
基于聚类和随机森林回归的超大型建筑能耗负荷预测模型研究
2022-10-18 03:35叶从周,肖朋林,秦俊等
绿色建筑 2022年5期
我国随着节能减排工作的推进,碳达峰和碳中和概念的提出,对公共建筑能耗约束和能效等级提出了更高的要求,低碳城区与绿色建筑的建设进程将以更快的速度推进。超高层超大型建筑是城市能耗大户,为了实现低碳目标,在其建设与运行过程中,将会使用更多类型的分布式能源,这使得多种能源的调度与控制,尤其是对于空调的控制,将成为一大难题。
根据《2020 年上海市国家机关办公建筑和大型公共建筑能耗监测及分析报告》,主要类型建筑 2020 年分项用电占比来看,照明与插座用电、空调用电为主要用电分项,各类型建筑这两项之和均超过 70%。在超高层超大型建筑中,空调用电也是主要耗能之一。所以通过预测供暖空调负荷,指导冷热源的优化运行,从而提高空调运行效率,能够有效节约能源、降低运行成本。
本文主要研究如何通过混合多种机器学习算法,包括聚类与回归算法等,提高建筑能耗预测建模准确性和有效性,并对能耗预测的实际应用提供帮助。
1 能耗预测模型研究现状
目前,能耗预测主要有 2 种方式,即物理模拟和数据驱动。数据驱动建模是本文研究的重点。数据驱动,一般指的是将收集到的建筑数据作为输入,对应的历史能耗数据作为输出,训练得到能耗预测模型[1]。数据驱动建模的方式主要有回归模型、时间序列模型、机器学习算法模型等[2]。其中,机器学习算法在建筑能耗建模的应用主要包括支持向量机(SVM)、人工神经网络(ANN)、决策树和其他统计算法[3]。如肖冉等[4]提出一种基于支持向量机的办公建筑逐时能耗预测方法,并引入了网格搜索方法优化模型超参数,体现了建筑的运行波动。杨丽娜等[5]提出一种结合神经网络(artificial neural network)和GRU的网络模型(ANNGRU)来预测数据中心能耗,具有很高的精度。
除了在不同算法上有各种研究以外,针对不同的建筑类型以及不同的时间粒度也有各类研究。如周芮锦等[6]基于时间序列分析,将建筑逐月能耗的 4 个主要影响因子:逐月积温值、逐月相对湿度平均值、逐月工作日天数及逐月非工作日天数引入建筑能耗预测模型,对逐月数据进行预测。高英博等[7]利用 LSTM 模型对上海某酒店建筑逐时能耗数据进行预测,并以此为依据对能耗数据进行异常识别。
以上种种在建筑能耗领域目前已得到广泛的研究,通过结合建筑运行数据和天气数据,预测建筑未来的能耗数据,有一定的预测准确性。但是,许多算法当建筑处于运行模式切换时,预测的准确性会下降,同时对于不同维度的数据需要做多步预处理和超参设置,而在超大型建筑中,往往存在不同区域的空调设备运行模式不同,造成了工程化的复杂性。本文为了解决该问题进行了以下几个试验。
2 基于随机森林回归的能耗预测模型
随机森林回归是一种基于决策树的集成学习算法。其核心思想是一个由多颗随机生成的决策树组成的森林,每一个数据输入后,由各个不相关的决策树做分类或者回归,并投票决定该数据该如何分类或者回归。
随机森林回归主要用到的决策树算法是 C A R T (classification and regression tree)算法。单独的决策树算法往往会在训练数据上表现良好,但在训练数据和实际应用中效果很差,其由于过拟合的缺点,使得模型不具有普遍性和工程上的应用能力。
为了弥补决策树的不足,随机森林引入了随机采样的概念,即在森林中的决策树在训练中得到的数据都是全局样本中的一部分,从而避免了过拟合,并且可以通过算法本身进行特征选择,不需要对数据进行规范化,相比于 SVM、ANN 等算法,工程化更简单,容易并行化,处理更大量的数据。
选取温度、湿度、是否为工作日以及小时点和相同工作状态下前一天同一时间点的能耗值作为输入变量,该时间点的能耗值作为输出变量,并对比不同的超参构建模型,试验不同大小和深度的随机森林对能耗预测模型的影响。
试验设置决策树深度分别为n=3、5 以及 7,对比不同超参数下,评估参数的值。评估参数选取R2与 mse(均方误差)。R2是用来评价预测值与真实值的拟合程度好坏,越接近 1 表示拟合度越高;均方误差 mse 是预测值与真实值之差的平方和的平均值,值越小代表预测值与真实值差距越小。
同时将连续的能耗数据分段截取一部分作为训练数据,另外一部分作为测试数据,比例为 7∶3。
评估参数选取R2与 mse,测试样本整体R2与 mse 见表 1 。
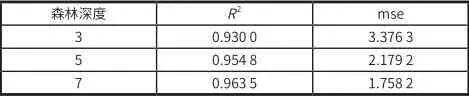
表1 预测值与真实值的拟合度及均方误差
由试验结果可知,随机森林越复杂,预测效果越佳。然而,仔细观察换季时的预测准确性,当数据处于不同季度之间时,误差较大。
季度交错时间段内的预测准确率明显下降。当决策树深度为 7 时,取 8 月、9 月数据计算R2与 mse 值,分别为 0.898 6 和 2.849 0,与整体相比,下降了 0.065 与 62%,有明显差距。
考虑原因,不同季度的相同时间段能耗消耗规律不同,当处于同一模型下训练时,随机森林无法及时分辨不同的空调运行模式,为此需要引入聚类对不同季度的能耗曲线进行分类和建模。
3 基于聚类的能耗曲线建模
聚类算法在建筑能耗建模中的应用主要指的是时间序列聚类,时间序列聚类在建筑节能领域的主要应用有 3 种:识别时间序列数据中的动态变化、预测与推荐以及模式识别。在建筑用能建模领域,基于时间序列聚类分析的主要研究有:建筑用能的模式识别、需求侧管理、建筑用能预测、建筑用能异常数据检测。
K-means 聚类作为最著名的聚类算法之一,在时间序列领域应用广泛。其原理为通过将数据分为K个簇中,使得簇内的各个数据到中心点的距离差平方和最小。在能耗数据的聚类中计算距离的方式,在本研究中主要采用欧几里得距离,K值设置为 6,理由如下。
(1)空调用电受季节因素的影响较大,可以分为过渡季,供热季,供冷季,同时工作日和节假日时的空调运行同样有很大的区分。所以,试验中将K设置为 6,即(过渡季,供热季,供冷季)×(工作日,节假日)。
(2)超大型建筑空调能耗时序数据与空调设备的启停时间有着强相关性。因此,在计算相似性时需要考虑建筑能耗曲线在相同时间点的实际物理意义,计算各条由 24 个点/d 组成的能耗曲线相互之间相似度,得到每个簇的中心,使得簇心曲线上的每个点有其实际的物理意义,为设备运行策略优化提供统计学意义上的支撑。
研究中混合了 K-means 和 DBSCAN 2 个聚类算法,对能耗曲线进行清洗以及分类。试验中,将某电表一整年的小时总能耗数据划分为一个 365×24 的矩阵,以天为单位,一天 24 h 组成一条时间序列曲线;通过混合多种聚类算法清洗数据,剔除异常曲线;将清洗后数据进行二次聚类。聚类结果如图1 所示。
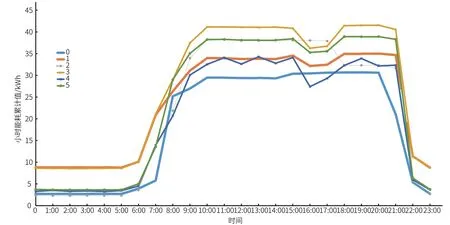
图1 某空调回路聚类簇中心曲线
从表2 统计结果可知,表2 的运行结果与季度相关性高,而与是否为工作日、节假日相关性低。为了能够更好区分出空调运行的能耗规律,将能耗数据按照工作日、节假日重新聚类,得出结果如图2 所示。

表2 各类别天数所处月份及所处工作日双休日天数统计表 单位:d

图2 某空调回路工作日、节假日聚类簇中心曲线
从统计结果表3,可以发现每一类簇中心曲线都分别代表了过渡季、制冷季和供热季在 0:00-6:00 时的非工作时间段以及 6:00-18:00 时的工作时间段上用能规律。由此可知该空调在不同季度大致的用能规律,并以此为根据对不同季度的能耗数据进行分类。

表3 工作日各类别天数所处月份及所处工作日双休日天数统计表 单位:d
4 混合聚类与随机森林回归的能耗预测模型
混合 K-means 聚类与随机森林回归两种算法,该思想主要针对超大型建筑不同区域和季节运行规律区别很大,需要针对不同时间段和用能区域来进行建模的困难,找到不同区域和时间段建模的理论依据。
经过以上聚类算法对能耗数据处理的试验,可以得知聚类算法能够对不同季度的能耗数据进行分类,并在分类之后可以统计各个分类的所处于的季节及相关时间段,从而找到不同区域的空调设备切换启停时间和运行模式的时间节点,以此作为划分预测模型的分割点,即不同区域空调设备该依据哪个时间段作为一种运行模式的训练数据,形成预测模型,并在一年中不同区域空调设备在不同季节中何时采用何种预测模型进行预测的理论依据。
首先尝试对该楼宇不同区域的空调设备能耗进行建模。试验结果见表4。
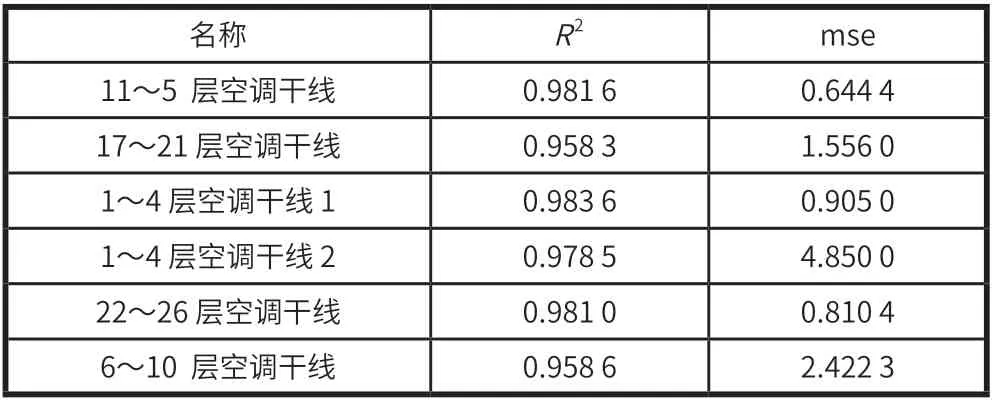
表4 不同区域的空调设备能耗预测值与真实值的拟合度及均方误差
由试验可知,即使设置相同超参,不同区域空调设备能耗数据对随机森林回归的性能依然表现良好,具有普适性,且不需要做任何的预处理。
之后,对某电表一整年的小时总能耗数据进行聚类,然后统计其各类曲线在各月分布情况,发现其空调运行模式切换主要在工作日 8月底9月初,符合之前试验准确率下降的数据段范围。找到时间划分点后,对不同的空调运行模式下的能耗建模,即7~8月底,采用一个训练模型,8~9 月采用第二个训练模型,混合模型后得到新的预测。
具体对应月份数据(7~9月)预测效果对比见表 。

表5 随机森林与混合算法的拟合度及均方误差对比
可见经过多步处理后季节交换时段的能耗预测准确性显著提高,较之前整体分别提高了 0.05 和 23.5%。
5 结 语
超大型建筑能耗的预测准确性的提高对相应国家的节能减排能够起重要的作用。尤其是换季时期的能耗预测准确性的提高能够帮助业主及时发现空调运行的异常。
本文采用了随机森林回归和 K-means 聚类 2 种算法,对超大型建筑的空调能耗预测进行了研究。本文主要结论如下。
(1)随机森林回归相较于 SVR、ANN 等算法主要优点在于不需要作特别的数据预处理,一样能得到较高的预测准确性,因此具有很好的工程化优势。在面对不同设备的模型训练时,不需要做任何的超参设置,预测性能不受影响。因此,不必为每一个设备做单独的算法模型的调试,能够极大地发挥出数据驱动建模时的便利性,并保证预测准确性。
(2)同时,与大部分拟合算法一样,无法应对换季时期的预测性能下降的问题,一旦空调运行规律改变,将会对预测的准确性有很大的负面影响。
(3)为了能够让模型及时相应天气和节假日造成的空调运行规律改变,研究通过对设备能耗的历史数据进行聚类,对聚类结果进行统计分析,可以发现不同季度空调设备运行规律区分度高,因此可以对不同季度空调设备能耗进行分别建模。
(4)在对设备能耗的历史数据进行聚类,从而合理划分运行规律改变的时间点,对不同运行规律采取不同的模型来进行训练和测试,有效地提高了换季时期整体模型的预测准确率。
猜你喜欢
昆钢科技(2022年2期)2022-07-08
当代水产(2021年10期)2022-01-12
建材发展导向(2021年23期)2021-03-08
铁道通信信号(2019年6期)2019-10-08
成都信息工程大学学报(2019年3期)2019-09-25
华人时刊(2018年15期)2018-11-10
电子制作(2018年16期)2018-09-26
雷达学报(2017年6期)2017-03-26
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
互联网天地(2016年1期)2016-05-04
