
睡眠呼吸暂停综合征患者的睡眠分期算法研究
2022-10-19 01:39鲁柯柯张建保闫相国
中国生物医学工程学报 2022年3期
鲁柯柯 祁 霞 张建保 王 刚#* 闫相国#*
1(生物医学信息工程教育部重点实验室,西安交通大学生命科学与技术学院, 健康与康复科学研究所,西安 710049)2(国家医疗保健器具工程技术研究中心, 广州 510500)3(神经功能信息学与康复工程民政部重点实验室,西安 710049)
引言
睡眠呼吸暂停综合征(sleep apnea syndrome,SAS)是发生在睡眠过程中呼吸出现短暂停止现象的一种睡眠障碍性疾病[1],与高血压、冠心病以及心律失常等心血管疾病密切相关[2]。 临床上通过睡眠分期来分析SAS 患者的睡眠结构和睡眠质量,为诊断睡眠疾病提供有效信息。
临床按照美国睡眠医学学会(The American Academy of Sleep Medicine,AASM)标准和多导睡眠图(polysomnography,PSG),以30 s 为间隔将夜间睡眠活动划分为5 个阶段:清醒(wake,W)期、非快速眼动(non-rapid eye movement,NREM)Ⅰ(N1)期、Ⅱ(N2) 期、 Ⅲ(N3) 期和快速眼动(rapid eye movement,REM)期,其中N1 期、N2 期统称为浅睡(light sleep,LS)期,N1 期、N2 期和N3 期统称为NREM 期[3]。 SAS 患者相比于健康人N3 期和REM期在整晚睡眠中占比较低,且睡眠呼吸暂停主要发生在N3 期[4]。 因此针对SAS 患者通过睡眠分期分析其睡眠结构具有重要意义。
PSG 作为临床诊断睡眠疾病和睡眠分期的金标准,记录了夜间睡眠脑电图(electroencephalogram, EEG)、 眼电图( electro-Oculogram,EOG)、心电图(electrocardiography,ECG)等多种生理信号[5],然而因其价格昂贵及受试者需在专业的睡眠实验室佩戴大量传感器,很难适用于普通的家庭以及病房监护。 因此,提出一种能够利用便于检测的生理信号进行自动睡眠分期的方法具有实际应用价值。
心率和呼吸信号与睡眠阶段高度相关[6-7],并且测量技术较为成熟。 Wang 等[8]从7 名SAS 患者的ECG 信号中以每5 min 为间隔提取时域、频域和非线性特征共24 个,使用序列前向选择(sequential forward seelction,SFS)进行特征选择,最后使用基于决策树的支持向量机(decision-tree-based support vector machines,DTB-SVM) 分类器实现W-REMNREM 三分类的睡眠分期任务,采用留一交叉验证法测试得到73.51%的平均准确率。 Willemen 等[9]提取了25 例SAS 患者心电、呼吸信号的时域及频域特征,使用线性判别分析(linear discriminant analysis,LDA)在W-REM-NREM 三分类睡眠分期任务上获得了70%的准确率,Cohen's Kappa 系数为0.41。 黄文汉等[10]通过提取23 例SAS 患者心电和呼吸信号的时域特征、频域特征和耦合特征,使用随机森林(random forest,RF)在W-REM-NREM 三分类睡眠分期任务上获得了71.9%的准确率(Cohen's Kappa =0.36)。
上述基于心电和呼吸信号的自动睡眠分期研究取得了较好的分期效果,但都是以三分类为主,应用范围和场景具有较大局限性。 而且基于小规模数据集训练测试的方法或模型往往缺乏一定的泛化能力,当用于其它数据集时,准确率可能只会下降10%左右,而Cohen's Kappa 系数却会下降20%左右[11]。 同时,睡眠是一个结构化过程,不同的睡眠阶段之间彼此紧密联系,但是已有的针对SAS 患者进行睡眠分期的研究忽略了时间维度信息。 另外值得注意的是,SAS 严重影响心电信号的稳定性,睡眠分期数据较普通人而言更加不连续和不平衡[12-13],现有的基于健康人的睡眠分期方法[14]用于SAS 患者时分类性能严重下降。 针对上述问题,本研究以R-R 间期序列为基础,利用较大规模数据集,提出一种基于门控循环单元(gate recurrent unit,GRU)网络进行多分类自动睡眠分期的方法。
1 材料和方法
1.1 SHRSV 数据集
所采用方法的总体描述如图1 所示。 首先从R-R 间期序列中提取心率变异性(heart rate variability,HRV)、 呼吸幅度变异性(respiratory amplitude variability, RAV) 和呼吸率变异性(respiratory rate variability,RRV)信号;然后从这些信号中提取时域、频域和非线性特征共55 个,并且根据分类器类型,对原六分类的睡眠状态注释进行合并处理,分别得到4 种对应不同分类器的睡眠标签;最后基于GRU 网络分别构建区分W-S 的二分类器、W-REM-NREM 的三分类器、W-REM-LS-SWS的四分类器、W-REM-N1-N2-N3 的五分类器。
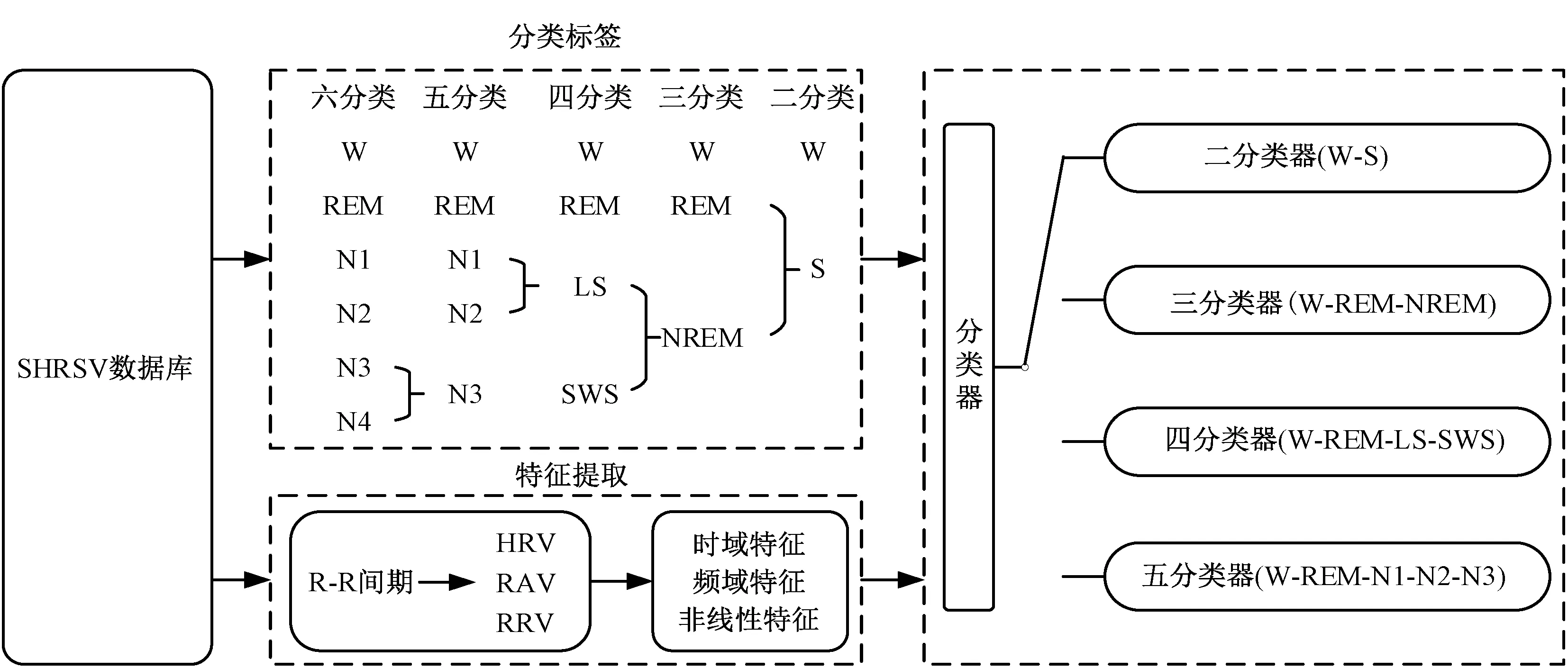
图1 自动睡眠分期整体框图Fig.1 An overall description of the method proposed
所采用的训练集和测试集来自SHRSV(sleep heart rate and stroke volume,SHRSV)数据库[15],该数据库包含274 例SAS 患者[男229 例,女45 例,平均年龄(61±10)岁],其中142 例为轻度SAS 患者(呼吸暂停低通气指数(apnea hyponea index,AHI)<15),132 例为中重度患者(AHI>15)。 数据库仅由R-R 间期(heart interbeat interval)序列、每搏输出量(stroke volume,SV)数据和睡眠状态注释组成。 R-R间期序列是从采样率为500 Hz 的心电信号中采用自动心率分析软件提取,并经过手动检视和校正;睡眠状态注释是由专家按照早期的Rechtschaffen 和Kales(R&K)睡眠分期标准将睡眠活动分为W、REM、N1、N2、N3、N4 等共6 个阶段[16]。
1.2 特征提取
提取的特征主要包括R-R 间期序列、HRV、RAV 和RRV 的时域特征,HRV 和RRV 的频域及非线性特征。 首先从R-R 间期序列得到心率信号HR,然后利用三次样条插值对HR 进行插值处理,得到采样率10 Hz 的等时间间隔HRV 信号。
根据心率变化受呼吸过程调制这一特点,使用一个截止频率为0.1~0.4 Hz 的三阶巴特沃兹带通滤波器处理HRV 信号,即可得到频率调制RAV 信号。 RRV 信号提取方法与HRV 相似,首先对RAV信号使用最大斜率法[17]检测呼吸波位置,并计算相邻呼吸波峰位置的时间间隔,即可得到P-P 呼吸间隔序列;然后从P-P 呼吸间期序列计算呼吸率信号,对其利用三次样条插值进行插值处理,得到采样率10 Hz 的等时间间隔RRV 信号。
提取特征之前,首先对HRV、RAV 和RRV 进行均值为0,方差为1 的标准化处理,并对整晚数据按30 s 为单位进行划分。 考虑到计算频域特征需要一定的长度,尤其是获取信号超低频带(very low frequence,VLF)的可靠信息至少需要5 min[18],同时为了保证特征数据的连续性和平稳性,时域、频域和非线性的特征计算均以当前30 s 为中心,前后各延伸2.25 min,共5 min 为一段,最后将5 min 数据计算的特征作为中心30 s 信号的特征。
从R-R 间期序列、HRV、RAV 和RRV 信号中提取的17 个时域特征如表1 所示,对于R-R 间期序列,提取了特征RRn 和PNN50,RRn 表示该段R-R间期序列中最常出现的R-R 间期数值,PNN50 表示相邻R-R 间期之差超过50 ms 的个数与总窦性心搏个数的比值,其余的15 个时域特征在文献[14]中有详细说明。 此外,HRV 和RRV 的频域特征能够深层次的反映心率和呼吸率的变化规律。 表2 是这一部分的特征说明,其中特征SA、SB、SC、SA/C、SB/C,分别表示0.05 ~0.40 Hz、0.005 ~0.010 Hz、0.01 ~0.05 Hz 频段的能量、0.05~0.40 Hz 与0.01~0.05 Hz能量的比值、0.005 ~0.010 Hz 与0.01 ~0.05 Hz 能量的比值,其余HRV 和RRV 分别对应的5 个频域特征来自文献[14]使用的特征。

表1 时域特征提取Tab.1 The time domain features from R-R intervals sequence, HRV, RAV and RRV

表2 频域特征提取Tab.2 The frequency domain features from HRV and RRV
考虑到心脏是一种复杂的非线性混沌系统,时域、频域特征很难完整揭示反映其本质特征的关键信息[19],进一步提取了原信号S,即HRV 和RRV 信号的多尺度熵(multiscale entropy,MSE)[20]、过零检测(zero crossing analysis,ZCL)、赫斯特指数和多重分形谱宽度[21]4 种非线性特征。 具体特征如表3所示,其中Sl和Sh为小波分解和重构后的低频和高频信号,分别视为HRV 和RRV 信号LF 和HF 分量的估计。

表3 非线性特征提取Tab.3 The nonlinear features from HRV and RRV
1.3 分类网络
考虑到不同应用场景的需求,研究基于Tensorflow 2.1.0 软件库的Keras 2.3.1 框架构建了4 个分类器,其中Python 版本为3.7。 每个分类器共有7 层,分别是输入层、Masking 层、全连接层、批标准化层、双向GRU 层、Dropout 层和输出层,最大区别仅在于输出层的神经元数量不同,代表不同的类别数。
此外,每个人每晚睡眠时间长度的不同导致提取的特征长度也不一致,而keras 构建网络模型时,输入层需要指定特征序列的长度和个数。 研究选择所有数据中最长的数据长度,即睡眠时间长度为9 h 2 min 30 s,以30 s 为一个时间单位,共划分为1 085个时间单位,对于数据长度不足1 085 的数据,采用keras 的Masking 策略,即用0 填充。 图2 为分类器的结构。

图2 分类网络结构Fig.2 Classification network structure
1)输入层:输入特征数据,指明输入维度,即时间维度为1085,特征维度为55。
2)Masking 层:屏蔽输入特征数据中补0 的时间单位,保证该时间单位在后续的所有层被跳过,不参与计算。
3)全连接层:将每个时间单位的特征线性映射到另一个特征空间,该层神经元数量为输入特征维度的2 倍。 其中,每个神经元节点均与上一层每个神经元节点相连接。
4)批标准化层:具有正则化的作用,使得每一批输入特征数据的分布重新置为均值接近为0,方差接近为1,这一层的作用能够减少中间协变量的转换,提高网络训练的速度[14]。
5)双向GRU 层:设置100 个GRU 网络单元,当前时间单位的输出不仅依赖于当前时间单位的特征,还依赖于之前以及之后时间单位的特征。 设置序列标志位为true,意味着该层的输出与输入的时间维度一致。
6)Dropout 层:采用Dropout 策略[22],随机以0.5 的失活概率丢弃双向GRU 层的输出节点,这样可以增强模型的泛化能力,防止网络陷入过拟合。
7)输出层:本质为一个全连接层,将前一层的输出映射到输出特征空间中,该层神经元个数为分类器的输出类别数。 使用softmax 激活函数使得神经元输出为概率值,各神经元对应的概率值之和为1,概率值最大的即为预测的类别。
1.4 模型训练
使用交叉熵代价函数作为损失函数,用来衡量训练过程中预测结果与实际结果之间的误差。通过赋予损失函数类别权重系数来降低类别样本数不均衡对模型训练的影响,类别权重系数定义为

式中,wi为第i个类别的权重系数,i取值范围为1~n,n为类别总数;N为样本总数;Ni为第i个类别样本数;α为权重指数,取值范围为0~1。
从SHRSV 数据集的274 例数据中随机选取20%作为测试集,剩余数据按照4 ∶1 随机划分训练集和验证集,即训练集176 例,验证集44例,测试集54 例,同时保证各数据集中AHI<15以及AHI>15 的数据在总数据集中所占比例基本相同。 训练过程中的batch_size 为5,训练次数epoch 为50,初始学习率为0.001,选择收敛速度快且效果较优的Adam 优化方法[23]用来更新权重。
实验环境为一台处理器为Intel(R) Core(TM)i5-6400 CPU @ 2.71 GHz、RAM 为16 GB、Win10 64 位操作系统、装有Matlab R2019b,Tensorflow-CPU 2.1.0 的DELL 台式机。
1.5 评价指标
1.5.1 统计学评价
使用混淆矩阵可视化分类结果,并计算总体准确率和Cohen's Kappa 系数k,其中k的取值范围在-1~1 之间,具体统计学意义为:k<0 表示分类器预测结果与真实结果没有一致性;0.01≤k≤0.2 表示有极低的一致性;0.21≤k≤0.4 表示有一般一致性;0.41≤k≤0.6 表示有中等一致性;0.61≤k≤0.8 表示有较高一致性;0.81≤k≤1 表示几乎完全一致[24]。
1.5.2 睡眠结构评价指标
睡眠分期的主要目的是分析评估睡眠结构,进而判断人体的睡眠质量。 共使用了11 个评价指标用以分析睡眠结构,对睡眠质量进行评价[25],如表4 所示。

表4 睡眠结构评价指标Tab.4 Sleep structure evaluation index
2 结果
一晚睡眠数据的特征提取时间与30 s 时间单位特征的提取时间呈线性关系,其中30 s 时间单位的特征提取时间为0.81 s;模型的训练时间随类别数的增加而增加,二分类、三分类、四分类、五分类网络的训练时间分别约为32 min 10 s、42 min 31 s、47 min 32 s、53 min 23 s,测试时间随类别数的变化微乎其微,每个类别测试所需时间均约1 s。
2.1 权重指数α 的影响
图3 显示了当损失函数被赋予类别权重系数wi时,三分类验证集的准确率和Cohen's Kappa 系数随权重系数wi中的权重指数α的变化过程。 可以看出当α取0.3 时Cohen's Kappa 系数最大且准确率无明显降低,此时整体效果最优。
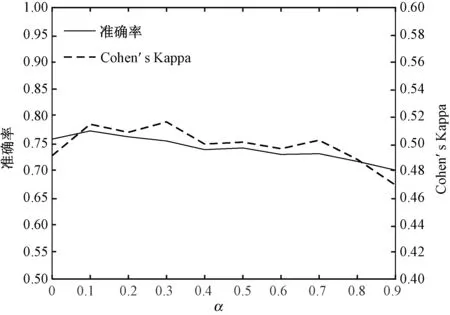
图3 准确率和Cohen's Kappa 系数随α 的变化Fig.3 The change of accuracy and Cohens Kappa statistic k with different α
2.2 模型在测试集上的表现
表5~8 分别给出了测试集二分类、三分类、四分类和五分类的混淆矩阵、准确率和Cohen's Kappa系数k,其中4 个分类器的准确率分别为85.06%、75.44%、63.80%、62.13%,Cohen's Kappa 系数达到了0.54、0.49、0.41、0.41,均达到了与临床PSG 结果中等的一致性。
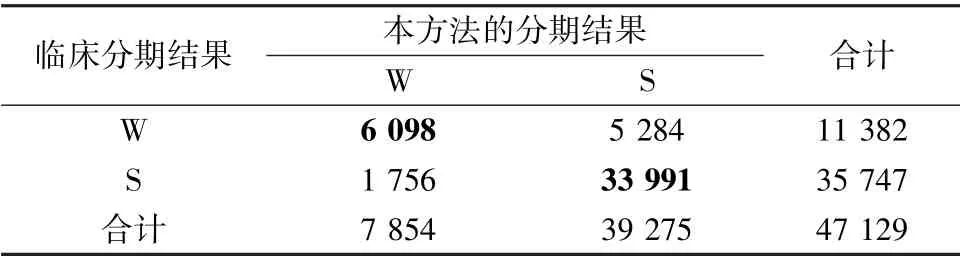
表5 二分类睡眠分期的混淆矩阵Tab.5 Confusion matrix of two-class sleep staging
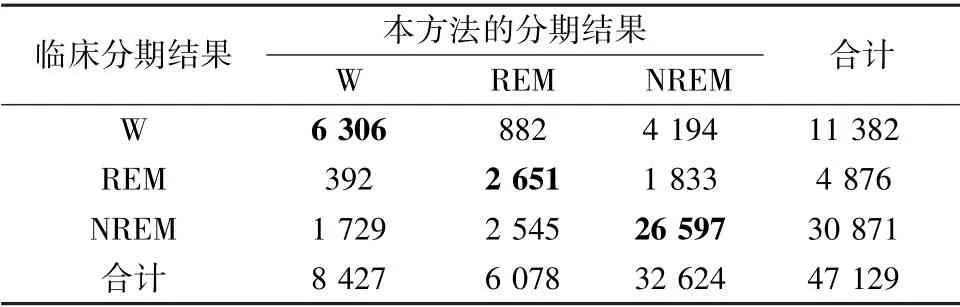
表6 三分类睡眠分期的混淆矩阵Tab.6 Confusion matrix of three-class sleep staging
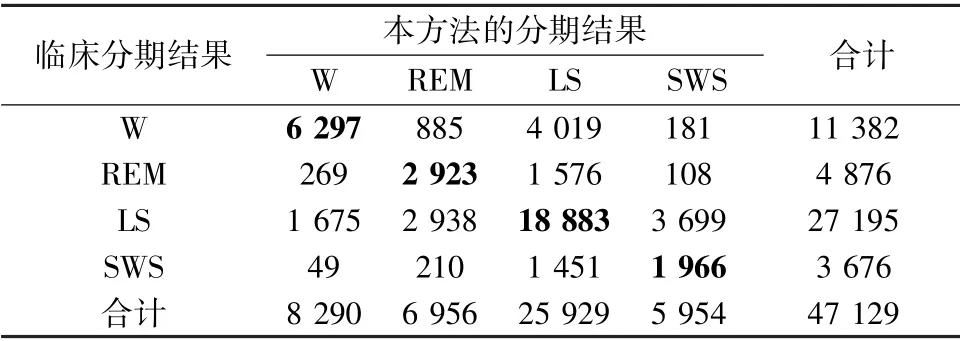
表7 四分类睡眠分期的混淆矩阵Tab.7 Confusion matrix of four-class sleep staging
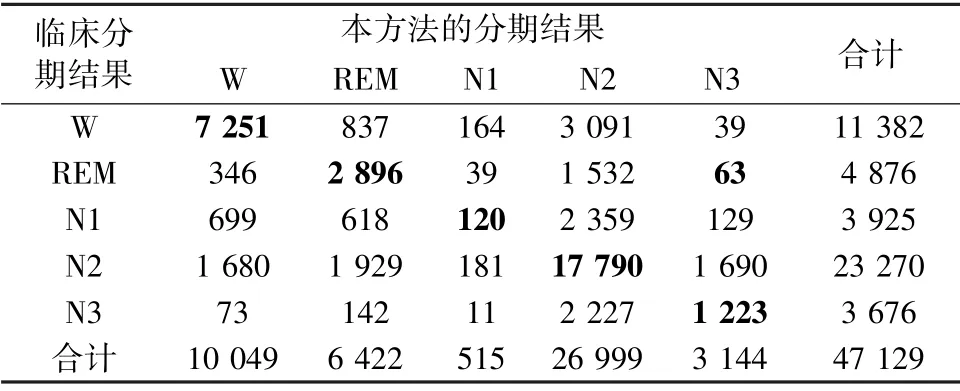
表8 五分类睡眠分期的混淆矩阵Tab.8 Confusion matrix of five-class sleep staging
图4 是测试集中某一受试者临床分期结果与文中方法预测结果的对比,可以看出只有少部分时间单位睡眠阶段被分错。 该受试者预测结果与专业医师的分析结果相比,准确率达到了86.39%,Cohen's Kappa 系数为0.80,与临床PSG 判读结果有较高的一致性,而临床中不同医师判读结果的一致性仅有76.8%[26]。
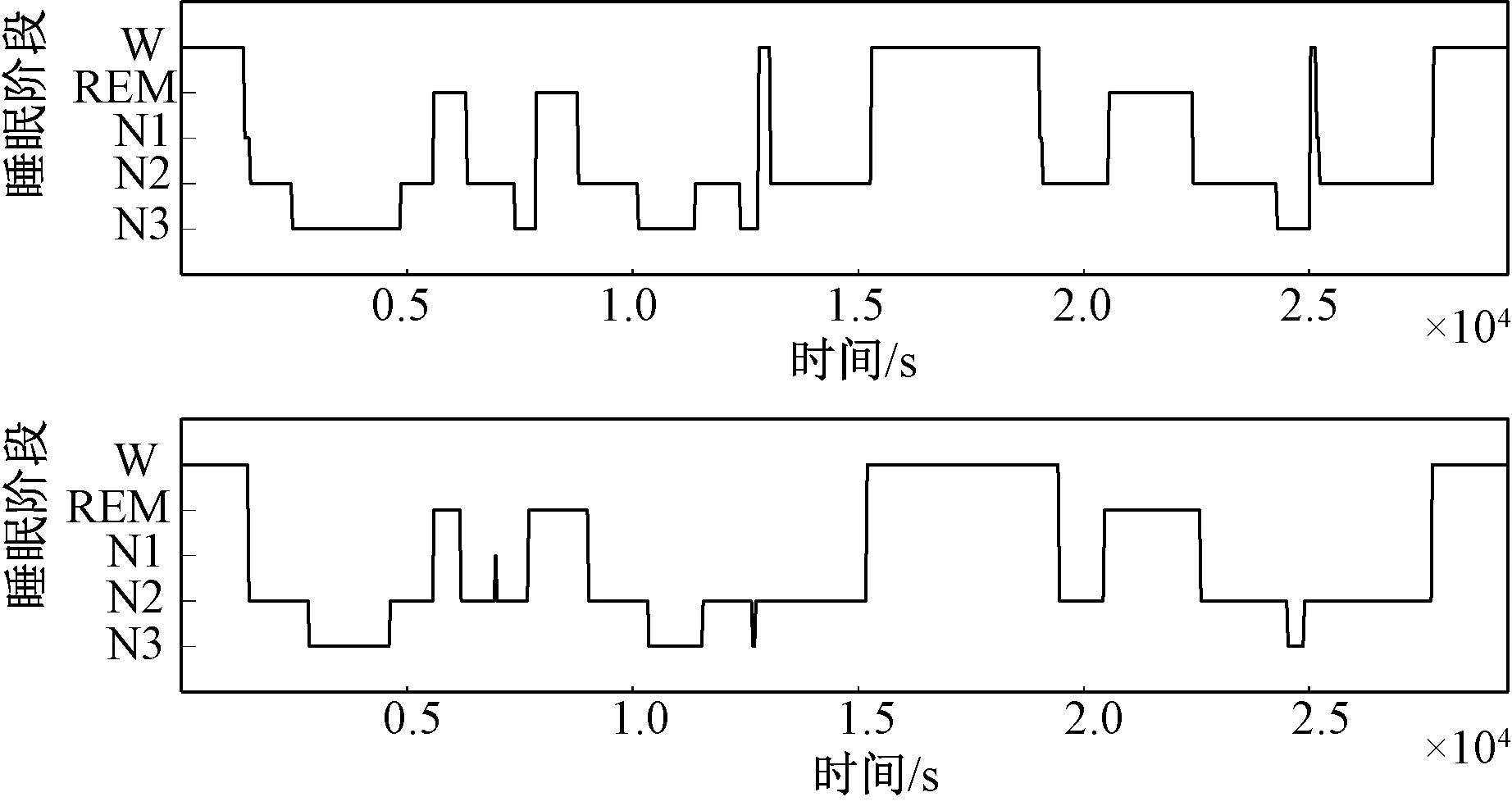
图4 模型分期结果与临床医师分期结果对比.模型分期结果(上);专业医师分期结果(下)Fig.4 The comparison of predicted sleep stage by GRU network with clinical technician of one subject from the test data.Sleep stages by GRU network (the top).Sleep stages by clinical analysis (the bottom).
用表4 列出的11 个评价指标,对54 个测试用例进行统计分析。 使用SPSS 软件分析发现相关评价指标不满足正态分布和方差齐性,因此采用曼-惠特尼U 检验规则检验[27]预测结果和临床PSG 判读结果之间的统计学差异。 表9 分别列出了预测结果和临床PSG 判读结果的均值、标准差和显著性水平P值,由于P值均大于0.05,表明预测结果和临床PSG 判读结果之间的差异无统计学意义。
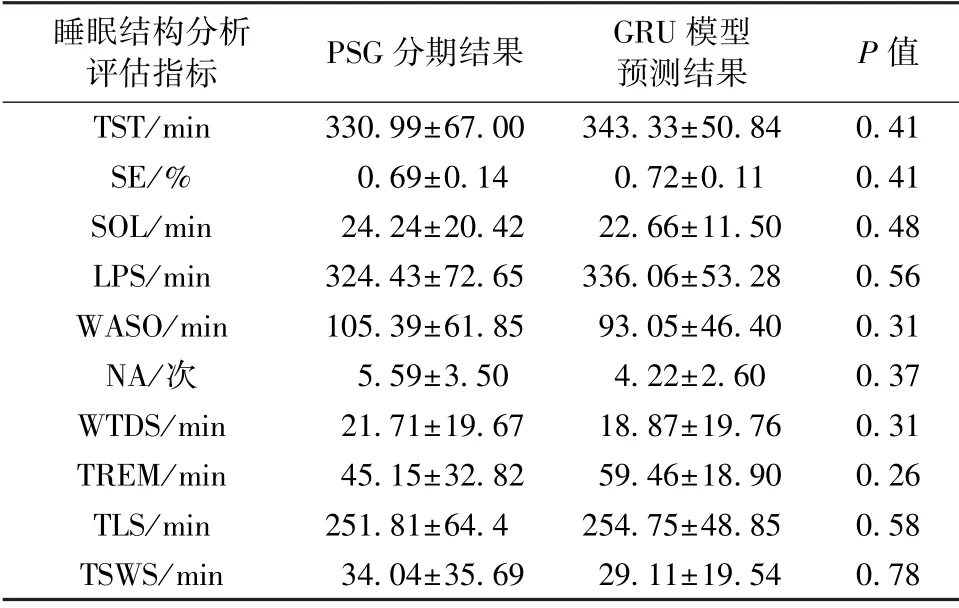
表9 睡眠结构评估指标的统计学分析Tab.9 Statistical analysis of sleep structure evaluation indicators
2.3 特征选择的可行性
为了从提取的特征集中筛选对当前分类任务有益的和剔除冗余的特征,提出一种更加简化的基于深度学习模型的封装式方法,具体过程为:对于原始特征集合F={f1,f2,…,fm},首先将每个特征fi独立的依次输入分类器,并依据验证集上的Cohen's Kappa 系数由大到小对F进行排序得到新的特征集合F' ={f1',f2',f3',…,f n'} 。 然后将最优的特征f1'放入空特征子集Fs,接着将F'中剩下的n -1 个特征依次加入Fs, 若加入特征f i'后得到的Cohen's Kappa 系数比之前好,则保留特征f i', 否则去除。最后特征子集Fs作为最终输入分类器训练和测试的特征集合。
表10 列出了不同粒度分类器筛选的特征集合,54 例测试数据的二分类、三分类、四分类和五分类的准确率分别是 85.10%、 76.16%、 69.07%、64.44%,Cohen's Kappa 系数是0.54、0.51、0.45、0.42。 可以看出三、四和五分类的分类效果相比于特征选择之前得到了提升,同时减少了需要的特征规模,节约了计算时间,充分说明了特征选择的有效性。

表10 选择的特征集合Tab.10 Selected set of features
2.4 国内外同类研究对比
表11 列出了课题组前期Wei 等[14]提出的基于健康人的睡眠自动分期算法应用于SAS 患者数据后的表现,可以看出不同粒度睡眠分期任务的效果大大降低,尤其是五分类准确率降低了14.66%,Cohen's Kappa 系数降低了0.22。 而表12 是本文模型或算法与国内外同类研究的对比结果,其中由于公开数据库UCD[28]中数据较少,直接采用文中训练好的模型对25 个SAS 患者进行预测,而对于健康人数据的处理过程与上文描述一致,由此发现准确率和Cohen's Kappa 系数均有所提高,这也表明所提出的自动睡眠分期算法的可行性与有效性。

表11 健康人的自动睡眠分期算法在不同数据集中的表现Tab.11 Performance of automatic sleep staging algorithm in healthy subjects in different data sets

表12 国内外同类研究方法的对比Tab.12 Comparison of similar research methods at home and abroad
3 讨论
本研究从SAS 患者的R-R 间期序列中提取了HRV、RAV 和RRV 等3 种信号,进一步地从这些信号中提取了时域、频域及非线性特征共55 个,基于GRU 网络实现了不同分类粒度的睡眠自动分期。其中所有睡眠分期任务的Cohen's Kappa 系数均在0.41~0.61 范围内,意味着与临床PSG 结果有中等一致性,可是与课题组前期关于健康人的睡眠分期研究[14]相比,所有睡眠分期任务的表现较差,一方面是由于SAS 患者与健康人相比,睡眠分期类别数呈现更加不平衡的特点,本研究虽通过赋予损失函数类别权重系数来缓解睡眠分期类别样本数严重不均衡对分类器学习过程的影响,但是从表5 ~8 中依然能看出二分类中有较多的W 期被错分为S,三分类中有较多的W 期和REM 期被分为NREM 期,四分类中错分为LS 期的数据较多,五分类中错分为N2 期数据较多,这也表明采用的样本权重虽然在一定程度上能够缓解,但并不能完全解决样本不均衡的问题。 另外,睡眠过程中的呼吸暂停事件也会模糊W 期和S 期、REM 和NREM 之间的决定界限[9],这也是上述分期任务中被错分的主要原因。
睡眠呼吸暂停是睡眠障碍中的一类普遍问题,相应的患者对在家庭或社区可进行睡眠监测的需求也日益强烈[10],而心电信号由于其测量技术成熟,已经成为可穿戴睡眠监测设备常用的生理信号,主要用来对受试者进行睡眠分期和睡眠结构评价。 可是表11 中列举的一些针对SAS 患者的研究,准确率和临床PSG 金标准结果相比还是有很大的差距,这也一直是制约可穿戴睡眠监测设备的推广使用的因素。 此外,这些研究只关注了准确率和Cohen's Kappa 系数两个评价指标,而可穿戴睡眠监测设备除了对睡眠进行分期外,还包括睡眠质量的评估,它们并没有从表4 列举的睡眠结构指标角度去综合评估算法的性能。 而本研究计算了11 个睡眠结构评估指标并利用统计学方法进行分析结果如表9 所示,所有指标均与临床结果之间的差异无统计学意义,由此发现本研究使用GRU 网络对SAS患者进行睡眠自动分期的有效性,虽然准确率与临床金标准PSG 的结果还有很大差距,但总的来说对于睡眠结构分析和睡眠质量评估还是比较准确的,一定程度上可移植于可穿戴睡眠监测设备,用于用户睡眠结构和睡眠质量的分析评估。
国内外同类研究往往集中于健康人,针对SAS患者的研究甚少,可是从表11 看出当健康人的算法用于SAS 患者时效果明显变差,这表明算法的泛化或推广能力较低,主要原因是SAS 严重影响心电信号的稳定性且Wei 等[14]的算法没有考虑睡眠分期类别样本数不均衡的影响。 然而从表12 看出本研究提出的睡眠自动分期算法和已训练好的睡眠分期模型在不同人群中有良好的普适性,值得注意的是,Willemen 和黄文汉等使用的训练集和测试集均来自于同一个数据集,一定程度会导致结果相较于训练集和测试集彼此独立的结果大幅升高,而SHRSV 和UCD 数据集来自于不同的采集设备与医师标注,会引起数据分布存在很大差异。
此外,虽然本研究在SAS 患者的数据基础上提出了一种自动睡眠分期算法,但是当用于健康人数据集时,表11 和表12 的结果对比表明,所有睡眠分期任务的表现均得到提升,尤其是二、三和四分类的Cohen's Kappa 系数大于0.61,与临床PSG 结果达到较高的一致性。 这可能是因为本研究相比于课题组前期Wei 等[14]提取了更多的特征,尤其是HRV 和RRV 信号频域的SB/C特征量即0.005~0.01 Hz 的能量与0.01 ~0.05 Hz 的能量的比值,它可以较好区分睡眠呼吸暂停和正常片段。 另一方面,考虑到人体心脏系统的非线性特性,本研究在时域、频域特征的基础上提取了一些非线性特征,这些特征的重要性在表10 中也有所体现。 综上,本研究基于SAS 患者的数据提出的自动睡眠分期算法具有较好的稳健性和普适性,用于可穿戴睡眠监测设备时可以适用于不同人群,反之部分设备会首先进行睡眠呼吸暂停事件的判断,然后加载与之对应的睡眠分期算法或模型完成睡眠分期和睡眠质量的评价,这无疑是增加了设备的分析时间和成本。
当然,本研究也存在一定的局限性。 一方面,提取特征过程复杂和特征数量较多,一定程度会限制它的推广能力,除可以通过本研究提出的一种基于深度学习模型的特征选择方法来降低特征数量外,未来将研究更有效的特征和复杂度更低的特征提取方法;另一方面,睡眠结构指标与临床结果之间的差异无统计学意义,基本上满足可穿戴睡眠监测设备中睡眠质量评估的需求,但是当考虑用于临床某些场合,准确率仍亟待提高,未来也将围绕改进模型来提高分类效果。
4 结论
睡眠分期是睡眠监测和睡眠质量评价中的一项重要内容。 本研究针对睡眠呼吸暂停综合征患者提出了一种基于GRU 网络的自动睡眠分期方法。在睡眠结构评估指标方面,本方法与临床分析结果无统计学差异,基本可以满足睡眠质量评估的需求,适用于可穿戴睡眠监测和家庭护理监护。
猜你喜欢
电子产品世界(2022年4期)2022-04-21
成都信息工程大学学报(2021年1期)2021-07-22
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
北京汽车(2021年2期)2021-05-07
农业科技与信息(2021年2期)2021-03-27
计算机系统应用(2021年2期)2021-02-23
健康体检与管理(2021年10期)2021-01-03
计算机应用与软件(2020年1期)2020-01-14
振动工程学报(2019年2期)2019-05-13
