
基于神华货车状态检修技术架构模型分析
2022-10-25 09:24乔志刚
粘接 2022年10期
卓 卉,乔志刚
(1.国家能源投资集团有限责任公司科技部,北京 100001;2.北京京天威科技发展有限公司,北京 100085)
神华铁路绝大部分运营列车均为重载煤炭运输列车,部分列车为煤矿等机构使用的建材或者钢材等。这些列车载重较大,车速略低于普通列车,车辆调度管理难度大。相关研究中,从列车实时报送信息中获得数据规律,根据规律的深度挖掘结果产生列车状态的领先特征数据。
基于列车轴温数据、制动气压数据、车速-油耗对照数据等建立加权指标预警机制;原始序列、差值序列等不同数据序列处理方法得到的线性离散数据矩阵,使用傅里叶变换获得其周期规律,使用移动窗口法获得振幅、频率的相关信息并对这些信息执行线性回归,从而获得一组货车状态的综合评价因子,然后对这些因子构建加权整合因子,得到更为精确的货车运行状态。该研究提出的货车状态评价算法可以更为精确的反映货车实际状态。
1 货车状态数据的产生机制
该研究中重点考察3列数据,数据均由列车实时监测系统通过车载物联网报送到数据中心机房,其中的数据产生机制如下:
1.1 轴温数据、制动气压数据
轴温数据、制动气压数据,均来自特定探头的时序数据,这些数据无需进行前置数据处理,数据的量纲和值域可以通过线性重投影算法执行归一化处理。线性重投影指历史最大值与历史最小值的差值记为A值;当前值与历史最小值的差值记为B值,将B/A的结果作为重投影结果值。经过重投影后,所有序列数值均取消了量纲,且值域控制在了[0,1]。
1.2 车辆油耗
车辆油耗可以反映出机车的牵引性能,此时需要获得不同车速条件下的油耗状态。即单位距离下油耗与车速的比值,原始量纲为t/s,即t/m与m/s的量纲比值;同样采用线性重投影法获得去量纲数据。
1.3 数据的关联性
轴温数据可以反映出货车结构的扛负荷能力,与车辆结构力学相关的故障可以在数据中直观展示;制动气压数据可以反映出货车压气系统的气密性状态,与车辆运行安全保障和系统稳定性相关的故障可以在数据中直观展示。车辆油耗可以反映出货车机车的牵引效率,机车系统故障可以在数据中直观展示。上述数据还可以产生低信噪比的其他故障,如货车运行阻力系数对油耗、轴温等均会产生影响,压气系统气密性也可以反映出其他控制系统的相关故障。
2 货车状态加权因子的提取算法
上述3个数据序列提取加权因子的算法流程相同,此处仅讨论线性离散序列数据的因子提取方案。在原始序列中划分移动窗口,将原始序列的可挖掘特征构成重组序列,具体如图1所示。
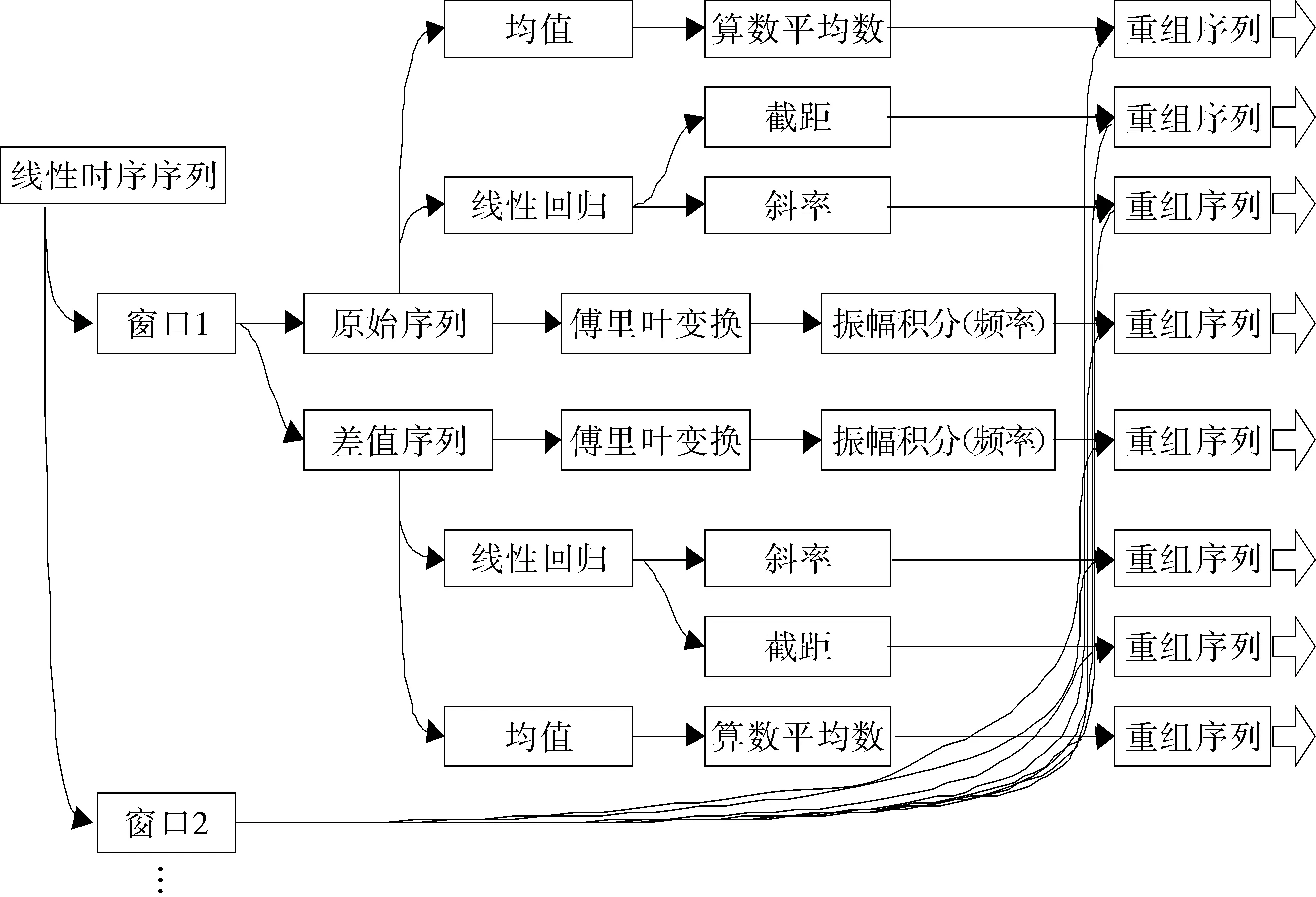
图1 重组序列的构建算法分解图Fig.1 Decomposition diagram of construction algorithm of recombination sequence
由图1可知,移动窗口的规模如果过小,则难以获得较长周期内的数据变化规律;移动窗口的规模如果过大,则早期数据将会对实时数据产生干扰。所以,一方面通过后置数据挖掘算法增加数据的敏感性;另一方面窗口规模应控制在合理范围内。参考相关文献的研究成果,每隔10个数据周期提取一次移动窗口,每个移动窗口前推200个数据周期,即每个移动窗口新增10个新产生数据,且移动窗口包含190个之前数据。每个移动窗口的数据,使用差值序列法生成原始序列和差值序列的2个平行序列,每个序列分别使用算数平均数法、线性回归法、傅里叶变换法获得4个输出数据(2列数据共8个输出数据),其中傅里叶变换法的输出数据为最大振幅表现下的特定频率下的振幅积分值,多个移动窗口输出的对应输出数据构建出对应的重组序列。
对每个重组序列执行一次线性重投影,在对其进行线性回归,得到对应的截距数据和斜率数据;再对截距和斜率数据执行一次线性重投影,获得截距和斜率的值域同构化整理数据。斜率加权因子设定为0.85,截距加权因子设定为0.15,对8列数据分别进行加权充足后,按照下述方案进行因子加权处理,具体如图2所示。

图2 加权因子的加权系数分配表Fig.2 Distribution table of weighting factors
由图2可知,重组序列的斜率和截距数据经过加权整合后的振幅、斜率、截距、均值4个结果,分别按照0.60、0.18、0.07和0.15的加权因子进行加权处理,形成原始序列产生的原始因子、差值序列产生的差值因子;然后,分别再使用0.75、0.25的加权因子进行第3层加权,从而形成轴温因子、气压因子、油耗因子3个评价因子。最后,在分别使用0.55、0.20、0.25这3个加权因子再次进行第4层加权,从而获得货车系统的综合评价因子。对轴温因子、气压因子、油耗因子、综合因子分别进行模糊矩阵处理,得到红色、橙色、黄色、蓝色4层预警机制并提供无预警状态。模糊矩阵为二阶原始数据、差值数据交叉矩阵,因为该模糊矩阵为常见模糊矩阵的基本形式,此处不展开论述。
3 算法效能仿真测试
综合所述,该加权整合因子算法,除使用了二阶模糊矩阵外,并未引入任何传统意义的人工智能算法,所有算法模块仅限于移动数据窗口、一维差值重组、线性重投影、线性回归等传统数据挖掘算法。这些算法模块对系统算力要求较小,所以该算法同时管理神华铁路上运行的数十列重载货车时,响应速度极快及中央机房的算力设备占用量较少。
参考相关文献中对同类分析需求提出的神经网络算法、蚁群算法、超限学习机算法等,在Matlab环境中加载神华铁路2020年全年所有列车的实时采集数据进行试运行仿真模拟,判断4种算法在不同预警级别下的故障检出率,得到如表1所示的结果。
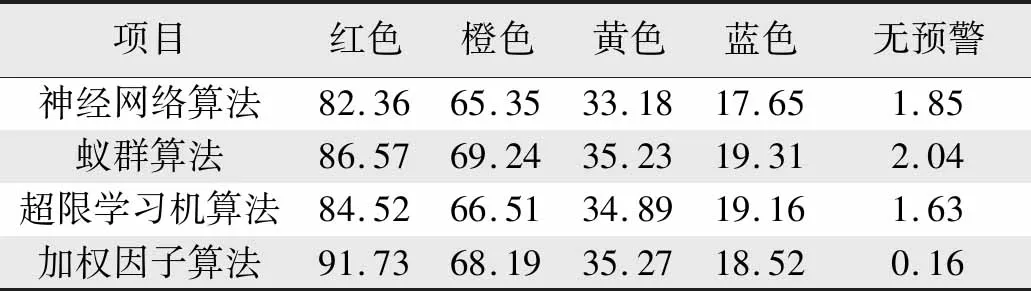
表1 不同预警级别下故障检出率比较Tab.1 Comparison of fault detection rate under different warning levels
由表1可知,本研究设计的加权因子算法相比较其他3种比较算法,除红色预警的故障检出率略高外,其他橙色、黄色、蓝色预警的故障检出率均无统计学差异;但研究设计的加权因子算法的无预警状态时的故障检出率显著低于3种比较算法;加权因子算法无预警状态的故障检出率,为神经网络算法的8.65%,为蚁群算法的7.84%,为超限学习机算法的9.82%。究其原因,3种比较算法均依赖于机器学习的数据判断,而该算法属于刚性数据分析算法,该算法更贴近系统的实际表现。
因为前文假设中提出该算法对硬件算力的需求较低,所以在Matlab仿真验证过程中将所有预警的反馈时间限定在190~200 ms,比较运行4种算法所需的算力硬件,比较结果如表2所示。

表2 不同算法的算力硬件需求量比较Tab.2 Comparison of computing power and hardware requirements of different algorithms 台
由表2可知,相关算力设备均在IBM架构服务器平台上构建,所有背板带宽均为40 Gbps,主板总线结构均完全一致,因为原始数据结构一致,所以该比较过程并不包含数据仓库的数据容量设备,其中:GPU(graphics processing unit)为浮点处理器,用于运行浮点数据的计算线程,为2.4 GHz,16线程,128位处理器,CPU(central processing unit)为通用处理器;用于运行操作系统并驱动算力平台,为2.0 GHz,8线程,64位处理器,SSD(Solid State Disk)为高速硬盘驱动器;用于存储操作系统和应用程序数据,为1 TB大容量硬盘驱动器,RAM(Random Access Memory)为动态缓存器;用于支持GPU或CPU的高速数据缓存,为DDR4代1TB高速缓存器。综合上述数据,发现在190~200 ms响应速度下,加权因子算法的实际算力设备需求远低于3种比较算法。
4 结语
基于加权因子算法的重载货车状态预警算法,相比较相关研究中普遍使用的神经网络算法、蚁群算法、超限学习机算法,在红色预警状态下拥有更高的故障检出率;在无预警状态下拥有更低的故障检出率,且在190~200 ms响应速度需求下,其实际算力硬件需求远低于上述3种比较算法。表明该加权因子算法适用于神华铁路的重载货车状态监测预警系统。
猜你喜欢
科学大观园(2022年6期)2022-04-21
中国药学药品知识仓库(2022年1期)2022-03-23
中兴通讯技术(2021年3期)2021-11-28
软件和集成电路(2019年9期)2019-11-29
读与写·教育教学版(2019年9期)2019-10-30
卷宗(2018年14期)2018-06-29
小资CHIC!ELEGANCE(2018年8期)2018-04-03
齐鲁周刊(2016年44期)2016-12-26
高中生学习·高三版(2016年9期)2016-05-14
中国纤检(2015年8期)2015-05-08
