
基于深度学习的ViSAR多运动目标检测
2022-10-26 02:07张笑博朱岱寅
雷达科学与技术 2022年5期
张笑博, 吴 迪, 朱岱寅
(南京航空航天大学电子信息工程学院雷达成像与微波光子技术教育部重点实验室, 江苏南京 211106)
0 引言
视频合成孔径雷达(Video Synthetic Aperture Radar, ViSAR)是由美国Sandia国家实验室提出的一种具有动态监测能力的高帧率成像模式,可实现对目标区域全天时、全天候的持续观测,直观地反映目标的位置及运动参数等重要信息。因此,运动目标的检测与跟踪一直是ViSAR研究领域的热点。
在ViSAR图像序列中,目标运动使图像出现散焦,同时其多普勒频移导致动目标在成像时出现偏移,并在其真实位置上留下了阴影。因此,可利用阴影信息实现对动目标的检测。国内外学者已经研究了基于阴影的检测方法的鲁棒性。文献[3]采用单高斯模型对图像序列进行统计,然后通过背景差分实现动目标阴影的检测。文献[4]将低秩稀疏分解应用在ViSAR中,并通过实测数据验证了该方法的有效性。上述方法均建立在SAR图像配准的基础上,且配准效果极大地影响了检测性能。文献[5]采用快速区域卷积神经网络(Faster Region-based Convolutional Neural Networks, Faster R-CNN)检测动目标阴影,然后利用滑窗密度聚类算法和双向长短期记忆网络抑制虚警和提高检测率,该方法在美国Sandia国家实验室公布的ViSAR片段上取得了较好的检测效果。文献[6]在Faster R-CNN的基础上,引入特征金字塔结构(Feature Pyramid Networks, FPN)和K-means算法在多尺度特征图上检测目标,提高了小目标的检测性能。文献[7]从SAR图像与光学图像的差异考虑,提出了一种不需要预训练模型的船舶检测方法。文献[8-10]基于YOLO(You Only Look Once)网络进行了不同的改进,在SAR图像检测上取得了良好的效果。
动目标阴影在ViSAR图像序列间具有较强的相关性。如果一个动目标阴影在某一帧被检测到,那么在相邻帧对应位置周围会较大概率检测到该目标。对动目标的跟踪可以有效提高检测性能的鲁棒性。目前在多目标跟踪(Multi-Object Tracking, MOT)算法中最流行的是检测后跟踪(Tracking by Detection)范式算法,即先检测目标,再将检测结果与已存在轨迹关联。由于基于深度学习的检测方法具有良好的性能,多目标跟踪算法主要完成检测结果的关联及检测性能的改进。
综上所述,针对ViSAR动目标检测技术,需要研究一种不依赖预训练模型,能够从零开始深度学习的动目标阴影检测算法。此外,为弥补单帧检测算法的缺陷,需要结合ViSAR时间维度的信息设计多目标跟踪算法提升检测性能。据此,本文提出了一种基于深度学习与多目标跟踪算法的ViSAR多运动目标阴影检测算法。首先,设计了一种从零开始深度学习的网络模型,实现动目标阴影的单帧检测。由于单帧检测结果中存在部分虚警和漏警,采用了基于卡尔曼滤波和帧间数据关联的多目标跟踪算法对检测结果进行跟踪,提高了算法的鲁棒性。
1 从零开始深度学习的动目标阴影检测算法
在深度网络中,随着网络深度的加深,梯度消失和梯度爆炸也越来越明显,使得网络难以训练。为了缓解这一问题,通过直接映射的方式将浅层特征与深层特征连接,使得反向传播的梯度信号可以直接传递到浅层中。文献[14]提出一种密集连接结构的密集块(Dense Block)。该结构的示意图如图1所示。在密集块中,第层的输入是之前所有的特征层:
=([,,,…,-1])
(1)
式中,[,,,…,-1]表示第0层至第-1层特征在通道维度上的连接,(·)表示批归一化、激活函数ReLU和卷积运算。这种密集的连接方式使得每一层都能够直接获取输入信号和损失函数的梯度,从而实现深度监督。这种深度监督是从零开始深度学习的关键。
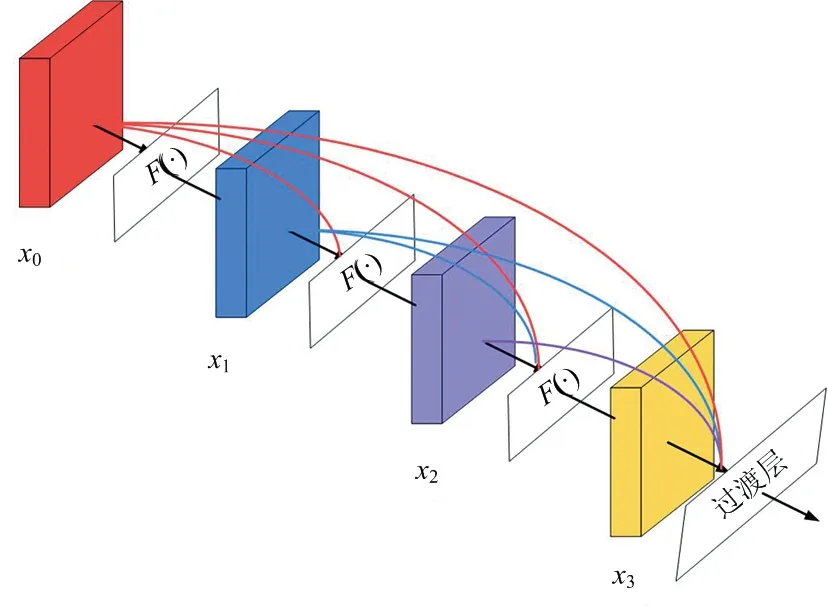
图1 密集块结构示意图
本文在现有从零开始深度学习研究成果的基础上,借鉴DSOD网络的设计思想,设计了用于动目标阴影检测的深度网络。网络的结构如图2所示,主要包含3个模块。第一个模块由3个3×3卷积层和1个2×2最大池化层组成,用于提取SAR图像的低级特征。这种小尺度卷积级联的连接方式有效降低了输入图像的信息损失。第二个模块主要由密集块组成。密集块能够充分利用各特征层的信息,每一层都可以在原有特征层的基础上添加新的特征,使模型的参数量大大降低。密集块间的连接有两种形式。第一种连接方式由1×1卷积层和2×2的最大池化层组成。这种连接方式的目的是对特征图降采样。神经网络中浅层的感受野较小,但包含了丰富的图像信息,有利于小目标的检测。随着网络层数的加深,感受野逐渐变大,特征图的尺度也越来越小。为了防止动目标阴影特征丢失,需要增加深层特征的通道数量。另一种连接方式只包括了1个1×1卷积层。由于特征图尺度过小不利于动目标阴影的检测,为了在不改变特征图尺度的情况下增加网络深度,使用了1×1卷积层连接相邻的密集块。第三个模块为特征学习与复用模块,其结构如图3所示。在此模块中,一半特征是通过两个卷积从上一层特征学习而来,其中1×1卷积用于对输入降维,降低后续学习的计算量。而另一半特征是直接对上一层特征下采样得到的。下采样由2×2的最大池化层和1×1卷积层完成,其中池化操作用于对特征下采样,保证不同尺度特征连接时大小匹配。因此特征学习与复用能够在预测时融合多尺度特征,提高了检测的准确率。网络具体的参数如表1所示。

图2 动目标阴影检测网络结构示意图

表1 动目标阴影检测网络参数
检测时沿用文献[17]提出的多尺度预测算法,本文共使用了4个不同尺度的特征层,每个特征层设置了5种不同长宽比的先验框,分别为{1, 2, 3, 1/2, 1/3},其中长宽比为1的先验框设置了两种尺寸。
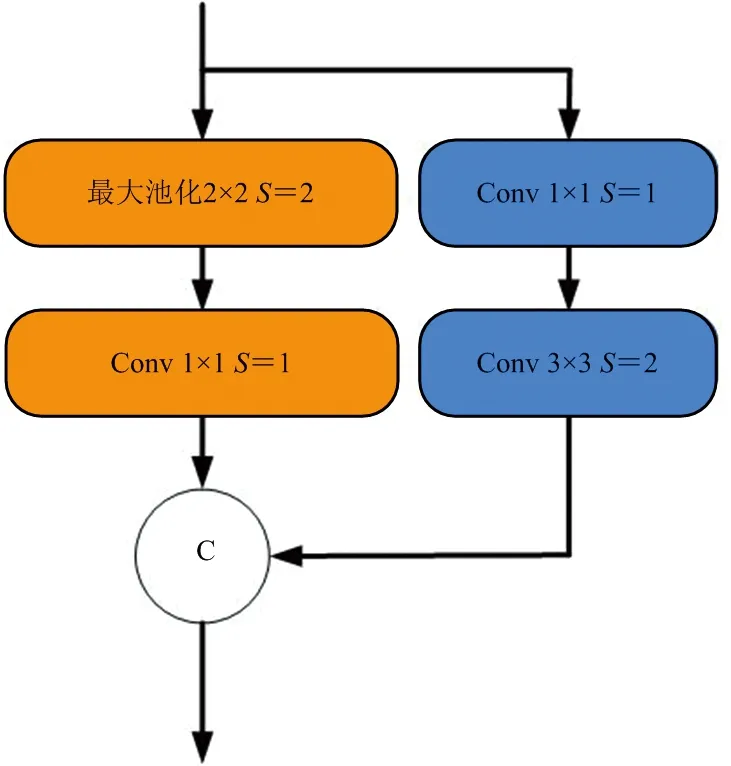
图3 特征学习与复用模块结构示意图
2 多运动目标阴影跟踪算法
基于深度学习的单帧检测方法仍然存在一定的缺陷。由于SAR图像的特征简单,场景中与动目标阴影特征相似的弱散射区域易被误判为动目标,造成不必要的虚警。另一方面,由于目标的运动,阴影区域的形状和灰度是时变的,这导致了检测中的漏警。考虑到相邻帧间动目标阴影的位置具有较强的相关性,本文提出了一种多运动目标阴影跟踪算法。该方法通过卡尔曼滤波和逐帧数据关联算法跟踪动目标阴影,有效地提高了检测性能。
首先,采用线性匀速模型对动目标阴影的运动建模,单个动目标的运动状态由以下八维状态空间描述:
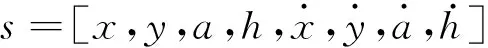
(2)
式中,和表示动目标中心的横纵坐标,和分别表示动目标的纵横比和长度,剩余4个变量依次表示,,,的变化速率。当检测结果与跟踪关联时,使用坐标信息(,,,)更新跟踪器状态,相应的速度分量通过卡尔曼滤波求解得出。反之,若没有检测相关联,通过线性匀速模型预测动目标的运动状态。
在将检测结果分配给现有的跟踪时,每个目标在当前帧的参数(,,,)通过卡尔曼滤波估计。然后通过计算每个检测与现有目标估计参数的交并比(Intersection-Over-Union, IOU)得到代价矩阵。在此基础上,检测与跟踪的关联问题可以通过匈牙利算法(The Hungarian Algorithm)求解。此外,若IOU小于预设门限将取消检测的分配。
动目标跟踪处理的流程图如图4所示,整个跟踪流程由4个跟踪状态组成。代表状态转换函数。“试探性跟踪”为任意目标跟踪的初始状态。一旦有目标初次被检测到,跟踪器将进入“试探性跟踪状态”,同时利用其坐标信息(,,,)进行初始化,初始速度设置为零。当跟踪器被连续更新三帧时,跟踪状态将转换为“稳定跟踪”。未能连续三帧与检测关联的跟踪器将被删除,从而抑制了检测中的虚警。如果稳定的跟踪器在连续的三帧中没有被更新,跟踪器的状态将转换为“候选跟踪”。只要有检测与候选的跟踪器关联,跟踪状态就返回至“稳定跟踪”。这可以有效防止跟踪对象身份的切换。若在帧内,“候选跟踪”未能转换为“稳定跟踪”,跟踪器将被删除。这种策略能够限制跟踪器的数量,降低长时间未更新出现的跟踪误差。

图4 多目标跟踪处理流程图
3 实验结果与分析
本节利用美国Sandia国家实验室公布的视频SAR数据对上述理论进行验证,场景中沿道路方向运动的阴影即为待检测目标。在整个成像片段中共提取了440帧SAR图像,其中300帧SAR图像作为训练集,140帧SAR图像作为测试集。为增强模型的泛化性,采用常用的数据增强处理如水平翻转、旋转等操作对原始数据集进行扩充。网络训练时,设置初始学习率为0.001,利用随机梯度下降法(Stochastic Gradient Descent,SGD)训练网络。为了进一步优化模型,学习率在整个训练集迭代500次后下降为初始值的0.01倍。上述实验的硬件平台为Intel i9-10900X和NVIIA TITAN RTX 24G。
学习率和损失函数曲线如图5所示,其中红色曲线表示训练过程损失函数的变化,蓝色曲线表示学习率。模型在训练8 000步后收敛。
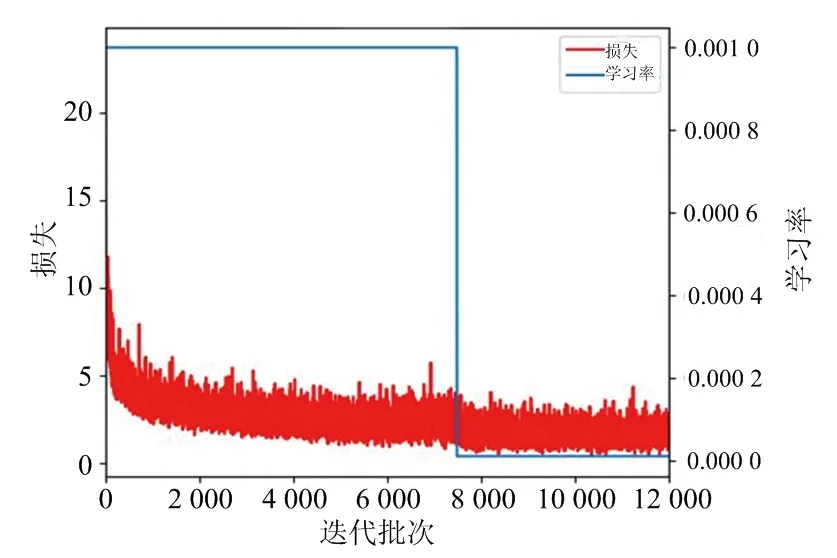
图5 网络模型训练过程
图6为基于深度神经网络的动目标检测结果。图6(a)中正确检测到的动目标阴影用红色矩形框标记,漏检的动目标阴影用绿色矩形框标记。而在图6(b)中,检测结果存在一个由弱散射区域引起的虚警。可以看出,基于深度学习的检测算法能够检测到大部分的动目标,但检测结果仍存在部分漏警和虚警。为了进一步分析本文方法的有效性,表2比较了本文检测算法与SSD,Faster R-CNN和YOLO在测试集上的表现。TP表示正确检测目标的个数,FP表示虚警个数,FN表示漏警个数。由于ViSAR图像中动目标阴影的尺寸过小,在光学图像上广泛应用的模型SSD和YOLO并不能取得较为满意的检测结果。尽管Faster R-CNN取得了良好的检测概率,但随之带来了较高的虚警。图7给出了不同检测方法在两帧ViSAR图像上的检测结果。综合表2和图7,可以看出与经典的深度学习检测算法相比,本文提出的从零开始深度学习的检测算法性能更加优异。

(a) 检测存在漏警 (b) 检测存在虚警图6 基于深度神经网络的动目标检测结果
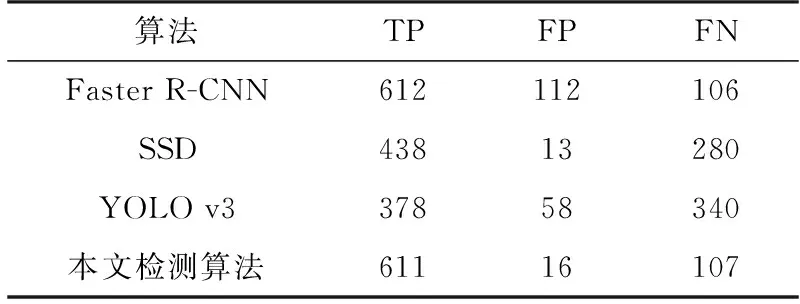
表2 检测算法对比
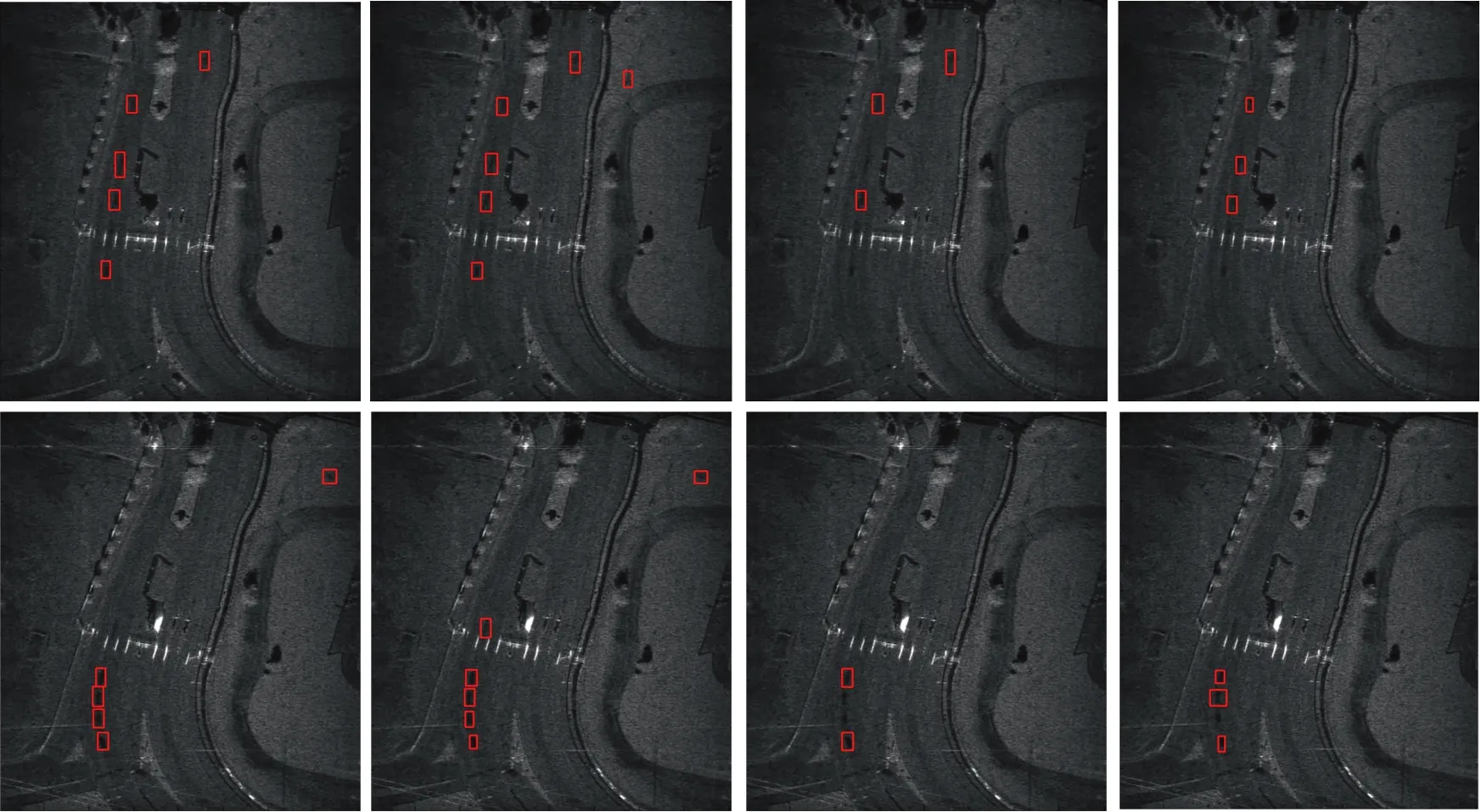
(a) 本文检测方法 (b) Faster R-CNN (c) SSD (d) YOLO 图7 动目标阴影检测方法对比
对动目标阴影进行跟踪时,算法中的参数与分别设置为0.3和40。为了评价跟踪算法的性能,在本文检测算法的基础上,将提出的多目标跟踪算法与Deepsort、TBD进行了比较,如图8所示。从图中可知,多目标跟踪算法能够提升检测性能。但TBD中出现了较多的漏警,提升效果较差。Deepsort设置的跟踪器活动时间过长,一旦有目标的跟踪状态出现变换,容易出现多个跟踪器跟踪同一个目标,造成不必要的虚警。进一步地,表3对跟踪性能进行了定量的分析。表3中Frag表示在跟踪过程中出现中断而形成的轨迹片段的数量。IDSW表示目标被正确跟踪时跟踪序号的变化次数。FP与FN的定义与表2相同。Frag与IDSW越小表示跟踪性能越优异。MOTA表示多目标跟踪的准确度,其定义如下:
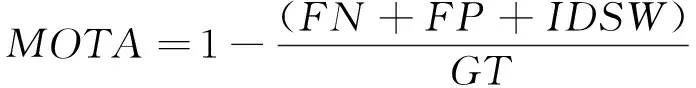
(3)
式中,表示真实动目标的总数量。MOTA越高,跟踪性能越好。从表中可知,TBD的漏警较高,因而跟踪到的片段较少,Frag的值较低。由于TBD对检测质量要求过高,在ViSAR图像上跟踪不准确,跟踪过程中虚警个数反而上升。Deepsort将目标的运动信息与图像深度特征结合用于多目标跟踪,在光学图像处理中取得了优异的跟踪效果。与SAR图像相比,光学图像有着丰富的特征,如色彩、纹理、边缘等,图像信息能够改善跟踪效果。而SAR图像中动目标阴影是由雷达回波能量空白造成的,图像特征并不复杂。而且SAR图像场景较大,在图像中动目标间的距离较近。引入图像信息可能会使目标的跟踪状态混乱,导致效果变差。本文跟踪算法中的漏警主要是由三帧确定跟踪的策略引起的,当一个新目标进入场景,需要使用前两帧的检测结果确认跟踪。对比可知,本文提出的算法在跟踪动目标阴影时更加有效,采用本文跟踪算法后,检测性能有了显著的提升。

(a) 真值图 (b) 本文跟踪方法 (c) TBD (d) Deepsort 图8 动目标阴影跟踪方法对比
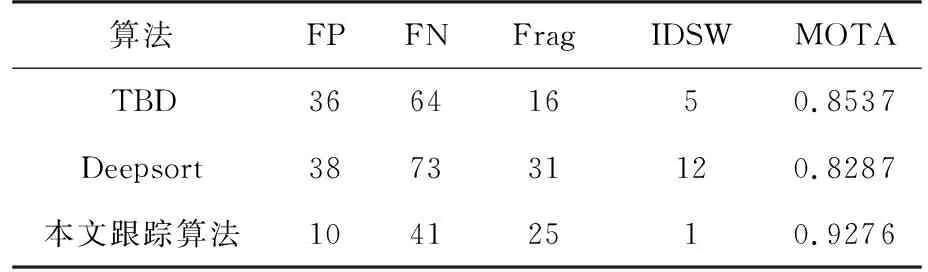
表3 跟踪性能比较
4 结束语
本文提出了一种基于深度学习与多目标跟踪算法的ViSAR多运动目标阴影检测方法,该方法首先采用一种从零开始深度学习的神经网络实现动目标阴影的初步检测,然后利用一种基于卡尔曼滤波和帧间数据关联的多目标跟踪算法对动目标阴影进行跟踪,从而提高了检测的性能。ViSAR实测数据处理结果验证了本文方法的有效性。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
快乐学习报·教育周刊(2022年16期)2022-05-01
新高考·高三数学(2022年3期)2022-04-28
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
福建基础教育研究(2019年6期)2019-05-28
文学港(2017年11期)2017-12-06
金山(2017年4期)2017-06-08
中国新通信(2017年9期)2017-05-27
数学大王·中高年级(2016年4期)2016-05-14
