
基于融合模型的机器学习算法识别财务造假的研究
——以制造业为例
2022-10-17 08:32陈雨芳赵英杰吴昕劼
统计与管理 2022年7期
陈雨芳 赵英杰 吴昕劼
(长春大学 理学院应用统计系,吉林 长春 130024)
一、引言
近几年来,财务造假事件依然持高不下,操作手法更是多种多样。据统计展示,2020年国家共查办上市公司财务造假事件59起,约占信息处理总案件的1/4,为了保证市场的正常稳定发展,查除上市公司财务造假问题不可懈怠。面对上市公司多年的财务数据报告,如何通过合理数据指标筛选进行跟踪分析和研究,根据有效的理论构建良好的财务造假识别模型,从而避免投资者踩雷,并能有效的解决市场监督机构和广大投资者共同关心的问题。学者刘君和王理平(2006)[1],依据上市公财务数据,使用径向基概率神经网络算法构建财务造假识别模型。陈国欣、吕占甲等(2007)[2],使用逻辑回归模型,使用等同的造假与非造假上市公司的29个财务数据建模,结果显示Logistic回归的识别率为95%。此外,也有学者试图使用多种模型进行研究。李康(2011)[3],利用组合模型思想,构建逻辑回归模型和神经网络的组合预测模型。对上市公司财务数据进行建模,认为组合模型比单个模型识别效果更好。成雪娇(2018)[4],构建多个识别模型进行综合,使用投票法机制对上市公司是否造假进行决策。国外诸多学者也进行了研究,国外学者 Green(1997)[5],Fanning 和 Cogger(1998)[6],在此方面研究较早,使用神经网络DNN对上市公司财务数据进行实证分析,利用公司资产、坏账准备、盈利等指标构建财务造假识别模型。区别于使用单个模型,Ophir Gottlieb(2006)[7],以美国上市公司财务数据为研究对象,分别构建Logistic回归、SVM和贝叶斯模型,对比得出Logistic回归和SVM 效果较好。P.Ravisankar等人(2010)[8],对比了多种数据挖掘方法,最终发现概率神经网络(PNN)构建的模型识别效果最好等。
基于模型组合这一个研究思路,本文在构建公司财务造假识别模型中,不仅包含有常用的机器学习模型,比如RL、DT等模型,也使用了比较火热的集成学习算法XGBoost进行建模,同时使用Voting和Stacking算法进行模型融合,以模型的AUC值和Accuracy作为评估指标,对比不同机制下模型的准确率,最终发现使用Stacking融合得到的模型效果最好,并以此作为最终预测模型。本文通过上市公司财务造假识别的研究,使得投资者识别了财务造假的公司,保障了投资者的权益,避免“黑天鹅”事件的发生,降低投资者的盲目性。同时也能给监管部门提供相应建议,给出上市公司在财务造假上更加倾向的财物指标作为重要核对对象。

图1:文章整体框架图
二、数据处理及特征工程
(一)数据样本选取与预处理
本文实验原始数据源于第九届泰迪杯竞赛中披露的11310组真实财务报表数据,包含了363项数据指标,其中前10个指标为无关变量指标,因此真实有用的财务数据指标共353项。选取0(财务正常)和1(财务造假)作为目标变量。
在财务数据的处理过程中,参考资料得知,现有的填补方法包括常值插法、热卡插值法、回归插值法等缺失值填补法都存在一定不足,比如使用均值填补的时候会改变数据的原始分布,造成一定的抽样误差,因为不同公司之间规模大小不同,财务情况也不会完全相同,所以使用均值填充的时候会损失一部分信息,不能很好地表示每个公司之间的差别,此外公司间的财务结算标准可能存在差异,均值填充不能很好地体现出缺失值的不确定性。本文做了缺失值填补效果的对比性分析,通过在正常数据中随机取点,记录下非空点值。将该位置重新赋值为空,通过多种缺失值填补方法,计算扣取点的真实值与填补值之间的误差,对比MSE和MAE的结果。结果如下表1所示,认为随机森林填补缺失值的方法最为有效。基于以上考虑,本次填补缺失值我们选择的是机器学习中的随机森林算法。

表1:各方法缺失值填充效果对比表
建立模型之前需要进行数据预处理,对于缺失比例过多的指标,如果选择使用小部分已知数据去填补大部分未知的数据,可能会造成填补的数据偏离数据的真实情况,对模型预测产生干扰,因此删除是比较可靠的方法。本文对指标数据缺失大于50%的指标选择剔除,对于缺失数量较少的指标,经过对比填充效果,选择使用随机森林进行缺失值填补,最终得到建模数据集。
(二)财务指标选取
对于模型来说,指标分为相关指标、无关指标、冗余指标,因此我们需要对其进行指标筛选工作,剔除一部分无关和冗余的特征,留下含有较大信息量的相关特征。由于提供的财务数据中财务指标比较齐全,包含了大部分常见的财务特征,因此本文不选择使用特征构造的方法,认为提供的特征能很好识别财务造假情况。剔除冗余和不相关的特征能够使得模型更加精确,同时在模型训练过程中也可以更好更快发现数据中隐含的信息和规律。指标选择的方法有很多,比如:嵌入式(embedding)、包裹式(wrapper)、过滤式(filter)等。
在使用Lasso算法筛选变量的时候,得到的变量只有三个,使用三个变量进行建模会损失很多信息,因此Lasso筛选结果仅作为参考。然后使用正态性检验(KS检验和W检验)检测各指标是否服从正态分布,结果显示大部分指标是不符从正态分布的。接着使用曼惠特尼非参数方法,筛选出在造假数据和非造假数据中存在显著区别的指标变量,一共47个指标。接着使用随机森林进行进一步指标筛选,根据各个指标对随机森林每一棵树的贡献程度,得到占据总得分80%的指标作为建模指标,一共筛选出29个指标如表2所示。

表2:最终筛选财务指标
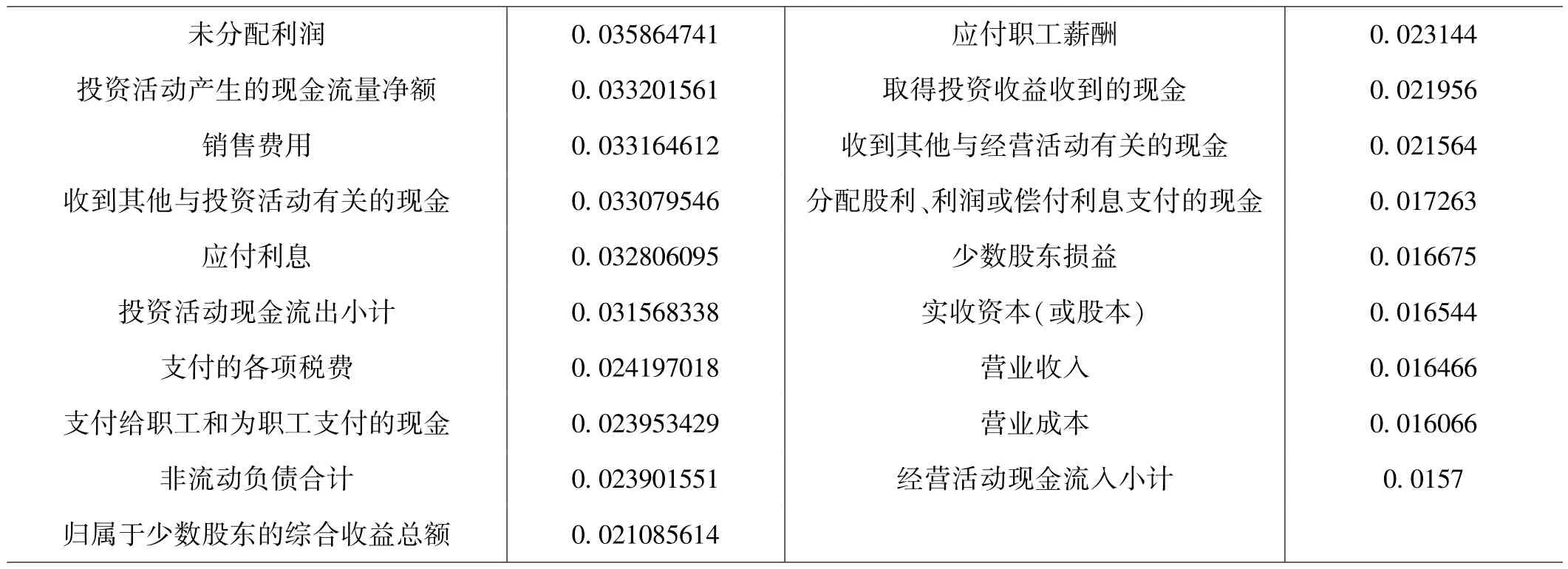
未分配利润 0.035864741 应付职工薪酬 0.023144投资活动产生的现金流量净额 0.033201561 取得投资收益收到的现金 0.021956销售费用 0.033164612 收到其他与经营活动有关的现金 0.021564收到其他与投资活动有关的现金 0.033079546 分配股利、利润或偿付利息支付的现金 0.017263应付利息 0.032806095 少数股东损益 0.016675投资活动现金流出小计 0.031568338 实收资本(或股本) 0.016544支付的各项税费 0.024197018 营业收入 0.016466支付给职工和为职工支付的现金 0.023953429 营业成本 0.016066非流动负债合计 0.023901551 经营活动现金流入小计 0.0157归属于少数股东的综合收益总额 0.021085614
(三)特征筛选效果检验
SHAP主要作用是量化每个特征对模型所作预测的贡献情况,主要思想是博弈论中Shapley值的方法,通过计算每个特征对prediction的贡献,对模型判断结果进行解释,该方法的整体框架如图2所示。
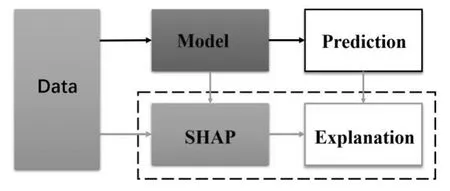
图2:SHAP框架图
目前多数解释机器学习模型的都是基于简单模型(比如线性回归模型),而一些复杂常用的机器学习模型是不容易理解的。对于树模型,SHAP使用Shapley值作为一种可加特征归因方法,并满足三大属性:局部准确性(Local accuracy),一致性(Consistency)和缺失性(Missingness)。随机森林模型衡量特征重要性的指标有信息增益(Gain)、分裂次数(Weight)、节点样本量(Cover)。不同的重要特征指标选择会导致特征重要性排序不一致,虽然通过重要性排序可以基本看出特征维度在模型中要重要性。但该指标没有给出重要性的积极或负向影响,无法判断特征与最终预测结果的关系是如何的。SHAP值则弥补了目前树模型算法可解释性的不足,很好的展示了变量对模型起到的正负性影响。
首先对一个label为1的样本(即存在财务造假的数据)进行SHAP值可视化分析,结果图3所示(黑白展示下,SHAP值可视化图片做了特殊处理,便于查看)。

图3:label为1的样本SHAP值可视化
接着对label为0的某一样本进行SHAP值可视化分析,结果如图4所示。

图4:label为0的样本SHAP值可视化
上图4中右侧浅色斜线部分表示该特征的贡献是负向的,左侧深色部分表示该特征那个的贡献是正向的,而宽度表示的是该特征对于目标变量的影响程度,宽度越宽,说明该特征的影响越大。从两个图中可以看出,在图3中可以看出可供出售金融资产指标(AVAIL_FOR_SALE_FA)为深色正向排在最前面,而且长度最长,说明在造假公司的数据中可供出售金融资产特征起到的作用是最大的,说明该特征对于公司造假具有很强的识别能力。两图对比展示了特征在非造假公司的数据与造假公司作用的区别,因此从结果上可以看出使用非参数方法+随机森林的组合方法筛选得到的特征具有很强的财务造假识别能力。
(四)数据不平衡处理
由于筛选出的变量数据中存在严重的数据不平衡问题,其中造假公司数据与非造假公司的比例约为250∶1。如果未处理该问题,训练出的模型就会倾向于样本量较多的数据,这样得到的模型结果偏差较大甚至毫无意义。因此在建模之前使用SMOTE算法对少数类样本重抽样,使得造假数据和非造假数据的比例为1∶1,避免机器学习模型对少数类样本欠学习。
SMOTE算法主要步骤如下:
1、使用欧式距离计算少数类(需要采样的类Smin)中每个样本xi到该类中其他样本的距离,得出k个最近位置。
2、根据设定采样比例N确定不平衡样本需采样的数量,接着从k个最近位置中随机选择若干个样本。
3、根据随机选择出的紧邻样本xj,与原样本x计算构建新样本。
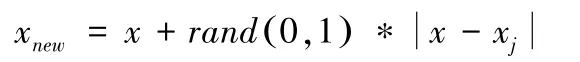
三、造假识别模型建立及优化
(一)财务造假模型选择及评估指标
对财务造假的研究过程中发现,财务造假的重要影响因素可以归纳为财务指标因素和非财务指标因素两种,而财务因素大致又可以分为偿债能力,成长能力,盈利能力,运营能力以及现金流量等方面,这些因素在一定程度上可以反映出公司的财务和经营状况。本文选择XGBoost模型、逻辑回归模型(Logistic Regression)以及决策树模型(Decision Tree)对上述指标进行深入挖掘分析,建立财务造假识别模型,以下是对这三种机器学习模型以及模型评价指标进行简要说明。
1、决策树模型(DT)
决策树是一种具有分类与回归作用的算法,本文建立的是财务识别分类算法,因此主要讨论的是分类树。分类决策树是一种描述分类的树形结构,旨在基于训练数据学习经验对目标分类做出判断。决策树从根节点开始,在生长过程中需要选择合适的分裂节点,最终得到一棵完整树模型。常用的选择标准如下:
(1)纯度。纯度可以理解为数据之间的相似度,纯度越高作分裂节点越好;
(2)信息熵。信息论中表示信息的不确定度,定义为:
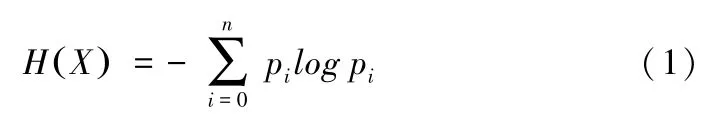
(3)信息增益。表示在得知X信息后Y信息不确定性的减少程度,其中特征A对集合D的信息增益g(D,A) =H(D)-H(D|A),其中H(D)表示集合D的信息熵,H(D|A)表示为特征A信息已知后集合D的经验条件熵。
(4)信息增益比。为改正信息增益会偏重选择分类较多的特征作为分裂节点,使用带来更大信息增益比值的特征进行分裂更加合理,即:
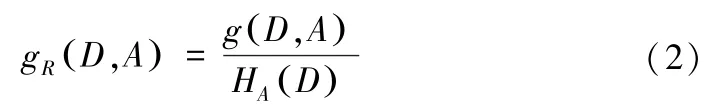
(5)基尼指数。描述数据的纯度,集合D的基尼指数为:
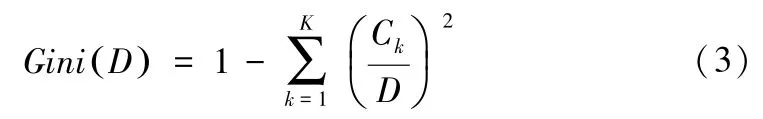
其中属于第k类的数据子集用CK表示,K表示类的数量。得到的基尼指数值越大,样本集合的不确定性就越大。
本文使用基尼指数的方式利用上市公司财务数据建立CART分类决策树,使用预剪枝的方式对完整决策树进行修改,减少过拟合情况的发生,更大程度提升模型的泛化能力。
2、逻辑回归模型(LR)
逻辑回归模型中虽然带有回归二字,却是经典的分类模型。二分类问题上,Logistic通过对特征数据压缩至0和1之间达到分类的效果,模型的条件概率分布为:
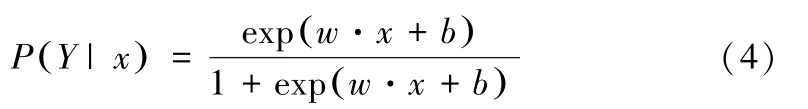
模型使用极大似然估计法来求得w参数,对应似然函数为:

对L(w)求极大值,得到w值的估计。
3、XGBoost模型
XGBoost模型是一种集成模型,通过将多个基学习器(比如单棵决策树)组合成一个各项性能都有所提升的强学习器。XGBoost的思想是一种提升树模型,通过前向分布算法,每次拟合前一个树的残差学习K棵决策树的加法模型,并通过贪心算法找到局部的最优解。
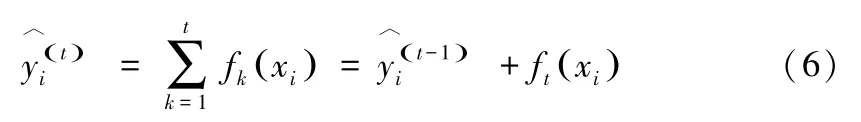
每一次迭代中,寻找使整体损失值下降最大的特征建树,因此目标函数可以写成:

接着使用泰勒展开对目标参数求取近似值:
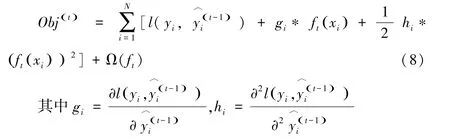
树模型中复杂度可以使用树的深度、中间节点数量、弱学习器的个数等衡量。XGBoost中加入了L2正则项来防止模型过拟合,假设一棵树中包含T个叶子节点,每个叶子节点上的样本权重为ωj,则模型的复杂度Ω(f)定义为:
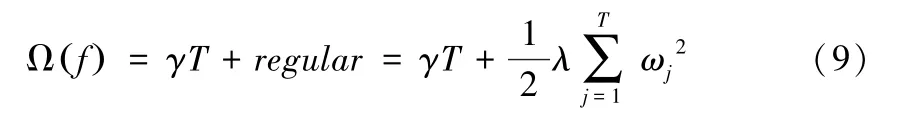
其中复杂度的第一部分控制着树结构,第二部分为正则项,可以通过判断叶子节点的数量T来判断树的深度,γ为自定义控制叶子数量的参数。带入正则项后,最终XGBoost的目标函数为:
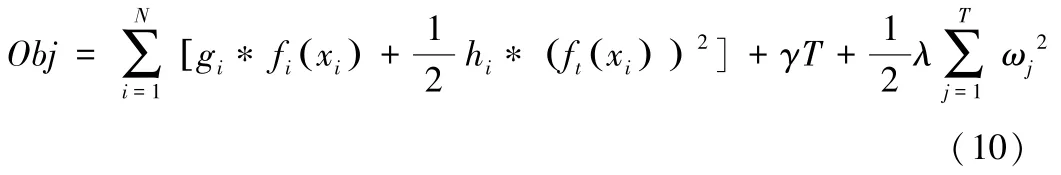
4、Voting算法
投票法,常用的有加权投票法和简单投票法,通过加权重的方式将多个模型得到的结果进行投票表决,票数多的结果获胜,避免了单一模型的精度不足问题,同时一定程度可以防止过拟合的发生。
5、Stacking算法
Stacking是对训练数据建立单学习器预测结果的二次学习,使用真实结果与单学习器的预测结果训练一个相对简单的学习器,对测试数据输出进行整合。
6、模型评估指标
(1)混淆矩阵。展示了数据的真实类别与预测结果之间的关系。
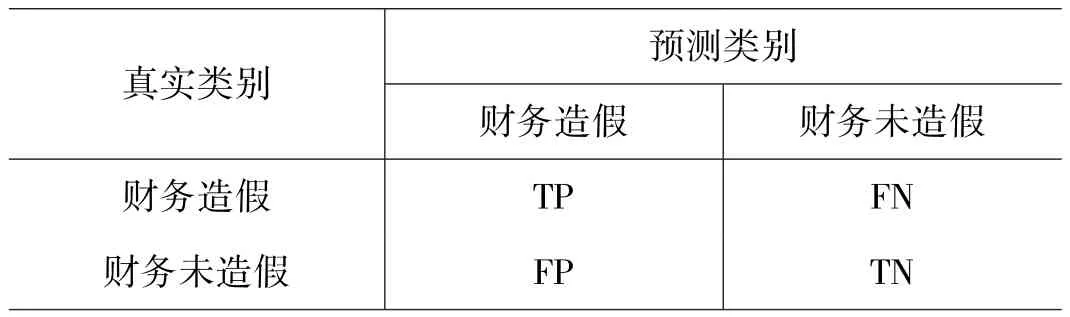
表3:混淆矩阵
(2)识别准确率(Accuracy)
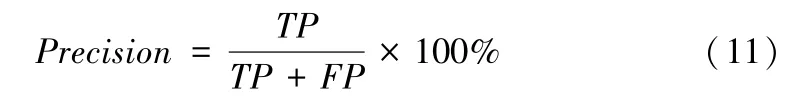
(3)识别反馈率(Recall)
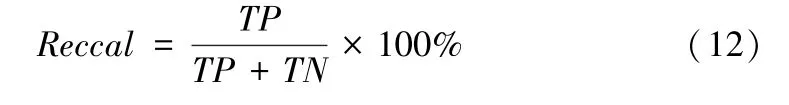
(4)ROC曲线。受试者工作特性(Receiver Operating Characteristic ROC)曲线是由横轴为假正例率与纵轴为真正例率构成的曲线图,可以反映出分类模型的效果,是二分类问题的常用评价指标。其中ROC曲线下的面积大小就是AUC值,反映分类器正确分类的统计概率,AUC值越接近1表明模型分类效果越好。

(二)模型建立
使用 XGBoost模型、Logistic模型、决策树模型、Voting和Stacking等方法结合筛选出来的变量建立财务造假识别模型,经过网格搜索和交叉验证等方法得到性能最优的模型,各个模型在测试集上的结果如下表4所示。
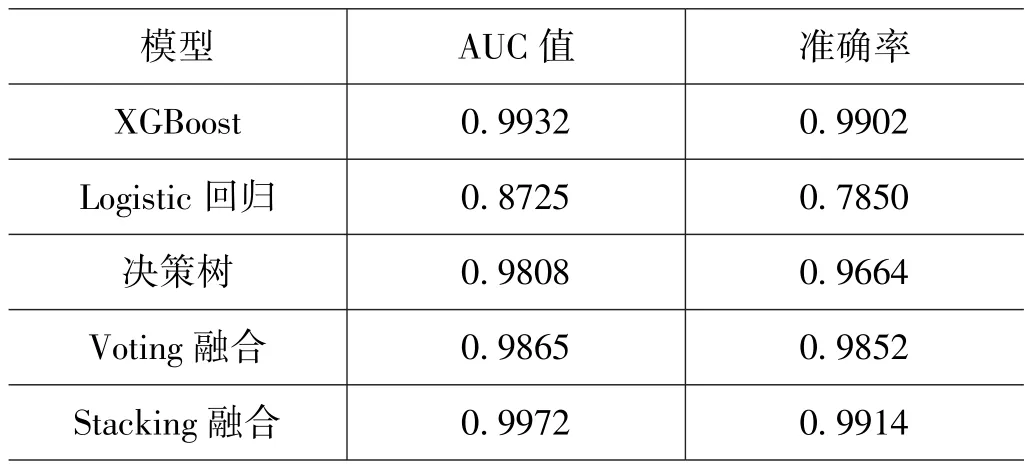
表4:单个模型和stacking融合效果对比
图5:Logistic模型的ROC曲线
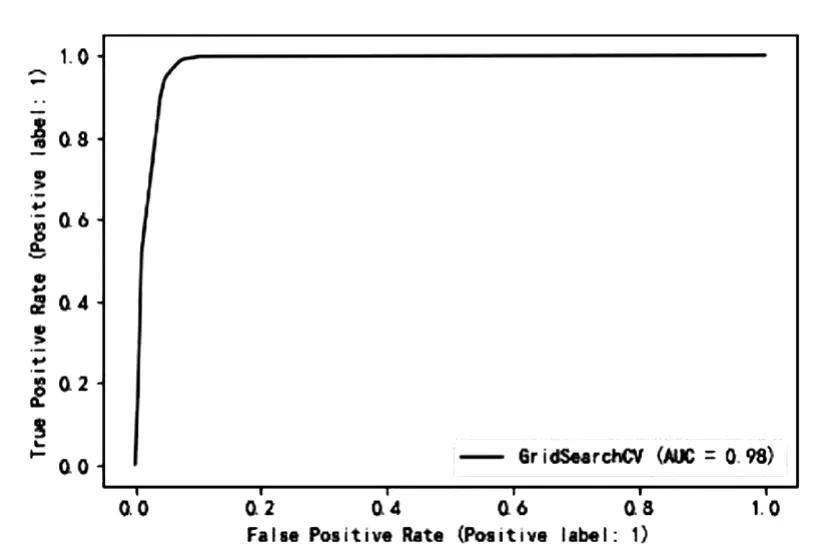
图6:决策树模型的ROC曲线
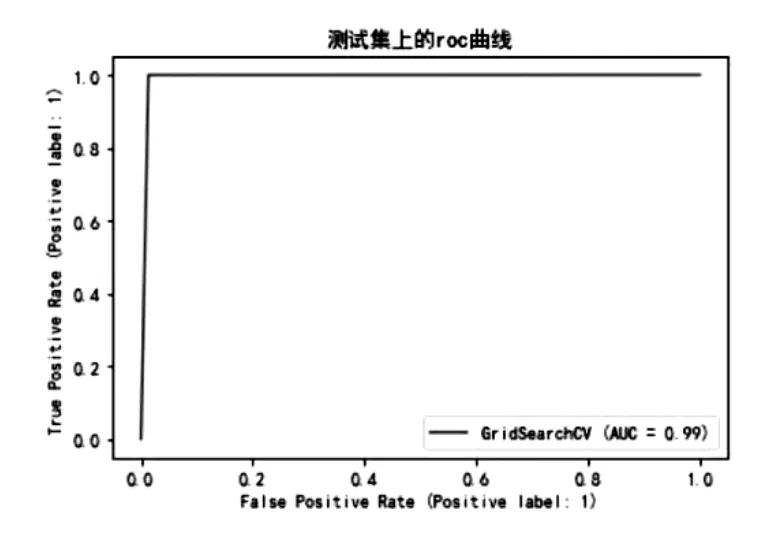
图7:XGBoost模型的ROC曲线
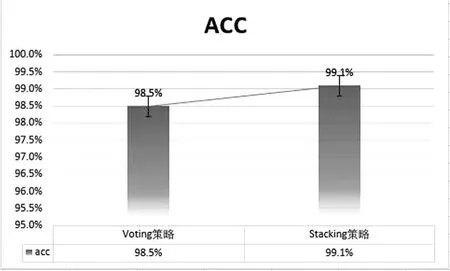
图8:Voting和Stacking效果对比图
通过对比模型效果,可以看出单个模型中XGBoost模型得到的效果很好,AUC的值和准确率都很高,表示模型可以很好地学习到数据中的规律。虽然XGBoost中加入了正则项来控制模型的过拟合,但是模型还是存在一定程度上的过拟合,其他单个模型都有各自的优点,得到的预测效果也不尽相同。对比与单个模型,Voting融合得到的结果相较于全部模型平均来说会更好一点,在预测精度方面得到了一定的提高。表现效果最好的是Stacking融合得到的结果,通过二次建模,将单个模型的预测结果进行整合,最终得到更加准确的结果。
四、结论
本文使用制造业上市公司财务数据结合机器学习算法及模型融合思想,建立了财务造假识别模型,主要目的是构建最优的分类预测模型来识别制造业中上市公司的财务数据中是否存在造假情况。通过对比指标筛选的结果可以看出,财务是否造假与支付其他与筹资活动有关的现金、投资支付的现金、收到的税费返还、营业外支出、未分配利润、应付利息、投资活动现金流出小计、支付的各项税费、应付职工薪酬、少数股东损益等等有着显著关系,在判断是否存在财务造假方面具有较强区分能力。本文在识别模型选取上,使用XGBoost、决策树、Logistics回归这三种建模方法。考虑到单模型的鲁棒性、识别能力和泛化能力可能存在不足,本文选择使用组合模型的思想,结合上述三种模型采用Voting投票方法和Stacking层叠方法进行建模,这样建立的模型较为稳定,不存在严重过拟合且效果较好。结果显示Voting算法得到的ACC为98.5%,而Stacking得到的ACC为99.1%,Stacking策略的效果更好,对于财务造假的识别能力更强。综上所述,本文通过筛选影响指标构建融合的上市公司财务造假识别模型具有较高的识别准确性及现实意义,在能够给投资者提供投资参考的同时,也能给监管者提出相关建议,使得公司财务数据得到更好地监管。
猜你喜欢
科学与信息化(2019年28期)2019-10-21
领导决策信息(2018年16期)2018-09-27
证券市场红周刊(2018年33期)2018-05-14
证券市场红周刊(2018年10期)2018-05-14
证券市场红周刊(2018年5期)2018-05-14
证券市场红周刊(2018年27期)2018-05-14
人大建设(2017年10期)2018-01-23
数学学习与研究(2017年3期)2017-03-09
科学与财富(2016年32期)2017-03-04
决策与信息·下旬刊(2013年1期)2013-03-11
