
四阶巢式设计分组随区组试验的非平衡数据处理的理论研究
2022-11-01 02:35包小梅何贵平
山东林业科技 2022年4期
齐 明,包小梅,何贵平*,张 振
(1.中国林业科学研究院亚热带林业研究所,浙江 杭州 311400;2.浙江省遂昌县生态林业发展中心,浙江 遂昌 323300)
在林木遗传改良中,为了制定正确有效的选择育种方案,需要了解群体内不同层次的遗传变异信息,为此林木育种工作者经常采用多阶巢式设计[1-6]。1962年Charles EG 等人[7]发表了平衡数据的四阶巢式设计的方差分析原理;2006年El-Saeiti I N 等人[8,9]发表了有缺失数据的四阶巢式设计的方差分析原理。这些研究美中不足是没有考虑区组效应和参试因子与区组重复间的互作,这极大地限制了这些模型在林木遗传育种中的应用。由于四阶巢式设计试验在林木遗传改良中还有一定的市场,例如:种源—林分—家系—个体间的变异;或林分—家系—个体—无性系试验的变异等等。2009年齐明[10]提出了一个转化理论,建议采用转化分析法,构建了一个包含区组重复效应和参试因子与区组重复间互作的线性模型,开发了林木遗传育种中四阶巢式设计的方差分析原理,但其缺点是忽视了在方差分析中一级参试因子与二级参试因子,二级参试因子与三级参试因子间不独立的事实,因此现在有必要对此研究作进一步的完善。另外本研究考虑了在林木遗传育种中四阶巢式设计的田间试验,参试材料众多,田间试验通常采用分组随机区组设计[1-6]的事实,建议使用环境指数对各亚区组内数据调整后[11],然后采用转化分析法的思想[10]进行非平衡(缺株)、非规则(缺区)试验数据处理。下面以种源—林分—家系—个体四阶巢式设计试验为例,进行方差分析的研究。
假定一个树种,从其分布区中抽取5~8 个典型种源,每个种源内抽取5~8 个林分,每个林分中选取5~8株优树,分系采集每个优株的OP 种子,进行育苗造林试验,采用分组随机区组设计,同一种源放在一起,占领一个亚区组,不同种源随机排列,十个重复,4 株行状小区。采用我们介绍的方法,先用每个重复内的环境指数,对各亚区组参试植株观察值进行调整[11],再将每个重复内的k 株小区转化为k 个重复的单株小区试验,进而采用转化分析法构建的随机模型进行数据处理[10]。
根据我们的研究成果,数据转化后,在非平衡条件下,所有的参试因子均符合线性,正态的前提条件。种源与重复互作因子肯定是遵从正态分布;而家系与区组重复间因无重复,其互作效应可以不考虑,因此线性模型中不包括此项因子;而林分与区组互作因子,在理论上遵从二项分布,有可能获得负的方差分量,也有可能获得正的方差分量,但为了模型的通用性,仍将其包含在模型中。如果采用此模型获得负的方差分量,可将此项因子删去,重构线性模型进行分析,这可仿两因素随机区组试验(析因设计)的方法[10]进行。
1 转化后的线性模型:
以单株观察值参与统计分析时,平衡不平衡、规则不规则的线性模型如下:
yijklm=u + bi+ pj+ sk/j+fl/k+ (pb)ij+(sb)ik+ eijklm
这里: i=1→a;j=1→p;k=1→s;l=1→f;m=1 或0
对于以上线性模型,在随机模型条件下,有如下约束条件:
(1)E(bi)=0;E(pj)=0;E(sk/j)=0;E(fj/l)=0;E(pb )ij)=0;E (sb)ik=0;E(eijklm)=0;
(2)在上述线性模型中,u 是群体平均效应;bi 是重复效应;pj是种源效应;sk/j是第j 个种源内第k 个林分效应;fl/k是第k 个林分中第l 个家系的随机效应;(Pb)ij是种源与重复的互作效应;(sb)ik是林分与重复间的互作;eijkl是随机误差。所有的因子在随机条件下进行试验,因此有: bi∽N(0,σb2) ;pj∽N(0,σp2);sk/j∽N(0,σs/p2);fl/k∽N(0,σf/s2);(Pb)ij∽N(0,σpb2);(sb)ik∽N(0,σsb2);eijkl∽N(0,σe2).
2 离差平方和的分解

仿照Henderson CR[12]的做法,对上式取数学期望,因此对以上等式有:所有参试因子两两之积的交叉项为0,于是有下式:
即,SST= SSb+ SSp+ SSs/p+ SSf/s+ SSpb+SSsb+SSe
这样可以得如下离差平方和的分解结果。
3 各因子效应的离差平方和
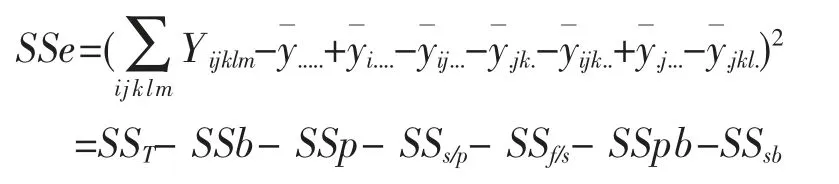
上式SSe 的展开式太复杂,实际中可用SSe=SST-SSb-SSp-SSs/p-SSf/s-SSpb-SSsb来计算SSe以上各因子效应平方和中的Y 和N 分别表示因子效应的求和及其参试子代样本数。
4 期望均方结构
从线性模型出发,推导期望均方结构,先对各参试因子的参试子代数加以说明。
nijkl表示第i 个重复内第j 个种源内第k 个林分内第l 个家系的参试子代数;nijkl=1 或0;
ni…表示第i 个重复内的参试子代数;
n.j..表示第j 个种源内的参试子代数;
n..jk.表示第j 个种源内第k 个林分因子内的参试子代数;
n..jkl表示第j 个种源内第k 个林分因子内第l 个家系内的参试子代样本数;
nij..表示第j 个种源在第i 个重复内的参试子代数;
nijk.表示第j 个种源内第k 个林分在第i 个重复内的参试子代数;
N....表示试验林中全部的参试子代数;
转化后的线性模型:yijklm=u+bi+pj+ sk/j+fl/k+ (pb)ij+(sb)ik+eijklm
这里: i=1→a;j=1→p;k=1→s;l=1→f;m=1 或0
根据线性模型,可推导出表1中的结果。
随机模型条件下,各参试因子的方差系数如表1。

表1 随机模型条件下,四阶不平衡巢式设计各因子的方差分量系数表Table 1 Variance component coefficients of each factor in fourth-order unequal nested design under random model
5 自由度的分解

表2 自由度分解
6 期望均方结构
四阶不平衡巢式设计模式转化分析法的期望均方结构列于表3。

表3 四阶不平衡巢式设计模式转化分析法的期望均方结构Table 3 Expected mean square structure of transformation analysis for four-order unbalanced nested design
这里: 期望均方=期望平方和/自由度,方差调节系数K 值从期望平方和表1中计算而来。



7 主效因子的F 检验
第一步,根据期望均方结构,建立联立线性方程组,求出σb2,σp2,σs/p2,σf/s2,σpb2,σsb2,σe2方差份量。
σe2+K1σsb2+K2σpb2+K3σf/s2+K4σs/p2+K5σp2+K6σb2=MSb
σe2+K7σsb2+K8σpb2+K9σf/s2+K10σs/p2+K11σp2+K12σb2=MSp
σe2+K13σsb2+K14σpb2+K15σf/s2+K16σs/p2+K17σp2+K18σb2=MSs/p
σe2+K19σsb2+K20σpb2+K21σf/s2+K22σs/p2+K23σp2+K24σb2=MSf/s
σe2+K25σsb2+K26σpb2+K27σf/s2+K28σs/p2+K29σp2+K30σb2=MSpb
σe2+K31σsb2+K32σpb2+K33σf/s2+K34σs/p2+K35σp2+K36σb2=MSsb
σe2+K37σsb2+K38σpb2+K39σf/s2+K40σs/p2+K41σp2+K42σb2=MSt
第二步,运用行列式知识求解(可用矩阵法求解,但是为了进行F 检验,用行列式法还是必须的),如下:


于是σb2=Db/D;σp2=Dp/D;σs/p2=Ds/p/D;σf/k2=Df/s/D;σpb2=Dpb/D;σsb2=Dsb/D;σe2=DE/D
为了进行主效因子的F 检验,除了将D 计算出行列式的具体数值外,其余的行列式是将MSb,MSp,MSs/p,MSf/s,MSpb,MSsb,MSt示为未知数,进行计算,合并同类项再将σb2,σp2,σs/p2,σf/s2,σpb2,σsb2,σe2展成MSb,MSp,MSs/p;MSf/s,MSpb,MSsb,MSt的线性函数,例:
σb2=β1MSb+β2MSp+β3MSs/p+β4MSf/s+β5MSpb+β6MSsb+β7MSt
σp2=β8MSb+β9MSp+β10MSs/p+β11MSf/s+β12MSpb+β13MSsb+β14MSt
σs/p2=β15MSb+β16MSp+β17MSs/p+β18MSf/s+β19MSpb+β20MSsb+β21MSt
σf/s2=β22MSb+β23MSp+β24MSs/p+β25MSf/s+β26MSpb+β27MSsb+β28MSt
σpb2=β29MSb+β30MSp+β31MSs/p+β32MSf/s+β33MSpb+β34MSsb+β35MSt
σsb2=β36MSb+β37MSp+β38MSs/p+β39MSf/s+β40MSpb+β41MSsb+β42MSt
σe2=β43MSb+β44MSp+β45MSs/p+β46MSf/s+β47MSpb+β48MSsb+β49MSt
上述线性方程中,β1,β2…β49为已知系数,这样做的目的是为了在进行主效因子的F 检验时,配合参比均方,计算出该均方的自由度。
例,在对种源效应作显著性检验时,σe2+K7σsb2+K8σpb2+K9σf/s2+K10σs/p2+K11σp2+K12σb2=MSp
F= MSp/MSx∽遵从
这里,MSx=σe2+K7σsb2+K8σpb2+K9σf/s2+K10σs/p2+K12σb2
将上述σe2,σsb2,σpb2,σf/s2,σs/p2,σb2展成MSb,MSp,MSs/p;MSf/s,MSpb,MSsb,MSt的线性函数,并代入MSx中,再合并同类项,再展成MSb,MSp,MSs/p,MSf/s,MSpb,MSsb,MSt的线性函数,
假设为:MSx=α1MSb+α2MSp+α3MSs/p+α4MSf/s+α5MSpb+α6MSsb+α7MSt
如果MSx的自由度为Nx,则MSx/Nx∽X2(Nx)
因此有下式:

有了Nx,便可以根据查F 表,对假设前提,作出判断,肯定或否定假设。
其它因子的F 检验可依照此例进行,为了节约篇幅,此处从略。
8 因子效应的多重对比
四阶不平衡巢式设计,其因子效应的多重对比十分繁复。
这可仿三阶巢式设计平衡不平衡试验资料分析方法中的做法进行[10]。
9 四阶不平衡巢式设计遗传力的计算
种源遗传力:
hp2=σp2/[(1/K11)σe2+(K7/K11)σsb2+(K8/K11)σpb2+(K9/K11)σf/s2+(K10/K11)σs/p2+σp2+(K12/K11)σb2];
种源内的林分遗传力:
hs/p2=K16σs/p2/[σe2+K13σsb2+K14σpb2+K15σf/s2+K16σs/p2+K17σp2+K18σb2] ;也可分子分母同除K16
林分内家系遗传力:
hf/s2=K21σf/s2/[σe2+K19σsb2+K20σpb2+K21σf/s2+K22σs/p2+K23σp2+K24σb2] ;也可分子分母同除K21
家系内单株遗传力:
hi2=4σf/s2/[σf/s2+σb2+σe2]或3σf/k2/[σf/s2+σb2+σe2]
10 四阶巢式设计分组随区组试验的非平衡数据处理软件
四阶巢式设计分组随区组试验的非平衡数据处理,可采用《林木遗传育中平衡不平衡、规则不规则试验数据处理技巧》中的MLAP 软件,采用R2016a 平台进行。
猜你喜欢
农村科学实验(2022年15期)2022-10-13
中国农学通报(2022年3期)2022-03-05
读与写·教育教学版(2019年9期)2019-10-30
赢未来(2019年15期)2019-08-14
华人时刊(2018年17期)2018-11-19
卷宗(2018年14期)2018-06-29
数学学习与研究(2018年7期)2018-05-16
小资CHIC!ELEGANCE(2018年8期)2018-04-03
山东青年(2017年11期)2018-03-29
吉林农业(2016年7期)2016-05-14
