
一种面向分布式数据库的多并发OLAP型查询性能预测方法
2022-10-27 03:13刘骥超杜建华谢寒生刘霄燕谢召干
计算机测量与控制 2022年10期
刘骥超,杜建华,谢寒生,刘霄燕,谢召干
(1.海南省气象信息中心,海口 570203;2.海南省南海气象防灾减灾重点实验室,海口 570203;3.海南省澄迈县气象局,海南 澄迈 571900)
0 引言
数据库中并行执行查询能够带来许多优势。例如,它能够缩短多个查询的整体运行时间并且提高硬件的利用率,但是,对于并发查询中的某一个查询,相较于其单独执行,它的执行时间可能会延长或缩短。主要原因是多个查询之间相互影响[1],有些查询能够促进该查询的执行,有些则由于与该查询存在资源竞争而延长查询执行。
并发查询性能预测对于查询调度控制[2-6]等具有很大的应用价值,例如,如果事先能够知道查询执行时间,那么就可以改变多个查询的顺序,继而达到用户SLA要求。准确的查询性能预测技术还能够用于查询进度显示[7],以便了解当前查询的执行进度,然后DBA就可以做下一步的决策,等待该查询执行完毕或杀死该查询。查询性能预测还对查询优化器具有一定的指导作用,比如:查询优化器可以更好地创建并发查询感知的查询计划,以此来缩短查询的整体执行时间。
由于查询性能预测技术具有很大价值,所以,针对该方面有很多研究,这些研究主要面向两类查询,一是OLTP型查询[8],OLTP主要指在关系型数据库中一些对时间要求比较高的事务型查询,通常该类查询的执行时间较短;二是OLAP型查询[9],OLAP型查询主要运用于数据仓库,这种类型的查询面对的数据量比较大,执行时间比较长。本文主要面向OLAP型查询。当前已经有一些技术能够对分析型查询做性能预测[10],但这些技术在实用性和扩展性方面存在一定的局限。
本文提出了一种能够量化多个查询之间的资源竞争并根据资源竞争情况预测并发查询的延迟时间的方法。在现实情况中,同一个查询在不同的并发查询组合下,执行时间等性能指标将产生差异,主要原因在于多个查询要竞争使用I/O和网络等资源。在I/O资源方面,分析型查询通常包含许多表连接操作,每个表的数据都需要从磁盘中读取,这会引发大量的I/O操作,而且若几个查询扫描不同的数据表,则会争用I/O,导致 I/O时间变长,继而使得查询变慢。对于网络资源,数据存放在分布式数据库集群的各个节点中,这些节点位于不同的物理机器上,在执行查询时,数据需要通过网络在节点间迁移,因此,网络带宽资源的争用也是影响性能的重要元素。模型能够根据不同的查询组合情况,量化资源(I/O、网络)的使用和争用情况,从而预测查询延迟时间。
本文提出了两个模型,分别是:查询干扰度(CQI,concurrent query interference)和查询敏感度(QS, query sensitivity)。查询干扰度是指多个并发查询对主查询(要预测的查询)的干扰程度,干扰度越大说明资源竞争越激烈,主查询的执行延迟也越大。查询敏感度是指主查询在不同的查询资源竞争情况下所表现出来的敏感程度即查询性能,不同的查询组合会引起不同程度的资源竞争。本文利用CQI和QS模型预测分布式数据库中并发OLAP型查询延迟。
1 相关工作
当前已有一些针对查询性能预测的研究,并且有较好的效果。另外,查询进度显示通常也需要预测执行时间。所以,接下来,本文将介绍关于这两面的研究并比较与本文技术的区别。
1.1 查询进度指示器
查询进度指示器(QPI, query progress indicators)用于指示一个查询的进度,这样可以直观地了解查询已经花费了多少时间和还需要多少时间能够执行完毕。当前,针对QPI已经有了一些研究,Surajit等人[11]对查询完成的比例建模,他们没有考虑并发查询的情况,只是针对单个查。G.Luo等人[12-13]把磁盘I/O、运行时间、消息字节数等作为度量,运用机器学习预测长查询的进度,但是他们在预测查询的延迟时间时,该查询必须是在运行中,而本文的方法在查询执行前就能够得知查询需要多少时间,且主要考虑并发查询的情况,相对机器学习方法来说,更加简单。
1.2 查询性能预测
文献[14-16]都是运用机器学习的方法来预测查询性能,但都没有处理并发查询的情形。对于多并发查询,文献[9,17-19]首先对性能预测技术进行了研究,他们的共同点都是针对分析型查询,而且考虑查询之间的交互作用并建立回归模型,即能够预测不同并发度下的查询性能。Mumtaz等人[20-21]扩展了上述的研究,他们考虑了不同组合中查询的相互影响,根据实验数据建立模型,从而得到了较高的准确率。Muhammad等人[7]对运行中的查询进行预测,而Barzan等人[8]主要对OLAP型的查询进行预测。Chetan等人[22]主要研究在数据仓库中,查询延迟如何随着工作负载的改变而改变。Jennie等人[23]对并发查询的资源竞争建模,使得预测的误差较低。文献[24]预测了在查询在大数据量下的单独执行时间,它把SQL查询映射为一系列基础操作符并计算操作符消耗时间之和来计算总执行时间。文献[25]主要针对OLTP型并发查询,运行机器学习方法以系统状态的36个指标为基础进行性能预测。
上述研究既有对OLAP型查询的研究,也有对OLTP型查询的研究,在OLAP型并发查询的情形下,都是基于单机数据库,并没有考虑分布式数据库的环境,即查询分布在多个机器上的情形,这种查询有网络开销。本文提出的查询干扰度模型考虑了网络资源开销,能更准确地预测分布式数据库并发查询的性能。
2 分析型任务
2.1 分布式数据库
本文使用分布式数据库Greenplum存储数据并查询。分布式数据库和单机数据库最大的区别在于分布式数据库是一个集群,集群中有多个节点,节点分为主节点和从节点,主节点用来管理从节点并生成查询计划,从节点存放数据并按照查询计划查询数据。当客户端提交一个SQL查询到Greenplum后,Greenplum中的主节点首先解析查询语句并生成一个代价最小的查询计划,然后,发送给各从节点,从节点根据查询计划执行查询,并将得到的结果返回给主节点,最后,主节点得到从各从节点发送来的结果,汇总结果并返回给客户端。
分布式数据库能够存储海量的数据,且能够通过增加节点来扩展存储量,但由于数据分布在多个节点上,执行表连接查询时,通常需要迁移数据,所以,相较于单机数据库,影响查询性能的因素不仅包含从节点的CPU,内存和I/O性能,还包括节点间网络的性能。
2.2 分析型任务特征
分布式数据库执行查询时,影响查询性能有4个重要的因素,分别为:CPU、内存、I/O和网络,在这4个因素当中,CPU和内存相较于I/O和网络,影响较小,因为通过实验观察到,在多个查询并行执行的时候,集群中各个节都有足够的CPU资源。另外,对于每个数据库实例,配置充足的内存。当有多个查询执行时,如果分配给该实例的内存耗尽,操作系统会将内存中的部分数据移到磁盘中,也就是发生页置换,引起I/O操作。分布式数据库最耗时的操作是扫描表,即发生I/O,其次是节点间数据传输。所以,本文主要研究磁盘I/O和节点间网络因素对查询性能的影响。
在本文的研究中,主要针对分析型查询,其特点是包含大量的join操作,每个join需要通过I/O和网络读写数据和传输数据,其查询时间一般较长。多个查询争用I/O和网络资源,这必然会对查询产生影响。
本文用到的查询是由TPC-DS中的10个模板生成[26]。选取的查询模板分别:17,20、25、26、32、33、61、62、65、71,它们都为IO敏感型查询,即花在I/O上的时间较多或占整个查询时间的比例较大,有些查询的I/O时间占整个执行时间的90%以上。
2.3 取样
本文定义MPL(multi-programming level)为同时运行的查询个数,当MPL=3时,表示当前有3个查询同时执行,且这3个查询构成一个查询组合。由于一共有10个查询,当MPL为2时,可以两两结合组成查询组合,但当MPL等于大于3时,手工设计查询组合会变得越来越复杂,所以,选用LHS(latin hypercube sampling)技术取样,下面以一个例子说明如何使用该方法构建查询组合。以MPL等于3为例,在python中,运行X=lhs(3,10)生成抽样矩阵X:
矩阵X中的元素都位于0~1之间,然后把这些元素化为整数。变换的过程是将矩阵X中的每个元素扩大10倍,然后再向上取整得到整数矩阵Y:
Y包含10种整数,并且Y中的每行每列的数字都不重复,接下来把这10个数字映射成具体的查询ID,映射的关系如下:
根据映射表最终得到在MPL为3下的查询组合为:
在矩阵Z中,每一行代表一个查询组合,每一行的第一个查询代表该查询组合的主查询,其余都是并发查询。在每个查询组合中,每个查询构成一个查询流,查询流就是让每个查询运行n次,这样就得到n个样本数据,这里只取后n-1次的数据。
2.4 预测评价
为了测量预测模型质量,本文使用平均相对误差MRE(mean relative error)来衡量,该度量的定义如下:
(1)
observedi为实际运行的时间,predictedi为预测的时间,MRE越低,说明预测模型越准确。
3 预测模型
该部分讲述如何对主查询和并发查询的I/O和网络资源争用进行建模。本文提出了查询干扰度和查询敏感度两个模型,查询干扰度用来描述主查询当前执行环境的优劣,也即描述资源的争用情况,而查询敏感度是描述主查询在不同并发查询执行时,它的性能如何变化。
3.1 查询干扰度
I/O和网络是影响数据库查询性能最重要的两个因素,在一定程度上能够决定查询总延迟。假定一个查询组合为m,它包括主查询q和与主查询并行执行的查询C={c1,c2,…,cn},并发查询的个数为n。首先,得到每个并发查询ci单独运行时需要的I/O和网络资源,此时,没有发生资源竞争。然后,估计每个并发查询与主查询争用资源对主查询的影响。最后,评估由于并发查询之间争用资源对主查询的影响。定义变量如表2所示。
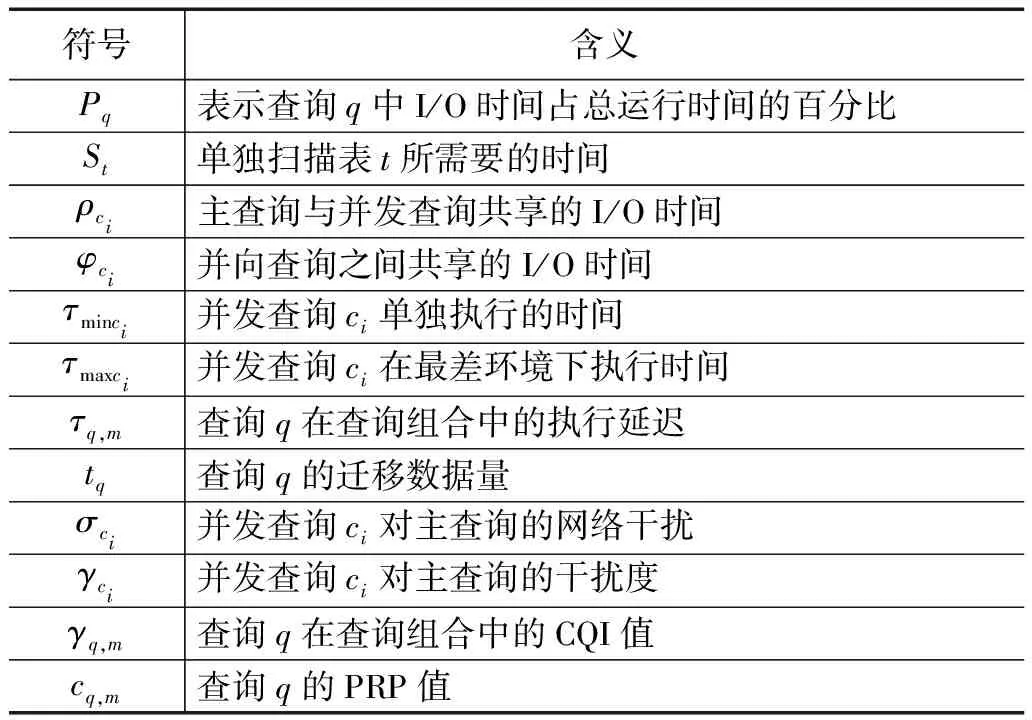
表2 主要符号含义
3.1.1 Baseline I/O
Baseline I/O指的是查询的基准I/O,即当一个查询独立执行时,它的I/O时间占用执行总时间的百分比,所占百分比越大,则表示此查询需要越多的I/O资源。用表示一个并发查询中I/O所占的百分比。
3.1.2 Positive I/O
当主查询与并发查询共同执行时,如果一个并发查询与主查询扫描不同的表,并发查询会对主查询产生“干扰”,这是因为不同查询会争用I/O。当并发查询与主查询扫描相同的表时,这种“干扰”会大大减小,甚至会对主查询产生“促进”作用,因为在数据库中,当频繁扫描一个表时,会把这个表的数据存入到共享缓存中,此后再请求这个表的数据,会直接从共享缓存中取,从而避免了重复性的I/O操作。下面通过模型来量化并发查询与主查询的相互作用。
假设表t是主查询q与并发查询ci共同扫描的表。定义如下值:
(2)
可以看到htci取值只有0和1,下面计算共享的I/O时间。
(3)
上述公式中,n表示主查询和并发查询需要扫描表的总个数,St表示扫描表t花费的时间。本文用select * from[table]形式的查询语句获取扫描表[table]花费的总时间,即该查询语句执行时间中的扫描表的时间。在Greenplum中,表的数据分布到各个节点中,查询在各个节点中执行,所以,多个查询如果包含共同的表,则可“省去”重复在磁盘上扫描表的时间。公式(3)计算由于共享I/O的而节省的时间。
3.1.3 Concurrent I/O
除了考虑主查询和并发查询的共享I/O之外,还需要度量并发查询之间的I/O影响。即主查询与两个并发查询a和b共同执行时,a和b由于并发执行所节省的I/O时间。首先定义表t为并发查询和其他非主查询共同扫描的表:
(4)
定义dt为扫描表t的并发查询的个数,这里dt必须大于1。另外,由于只考虑并发查询之间的表扫描情况,所以这里的表t不能出现在主查询当中。计算由于并发查询共享I/O而节省的时间为:
(5)
上面公式中的n同样是主查询和并发查询需要扫描表的总数。
3.1.4 网络争用
本文面向的是分布式数据库,数据分布在集群中的各个节点中,SQL查询中的表连接操作一定会发生数据传输,即把在一个节点上的数据迁移到另一个节点上。Greenplum中数据迁移的方式有两种:广播和重分布。广播就是把一个节点上的数据传输给其他所有节点,从而每个节点都有一个表的完整数据。重分布就是把表的数据根据关联键计算哈希值,然后再重新分布到各个节点上。假设一个表的记录数为N,那么重分布的数据量为N,广播的数据量为N*节点数,通过上述的方式就可以计算一个连接操作的数据迁移量。主查询的数据迁移总量为tq,并发查询的迁移数据量为,tci定义并发查询对主查询的网络干扰为:
(6)
从上式可以看出,并发查询ci的数据迁移量越大,对主查询的干扰就越大;反之,则越小。这是由于系统的网络带宽是一定的,当网络中有其他查询传输数据时,必然会影响主查询的数据传输。
3.1.5 查询干扰度模型
得到上述各个变量以后,就可以定义并发查询对主查询的影响。
(7)
公式(7)可以理解为并发查询ci与主查询直接竞争I/O和网络的激烈程度,公式(7)的前半部分是主查询减去了并发查询与主查询共享I/O的时间,在网络争用确定的情况下,当γci越大,则表示并发查询与主查询共享I/O的时间越短,竞争I/O的时间越长,在这种情况下,会延长主查询的查询延迟。当γci越小,则表示并发查询与主查询的资源竞争越小,对主查询的延迟影响越小。
在一个查询组合中,定义主查询的CQI值为γq,m,计算公式如下:
(8)
上述公式即取各并发查询的γci平均值。
3.2 查询敏感度
查询敏感度是指主查询对不同执行环境的敏感程度,这里不同的执行环境就是不同的MPL以及在相同MPL下的不同查询组合。敏感程度指主查询的性能变化,不同的执行环境会引起不同的资源竞争,进而导致主查询的性能变化。下面详细介绍该模型。
3.2.1 查询性能区间
查询性能区间PR(performance range)指的是一个查询延迟时间范围,这个区间中的值表示查询在不同环境中的执行时间,区间的最大值为τmaxci,表示查询在最恶劣的资源环境下的执行时间。本文通过不断读取大文件并在不同节点间交换传输这些文件模拟最差的环境。最小值为τminci,表示在当前环境中,只有这个查询在执行时的延迟时间。上述两个值表示在极端执行环境中的执行查询,在其余环境下的查询执行时间都位于该查询性能区间中,主查询的PRP(performance range point)值定义如下:
(9)
当知道了cq,m的值以后,将该值代入公式(9)反推可得到τq,m,即主查询的查询延迟。接下来,介绍如何预测cq,m的值。
3.2.2 查询敏感度模型
在3.1节介绍了CQI模型,该模型可以用于预测查询延迟(后面通过实验具体验证)。这意味着,给定一个查询组合m和一个主查询q,可以利用公式(8)来计算CQI值,然后使用线性回归模型预测查询的性能。为了进一步说明查询性能和CQI之间的线性关系,本文引入查询敏感度QS(query sensitivity)。
假定CQI和PRP存在线性的关系,定义如下公式:
cq,m=μq*γq,m+bq
(10)
上述公式中,μq为斜率,bq为截距,cq,m与γq,m是一种线性关系。
3.2.3 预测流程
在Greenplum中,利用QS模型预测查询q的流程如图1所示。
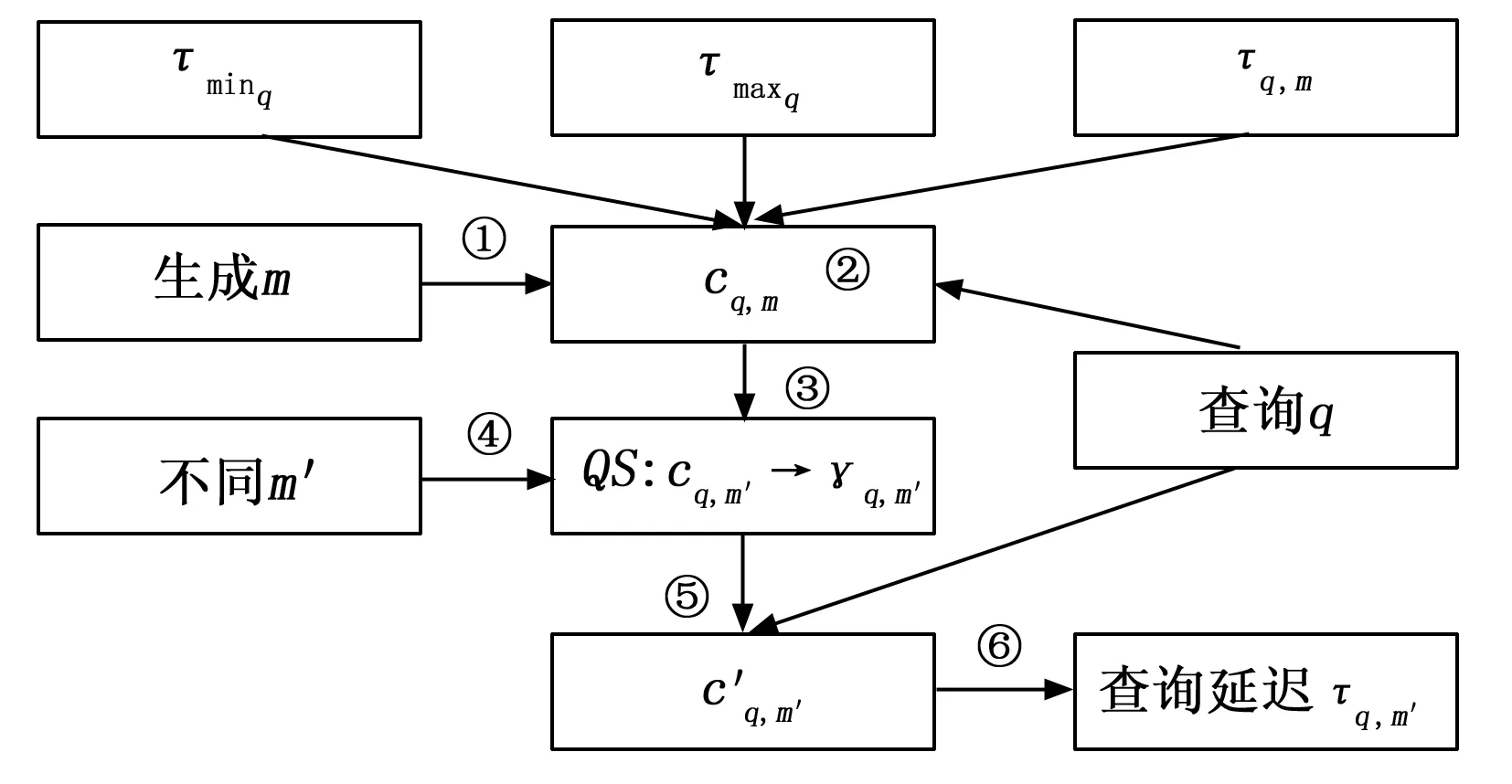
图1 利用QS预测查询延迟
4 实验评估
4.1 实验环境
实验的环境为Greenplum分布式集群,Greenplum版本为5.0.0-alpha+79a3598。集群中共有4个节点,一个主节点和3个从节点,从节点主要用来存放数据并执行查询,主节点则负责分配查询和汇总结果。主节点的硬件配置为32 GB的内存,CPU为4核Intel(R)Xeon(R)CPU E5-2630 v2 @ 2.60 GHz,从节点的内存16 GB,CPU的核数和型号与主节点相同,在每个从节点中有4个数据库实例,每个数据库实例相当于一个完整PostgreSQL的数据库,用于处理一部分的数据。主节点和从节点的操作系统均为CentOS 7.4,linux内核版本为3.10。
表和数据通过TPC-DS生成,TPC-DS是一个决策支持的benchmark。实验所用数据量大小为50 G,选取TPC-DS中的10个模板生成10个查询用于训练和测试模型,这10个查询主要是I/O敏感型查询,执行时间较长,有利于提高预测模型的精度。
4.2 实验过程
在第3节详细讲述了如何利用查询干扰度和查询敏感度模型预测一个查询的延迟时间,下面通过实验验证上述的模型方法。具体实验过程说明如下:
在实验环境中,基于Greenplum数据库集群的默认配置,执行TPC-DS基准测试。并通过设置Greenplum的并行度参数,控制同时执行的查询数分别指定的MPL(例如:1-5)。与此同时,通过性能监控工具Telegraf采集服务器的各项资源开销数据,并结合Greenplum返回的查询执行时间等性能数据,构建下述提到的查询干扰度模型和查询敏感度模型,并据此进行分析型查询的性能预测。
4.2.1 查询干扰度模型
3.1节介绍了主查询q在查询组合m中的查询干扰度,接下来,通过实验验证通过该模型预测查询延迟是否有效。
1)查询干扰度模型分量:
查询干扰度评估了并发查询对主查询的干扰程度,干扰程度越大,对主查询的延迟也就越大。在查询干扰度模型中,下面分别对干扰度模型中的4个分量进行验证。
首先是基准I/O(baseline I/O),当模型中只有baseline I/O时,计算一个并发查询的干扰度会变成如下形式:
γci=(τminci*Pci)/τminci
(11)
公式只计算了并发查询与主查询竞争的I/O带宽,相当于并发查询与主查询是完全竞争的关系。
其次,在基准I/O的基础上,加入并发查询与主查询的正向交互作用因素,即positive I/O,得到如下形式:
γci=(τminci*Pci-ρci)/τminci
(12)
式(12)从争用的I/O时间中减去了由于共享表扫描所节省的时间,该公式主要考虑了并发查询对主查询的影响。
然后,再进一步考虑并发查询之间的交互,即concurrent I/O,所得模型如下:
γci=(τminci*Pci-ρci-φci)/τminci
(13)
式(13)即在式(12)的基础上加入了在一个查询组合中,并发查询之间的共享I/O时间。并发查询之间的作用会间接影响主查询的I/O操作。
最后,再加入网络争用的因素,得到CQI模型:
(14)
2)查询干扰度模型验证:
首先评估CQI的各个分量对误差率的影响,然后利用CQI预测查询延迟。当MPL为3时,上述各个变量对查询延迟的预测误差如下:
从图2可以看到,只利用baseline I/O(对应公式(11))预测查询延迟的时候,它的误差较大,当加入并发查询交互(对应公式(12))的因素后,对误差率有明显的降低。考虑concurrent I/O(对应公式(13))和网络争用因素(对应公式(14)),对预测的准确率没有明显提高,说明positive I/O是影响预测模型准确率的主要因素,其他因素能够小幅度的提升准确率。综上,CQI考虑了并发查询之间的主要影响因素,是一个较好的预测模型。接下来,验证CQI模型对各个查询的误差。
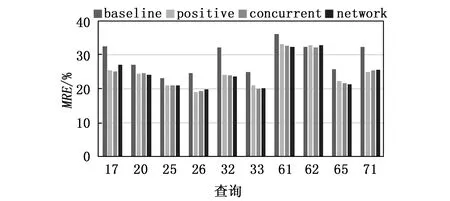
图2 各个查询在不同度量下的误差
对于一个给定的查询组合,其中有一个主查询,其他查询为并发查询。实验产生的数据分为训练集和测试集。假设主查询的查询延迟和CQI存在线性关系,则通过训练集能够得到这个线性关系,然后,利用该线性模型对主查询进行预测,再与测试集数据比较并计算误差,从而得到图3。
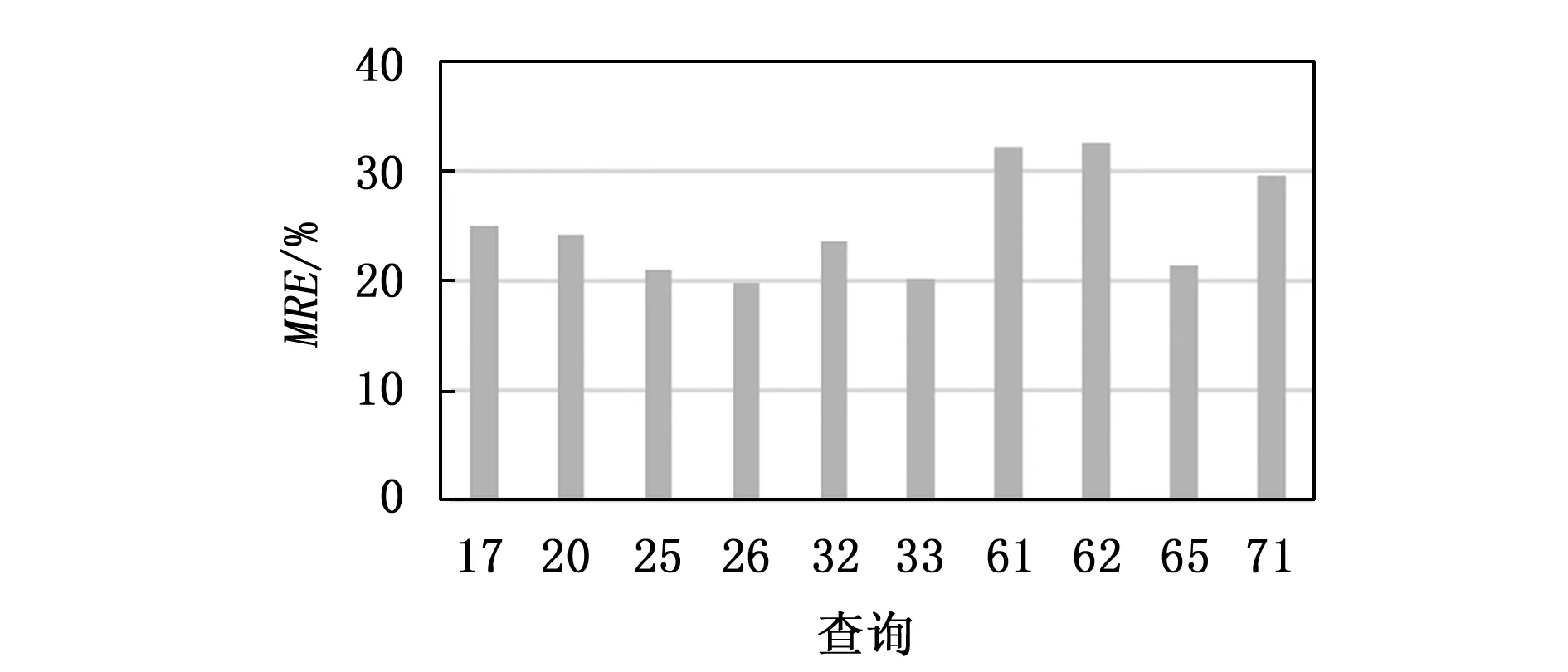
图3 各个查询在MPL等于3时的误差
图3为10个查询在MPL为3时的预测情况,从图中可以看到,查询延迟预测的误差大部分在25%以下。此处的误差是平均相对误差(MRE),其定义已经在公式(1)中给出。查询61和62的误差相对较高,这是由于这两个查询相对较为简单,查询时间较短,因而其它因素查询预测的干扰较大,导致误差相对较大。在实验中,查询71的误差也相对较高。该查询较为复杂,主要用于“对于指定的经理及其关联的所有3个销售渠道,找出其一个月内在早餐或晚餐时间段营收最高的产品”,其执行时间较长,因而误差相对率偏高。该查询的标准SQL形式如下:
select i_brand_id brand_id, i_brand brand,t_hour,t_minute,
sum(ext_price)ext_price
from item,(select ws_ext_sales_price as ext_price,
ws_sold_date_sk as sold_date_sk,
ws_item_sk as sold_item_sk,
ws_sold_time_sk as time_sk
from web_sales,date_dim
where d_date_sk = ws_sold_date_sk
and d_moy=12
and d_year=2002
union all
select cs_ext_sales_price as ext_price,
cs_sold_date_sk as sold_date_sk,
cs_item_sk as sold_item_sk,
cs_sold_time_sk as time_sk
from catalog_sales,date_dim
where d_date_sk = cs_sold_date_sk
and d_moy=12
and d_year=2002
union all
select ss_ext_sales_price as ext_price,
ss_sold_date_sk as sold_date_sk,
ss_item_sk as sold_item_sk,
ss_sold_time_sk as time_sk
from store_sales,date_dim
where d_date_sk = ss_sold_date_sk
and d_moy=12
and d_year=2002
)tmp,time_dim
where
sold_item_sk = i_item_sk
and i_manager_id=1
and time_sk = t_time_sk
and(t_meal_time = ‘breakfast’ or t_meal_time = ‘dinner’)
group by i_brand, i_brand_id,t_hour,t_minute
order by ext_price desc, i_brand_id
总体而言,除去类似于查询61和查询62这类因查询任务简单、执行时间短,易受干扰的查询,以及查询71这类非常复杂的查询,TPC-DS的代表性查询在MPL为2、4和5时的资源预测情况与MPL为3时类似,大部分查询误差率仍在25%以下。
4.2.2 查询敏感度模型
前面的实验验证了CQI可以较准确地预测查询延迟,而CQI是针对特定的查询组合,为此,本文提出了QS模型,它能够感知查询所处的不同环境(不同的查询组合),并做出预测。
对于一个特定的查询q,找到包含这个查询的查询组合,然后以q为主查询构建QS模型,利用该模型预测执行时间,并与实际执行时间比较,得到结果如图4所示。
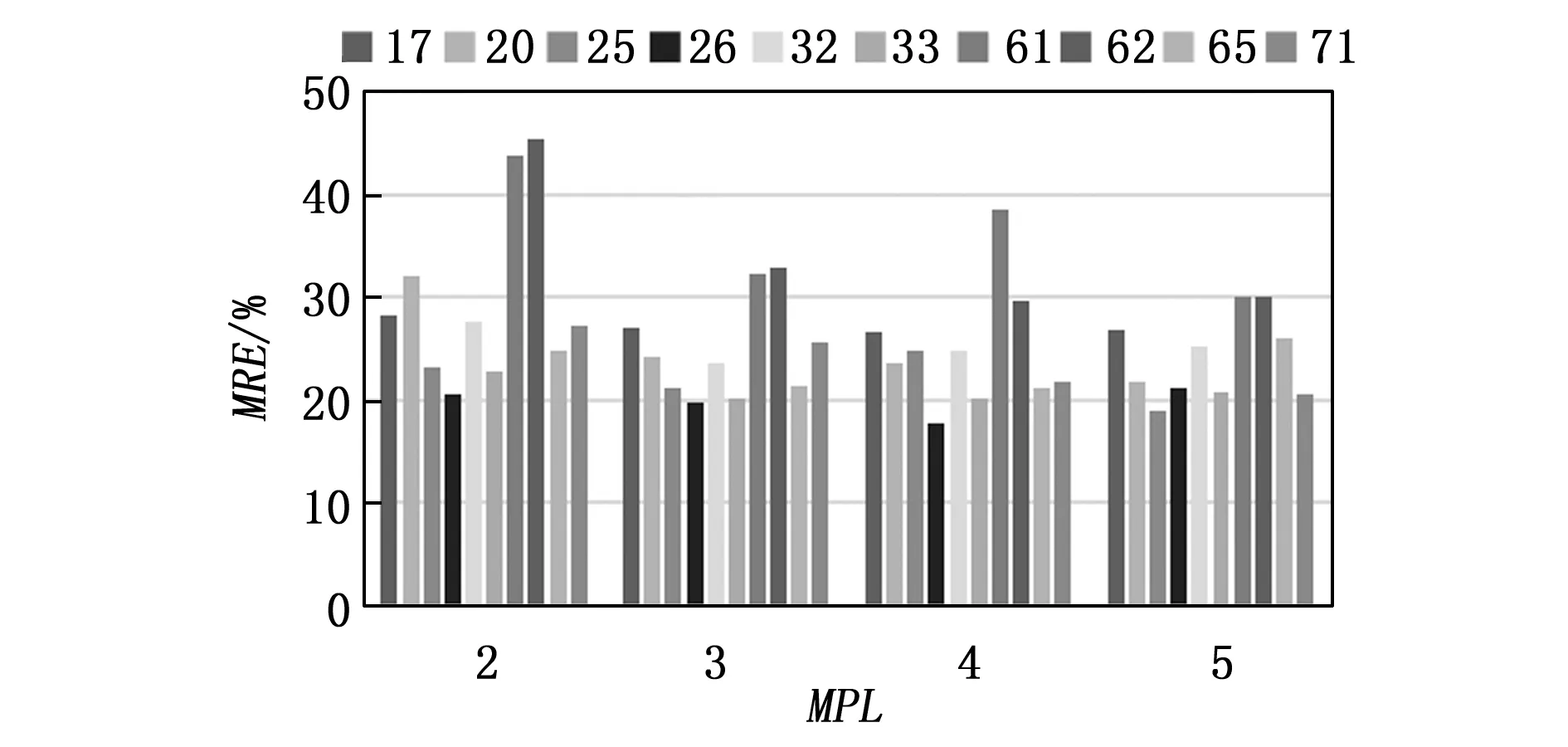
图4 各个查询在不同MPL时的误差
从图4可以看出,不同的MPL,除去查询61和62,查询的误差都在25%以下,有的甚至能够达到20%以下。同样的,查询61和62的误差较高的原因在于它们的执行时间较短,从而造成误差较大。由此实验结果表明,QS模型能够适应不同的查询执行环境(不同MPL下的不同查询组合),从而能够较准确地预测查询的执行延迟。
5 结束语
本文主要研究在分布式数据库中预测一个查询在多个其他查询并行执行的情况下其执行时间的技术,考虑了I/O和网络因素,这与其他基于机器学习的在单机数据库上的性能预测技术有明显不同。
本文主要提出了两个模型,分别为:查询干扰度和查询敏感度。查询干扰度(CQI)用于建立资源竞争的衡量模型,而查询敏感度(QS)用于衡量主查询对其他并发查询的感知度。查询敏感度是建立在查询干扰度的基础上,通过实验发现CQI与查询延迟存在线性关系,而QS则在CQI的基础上建立这种线性模型,从而利用QS预测查询延迟。
最后,实验结果表明模型的预测误差率大部分能够维持在25%以下,能够较准确地预测查询的延迟时间。在此后的工作中,可以考虑如何使用更有效的指标来量化资源的竞争,以及如何利用查询执行计划辅助来建立预测模型。
猜你喜欢
电气技术(2022年8期)2022-08-20
中华骨与关节外科杂志(2021年8期)2021-11-30
今日农业(2021年17期)2021-11-26
今日农业(2021年17期)2021-11-26
军民两用技术与产品(2021年5期)2021-07-28
西安邮电大学学报(2021年6期)2021-05-10
软件(2020年3期)2020-04-20
智富时代(2018年5期)2018-07-18
智富时代(2018年5期)2018-07-18
新西部下半月(2017年6期)2017-07-19
