
DCN:双通道密集哈达玛卷积的画质评价网络
2022-11-16 02:25杨晓东韩振奇刘立庄
计算机工程与应用 2022年21期
杨晓东,韩振奇,刘立庄,赵 丹
1.中国科学院 上海高等研究院,上海 201210
2.中国科学院大学,北京 100049
随着科技的快速发展,图像作为信息的主要形式之一,在社交网络和智能移动终端中占据着重要地位,对于任何显示设备,图像的质量是十分重要的技术指标。然而,图像在产生、传输、处理和存储的过程中会产生各种失真,会极大地影响观察者的主观舒适度和其他视觉任务的准确率。因此,客观画质评价方法研究具有重要的社会意义。在现有的方法中,由于实际场景的参考图像较难获取,无参考方法成为了主要研究方向。
造成图像失真的因素主要分为两个方面:环境条件和拍摄手法,可能导致图像产生离焦模糊、运动模糊、噪声、过曝、欠曝等现象,如图1所示;图像处理过程,可能会引起有损压缩、高斯噪声和对比度衰减等,导致图像质量下降[1]。引入失真图像会降低其他视觉任务性能,在Dodge 等人[2]的研究中,神经网络易受模糊和噪声失真图像的影响,会加大网络学习的难度。因此,客观图像质量评价可用于指导图像处理,以提高其他任务的性能。此外,在工业生产中,画质评价广泛也应用于显示器设备的画质调试和相机自动聚焦,评价结果可与软硬件处理相结合,以得到更高的画质和更精准的聚焦,具有较高的实用价值。
画质评价学术上称为图像质量评价,方法分为主观质量评价和客观质量评价。主观质量评价指标分为平均主观意见分(mean opinion score,MOS)和平均主观得分差异(differential mean opinion score,DMOS)。普遍认为主观评价较为可靠[3],但耗费大量时间人力成本,一般作为真实值来衡量主客观评价一致性。对于客观质量评价,根据参考标准图像信息的程度,将相关研究工作分为全参考型、半参考型和无参考型。
全参考(full-reference,FR)图像质量评价是利用标准图像所有信息与待评价图像计算相应指标而得出质量分数。传统的计算指标有均方误差、信噪比和峰值信噪比,计算速度快但准确度较低。近年来利用亮度、对比度、结构、梯度等质量特征进行相似度计算的方法逐渐发展,常用的指标有SSIM[4]、FSIM[5]、GMSD[6],以及DASM[7]等。随着深度学习的发展,深度卷积神经网络模型也被用于全参考图像质量评估。例如Liang等人[8]提出路径深度卷积神经网络(DCNN),利用“自然度”信息,对于非对齐相似场景能取得较好效果。Gao等人[9]提出的DeepSim模型通过测量深度特征的局部相似性,并融合局部指标来计算总分。Kim等人[10]提出的DeepQA方法是从IQA数据库分布中学习信息,产生视觉敏感度分布权重图,预测精度较高。FRIQA主客观一致性评价较好,但在多数实际情况中并不适用。
半参考(reduced-reference,RR)方法是以理想图像的部分特征作为参考,对待评估图像进行分析得出结果,主要为解决在无线传输条件图像质量评估问题而发展。Wang等人[11]提出RR-IQA方法,在小波域分解图像并拟合系数分布,计算KL距离作为评估分数。Soundararajan 等人[12]提出RRED 方法,在高斯混合尺度模型下使用参考和评价图像的交叉熵来预测质量。
无参考(no-reference,NR)方法也称作盲图像质量评估(blind image quality assessment,BIQA),是学习待评价图像本身特征到主观质量的映射关系,不利用参考图像的任何信息,具有较大挑战性。对于自然统计特征的研究,有空域熵和梯度、频域熵和小波域等特征,例如BIQI[13]、NIQE[14]、BRISQUE[15]和SSEQ[16]指标,典型的是Xu 等人[17]提出高阶统计量聚合(HOSA)方法,通过K-means 聚类局部特征构造码本,计算类均值和方差等,构建全局质量感知特征,采用支持向量机(support vector machine,SVM)学习质量映射关系,其性能在传统方法中具有竞争力。对于深度学习的方法研究,一般利用其他任务的深层语义特征作为先验知识辅助学习。Bianco 等人[18]提出DeepBIQ 模型,采用使用VGG16 网络提取特征,支持向量回归(support vector regression,SVR)预测质量。Liu等人[19]提出RankIQA网络,采用迁移学习的思想,对原始图像和失真图像训练孪生网络等级质量的图像对。Zeng 等人[20]对流行的预训练模型进行微调,以学习概率质量表示(PQR)。Pan 等人[21]提出BPSQM模型分为预测相似质量图和池化网络分数预测两部分。针对不同图像内容和失真类型的问题,Li 等人[22]提出SFA思想,统计聚合多个patch的语义特征,用分类模型得到上下文感知属性;Zhang 等人[23]提出深度双线性模型DBCNN,对于综合和真实的失真图像都有效;Zhu 等人提出[24]了基于深度元学习的IQA 度量MetaIQA,将不同畸变的图像质量评估时共享的元知识作为先验,以适应未知畸变;Su 等人[25]提出HyperIQA,通过超网络自适应地建立感知规则,并将其用于质量预测网络。基于Koniq-10k 数据集,Hosu 等人[26]提出Koncept512模型,核心架构为Inception-ResNet-v2,具有较高的泛化能力。针对MAE 和MSE 损失函数收敛速度缓慢的问题,Li 等人[27]设计了一种与PLCC 和RMSE指标密切相关的归一化损失函数(norm-in-norm loss,NINLoss),取主客观分数归一化的差值范数,梯度更稳定,加快IQA 模型收敛速度,在KonIQ-10k 数据集上获得了先进的预测性能。
无参考评价方法普遍面临失真复杂性和内容依赖性的挑战,自然统计特征方法有局限性且准确率低,深度学习方法虽然性能提升较大,但多数的质量特征表达还不够充分有效。针对此问题,本文提出了一种基于密集哈达玛卷积的双通道无参考图像质量评价网络。该方网络由骨干网络和分数评估网络级联组成,其中,骨干网络采用的是Inception-ResNet-v2,主要负责图像质量特征提取;分数评估网络采用多层感知机和多层卷积并联的双通道结构,充分结合了多层次的语义特征,增强特征表达的多样性。在多层感知机分支中设计了密集哈达玛卷积模块(DHPM),即通过哈达玛乘积的形式将低层神经元特征与高层神经元特征进行组合变换,起到一定的自注意力作用。
1 双通道密集哈达玛卷积网络(DCN)
双通道密集哈达玛卷积图像质量评价网络的整体架构如图2 所示,由骨干网络和分数评估网络级联组成。(1)骨干网络,采用特征提取能力优秀的Inception-Resnet-v2 网络,以ImageNet 预训练权重提取分类特征作为先验,在质量评估数据集上进行微调,以解决内容依赖性问题。网络输入是三维的待评估图像,输出1 536维特征图。(2)分数评估网络,采用多层感知机和多层卷积并联双通道特征融合结构。多层感知机实现特征变换,密集哈达玛卷积模块以输入作为权重,与每层特征映射做哈达玛积。其使用多特征融合和高级表达以更好地处理失真复杂度。(3)分数评估网络连接在骨干网络之后,模型输入输出分别为待评价图像和质量分数。
1.1 骨干网络
整个框架的骨干部分应该具有较强的特征提取力,因此本文采用Inception-ResNet-v2网络。在一定程度上,随着网络加深,语义特征更高级和抽象,图像质量越容易分辨。以ILSVRC 图像分类的表现为参考标准,在ResNet与GoogLeNet的结合体中,Inception-ResNet-v2的性能十分优秀,能够充分挖掘图像的特征,减少卷积过程中信息的损失。残差网络中的shortcut既可以加速训练,又能防止梯度弥散,易于训练深层网络;Inception模块增加了网络的宽度和多尺度适应性;再加上足够大的网络规模,使得Inception-ResNet-v2的Top-1准确率高达80.4%。Inception-ResNet-v2 的网络框架如图3 所示,包含Stem网络、各种Inception-Resnet 模块和适配的Reduction 模块[28]。在本实验中,不包含Average Pooling、Dropout和Softmax层,提取的特征图直接输出到预测网络中。
1.2 分数评估网络
1.2.1 密集哈达玛卷积
密集哈达玛卷积,也称为密集哈达玛乘积,是根据Liu 等人[29]提出的Dendrite Net(DD)总结而来。Dendrite Net 不同于卷积神经网络,此结构中只含全连接的特征映射层,并通过将输入与每层特征融合来表达各个输入与输出的复杂关系,式(1)为前向传播表达式:
其中,X是DD网络整体的输入,Al-1和Al分别为第l层的输入和输出特征,Wl,l-1是第l-1 到第l个模块的变换权重,运算符∘表示哈达玛积。相对于神经元网络,DD具有较低的计算复杂度和更好的泛化能力,在回归问题上表现出良好的性能。
本文提出的DHPM由3层DD组成,如图4所示,输入X是特征向量,输出为F(x)。X除了进行权重变换之外,还有一个恒等映射的连接到每层的输出,这点与残差模块结构[30]十分相似,也同样使得深度质量评价网络易于训练和优化。不同的是,图4结构不是模块的简单堆叠,每层输出都与原始输入融合。在恒等映射的连接结构上,又类似于DenseNet[31]的密集连接,能够加强特征的传递,从而更有效地利用特征,所以称之为密集哈达玛卷积。
对于前馈特征的融合方式,一般为通道维度上的连接或者空间位置的相加,DHPM结构中则使用了哈达玛积,可以理解为引入了一种特殊的自注意力机制[29]。在视觉自注意力机制的模块结构中,两个信息流分别用来评估注意力权重和特征线性映射,输出通过哈达玛乘积聚合[32]。对应于图4,左信息流是特征变换,右信息流的恒等映射相当于图片内容相关的权重。对于空间和通道特定位置上的特征自适应加权,可以将重要的特征放大,抑制不重要的特征。
对于DHPM,从输出表达式来进一步分析其特性。假设输入X是3维特征向量,输出表达式如式(2)所示:
X依次经过三个权重矩阵(W10、W21和W32)的变换,每层输出都与X对应相乘。输出项是三个特征与权重的组合项,有单特征的高次幂项和多特征乘积项;组合项的权重系数较多,可使得特征学习更为灵活。而传统的多层感知机只有特征的一次项,输出是输入的线性叠加,特征表达形式较为局限。对于无法用公式表达的抽象特征映射函数,密集哈达玛集成恰好是泰勒展开式,理论上可以近似到所需的任何精度[29]。
1.2.2 双通道结构
双通道结构由两个特征变换分支组成,如图2 所示。骨干网络输出的特征图作为输入,接着流向两个支路。多层感知机支路包含全局平均池化(global average pooling,GAP)、3 层全连接层(fully connected,FC)和3层DD,全连接层神经元个数分别为2 048、1 024、256;卷积支路串联3层卷积,卷积核大小均为1×1,个数为512、256和128,输出特征图再经过全局平均池化(gap2),得到128维特征向量。最后连接(concat)以上两个通道的特征向量,经过全连接层(fc7)映射到质量分数。
具体的,DHPM嵌在全连接支路,X和Y分别为输入和输出特征,全连接层表示特征的线性映射,∘表示哈达玛积。DHPM 在分数评估网络中能够逼近全局最优,其层数可以有效调整特征表达能力,层数越多拟合越精确,但是过量则会引起网络学习的过拟合,并带来较高的计算复杂度,所以3层较为合适。
分数评估网络设计的优势在于:(1)以往的质量评估网络多是特征提取和全连接组成,对特征图直接进行全局平均池化会造成特征的模糊,从而丢失部分信息。而双通道结构是将不同类型的特征相结合,增加了语义特征的多样性和完整性;(2)相对于单通道评估网络,其增加了深度和宽度,使得特征表达更加高级。(3)在多层感知特征后连接DHPM,通过多层特征的自适应密集连结,更精确地拟合特征映射函数。因此,双通道结构的评估网络更具有图像质量的可辨别性。
2 实验
2.1 数据集
真实的图像退化对于准确的质量预测至关重要。对于真实失真的图像数据,目前规模最大的IQA数据集是KonIQ-10k[26],包含10 073 个质量评分图像。通过使用众包,每幅图像获得120个可靠的质量评价等级和主观平均得分。数据集在七个指标分布上具有平衡性,分别是亮度、色彩、均方根对比度、清晰度、图像比特率、分辨率和JPEG 压缩质量,均与人类感知密切相关。KonIQ-10k 数据集共有三个分辨率,分别是1 024×768、512×384 和224×224,最常用的是512×384 分辨率。从规模和指标分布上看,KonIQ-10k有利于训练泛化性能更好的深度网络模型。
2.2 评价指标
2.2.1 PLCC
主客观质量评价的一致程度可通过度量指标说明。皮尔森线性相关系数(PLCC)反映两变量或分布之间的相关性,计算公式如式(3)所示:
其中,N为测试图像个数,xi和xˉ表示第i幅图像的MOS和其样本均值,yi和yˉ表示第i幅图像的质量预测分数和均值。PLCC取值范围[0,1],值越大表示图像质量的主客观评价越一致,客观评价算法预测准确率越高。
2.2.2 SROCC
斯皮尔曼秩相关系数(SROCC)表示客观评价分数相对于真值分数的单调性,计算公式如式(4)所示:
其中,N表示测试图像的个数,rxi和ryi表示第i幅图像的主客观分数的分别排序位置,差值表征距离。SROCC取值范围[0,1],值越大表示单调性越好,反映主客观评价一致性越高。
2.3 实验设置
实验采用KonIQ-10k的训练集、验证集和测试集包含图像的个数分别为7 058、1 000和2 015。实验中所有的模型都使用512×384分辨率数据集进行训练,标签采用MOS。选择Adam 优化器,MSE 损失函数表达式如式(5)所示:
其中,Q和Q^ 分别为MOS和预测分数分布,qi和qi为第i张图片的分数,N为集合图片个数。另一个常用的MAE损失函数表达式如式(6)所示,仅作为测试时的指标之一。
为使模型更快收敛,批次大小设置为16。骨干网络Inception-ResNet-v2 使用ImageNet 预训练权值进行初始化。学习率逐渐下降,第一阶段学习率为1×10-4,训练40步;第二阶段学习率为2×10-5,训练40步;第三阶段学习率为1×10-5,训练20步。每步训练后在验证集上计算Loss、SROCC 和PLCC,整个过程监控PLCC,保存最大值对应的模型以防止过拟合,使模型泛化能力达到最佳。模型的最终性能为测试集上评估的结果。实验使用NVIDIA RTX 8000 GPU和PyTorch深度学习框架。
2.4 实验结果
2.4.1 消融实验
为了证明双通道结构本身和DHPM 各自的作用,本文设计了4 个对比实验,骨干网络均采用Inception-ResNet-v2,分数评估网络分别为:4 层全连接层单通道结构(SC)作为基准,双通道结构(DC),在单通道的相同位置加入DHPM(SC+DHPM),以及本文提出的结构(DCN)。
所有实验在KonIQ-10k测试集上的评价结果如表1所示,观察数据可以得出:(1)SC 的SROCC 和PLCC 分别为0.909 和0.924,DC 比它高出1.0 和1.2 个百分点。同样的,DCN 的两个指标也比SC+DHPM 均高出了0.7个百分点,这说明双通道结构的确能够充分融合特征,减少信息损失。(2)SC+DHPM 的SROCC 和PLCC 相对于SC 分别提升了0.6 和0.7 个百分点,DC+DHPM 相对于DC则提升的相对较少,为0.3和0.2个百分点,意味着双通道特征和DHPM的作用会有一定的重合,其在网络中发挥了特征高级表达作用。
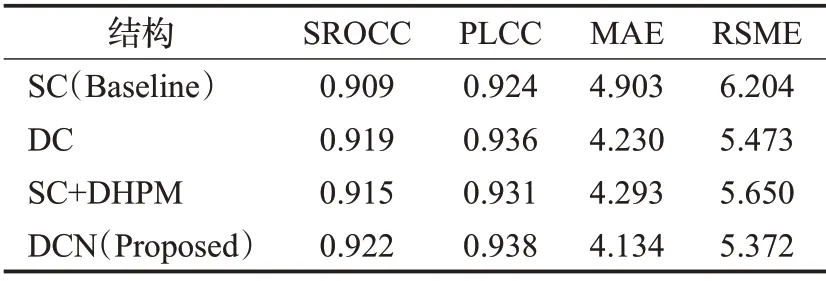
表1 不同结构对比Table 1 Comparison of different structures
在公开数据集KonIQ-10k测试评价指标中,本文所提出方法的SROCC 和PLCC 分别达到0.922 和0.938 的性能;在骨干网络相同的情况下,相对于无密集哈达玛卷积的单通道多层感知机评估网络结构,提升了1.3 和1.4 个百分点;相对于无密集哈达玛卷积的双通道结构提升了0.3 个百分点和0.2 个百分点。从MAE 和MSE损失值来看,本文方法最低,这与评价指标相对应。整体实验表明,本文提出的网络结构提取的质量特征更加有效,模型的泛化性能较好。
为了形象地表示主客观图像质量评价的关系,以x轴为真值MOS,y轴为模型预测的MOS,将模型在KonIQ-10k 测试集上的预测分布画在二维散点图上。为了方便对比,将SC和DCN的主客观评价值画在一个图中,如图5所示,图中每个点对应一幅图像,蓝色的点表示SC,黄色的点表示DCN。观察得知,DCN 的点更集中在对角线上,且分布更加密集;而SC的点整体分布偏于对角线,且低分阶段比较分散。因此DCN 模型对于图像质量评估有更好的主客观一致性。
为了进一步说明DCN 模型对失真图像的效果,从KonIQ-10k测试集中随机挑选6幅图片如图6,将基准SC和DCN模型的客观质量评分与主观MOS进行对比。图6的(a)、(b)、(c)失真比较严重,包括压缩模糊、离焦模糊和场景过暗等情况;(d)、(e)、(f)质量较好,色彩丰富恰当,分辨率较高且细节清晰。表2 中是每幅图片的MOS、SC和DCN预测分数。总体来看,DCN模型的预测分数更接近MOS,在评价对比度、清晰度和色彩等方面,DCN模型的辨别能力更强,与主观评价指标的表现相对一致。
2.4.2 算法性能对比
为了说明本文提出方法的先进性,将其与目前性能较好的IQA 方法对比。手工提取特征方法在KonIQ-10k上的性能远不能令人满意,即使其在合成失真数据库上取得了较高的准确率,因此表2 只列出一种传统BIQA方法即HOSA[17],其余均为深度学习模型。表2中的所有方法皆在KonIQ-10k 上训练和测试,观察得出,提出的DCN 模型在无参考图像评估中,优于传统方法和大部分深度学习模型,处于较为先进的水平。本文提出的基于密集哈达玛加权的双通道特征融合结构,能够使得图像的质量特征可辨别性更高。
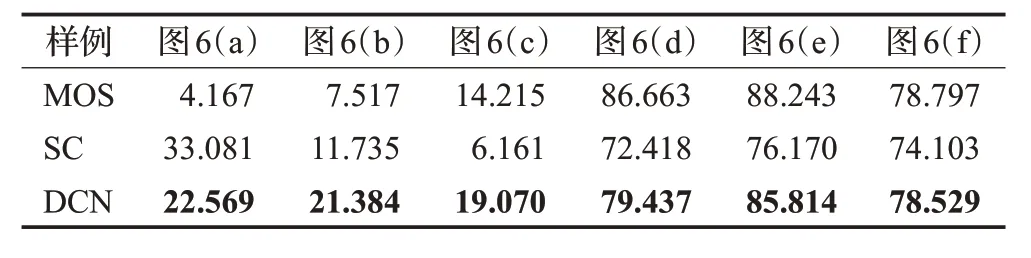
表2 SC和DCN的评分对比Tabel 2 Comparison of scores of SC and DCN
评估性能第一名的LIneartyIQA 方法[27],采用了规范化损失(NINloss)加速模型的收敛,基于ImageNet 预训练的ResNeXt-101的骨干模型进行多层次特征提取,通过全连接层将不同级别的特征聚合。虽然其性能处于最先进的地位,但是模型复杂度较高,如表3所示,本文模型的训练参数量仅有60.9×106,LIneartyIQA 综合ResNeXt-101 和特征映射层,总训练参数量达到89.9×106,高出DCN 约1/2。因此,本文方法平衡了质量预测准确率和模型复杂度,综合性能较好,是一种有效的图像质量评价方法。
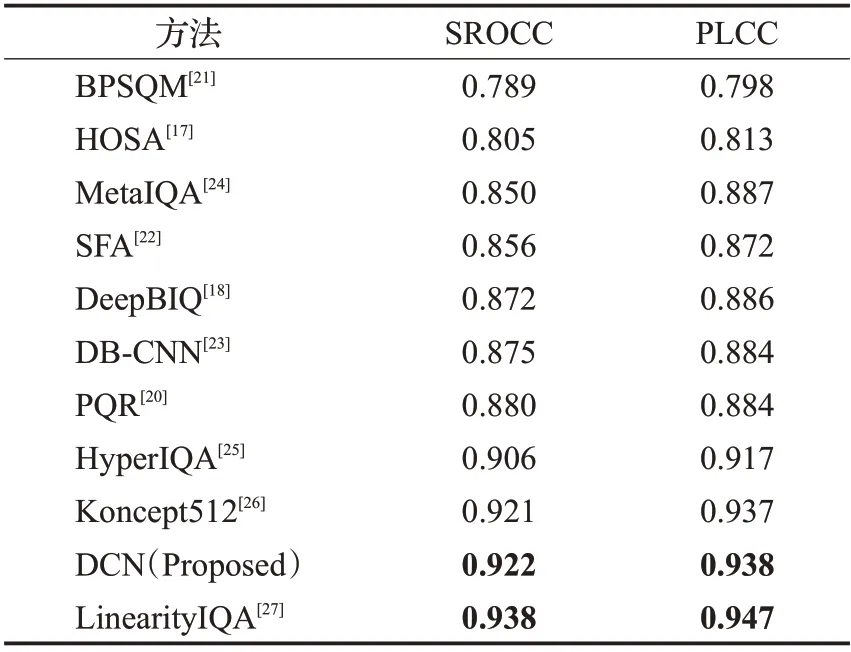
表3 与其他算法对比Table 3 Comparison with other methods

表4 模型参数量对比Fig.4 Comparison of parameters
3 结束语
在真实失真图像质量评价的挑战性问题上,本文提出了一种双通道密集哈达玛卷积的IQA 网络,采用InceptionResnet-v2作为骨干网络,并以增强特征表达的准确性和有效性为目标,设计了融合多层感知机和卷积特征的双通道结构。此外,多层感知机分支中的DHPM,通过密集哈达玛加权引入了自注意力机制,实现特征的自适应性。在KonIQ-10k 数据集上的实验结果表明,与现有方法对比,本文方法的SROCC 和PLCC指标均处于较领先的地位,图像质量评估的主客观一致性较高,模型泛化能力更强,同时复杂度低于Linearty-IQA 模型。本文提出的分数评估网络和整体结构不只适用于IQA 问题,也可以迁移至其他视觉任务,具有一定的通用性。此外,针对图像质量评估方法的优化,考虑加入先验知识以指导神经网络特征提取,提升主客观评价一致性。
猜你喜欢
音乐教育与创作(2022年6期)2022-10-11
散文诗(2021年22期)2022-01-12
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
昆明医科大学学报(2021年4期)2021-07-23
就业与保障(2021年23期)2021-04-06
启迪与智慧·下旬刊(2019年11期)2019-09-10
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
作文周刊·小学一年级版(2017年42期)2017-12-05
