
语义保持哈希在跨模态检索中的应用
2022-11-16 02:25康培培林泽航杨振国张子同刘文印
计算机工程与应用 2022年21期
康培培,林泽航,杨振国,张子同,刘文印
1.广东工业大学 计算机学院,广州 510006
2.香港理工大学 计算机学院,香港 999077
3.华南农业大学 数学与信息学院,广州 510642
跨模态检索旨在根据一个模态的查询样本(如文本),检索与其相关的其他模态的样本(如图像),具有研究和应用价值[1]。例如,给定一段文本描述的语句,用于搜索其描述的语义场景图像或视频。由于各模态具有不同的数据表示,不同模态的样本间并不能直接进行相似性比较。现有的跨模态检索方法通常将各模态数据变换到潜在的共同空间,从而进行相似度比较。由于哈希表示能够节省存储空间,加快检索速度,基于哈希表示的跨模态检索引起广泛关注[2]。
依据训练过程中是否用到语义标签,跨模态哈希方法分为无监督方法和有监督方法。无监督跨模态哈希方法在训练过程中不依赖于语义标签[3]。例如,Ding等人[4]提出联合矩阵分解哈希(collective matrix factorization hashing,CMFH),对不同模态的数据进行联合矩阵分解,学习统一的哈希编码。Irie等人[5]提出交互共量化方法(alternating co-quantization,CCA-ACQ),从最小化各模态二值化误差的角度提高跨模态检索准确率。Zhou 等人[6]提出潜在语义稀疏哈希(latent semantic sparse hashing,LSSH),利用稀疏表示和矩阵分解探索多模态数据之间的相关性。
有监督的跨模态哈希方法将语义信息融合到哈希编码中,所以能取得更好的检索效果[7-8]。Lin等人[9]提出语义保持哈希(semantics-preserving hashing,SEPH),将语义相似矩阵作为监督信息,通过最小化KL 分布学习统一的哈希编码,进而利用核逻辑回归学习非线性哈希函数。Zhang等人[10]研究大规模数据背景下的有监督学习,提出语义相关性最大化方法(semantic correlation maximization,SCM)。Xu 等人[11]提出有鉴别力的跨模态哈希(discrete cross-modal hashing,DCH),通过线性投影矩阵将各模态数据投影到汉明空间,再将共同哈希编码变换到语义空间,使学习的哈希编码具有鉴别性。随着神经网络的发展,很多基于深度学习的跨模态方法成为研究的主流[12-13]。本文关注于研究语义结构保持哈希方法的有效性,未来会将其扩展到深度学习框架,进一步提高检索准确率。
多数有监督的跨模态哈希方法以一种逻辑回归的方式学习有鉴别力的哈希编码[14],或者构造语义结构图将语义信息融入哈希编码[15]。然而,这些方法忽略了哈希函数的语义鉴别性。在检索过程中,哈希函数将查询样本变换到汉明空间,通过与数据库样本的哈希编码进行比对,返回检索序列。在这一过程中,如果只是哈希编码具有鉴别力,而哈希函数却不能将新样本变换为有鉴别力的哈希编码,那么检索效果也会受到很大影响。为了同时学习具有语义保持的哈希编码和哈希函数,本文提出一种语义保持哈希方法(semantic preserving hash,SPH)用于跨模态检索。通过引入两个不同模态的哈希函数,本文将不同模态空间的样本映射到共同的汉明空间。为使哈希编码和哈希函数均具有较好的语义鉴别性,引入了语义结构图,并结合局部结构保持的思想,将哈希编码和哈希函数的学习融合到同一个框架,使两者同时优化。在三个公开的多模态数据集上的实验证明了该方法在跨模态检索任务的有效性和优越性。本文的主要贡献总结如下:
(1)本文提出SPH,将哈希编码和哈希函数的学习融合到同一个框架,共同保持语义结构信息。
(2)本文为SPH 提出一种交替优化算法,通过迭代的方式学习离散哈希编码。
(3)本文在三个数据集上进行大量实验对比,验证了SPH及优化算法的有效性。
1 相关工作
1.1 DCH
此外,DCH 通过两个线性映射函数U∈Rdx×K和V∈Rdy×K将两个模态的数据映射到共同哈希编码,并最小化各模态的投影误差,用来学习各自模态的哈希函数。其目标函数为:
其中,μV和μT为惩罚参数,λ为正则化参数,||·||22为向量的L2范数,|||·||2F为矩阵的Frobenius范数。
1.2 局部保持投影
假定W∈Rd×c为投影矩阵,将原始数据T投影到潜在的低维表示H,LPP整体的目标函数定义为:
2 语义保持哈希
本文的跨模态检索关注于两个模态,为了方便阐述,以文本和图像两种模态为例,框架图如图1 所示。本章后续部分先进行符号化的问题描述,而后介绍SPH的模型框架以及优化算法。
2.1 问题描述
2.2 模型
为了消除不同模态间的语义鸿沟,本文为图像和文本两种模态的数据学习共同的哈希编码B。理想情况下,B应具有区分不同类别的特性,使得在检索时更易检索出同类的样本,从而提高检索准确率。为此,引入一个线性映射矩阵W∈RK×c,将哈希编码映射到其对应的类别标签,使其具有语义鉴别性,公式表示为:||·||F为矩阵的F范数。此外,为使图像和文本数据得到共同的哈希编码,本文为两种模态的数据各学习一个哈希函数,即Hx(x)=sgn(UTx)和Hy(y)=sgn(VTy),用于将样本在不同模态的表示变换到共同的哈希表示。考虑到符号函数sgn(·)难以优化的问题,这里对不同模态的数据直接线性变换并逼近于哈希表示,即:
这样,第i个样本所对应不同模态的数据表示即可变换到共同的哈希表示bi,从而进行跨模态检索。然而,该过程忽略了样本间的局部结构信息。直观理解上,同一语义的样本所拥有的哈希表示也应近似,而不同语义的样本所拥有的哈希表示也应是远离的。为此,本文引入一个表示样本间语义关系的矩阵S={0,1}n×n,如果li=lj,则Sij=1,否则,Sij=0。借用局部保持投影的思想,本文令哈希编码保持样本间的语义关系:
当样本oi与oj相似时,Sij=1,为使目标函数最小,会学习到相似的bi与bj,从而使哈希表示保持样本间原有的语义结构关系。进一步地,为使新样本也保持语义结构关系,希望哈希函数也具有语义鉴别性,即在学习过程中哈希函数与哈希编码共同保持语义结构关系。所以,公式(6)变为:
当样本oi与oj相似时,Sij=1,为使目标函数最小,会学习到相似的bi与UTxj、VTyj,从而将哈希函数融入语义结构保持的目标中,将新样本变换到语义结构保持的潜在空间。此外,为降低模型复杂度,对各变换矩阵施加Frobenius 范数约束,总的目标函数表示为:
2.3 算法
本文采用交替方向乘子法(alternating direction method of multipliers,ADMM)对目标函数进行优化,即交替地对每个变量分别求解,迭代优化至收敛到局部最优解。具体分为以下几步:
步骤1 更新W
其中,I2∈Rdx×dx为单位矩阵,D为S对应的拉普拉斯矩阵。
步骤3 更新V
类似地,固定目标函数中其他变量,得到关于V的表达式:
其中,I3∈Rdy×dy为单位矩阵。
步骤4 更新B
类似地,固定目标函数中其他变量,得到关于B的表达式:
3 实验结果与分析
3.1 数据集介绍
本文在三个公开数据集上进行实验,分别为Wikipedia[17]、MIRFlickr[18]、和NUS-WIDE[18]。
Wikipedia为最常用的数据集之一,包含2 866 个样本,分别属于10个类中的某一类,每个样本对应图片和文本两种模态的数据。实验中,随机选取2 173 个样本作为训练集和检索数据库,其余的693个样本作为测试(查询)集。每张图像提取SIFT 特征表示为128 维的向量,文本经LDA处理后表示为10维向量。
MIRFlickr 包含25 000 个图片,每个图片有相应的词语标签作为其对应的文本数据,并且人工标注了24个类。剔除掉出现次数少于20 次的标签,最终得到16 783 个样本。随机选取836 个样本作为测试集,其余的样本用于训练和检索。对于每个样本,提取图像的直方图特征,表示为150维的向量,文本用索引向量表示,然后用PCA降维到500维。
NUS-WIDE 包含269 648 个图片和对应的425 059个词语标签,共划分为81 个语义类别。因为有些类别的样本较少,选取前10个大类的样本用于本实验,所以共包含186 577个样本。其中,随机选取1 866个样本作为测试集,其余的作为训练集和检索集。提取500维的SIFT 特征向量作为图像表示,1 000 维的标签索引向量作为文本表示。由于NUS-WIDE 数据量较大,本文采用分批的训练方式进行学习。
3.2 评测方法
本文采用网格搜索法确定各参数值,并在三个数据集上进行两种模态间的相互检索任务,即图像检索文本(Img2Txt)和文本检索图像(Txt2Img)。采用信息检索普遍采用的评价指标—均值平均准确率(mean average precision,MAP)对方法进行评测。每个查询样本都会得到一个平均准确率(average precision,AP),而所有查询样本AP的均值则为MAP。AP的计算公式为:
其中,q为查询样本,R为数据库中与该样本语义相关的样本数,Rp为返回的前p个样本中与q实际相关的个数。如果第p个样本与q语义相关,则rel(p)=1,否则rel(p)=0。此外,也采用Precision@scope 的评价指标对方法进行测评。Precision@scope 曲线展示了检索准确率随检索返回样本数量变化的规律,其值越大,表明方法取得的效果越好。
3.3 MAP比较
表1报告了各数据集上SPH与各方法关于MAP的对比情况,包含了哈希编码长度从16 位到128 位,在两个检索任务(Img2Txt及Txt2Img)的MAP 比较。从表1中,有以下发现:
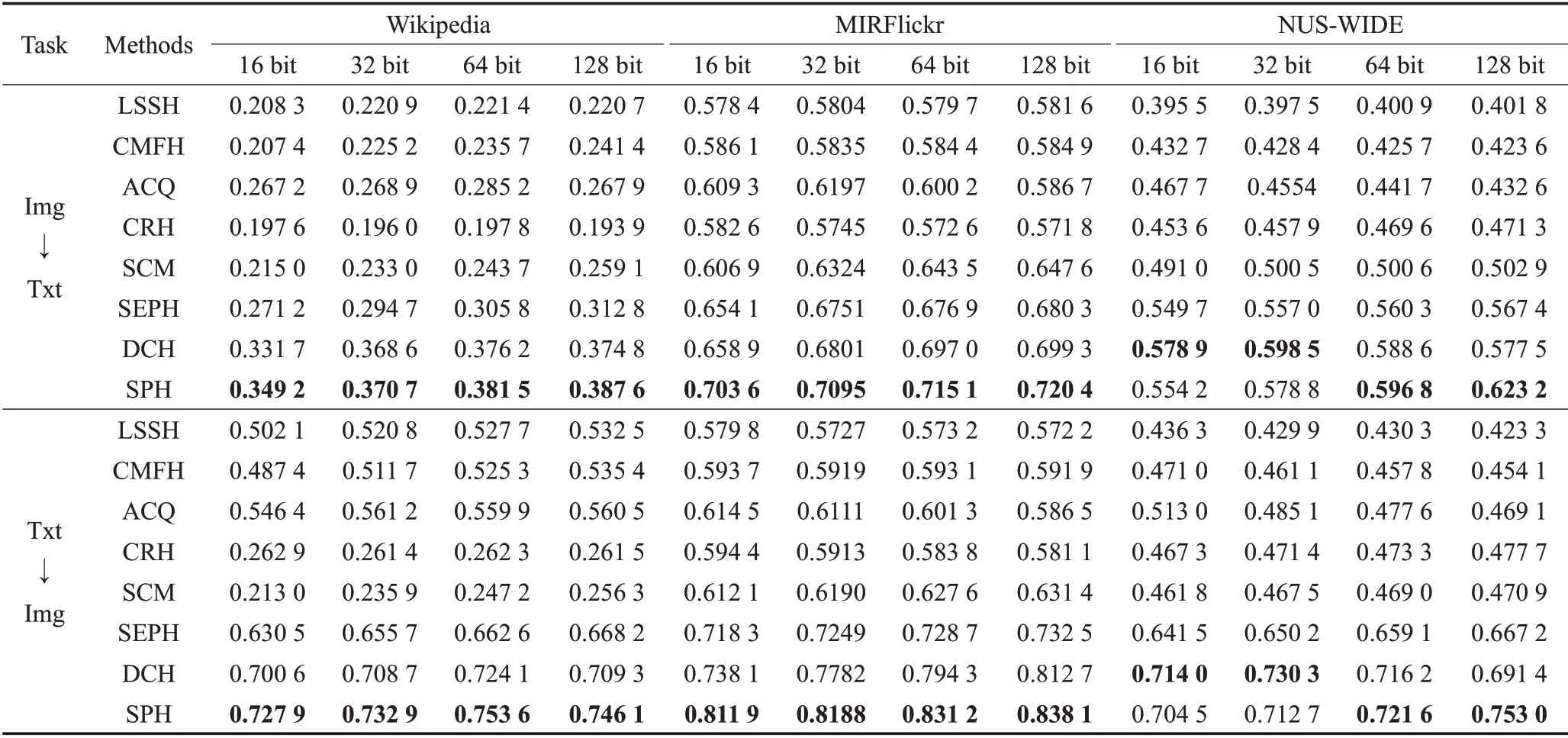
表1 各数据集上MAP的对比情况Table 1 MAP comparison on all datasets
(1)在所有数据集上,MAP随哈希编码的长度增加而有所提高。这是因为,较长的哈希编码可以记录更多的识别信息。
(2)相较于其他对比方法,SPH 在Wikipedia 和MIRFlickr 数据集上取得最好的检索结果,原因在于SPH将哈希编码和哈希函数的学习融合到一个框架,使其共同保持语义结构。
(3)相比于其他方法,DCH和SPH取得较好的检索结果,其优势在于它们将哈希编码映射到语义标签,使哈希编码具有语义鉴别性。另外,SPH 比DCH 的检索效果更好,原因在于SPH使哈希编码和哈希函数进一步保持了语义结构关系。
(4)SPH在NUS-WIDE数据集上并不总是取得最好的结果,其原因可能为NUS-WIDE数据集过于庞大,学习过程中采用分批的训练方式导致哈希编码不能保持整体的语义结构信息,这也成为未来工作中需要解决的问题。
3.4 Precision@scope曲线
为了进行更深入的对比研究,图2 展示了在Wikipedia 和MIRFlickr 两个数据集上各方法关于Img2Txt和Txt2Img 任务的Precision@scope 曲线的对比情况,其中哈希编码固定为32 位,scope 表示检索返回的样本数。由图可见,本文方法SPH 在Img2Txt 和Txt2Img任务上总能取得最高的检索准确率,特别是在MIRFlickr 数据集上,取得了更显著的效果。这一结果的根本原因在于,SPH 借用局部结构保持的思想,将哈希编码和哈希函数的学习融合到同一个框架,使两者同时优化,共同保持语义结构,从而提高哈希编码的语义鉴别能力。
3.5 收敛性分析
图3 展示了Wikipedia 和MIRFlickr 数据集上SPH的目标函数值随训练迭代次数而变化的曲线。由图3可见,两个数据集上,SPH 的目标函数值随着迭代次数的增加而迅速下降,并在数次迭代后趋于平衡,收敛于局部最小值。这一结果体现了本文优化方法的快速收敛性,证明了其有效性。
4 结束语
本文将局部结构保持的思想用于跨模态的语义结构保持,并提出语义结构保持哈希的方法(SPH),将其应用于跨模态检索。SPH通过构造语义结构图,把哈希编码和哈希函数的学习融合到同一个框架,并对两者同时优化,使其具有语义鉴别性。本文在三个多模态数据集上对SPH进行评估,其效果广泛优于现有的线性跨模态检索方法,且具有良好的收敛性。后续工作将会探索将SPH的思想扩展到基于深度学习的框架,探讨其在深度框架下的优化方法,进一步提高检索准确率。另外,在大规模数据集下保持数据的语义结构也在未来工作范畴内。
猜你喜欢
计算机研究与发展(2022年1期)2022-01-19
大数据(2021年6期)2021-11-22
电脑爱好者(2021年8期)2021-04-21
计算机应用(2020年12期)2020-12-31
电脑爱好者(2020年20期)2020-10-22
技术与创新管理(2020年5期)2020-10-09
科学与财富(2019年27期)2019-10-25
意林(图解作文)(2019年6期)2019-07-16
科学与财富(2017年28期)2017-10-14
文苑(2015年9期)2015-09-10
