
基于长短时记忆模型网络的水处理系统参数预测与评价
2022-10-25 08:43王竞一刘晓冬杨文广
智能制造 2022年5期
王竞一,曹 欢,刘晓冬,杨文广,张 明
(1.河北涿州京源热电有限责任公司,河北 保定 072750;2.南京天洑软件有限公司,江苏 南京 211106)
1 引言
随着火电厂运行管理模式的精细化,特别是随着智能化技术在火电厂中的应用,优化火电厂整个系统中关键环节的运行方式、降低辅机等设备的异常停机、提高设备运行经济性和可靠性,成为火电厂提质增效的重要手段。火电厂化学水处理系统是火电厂的重要辅助系统。火电厂化学水处理系统通常包括锅炉补给水、凝结处理、废水处理三个部分,是整个电力生产系统中的重要组成部分。由于火电厂不同环节对水质的高要求,化学水处理系统通常较为复杂,且运行过程对异常和故障的容忍度低。为保持化学水处理系统运行在较优状态,需定期对化学水处理系统进行清洗,清洗周期的优化对于水质的保持和运行的经济性都具有十分重要的影响。通过关键参数趋势预测,可以对设备的性能状态退化进行趋势预测,可以辅助运行人员发现参数异常以及合理安排清洗计划。
本文以化学水处理系统关键设备的运行参数预测为目标,提出了一种基于mRMR和LSTM的时间序列预测方法,可以针对运行数据中影响水处理系统性能的关键参数,建立高准确度的水处理系统参数预测与评价方法,通过与随机森林数等多种算法进行对比,证明了方法的有效性,为短期趋势预测和清洗周期预测提供方法支撑。
2 基于mRMR和LSTM的时间序列预测方法
典型的时间序列预测训练的过程包括输入参数的选择、时间序列的数据步长和窗口的选择、训练算法的选择以及超参的选择。在建立预测模型的过程中,需要根据选择的时间长度进行时间序列的预处理,由于实际系统的采样率较高,每秒1次数据采集,在预测较长时间的参数状态值时,需考虑中长期的历史趋势,存在了时间序列长度难以被长短时记忆模型有效捕获的困难,即数据数据的时间间隔和窗口大小将对结果具有显著影响。
对此,本文提供了一种分层的超参优化选择思路,即首先使用mRMR来进行特征参数的选择,然后通过对比训练进行时间序列的数据步长和窗口的选择,最后进行LSTM网络层数和神经元个数的超参选择,最终完成模型的训练。对于本方法中的关键组成部分的原理描述如下。
2.1 数据预处理
进行特征参数选择之前,首先要根据测量数据进行数据的预处理,入口流量的分布规律如图1所示。
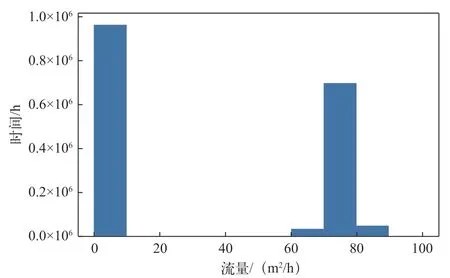
图1 入口流量分布规律
由图1可知,入口流量为0的时间占据了相当的比例,这表明,在数据预处理中,需要对数据进行筛选,去掉停机时间的数据,同时利用清洗时间将数据进行分割,以正确捕获数据规律,为预测模型的建立提供良好的数据基础。
2.2 特征参数选择
在原始测量参数中,存在较多的变量,为分析变量直接的相关性,特别是对预测性能的相关性,本文采用最小冗余最大相关性的特征参数选择方法。
最小冗余最大相关性(mRMR)是一种滤波式的特征选择方法,一种常用的特征选择方法是最大化特征与分类变量之间的相关度,就是选择与分类变量拥有最高相关度的前k个变量。但是,在特征选择中,单个好的特征的组合并不能增加分类器的性能,因为有可能特征之间是高度相关的,这就导致特征变量的冗余。因此最终有了mRMR,即最大化特征与分类变量之间的相关性,而最小化特征与特征之间的相关性。这就是mRMR的核心思想。它不仅考虑到了特征和label之间的相关性,还考虑到了特征和特征之间的相关性。度量标准使用的是互信息(Mutual Information,MI)。对于mRMR方法,特征子集与类别的相关性通过各个特征与类别的信息增益的均值来计算,而特征与特征的冗余使用的是特征和特征之间的互信息加和再除以子集中特征个数的平方。
(1)互信息
定义:给定两个随机变量x和y,他们的概率密度函数(对应于连续变量)为p(x),p(y),p(x,y),则互信 息为
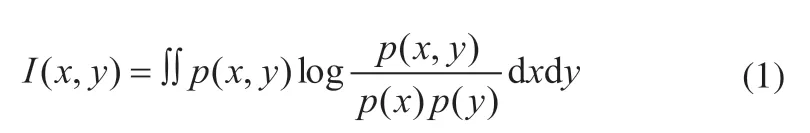
互信息是信息论里一种有用的信息度量,它可以看成是一个随机变量中包含的关于另一个随机变量的信息量,或者说是一个随机变量由于已知另一个随机变量而减少的不确定性。
(2)mRMR目标
mRMR的目标就是找出含有m个特征的特征子集S,这m个特征需满足以下两点条件:
1)保证特征和类别的相关性最大;
2)确保特征之间的冗余性最小。
2.3 长短时记忆神经网络模型
由于RNN存在梯度消失的问题,学者提出了长短时记忆神经网络模型(Long Short-Term Memory,LSTM)来解决这个问题。除了隐状态向量外,LSTM还维护一个能够对截止时间步所观测到的信息进行编码的记忆单元。记忆单元由三个门结构控制:输入门、输出门和遗忘门。
LSTM单元的具体结构如图2所示。在每一个时间步t,首先,遗忘门的向量f通过一个关于当前时刻输入x和上一个时刻的隐状态f的函数得到。当遗忘门的值接近1时,来自上一个记忆单元c的信息将会被保留,当遗忘门的值接近0时,来自上一个记忆单元的信息将会被遗忘。之后,另一个关于当前时刻输入x和上一个时刻的隐状态h的函数将会导出输入门向量i。该输入门向量将会被加到记忆单元中形成c。最后,输出门将会决定哪些来自记忆单元的信息被用来形成新的新状态h。

图2 LSTM单元结构图
3 应用案例
为验证本文所提出的方法,针对化学水处理的反渗透设备的一段压差,基于本文提出的方法,进行了4h和12h提前预测,为状态的识别和预警提供方法和模型基础。原始数据集的采样间隔为10s,长度为1年。采用前文中的方法,剔除停机时间的数据,得到有效数据共计142万组,其中训练数据占比70%,测试数据占比30%。
3.1 特征参数的选择
利用mRMR方法,针对反渗透设备进行了特征参数选择,选择结果见表1。

表1 特征参数选择结果
3.2 模型建立和训练
利用特征参数选择得到的参数,以及优化选择的时间窗口参数,构建了多个LSTM训练模型,自动筛选模型超参数,按训练结果从中选取合适的组合。
4h预测的LSTM模型最优的层数为2层,神经元的个数为10个。建立的短时记忆模型网络结构如图3所示。
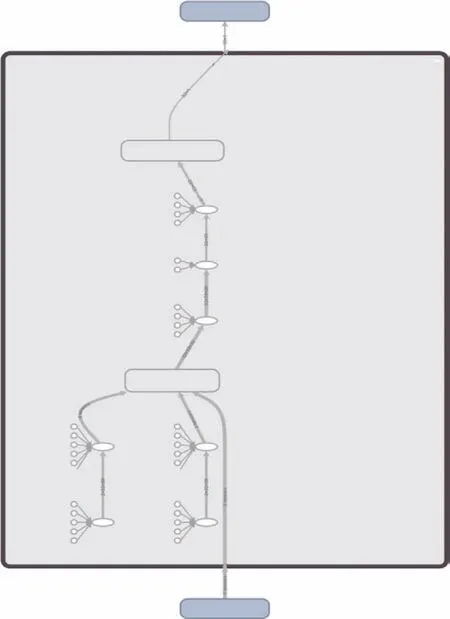
图3 长短时记忆模型网络结构
通过训练得到的预测结果如图4所示。
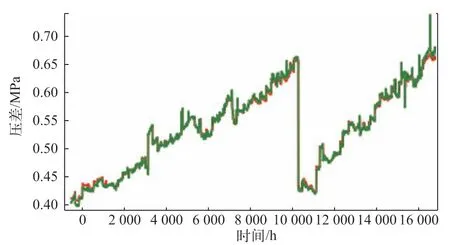
图4 差压4h预测
对于12h预测模型,选择网络层数为2,通过训练,得到的预测结果如图5所示。利用特征参数选择得到的参数,构建了训练模型,自动筛选模型超参数,按训练结果从中选取合适的组合。

图5 差压12h预测
3.3 时间窗口参数优化选择
从机理的角度看,对于不同的目标预测时长,最优的输入参数的时间间隔和窗口大小是不同的。对于4h和12h的压差预测,本文分别计算了时间间隔为2 min和10 min, 窗口大小为2 h、3 h和4 h,对于预测准确度的影响,最终得到的结果见表2和表3。
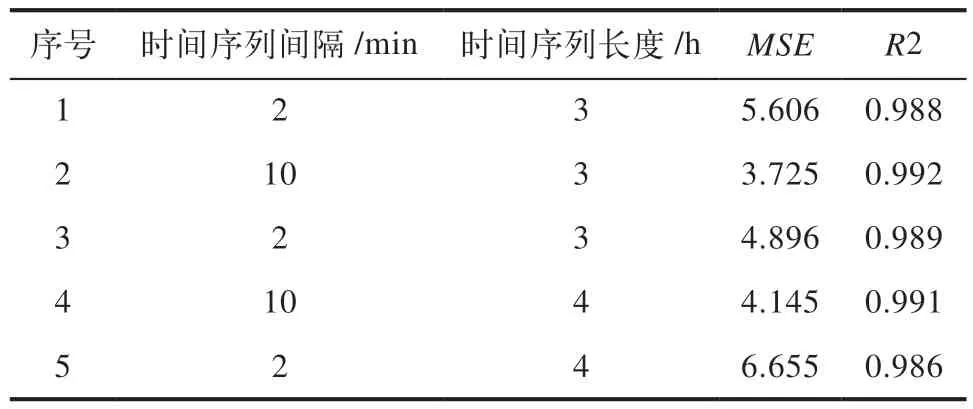
表2 4 h提前预测效果

表3 12 h提前预测结果
可以看到,当预测时长为4 h时,数据间隔取10 min,数据窗口为3 h是预测效果最好。当预测时长为12 h时,数据间隔为10 min,数据窗口为4 h,预测效果更好。
3.4 不同预测方法对比
作为对比,本文在相同输入样本之下,同时使用支持向量机SVR、随机森林RF和集成学习梯度提升决策树GBDT,SVR使用RBF核函数,随机森林中数目的个数为100,GBDT中弱学习器的个数为100。
根据最终训练的结果(表4)可以得出。不论对于4h预测还是12 h预测,使用LSTM的精度要好于另外三种算法,进一步证明了本文提出的组合算法的有效性。
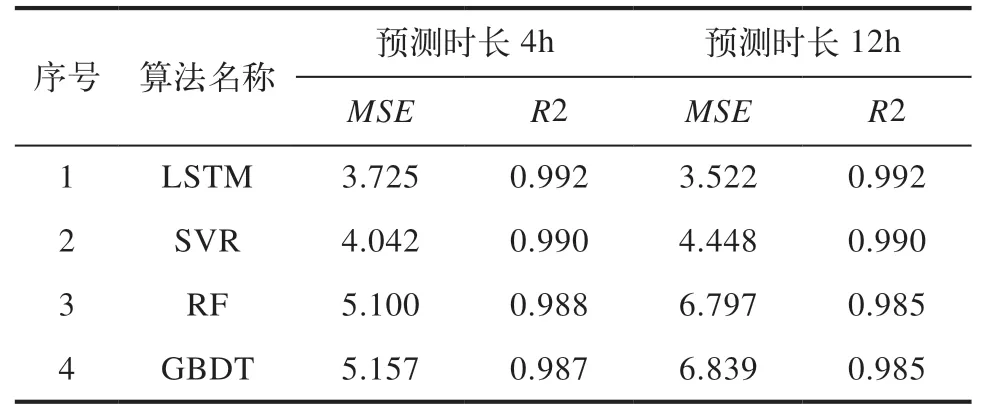
表4 不同预测方法对比表
4 结束语
本文以火电厂化学水处理系统为对象,提出了一种基于mRMR和LSTM的时间序列预测方法,提供分层的超参优化选择思路,即首先使用mRMR来进行特征参数的选择,然后使用通过对比训练进行时间序列的数据步长和窗口的选择,最后进行LSTM网络层数和神经元个数的超参选择,最终完成模型的训练。
将该方法应用在反渗透设备一段压差的预测之中,分析了运行数据中影响该参数的关键参数,针对4h和12h的差压参数预测优化选择了时间步长和窗口大小的,最后建立基于长短时记忆模型网络的参数预测模型,并通过与其他算法进行对比,取得了较好的预测效果。本文所建立的方法可以为化学水处理系统短期趋势预测和清洗周期预测提供方法支撑。同时也可以为相似设备的趋势预测和清洗周期预测提供方法 支持。
猜你喜欢
黄河之声(2022年10期)2022-09-27
大电机技术(2022年4期)2022-08-30
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中国特种设备安全(2021年5期)2021-11-06
装备制造技术(2021年4期)2021-08-05
制造技术与机床(2017年11期)2017-12-18
疯狂英语(双语世界)(2017年4期)2017-04-28
唐山文学(2016年11期)2016-03-20
电测与仪表(2015年7期)2015-04-09
