数来实现,10倍交叉验证方法获取最优核函数参数。在分类过程中,采用分层的随机取样方式获取训练和测试样本,并且每类的采样比率或数量相同。另外,为了定量地评价分类的结果,选取5个客观质量指标:总体精度(OA)、平均精度(AA)、每类地物的精度、Kappa系数,以及运行时间。
2.2 参数敏感性分析
本节对所提出算法的参数进行分析,主要包括3个参数:S2DSSA的超像素数量S、窗口大小L,以及LFDA的降维成分数。
在空间域,S2DSSA的超像素数量以及窗口大小的组合至关重要。为此,设计实验来评估超像素数量和窗口大小的组合效果,其中超像素数量S的选取范围为{10,25,50,100,150,200},窗口大小L范围为{3×3,5×5,7×7,9×9},不同组合的分类精度如图3所示。根据图3可以看出,两个数据集由于地物覆盖的大小形状不同,最优参数组合也存在差异。对于较小超像素区域,较小的S2DSSA窗口能够很好地平滑超像素内部,提高区域一致性;而较大的窗口会因无法处理,只保留原始的区域特征,精度下降。在参数S和L分别为50和7的情况下,两个数据集都能取得不错的分类精度。
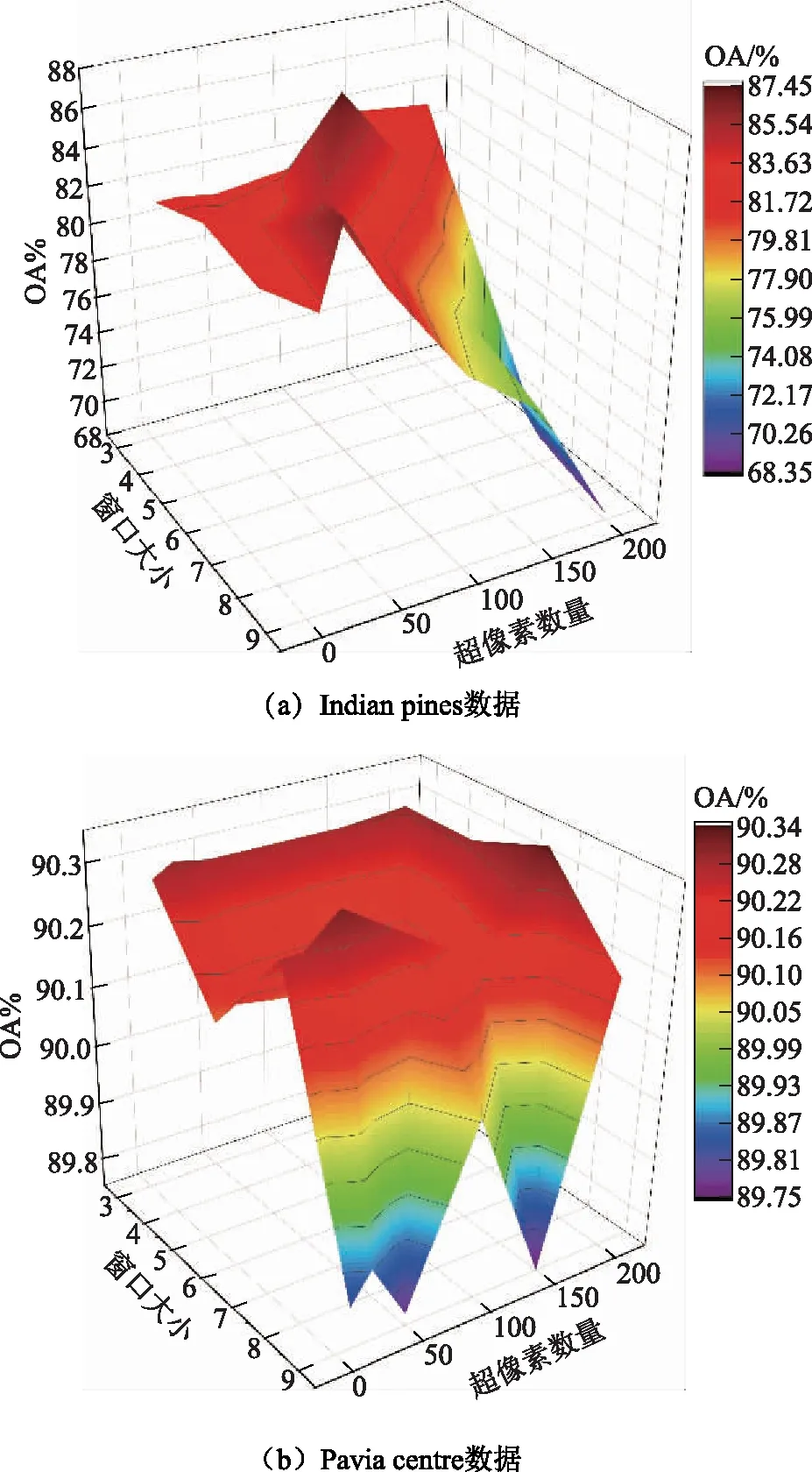
图3 S2DSSA的参数(窗口大小及超像素数量)敏感性分析
在光谱域,LFDA的降维成分数能够衡量光谱特征的利用程度。评估实验的结果如图4所示。根据结果可知,随着维度的增加,两个数据集的精度均有上升趋势,在维度为15时取得最高精度;随着降维成分的继续增加,精度呈下降趋势。为了保证所提出方法在不同数据集上的适用性,将上述3个参数分别固定为50、7和15,即针对一副给定的高光谱影像,提出方法的参数是可迁移的。
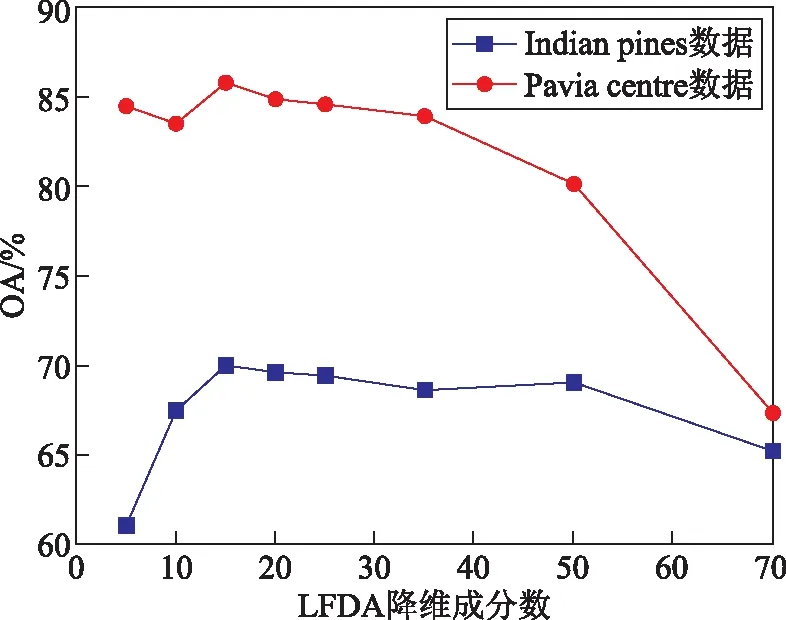
图4 LFDA的降维数量分析
2.3 精度对比和分析
为了验证所提出算法的有效性,本节选取了几种先进的分类方法进行了精度对比。原始像素级SVM分类作为基准,记为SP-SVM。LFDA-SVM和2DSSA-SVM分别作为光谱、空间特征提取方法。光谱-空间分类算法上,选择了本征图像分解(IID)的融合、高斯金字塔的多尺度融合(SPCA-GPs),二者分别使用相应文献中的默认参数。此外,2DSSA-LFDA-SVM、S2DSSA-SVM也分别作为特征提取方法与S2DSSA-LFDA-SVM进行对比,从而验证S2DSSA的有效性。
首先,比较所有方法在不同比例训练样本数量下的分类结果。如图5所示,随着训练样本数量的增加,所有算法的分类精度都逐渐提高。此外,在所有的训练样本数量下,提出的S2DSSA-LFDA-SVM方法都取得了最高的分类精度,这证明了所提出算法的有效性。

图5 不同训练样本数量下的精度对比
为了进一步定量化评估S2DSSA-LFDA-SVM的有效性,对比了所有算法的每类详细精度以及运行效率,如表1~表4所示,相应的分类结果如图6、图7所示。

表1 Indian pines数据集的分类精度对比1(2%训练样本) %

续表
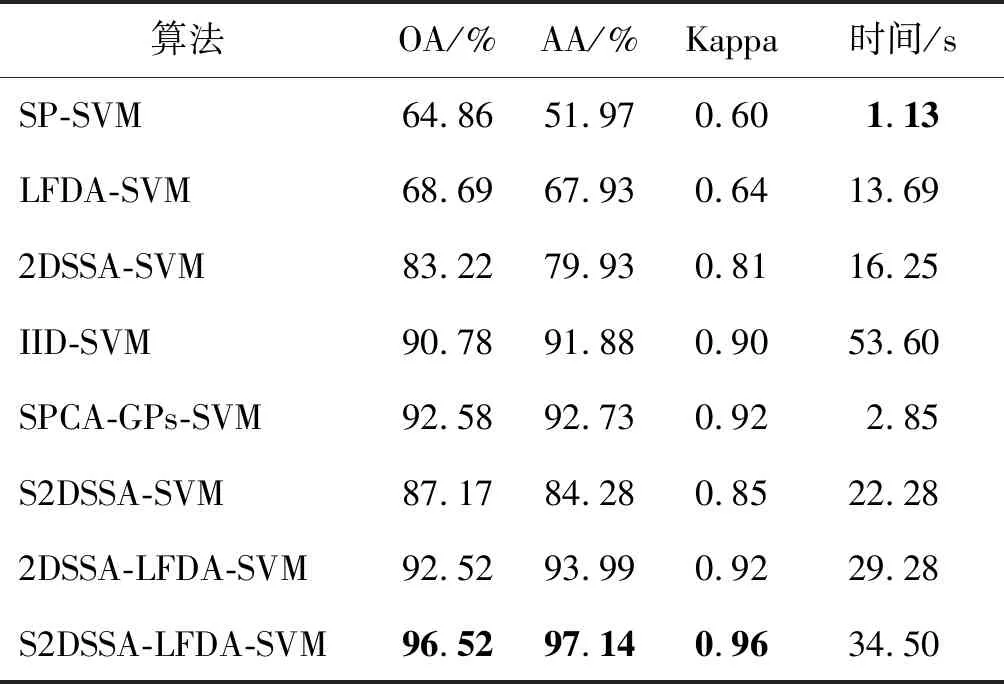
表2 Indian pines数据集的分类精度对比2(2%训练样本)
1)Indian pines数据。如表1、表2所示,在 OA、AA和Kappa 3个总体指标上,S2DSSA-LFDA-SVM都取得了最高的精度,并且在绝大多数的地物类别上都有不错的分类效果,其中玉米、燕麦和石铁堡3种地物的分类准确率达到100%。相比于基准方法SP-SVM,S2DSSA-LFDA-SVM的OA从64.86%提升到96.34%,比LFDA-SVM和2DSSA-SVM的OA分别高约27.83%和13.3%。S2DSSA相比于2DSSA,很好地考虑了地物的不同空间尺度特征,因而取得了优于后者的分类精度,OA提升了3.95%。与其他几种光谱-空间分类算法IID-SVM、SPCA-GPs-SVM和2DSSA-LFDA-SVM相比,S2DSSA-LFDA-SVM仍然有4%~6%等不同程度的提升,主要是因为后者提取了有效的空间尺度特征和光谱流形结构,增强了地物的可区分性。
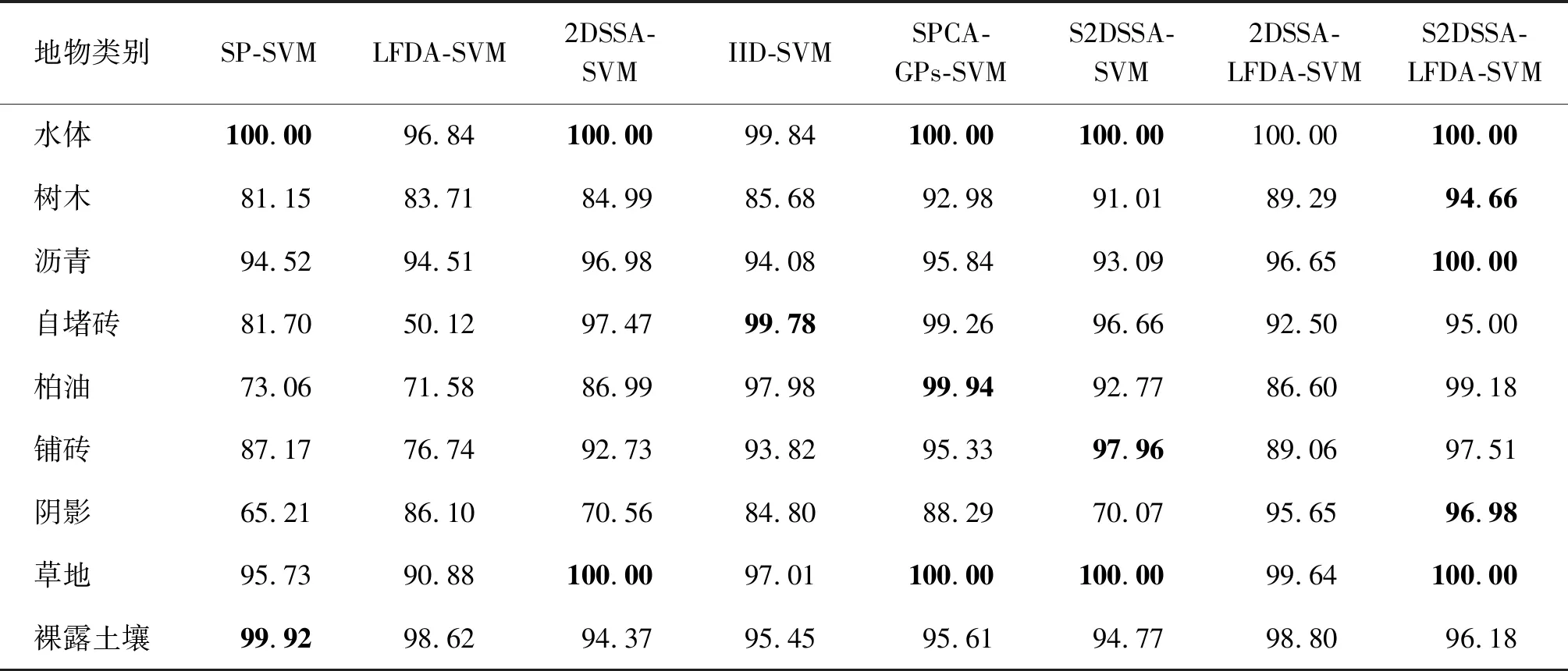
表3 Pavia centre数据集的分类精度对比1(0.3%训练样本) %

表4 Pavia centre数据集的分类精度对比2(0.3%训练样本)
根据图6所示,S2DSSA-LFDA-SVM的分类图也优于其他的对比算法。2DSSA-SVM利用空间信息减少了前者的点状误分类噪声,但存在一些小块或条状误分类,改进的S2DSSA-SVM利用了超像素的自适应能力,消除了条状分类噪声的现象。与其他3种光谱-空间方法相比,S2DSSA-LFDA-SVM在地物内部和边缘处均有较好的分类结果,这也体现了所提取的地物鉴别特征的有效性。
处理效率上,提出的S2DSSA比传统的2DSSA花费了更多的时间,主要原因在于2DSSA作用于每个波段的每个超像素区域,增加了运算量。此外,相比于其他光谱-空间方法,所提出的S2DSSA-LFDA-SVM的计算效率较低,低于SPCA-GPs-SVM和2DSSA-LFDA-SVM,仅优于IID-SVM,主要原因是IID通过优化能量函数,经多次迭代后才能获取影像的反射率成分,会花费较高的时间。此外,IID逐波段进行全图迭代,计算时间会随着影像尺寸的增大而增加。
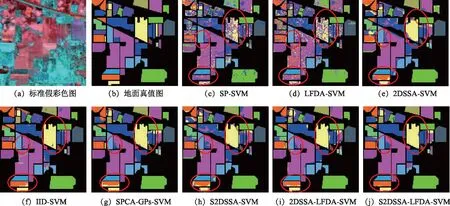
图6 Indian pines数据分类图

图7 Pavia centre数据分类图
2)Pavia centre数据。该数据集存在一些较小且不规则的地物类别,如树木、沼泽、道路等,给分类带来了一些困难。根据表3、表4的定量结果,提出的S2DSSA-LFDA-SVM依然延续了它的有效性,在OA、AA、Kappa和大部分的地类中均取得了最高的分类精度,包括沥青和草地两种地物分类准确率达到100%。S2DSSA-LFDA-SVM的OA比基准方法SP-SVM的OA提升12.98%,比传统的LFDA-SVM和2DSSA-SVM分别提升12.08%和8.75%。S2DSSA-SVM仍然优于2DSSA-SVM方法,这也证明了前者的鲁棒性。S2DSSA-LFDA-SVM仍然优于其他的光谱-空间分类方法,在OA上比IID-SVM、SPCA-GPs-SVM和2DSSA-LFDA-SVM分别提升4.43%,2.4%和2.78%。根据图7的分类图,S2DSSA-LFDA-SVM能够有效消除大面积地物内部的分类噪声,并且保留了不规则较小地物的形状和边缘,因而获得了与地面真值图最接近的分类结果图。此外,由于该影像数据尺寸较大,所提出的S2DSSA-LFDA-SVM方法效率较低,主要因为在S=50的情况下,每个超像素区域相对较大,S2DSSA对于每个超像素的处理时间增加。
3 讨论
本文提出的S2DSSA-LFDA-SVM结合了改进的S2DSSA和LFDA,能够有效地提取影像的光谱-空间特征,并且可以消除影像内部的诸多噪声。
S2DSSA充分考虑了影像地物的形状多样性,在每个超像素内部进行2DSSA空间特征提取,可以进一步提升地物内部像素的差异,提高一致性,不同地物的边缘处也得到增强,对于地物的区分有重要作用。LFDA作为一种流形学习方法,可以充分挖掘光谱维度的非线性结构,但是其单独作用效果受光谱异质性的限制。将其作用于匀质的S2DSSA空间特征,可以充分发挥LFDA的效果。
该方法仍然会存在一些不足。首先,超像素的分割无法完全适用于地物的形状结构,最优超像素个数因不同的影像而存在差异。此外,2DSSA使用了固定的窗口,这对于不同超像素区域的特征提取可能是不合适的。因而,未来我们将进一步开发自适应的S2DSSA来提取空间特征。
4 结束语
本文提出了一种结合改进的S2DSSA和LFDA的光谱-空间分类方法,用来表征高光谱影像的内在结构特征。二者的有效融合,可以有效地提取高光谱影像的空间和光谱特征,大幅提升后续的分类性能。相关结论主要如下。
1)本文提出的S2DSSA空间特征提取方法结合了超像素和2DSSA的优势,可以自适应地提取复杂多样的地物空间特征。实验结果证明,S2DSSA取得了比2DSSA更高的分类精度。
2)S2DSSA用于空间特征提取,LFDA用于挖掘光谱流形结构,二者的结合可以消除高光谱分类中“同物异谱、同谱异物”和“Hughes现象”,并且克服了单一方法在特征提取方面的有限性,提升了特征提取效果。
3)在两个经典高光谱数据集上的实验结果表明,本文方法提取的特征要远优于原始的高光谱数据,并且要好于其他先进的光谱-空间提取技术。此外,本文算法的参数较少,并且可以使用一套相同的参数处理不同的数据集,这使得该方法在实际的高光谱影像处理中有较大的应用潜力。
4)通过机器学习的方法可以提取高光谱数据的诸多特征,但是这些特征主要是浅层特征,蕴含的信息比较有限。深层的特征具有良好的不变性和抽象性,对于影像分类具有更大的意义。因此,下一步的工作主要是结合轻而小的深度学习模型,来挖掘高光谱内在结构的深层特征。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
导航定位学报(2022年5期)2022-10-13
机械工业标准化与质量(2022年8期)2022-10-09
北京航空航天大学学报(2022年8期)2022-08-31
农业工程学报(2022年8期)2022-08-08
黑龙江大学自然科学学报(2022年1期)2022-03-29
电机与控制学报(2018年9期)2018-05-14
计算机应用(2016年10期)2017-05-12
华人时刊(2016年16期)2016-04-05
职业·中旬(2009年12期)2009-06-01
